Singly Linked Lists -- Reverse
It will reversed the Singly Linked List
Example:
"A"
"B"
"C"
"D"
"E"
reversed_list :
"E"
"D"
"C"
"B"
"A"
Given the head of a singly linked list, reverse the list, and return the reversed list.
Example 1:
Input: head = [1,2,3,4,5]
Output: [5,4,3,2,1]
Example 2:
Input: head = [1,2]
Output: [2,1]
Example 3:
Input: head = []
Output: []You are given the heads of two sorted linked lists list1 and list2.
Merge the two lists into one sorted list. The list should be made by splicing together the nodes of the first two lists.
Return the head of the merged linked list.

Example 1:
Input: list1 = [1,2,4], list2 = [1,3,4]
Output: [1,1,2,3,4,4]Example 2:
Input: list1 = [], list2 = []
Output: []Example 3:
Input: list1 = [], list2 = [0]
Output: [0]This problem requires merging two sorted linked lists into a single sorted linked list. The key is to traverse both lists simultaneously, comparing their current nodes and appending the smaller one to the result list.
-
Why This Approach?
To solve the problem efficiently, we use the Two-Pointer technique to traverse both sorted lists simultaneously and compare their current nodes. This allows us to merge the lists in a single pass, avoiding unnecessary overhead.
This approach preserves the sorted order and works in linear time, making it ideal for large linked lists.
-
Problem-Solving Pattern
- Two Pointers
- Greedy Merge
- Linked List Manipulation
This is a classic merge operation, similar to the one used in the merge step of Merge Sort.
-
Efficiency and Elegance
Compared to brute-force approaches that might collect values into arrays and sort them later, this solution:
- Does not require extra storage for values
- Avoids additional sorting
- Maintains constant space (excluding output)
We achieve an elegant and efficient solution by directly manipulating the
nextpointers of the nodes.
-
Let’s walk through the merging of the following two sorted linked lists:
list1 = [1 -> 2 -> 4] list2 = [1 -> 3 -> 4] -
Initialization
- We create a
dummynode to act as the starting point of our merged list. - We use a
tailpointer to build the result list by attaching nodes to it.
- We create a
-
Iterative Merging
Step list1.val list2.val Action Merged List So Far 1 1 1 list2 appended 1 2 1 3 list1 appended 1 → 1 3 2 3 list1 appended 1 → 1 → 2 4 4 3 list2 appended 1 → 1 → 2 → 3 5 4 4 list2 appended 1 → 1 → 2 → 3 → 4 6 4 None list1 appended 1 → 1 → 2 → 3 → 4 → 4 -
At the end of the loop, we return
dummy.nextwhich points to the head of the merged list.
| Metric | Complexity | Explanation |
|---|---|---|
| Time | We traverse each of the two input lists once, where n and m are lengths |
|
| Space | We perform merging in-place (excluding output list nodes already given) |
The solution only creates one dummy node. All other nodes are reused from the input lists.
- We used a greedy and in-place two-pointer strategy to merge two sorted linked lists.
- The solution is efficient, clean, and leverages standard linked list operations.
- Time complexity is O(n + m) and space complexity is O(1), making it optimal.
- This pattern is highly reusable for other merging and comparison problems involving lists or arrays.
You are given the head of a singly linked-list. The list can be represented as:
L0 → L1 → … → Ln - 1 → Ln
Reorder the list to be on the following form:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
You may not modify the values in the list's nodes. Only nodes themselves may be changed.
Example 1:
Input: head = [1,2,3,4]
Output: [1,4,2,3]
Example 2:
Input: head = [1,2,3,4,5]
Output: [1,5,2,4,3]Given the head of a linked list, remove the nth node from the end of the list and return its head.
Example 1:
Input: head = [1,2,3,4,5], n = 2
Output: [1,2,3,5]
Example 2:
Input: head = [1], n = 1
Output: []
Example 3:
Input: head = [1,2], n = 1
Output: [1]Given head, the head of a linked list, determine if the linked list has a cycle in it.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail's next pointer is connected to. Note that pos is not passed as a parameter.
Return true if there is a cycle in the linked list. Otherwise, return false.
Example 1:
Input: head = [3,2,0,-4], pos = 1
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 1st node (0-indexed).Example 2:
Input: head = [1,2], pos = 0
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 0th node.Example 3:
Input: head = [1], pos = -1
Output: false
Explanation: There is no cycle in the linked list.This problem requires detecting whether a linked list has a cycle. A cycle occurs when a node's next pointer points back to a previous node, creating a loop.
