
National Action Council for Minorities in Engineering(NACME) Google Applied Machine Learning Intensive (AMLI) at the UNIVERSITY OF ARKANSAS
Developed by:
- Santiago Dorado -
UNIVERSITY OF ARKANSAS - Devin Hill -
UNIVERSITY OF ARKANSAS - Ayia Ismael -
VIRGINIA TECH - Adrian Whitty -
UNIVERSITY OF ARKANSAS-PINE BLUFF
The objective of this project is to use machine learning models to predict the location of a aerial drone. These models rely on the real-time high-altitude to maintain geolocation of the drone.
Long term - To use Convolutional Neural Networks in application to Absolution Visual Geolocation to prevent the possible drawbacks and lack of secure navigation when navigating by GNSS. In the long run, taking this model and its subsequent algorithmic modeling and applying it to sections outside of the Washington County area that the current images used for testing and training are based on. Short term - Optimize the models for better accuarcy uses 12 training set and 1 testing set for Washington County.
-
Dataset: Agricultural land images taken in Washington county from 2006 to 2020.
-
Data Preparation: Data gathering, data transformation and data validation were all methods we used to prepare our data.
For this project, we decided to use Xception and Vision Transformer models. The models that we used were developed and constructed previously by Dr. Rainwater and Winthrop Harvey. Our main objective was to improve the performance of these models.
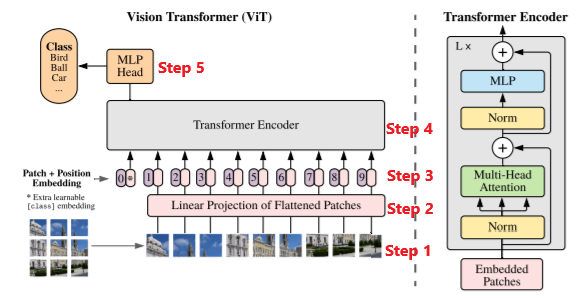
ViT
The Vision transformer is based on the structure of a transformer designed for text-based tasks.
 Xception
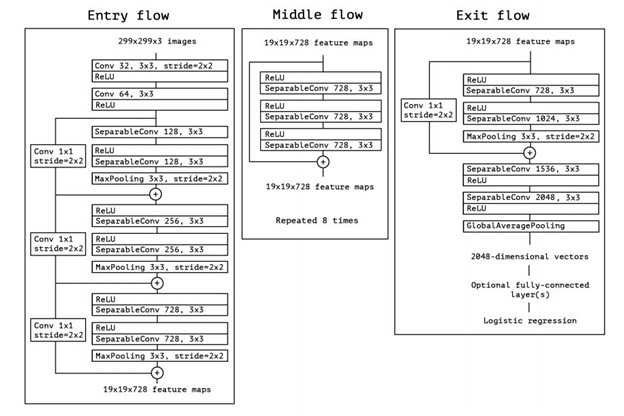
Xception is a convolutional neural network. The pretrain Xception network can classify 1000 object categories, but in our class we are using Xception to categorize location of images.
Xception
Xception is a convolutional neural network. The pretrain Xception network can classify 1000 object categories, but in our class we are using Xception to categorize location of images.
Based on our model’s performance, we have deemed that the model that utilizes Vision Transformers was the best performing model. This was due to the optimal RMSE score and loss score being less than that of the model using Xception. Although Xception did have slightly higher accuracy, vision transformers are optimal for large datasets that include millions of images. Since we only had a dataset of 24,000 images, the accuracy, and performance of the model using vision transformers underperformed due to the lack of data. This however is not a real issue since our dataset was only collected from an area of thirty kilometers squared.
- Fork this repo
- Change directories into your project
- On the command line, type
pip3 install requirements.txt - ....