![]()

📖 Documentation • 🔥 Ready-to-Use Recipes • 💡 Examples • Model Coverage • Performance • 🤝 Contributing
- [04/29/2026]Mistral Medium 3.5 We now support finetuning Mistral AI's 128B FP8-native VLM Mistral Medium 3.5. Check out our recipe and guide.
- [04/28/2026]Nemotron-3-Nano-Omni We now support finetuning
nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16, NVIDIA's 30B-A3B omnimodal MoE (text · image · audio) with NemotronH hybrid Mamba+Attention backbone. Check out our SFT recipe, LoRA recipe, and guide. - [04/28/2026]Hy3-preview We now support finetuning
tencent/Hy3-preview, thanks to @Khazic. Check out our recipe. - [04/25/2026]DeepSeek V4 Flash We now support finetuning
deepseek-ai/DeepSeek-V4-Flash, thanks to @Khazic. Check out our recipe and guide. - [04/22/2026]Qwen3.6-27B We now support finetuning
Qwen/Qwen3.6-27B. Check out our recipe. - [04/20/2026]Qwen-Image We now support finetuning
Qwen/Qwen-Image, thanks to @harshareddy832. Check out our recipe. - [04/16/2026]Qwen3.6 MoE We now support finetuning
Qwen/Qwen3.6-35B-A3B. Check out our recipe. - [04/16/2026]LLaVA-OneVision-1.5 We now support finetuning
lmms-lab/LLaVA-OneVision-1.5-4B-Instruct, thanks to @vgauraha62. Check out our recipe. - [04/12/2026]MiniMax-M2.7 We now support finetuning
MiniMaxAI/MiniMax-M2.7. Check out our recipe. - [04/07/2026]GLM-5.1 We now support finetuning
zai-org/GLM-5.1. GLM-5.1 is Zhipu AI's latest open-source MoE model featuring MLA + DeepSeek Sparse Attention. Check out our recipe and discussion. - [04/02/2026]Gemma 4 We support fine-tuning for Gemma4 (2B, 4B, 31B, 26BA4B)! Check out our recipes.
- [03/30/2026]NeMo AutoModel ships with agent-friendly skills in skills/ to help you with common development tasks (e.g., running a recipe, model onboarding, development) across the repo. We welcome PRs that improve existing skills or add new ones.
- [03/16/2026]Mistral Small 4 We support fine-tuning for Mistral4 119B! Check out our recipe.
- [03/11/2026]Nemotron Super v3 We support fine-tuning for
nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16. Check out our recipe. - [03/11/2026]GLM-5 We now support finetuning
zai-org/GLM-5. Check out our recipe. - [03/02/2026]Qwen3.5 small models We support finetuning for Qwen3.5 small models 0.8B, 2B, 4B (recipe) and 9B (recipe)
- [02/16/2026]Qwen3.5 MoE We support finetuning for
Qwen/Qwen3.5-397B-A17B(recipe) andQwen/Qwen3.5-35B-A3B(recipe)
Previous News
- [02/13/2026] MiniMax-M2.5 We support finetuning for
MiniMaxAI/MiniMax-M2.5. Checkout our recipe - [02/11/2026] GLM-4.7-Flash We now support finetuning GLM-4.7-Flash. Checkout our packed sequence recipe
- [02/09/2026] MiniMax-M2 We support finetuning for
MiniMaxAI/MiniMax-M2. Checkout our recipe - [02/06/2026] Qwen3 VL 235B We support finetuning for
Qwen/Qwen3-VL-235B-A22B-Instruct. Checkout our recipe - [02/06/2026] GLM4.7 We now support finetuning GLM4.7. Checkout our recipe
- [02/06/2026] Step3.5-flash is out! Finetune it with our finetune recipe
- [02/05/2026] DeepSeek-V3.2 is out! Checkout out the finetune recipe!
- [02/04/2026] Kimi K2.5 VL is out! Finetune it with NeMo AutoModel
- [01/30/2026] Kimi VL We support fine-tuning for
moonshotai/Kimi-VL-A3B-Instruct. Check out our recipe. - [01/12/2026] Nemotron Flash We support fine-tuning for
nvidia/Nemotron-Flash-1B. Check out our recipe. - [01/12/2026] Nemotron Parse We support fine-tuning
nvidia/NVIDIA-Nemotron-Parse-v1.1(recipe, tutorial and try on Brev). - [01/07/2026] Devstral-Small We support fine-tuning for
mistralai/Devstral-Small-2-24B-Instruct-2512. Check out our recipe. - [12/18/2025] FunctionGemma is out! Finetune it with NeMo AutoModel!
- [12/15/2025] NVIDIA-Nemotron-3-Nano-30B-A3B is out! Finetune it with NeMo AutoModel!