-
Why This Approach?
We detect the cycle using Floyd’s Tortoise and Hare Algorithm (a two-pointer technique). This method is both efficient and elegant — it doesn't require extra space like hash sets and detects cycles in
O(n)time withO(1)space. -
Problem-Solving Pattern
- Two Pointer (Fast and Slow Pointers) — a classic approach used for cycle detection in linked lists.
- Hashing (Method 2) — an alternative approach that uses extra space but is easier to understand for beginners.
-
We will walk through Floyd's Cycle Detection Algorithm using the input:
Input: [3, 2, 0, -4], pos = 1
-
This means the list looks like:
3 → 2 → 0 → -4and-4.next = 2(cycle starts at node 2). -
Iteration Table
Step Slow Pointer Fast Pointer Notes 0 3 (head) 3 (head) Both pointers start at head 1 2 0 slow = slow.next, fast = fast.next.next 2 0 2 moving further 3 -4 -4 Both meet → Cycle detected -
When
slow == fast, a cycle is confirmed.
| Method | Time Complexity | Space Complexity | Explanation |
|---|---|---|---|
| Two Pointer (Floyd) | Fast and slow pointer traversal | ||
| Hashing | Store each node in a set |
- Best Practice: Use Floyd’s algorithm for efficient constant space solution.
- Alternative: Hashing can be useful when clarity is more important than optimal space.
You are given an array of k linked-lists lists, each linked-list is sorted in ascending order.
Merge all the linked-lists into one sorted linked-list and return it.
Example 1:
Input: lists = [[1,4,5],[1,3,4],[2,6]]
Output: [1,1,2,3,4,4,5,6]
Explanation: The linked-lists are:
[
1->4->5,
1->3->4,
2->6
]
merging them into one sorted list:
1->1->2->3->4->4->5->6
Example 2:
Input: lists = []
Output: []
Example 3:
Input: lists = [[]]
Output: []Given the head of a sorted linked list, delete all duplicates such that each element appears only once. Return the linked list sorted as well.
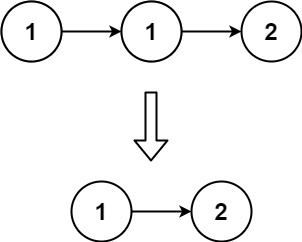
Example 1:
Input: head = [1,1,2]
Output: [1,2]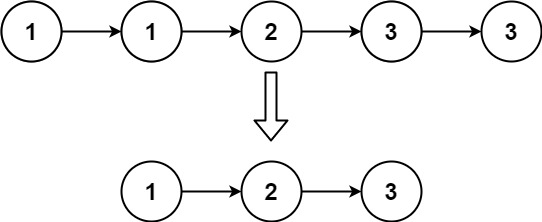
Example 2:
Input: head = [1,1,2,3,3]
Output: [1,2,3]This problem requires removing duplicates from a sorted linked list. Since the list is already sorted, duplicates will always be adjacent, allowing us to efficiently remove them in a single pass.
-
Why This Approach?
We chose a single-pass traversal approach since the linked list is already sorted in non-decreasing order. This key observation allows us to simply compare adjacent nodes to detect and remove duplicates in O(n) time without needing additional memory.
-
Problem-Solving Pattern
- Two-Pointer Technique (Current and Next Pointer)
- Linked List Traversal
- Greedy Filtering (removing duplicates as soon as they are found)
This pattern avoids extra data structures like hash sets or arrays and solves the problem in-place.
-
Efficiency and Elegance
Compared to methods that involve converting the list to a Python list or using sets, our approach is:
- In-place: No extra memory usage.
- Efficient: Just one iteration over the list.
- Clean: No complex conditionals or auxiliary operations.
-
Let’s walk through this input step-by-step:
Input: [1 → 1 → 2 → 3 → 3]-
Initialize a pointer
headto the start of the list. -
Traverse as long as both
headandhead.nextare not null. -
At each step:
-
If
head.val == head.next.val, skip the next node by updating thenextpointer. -
Otherwise, move the
headpointer forward.
-
-
Iteration Breakdown
Step Current head.valhead.next.valAction Linked List State 1 1 1 Duplicate → skip next 1 → 2 → 3 → 3 2 1 2 Move to next 1 → 2 → 3 → 3 3 2 3 Move to next 1 → 2 → 3 → 3 4 3 3 Duplicate → skip next 1 → 2 → 3 The pointer stops when
head.nextbecomesNone. -
Final Output
Updated List: [1 → 2 → 3]
| Metric | Complexity | Explanation |
|---|---|---|
| Time | We traverse the entire linked list once. | |
| Space | No additional data structures used; operations are done in-place. |
- This is an in-place solution that removes duplicates from a sorted linked list.
