|
| 1 | +# RAG + SLM: Efficient Knowledge-Augmented Reasoning |
| 2 | + |
| 3 | +RAG + SLM = A lightweight model that “thinks” efficiently while “reading” |
| 4 | +external, up-to-date knowledge bases. |
| 5 | + |
| 6 | +--- |
| 7 | + |
| 8 | +## Overview |
| 9 | + |
| 10 | +A simple chart was created to visualize and clarify how |
| 11 | +**Retrieval-Augmented Generation (RAG)** operates when integrated with |
| 12 | +**Small Language Models (SLMs)**. |
| 13 | + |
| 14 | +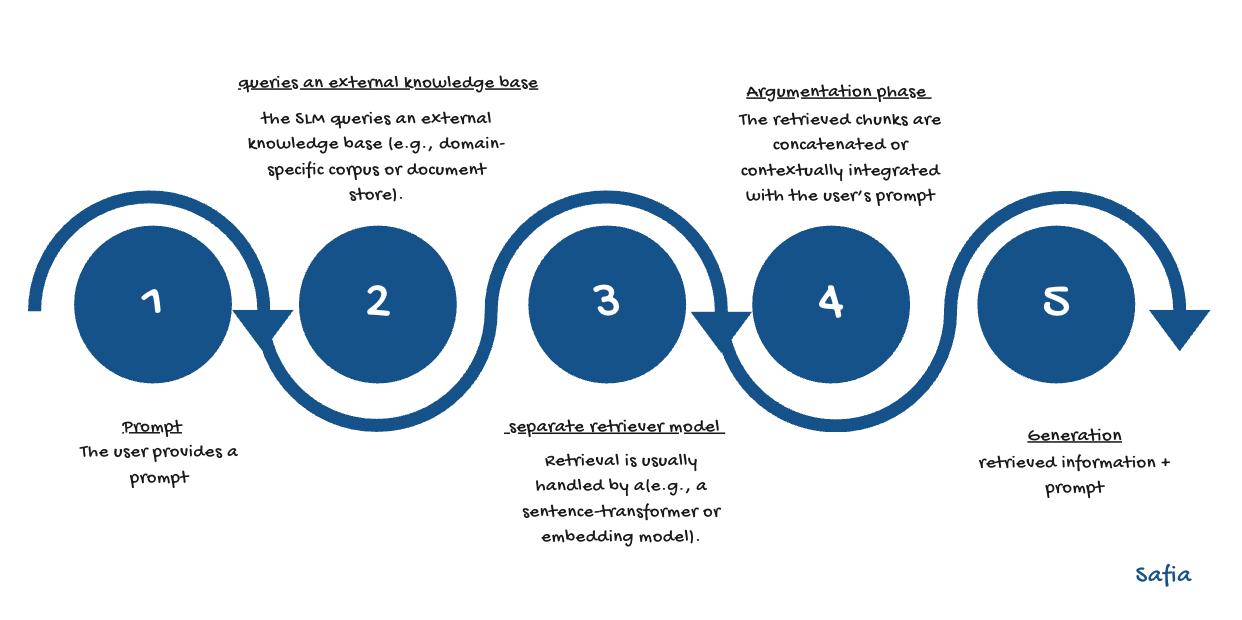 |
| 15 | + |
| 16 | +Through this combination, the model is enabled to remain lightweight while |
| 17 | +efficiently accessing external knowledge this is an ideal configuration for setups |
| 18 | +requiring local execution, low latency, and minimal computational cost 'our case'. |
| 19 | + |
| 20 | +--- |
| 21 | + |
| 22 | +## Reference |
| 23 | + |
| 24 | +A comprehensive guide provided by Hugging Face was used to understand the |
| 25 | +concept and its implementation: |
| 26 | +[Make Your Own RAG](https://huggingface.co/blog/ngxson/make-your-own-rag) |
| 27 | + |
| 28 | +--- |
| 29 | + |
| 30 | +## Implementation |
| 31 | + |
| 32 | +The Hugging Face example was explored, and the code was adapted for testing on |
| 33 | +Google Colab. |
| 34 | +The notebook can be accessed here: |
| 35 | +[Colab Notebook](https://colab.research.google.com/drive/1b3U2QI1NiYe67dCcxuur9vN2Q_HiHAn0#scrollTo=f9wbzle2ENt1) |
| 36 | + |
| 37 | +--- |
| 38 | + |
| 39 | +## Key Takeaways |
| 40 | + |
| 41 | +- **RAG (Retrieval-Augmented Generation)** integrates: |
| 42 | + - a retriever → used for fetching relevant context or knowledge chunks |
| 43 | + - a language model → employed for generating grounded and |
| 44 | + context-aware answers |
| 45 | + |
| 46 | +- **SLMs (Small Language Models)** were shown to perform RAG effectively when: |
| 47 | + - coupled with high-quality embeddings |
| 48 | + - guided by well-engineered prompts |
| 49 | + |
| 50 | +- The **embedding model** was found to be crucial for retrieval quality. |
| 51 | +- **Prompt engineering** was identified as a key factor for improved grounding |
| 52 | + and coherence. |
| 53 | +- The use of **GPU acceleration** in Colab was recommended for faster |
| 54 | + performance. |
0 commit comments