- [11/6/2025] Accelerating Large-Scale Mixture-of-Experts Training in PyTorch
- [10/6/2025] Enabling PyTorch Native Pipeline Parallelism for 🤗 Hugging Face Transformer Models
- [9/22/2025] Fine-tune Hugging Face Models Instantly with Day-0 Support with NVIDIA NeMo AutoModel
- [9/18/2025] 🚀 NeMo Framework Now Supports Google Gemma 3n: Efficient Multimodal Fine-tuning Made Simple
Nemo AutoModel is a Pytorch DTensor‑native SPMD open-source training library under NVIDIA NeMo Framework, designed to streamline and scale training and finetuning for LLMs, VLMs, diffusion models, and retrieval models. Designed for flexibility, reproducibility, and scale, NeMo AutoModel enables both small-scale experiments and massive multi-GPU, multi-node deployments for fast experimentation in research and production environments.
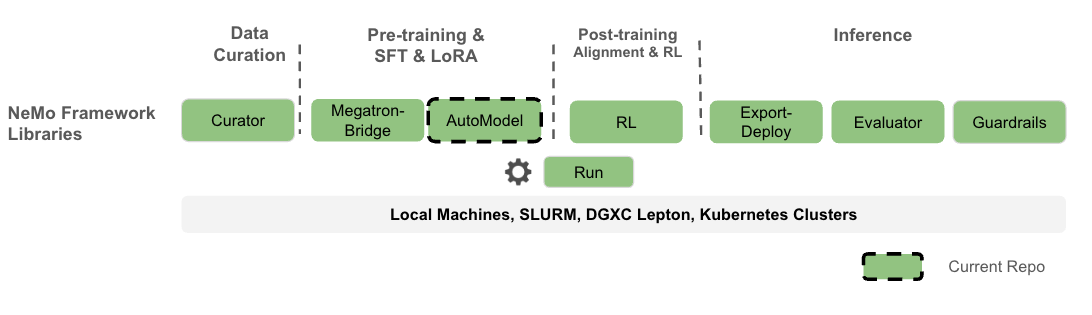
What you can expect:
- Hackable with a modular design that allows easy integration, customization, and quick research prototypes.
- Minimal ceremony: YAML-driven recipes; override any field using CLI.
- High performance and flexibility with custom kernels and DTensor support.
- Seamless integration with Hugging Face for day-0 model support, ease of use, and wide range of supported models.
- Efficient resource management using Kubernetes and Slurm, enabling scalable and flexible deployment across configurations.
- Documentation with step-by-step guides and runnable examples.
- One program, any scale: The same training script runs on 1 GPU or 1000+ by changing the mesh.
- PyTorch Distributed native: Partition model/optimizer states with
DeviceMesh+ placements (Shard,Replicate). - SPMD first: Parallelism is configuration. No model rewrites when scaling up or changing strategy.
- Decoupled concerns: Model code stays pure PyTorch; parallel strategy lives in config.
- Composability: Mix tensor, sequence, and data parallel by editing placements.
- Portability: Fewer bespoke abstractions; easier to reason about failure modes and restarts.
- Feature Roadmap
- Getting Started
- LLM
- VLM
- Supported Models
- Performance
- Interoperability
- Contributing
- License
TL;DR: SPMD turns “how to parallelize” into a runtime layout choice, not a code fork.
✅ Available now (v0.4.0 / 26.04 container) | 🔜 Coming next
High-throughput scalable training
- ✅ PyTorch DTensor-native SPMD training Same training script can scale from 1 GPU to large multi-node jobs by changing the device mesh/config.
- ✅ Composable Parallelism - PyTorch native FSDP2, HSDP, TP, CP, SP and PP for distributed training.
- ✅ Optimized kernels - Uses NVIDIA-oriented kernel paths such as Transformer Engine, DeepEP, FlexAttn, TorchSDPA, fused attention, rotary embeddings, Triton, and optional kernel patches.
- ✅ MoE acceleration - Includes MoE routing and DeepEP integration, plus expert-parallel configurations used in DeepSeek, Qwen MoE, GPT-OSS, and Nemotron MoE benchmarks.
- ✅ FP8 and mixed precision - FP8 support with torchao and Transformer Engine.
- ✅ Activation checkpointing - Trades recomputation for lower activation memory, especially useful with FSDP and memory-efficient losses.
- ✅ Memory-efficient loss - Linear-Cut / fused linear cross entropy avoids materializing full logits for the loss, reducing output-layer memory pressure.
- ✅ Sequence packing - Packs variable-length examples together to reduce padding compute and improve GPU utilization.
- ✅ FlashAttention packed-sequence support - Packed masks can feed variable-length FlashAttention paths using per-document cu_seqlens.