- By comparing adjacent nodes, we efficiently eliminate duplicates in O(n) time and O(1) space.
- This solution demonstrates a clean and minimalistic use of linked list traversal without auxiliary space or complexity.
There is a singly-linked list head and we want to delete a node node in it.
You are given the node to be deleted node. You will not be given access to the first node of head.
All the values of the linked list are unique, and it is guaranteed that the given node node is not the last node in the linked list.
Delete the given node. Note that by deleting the node, we do not mean removing it from memory. We mean:
- The value of the given node should not exist in the linked list.
- The number of nodes in the linked list should decrease by one.
- All the values before
nodeshould be in the same order. - All the values after
nodeshould be in the same order.
Custom testing:
- For the input, you should provide the entire linked list head and the node to be given node. node should not be the last node of the list and should be an actual node in the list.
- We will build the linked list and pass the node to your function.
- The output will be the entire list after calling your function.
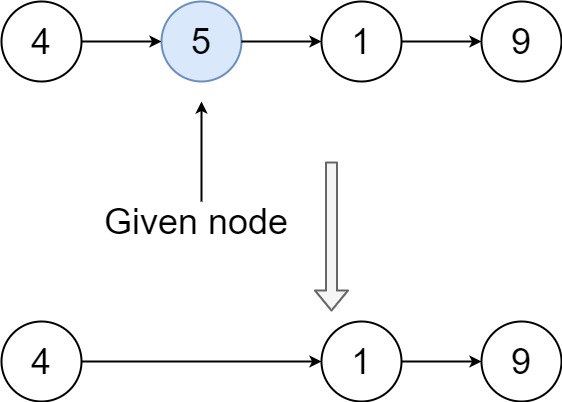
Example 1:
Input: head = [4,5,1,9], node = 5
Output: [4,1,9]
Explanation: You are given the second node with value 5, the linked list should become 4 -> 1 -> 9 after calling your function.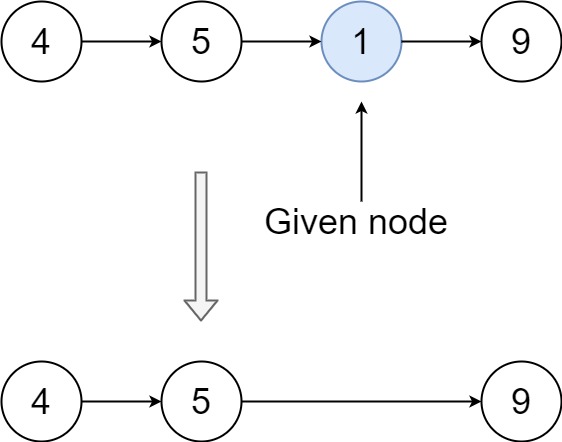
Example 2:
Input: head = [4,5,1,9], node = 1
Output: [4,5,9]
Explanation: You are given the third node with value 1, the linked list should become 4 -> 5 -> 9 after calling your function.This problem requires us to delete a node from a singly linked list without having access to the head of the list. The key constraint is that we cannot traverse the list from the head, and we are guaranteed that the node to be deleted is not the last node.
-
Why This Approach?
Since we don't have access to the previous node or the head pointer, we cannot simply traverse from the beginning and update links in the usual way.
To delete the given
node, we instead:- Copy the value from the next node into the current node.
- Bypass the next node by adjusting pointers.
This clever technique transforms the current node into the next node, effectively "deleting" the one we want.
-
Problem-Solving Pattern
- Pointer Manipulation
- In-place Node Overwrite
- A variant of the two-pointer technique, although limited due to access restrictions.
This solution is optimal given the constraints, using constant time and space, and no traversal from head.
-
Efficiency and Elegance
This approach is elegant because:
- It avoids traversal.
- No extra memory is used.
- It meets all constraints.
- The node is deleted logically, not physically.
