RAG + SLM = A lightweight model that “thinks” efficiently while “reading” external, up-to-date knowledge bases.
A simple chart was created to visualize and clarify how Retrieval-Augmented Generation (RAG) operates when integrated with Small Language Models (SLMs).
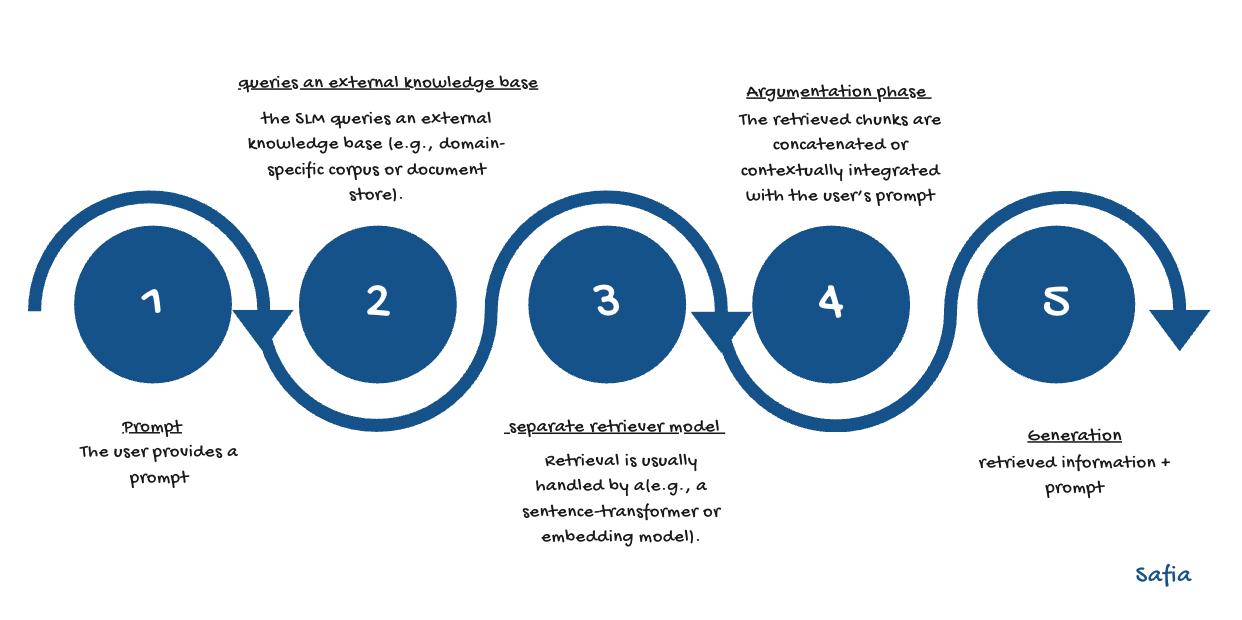
Through this combination, the model is enabled to remain lightweight while efficiently accessing external knowledge this is an ideal configuration for setups requiring local execution, low latency, and minimal computational cost 'our case'.
A comprehensive guide provided by Hugging Face was used to understand the
concept and its implementation:
Make Your Own RAG
The Hugging Face example was explored, and the code was adapted for testing on
Google Colab.
The notebook can be accessed here:
Colab Notebook
-
RAG (Retrieval-Augmented Generation) integrates:
- a retriever → used for fetching relevant context or knowledge chunks
- a language model → employed for generating grounded and context-aware answers
-
SLMs (Small Language Models) were shown to perform RAG effectively when:
- coupled with high-quality embeddings
- guided by well-engineered prompts
-
The embedding model was found to be crucial for retrieval quality.
-
Prompt engineering was identified as a key factor for improved grounding and coherence.
-
The use of GPU acceleration in Colab was recommended for faster performance.