-
Let’s consider this linked list:
Initial List: [1 → 2 → 3 → 4 → 5] Node to delete: 3 -
We are given a direct reference to node
3, but no access to head. -
Algorithm:
node.val = node.next.val node.next = node.next.next
-
Iteration Breakdown
Step Operation Resulting List Explanation 1 Copy node.next.val→node.val[1 → 2 → 4 → 4 → 5] Value of node 3becomes42 Skip next: node.next = node.next.next[1 → 2 → 4 → 5] The original 4is now skippedNode
3(now with value4) has replaced the next node and linked to the node after it. -
Final Output
Updated List: [1 → 2 → 4 → 5]The original
3is logically deleted.
| Metric | Complexity | Explanation |
|---|---|---|
| Time Complexity | Only local pointer and value manipulation is used; no traversal. | |
| Space Complexity | No additional space is required beyond a few pointers. |
- This solution handles deletion without head access, by overwriting the given node.
- It works only when the node to delete is not the last node.
- Offers constant time and space complexity.
- Elegant and efficient under given constraints.
Given the head of a singly linked list, group all the nodes with odd indices together followed by the nodes with even indices, and return the reordered list.
The first node is considered odd, and the second node is even, and so on.
Note that the relative order inside both the even and odd groups should remain as it was in the input.
You must solve the problem in O(1) extra space complexity and O(n) time complexity.
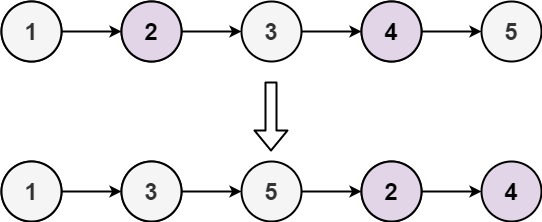
Example 1:
Input: head = [1,2,3,4,5]
Output: [1,3,5,2,4]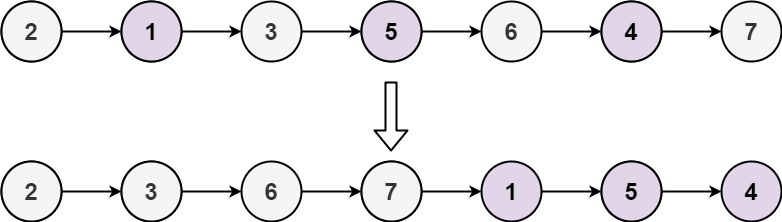
Example 2:
Input: head = [2,1,3,5,6,4,7]
Output: [2,3,6,7,1,5,4]This problem requires us to rearrange a singly linked list such that all nodes at odd indices come before nodes at even indices, while maintaining the relative order of nodes in each group. The challenge is to do this in-place with constant space complexity.
-
Why This Approach?
To rearrange the list while maintaining relative ordering of odd and even nodes, we traverse the list only once while maintaining two pointers:
- One for the odd-indexed nodes.
- One for the even-indexed nodes.
This allows us to relink the nodes in-place using a single traversal and constant space.
-
Problem-Solving Pattern
- Pattern Used: Two Pointers (Odd-Even separation)
- Type: Linked List pointer manipulation
- Goal: Partition the list into odd and even sequences while preserving relative order.
-
Example: Input
head = [1, 2, 3, 4, 5] -
Initial Structure:
Index: 1 2 3 4 5 Node: 1 → 2 → 3 → 4 → 5 -
Initialization:
odd = head→ points to 1even = head.next→ points to 2even_head = even→ stores the start of even list (needed later)
-
Iteration 1:
odd.next = even.next→ 1's next becomes 3odd = odd.next→ move odd to 3even.next = odd.next→ 2's next becomes 4even = even.next→ move even to 4
-
List so far:
Odd List: 1 → 3 Even List: 2 → 4 Remaining: 5 -
Iteration 2:
odd.next = even.next→ 3's next becomes 5odd = odd.next→ move odd to 5even.next = odd.next→ 4’s next is now None (end)even = even.next→ even becomes None (loop ends)
-
Final Merge:
odd.next = even_head→ connect odd list to start of even list
-
Result:
1 → 3 → 5 → 2 → 4
| Metric | Value | Explanation |
|---|---|---|
| Time Complexity | Single traversal of the entire list (each node visited once). | |
| Space Complexity | No extra space used other than a few pointers; list modified in-place. |
- This approach achieves in-place rearrangement by separating odd and even indexed nodes with constant space.
- No values are changed—only pointer manipulation is used.
A linked list of length n is given such that each node contains an additional random pointer, which could point to any node in the list, or null.
Construct a deep copy of the list. The deep copy should consist of exactly n brand new nodes, where each new node has its value set to the value of its corresponding original node. Both the next and random pointer of the new nodes should point to new nodes in the copied list such that the pointers in the original list and copied list represent the same list state. None of the pointers in the new list should point to nodes in the original list.
For example, if there are two nodes X and Y in the original list, where X.random --> Y, then for the corresponding two nodes x and y in the copied list, x.random --> y.
Return the head of the copied linked list.
The linked list is represented in the input/output as a list of n nodes. Each node is represented as a pair of [val, random_index] where:
val: an integer representing Node.val
random_index: the index of the node (range from 0 to n-1) that the random pointer points to, or null if it does not point to any node.
Your code will only be given the head of the original linked list.
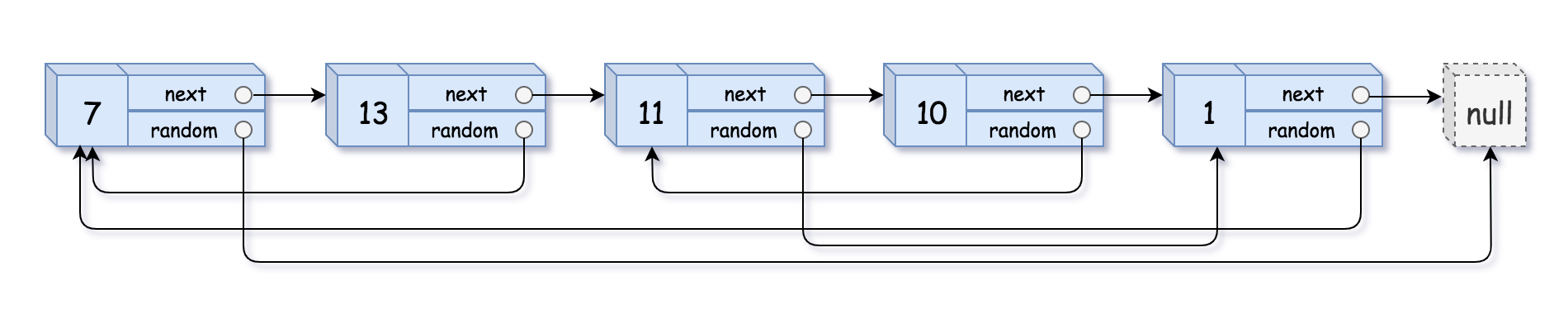
Example 1:
Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]
Example 2:
Input: head = [[1,1],[2,1]]
Output: [[1,1],[2,1]]
Example 3:
Input: head = [[3,null],[3,0],[3,null]]
Output: [[3,null],[3,0],[3,null]]This problem requires us to create a deep copy of a linked list where each node has an additional random pointer that can point to any node in the list or be null. The challenge is to ensure that the new list maintains the same structure and relationships as the original list.
-
Why This Approach?
This problem requires duplicating both the structure and cross-links (random pointers) of the original list. A one-pass clone of nodes would lose the
randomreference details.To handle this, we use a two-pass strategy:
- First pass: Create all new nodes and map original nodes to new nodes.
- Second pass: Reassign the correct
nextandrandompointers using the mapping.
This approach ensures a true deep copy while maintaining simplicity and clarity.
-
Problem-Solving Pattern
- HashMap / Dictionary mapping between original nodes and copied nodes.
- Two-pass traversal (common in linked list cloning problems).
- Ensures O(n) time with no cyclic dependencies.
-
Why This Is Efficient and Elegant
Other approaches attempt in-place interleaving and pointer reassignments, but they sacrifice readability and are prone to bugs. This dictionary-based method is:
- Intuitive
- Robust
- Efficient in practice
-
Example Input:
head = [[17,null],[13,0],[11,4],[10,2],[1,0]]
Which means:
Node1: val=17, random=NoneNode2: val=13, random=Node1Node3: val=11, random=Node5Node4: val=10, random=Node3Node5: val=1, random=Node1
-
Step 1: Clone Nodes Without Setting Pointers
current = head while current: old_to_new[current] = Node(current.val) current = current.next
-
Now we have:
old_to_new = { Node1_original: Node1_copy, Node2_original: Node2_copy, ... }
-
Step 2: Assign
nextandrandomPointerscurrent = head while current: copy_node = old_to_new[current] copy_node.next = old_to_new.get(current.next) copy_node.random = old_to_new.get(current.random) current = current.next
-
Each copy now gets its
nextandrandompointers based on the mapping. For instance:-
If
Node2_original.random = Node1_original, then: -
Node2_copy.random = old_to_new[Node1_original] = Node1_copy
-
-
Final Result:
The new list has:
- Nodes with same values.
- Correct
nextchain. - Correct
randomreferences — to new copies only, not to any original node.
| Metric | Value | Explanation |
|---|---|---|
| Time Complexity | We visit each node twice (once to copy values, once to assign pointers). | |
| Space Complexity | A dictionary of size n is used to store mapping from original to copy. |
- We used a dictionary to map original nodes to their respective copies.
- Ensured that the new list is structurally identical but made up of entirely new nodes.
- Efficiently handled both
nextandrandomassignments using a two-pass method. - Time and space complexities are optimal for this problem class.
Given the head of a linked list, rotate the list to the right by k places.
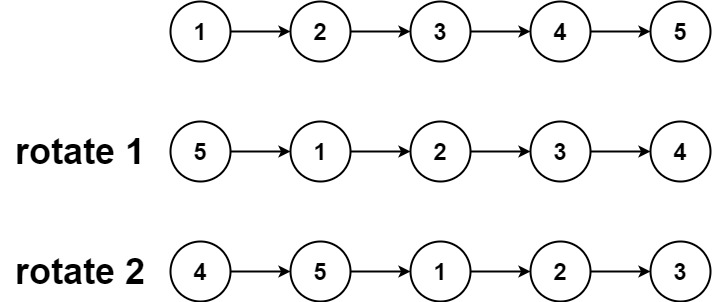
Example 1:
Input: head = [1,2,3,4,5], k = 2
Output: [4,5,1,2,3]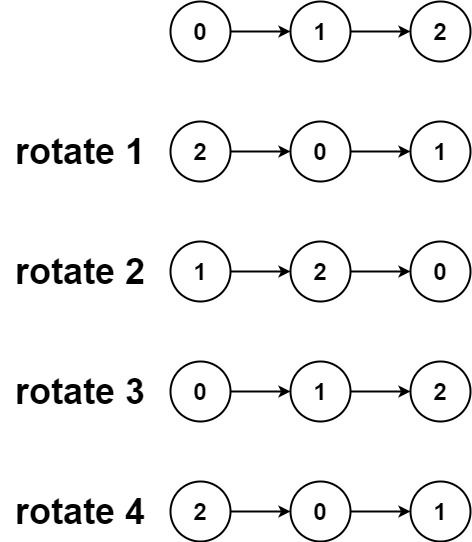
Example 2:
Input: head = [0,1,2], k = 4
Output: [2,0,1]This problem requires us to rotate a linked list to the right by k places. The challenge is to achieve this efficiently, especially when k can be larger than the length of the list.
-
Why This Approach?
The key idea is to convert the linked list temporarily into a circular list, then break it at the correct position to achieve the rotation efficiently.
This avoids repeated traversals that would be inefficient for large lists or large values of
k. -
Problem-Solving Pattern Used
- Two-pointer technique
- Modular arithmetic
- Circular linked list manipulation
- Linked list pointer reconfiguration
-
Efficiency and Elegance
This approach achieves the desired rotation in a single traversal for length and another traversal for positioning, with no extra space, thus making it both time and space optimal.
-
Input:
head = [1, 2, 3, 4, 5] k = 2
-
Step 1: Handle edge cases
- If
headisNone, has only one node, ork == 0→ return head immediately.
- If
-
Step 2: Determine length and connect tail to head (form a circle)
-
Traverse list:
length = 5tail = node with val 5
-
Connect tail to head:
-
tail.next = head(circular link formed)
-
-
Step 3: Calculate effective rotation steps
k = k % length # 2 % 5 = 2 steps_to_new_tail = length - k - 1 = 2
-
We now need to stop 2 steps before the original tail to get the new tail node.
-
Step 4: Find new tail and break the circle
-
Starting at head (
1), move 2 steps:- Step 1:
2 - Step 2:
3→ this becomes the new tail
- Step 1:
-
new_head = new_tail.next = 4 -
Break the cycle:
new_tail.next = None
-
-
Final Output:
Rotated list = [4, 5, 1, 2, 3]
| Complexity Metric | Value | Explanation |
|---|---|---|
| Time Complexity | One pass to get length + one pass to find new head and tail | |
| Space Complexity | Constant extra space; rotation done in-place |
- This solution rotates the linked list efficiently with O(n) time and O(1) space.
- The list is temporarily made circular to facilitate smooth rotation.
- Modular arithmetic ensures we handle
kvalues larger than list size.