- ✅ DCP - Supports PyTorch DCP and SafeTensors, sharded and consolidated layouts, merge/reshard utilities, and Hugging Face-compatible outputs.
- ✅ Async checkpointing - Can write checkpoints in the background to reduce training stalls caused by I/O.
- ✅ Dion optimizer - Distributed Dion optimizer integration.
- ✅ Environment Support - SLURM, interactive, SkyPilot, and Kubernetes (via SkyPilot) launchers.
SOTA algorithms
- ✅ Pre-training - Support for model pre-training, including DeepSeekV3.
- ✅ Learning Algorithms - SFT (Supervised Fine-Tuning), PEFT (LoRA, QLoRA), and QAT (Quantization-Aware Training).
- ✅ Knowledge Distillation - Support for knowledge distillation with LLMs.**
Model Coverage and 🤗 Ecosystem compatibility
- ✅ Transformers v5 🤗 - Built on latest transformers with device-mesh driven parallelism.
- ✅ 🤗 HuggingFace Integration - Works with dense models (e.g., Qwen, Llama3, etc) and large MoEs (e.g., DSv3, DSv4).
- ✅ VLM - Finetuning for VLMs (Qwen2.5/3/3.5/3.6 VL, Gemma-3/3n/4 VL, Mistral 3.5/4, LLaVA-OneVision-1.5, Kimi-VL, etc.).
- ✅ Omnimodal - Finetuning for omnimodal MoE models (Nemotron-3-Nano-Omni, Qwen3-Omni).
- ✅ Diffusion - Pretraining and LoRA finetuning for image/video diffusion models (Qwen-Image, FLUX, Wan2.1, Hunyuan).
- ✅ dLLM - Discrete diffusion LM finetuning (LLaDA).
- ✅ Retrieval - Bi-encoder and cross-encoder training with in-batch negative sampling.
- ✅ Extended MoE support - GPT-OSS, Qwen3 / Qwen3.5 / Qwen3.6 MoE, Qwen-next, MiniMax-M2.x, GLM-4.7 / GLM-5 / GLM-5.1, DeepSeek V3.2 / V4 / V4-Flash, Hy3-preview.
Agentic Development and UX
-
✅ Agent-friendly skills - Curated
skills/for common dev tasks (recipe runs, model onboarding, CI). -
🔜 Muon optimizer - Muon optimizer support.
-
🔜 SonicMoE - Optimized MoE implementation for faster expert computation.
-
🔜 FP8 MoE - FP8 precision training and inference for MoE models.
-
🔜 Cudagraph with MoE - CUDA graph support for MoE layers to reduce kernel launch overhead.
-
🔜 VLM Knowledge Distillation - Extend KD to VLM and omnimodal models.
We recommend using uv for reproducible Python environments.
# Setup environment before running any recipes
uv venv
# Choose ONE:
uv sync --frozen # LLM recipes (default)
# uv sync --frozen --extra vlm # VLM recipes (fixes: ImportError: qwen_vl_utils is not installed)
# uv sync --frozen --extra cuda # Optional CUDA deps (e.g., Transformer Engine, bitsandbytes)
# uv sync --frozen --extra all # Most optional deps (includes `vlm` and `cuda`)
# uv sync --frozen --all-extras # Everything (includes `fa`, `moe`, etc.)
# One-off runs (examples):
# uv run --extra vlm <command>
# uv run --extra cuda <command>
uv run python -c "import nemo_automodel; print('NeMo AutoModel ready')"All recipes are launched via the automodel CLI (or its short alias am). Each YAML config specifies the recipe class and all training parameters:
# LLM example: multi-GPU fine-tuning with FSDP2
automodel examples/llm_finetune/llama3_2/llama3_2_1b_hellaswag.yaml --nproc-per-node 8
# VLM example: single-GPU fine-tuning (Gemma-3-VL) with LoRA
automodel examples/vlm_finetune/gemma3/gemma3_vl_4b_cord_v2_peft.yaml
# Both commands also work with uv run:
uv run automodel examples/llm_finetune/llama3_2/llama3_2_1b_hellaswag.yaml --nproc-per-node 8Tip
Login-node / CI installs: If you only need to submit jobs (SLURM, k8s, NeMo-Run) and don't need to train locally, install the lightweight CLI package: pip install nemo-automodel[cli]
We provide an example SFT experiment using the FineWeb dataset with a nano-GPT model, ideal for quick experimentation on a single node.
automodel examples/llm_pretrain/nanogpt_pretrain.yaml --nproc-per-node 8We provide an example SFT experiment using the SQuAD dataset.
The default SFT configuration is set to run on a single GPU. To start the experiment:
automodel examples/llm_finetune/llama3_2/llama3_2_1b_squad.yamlThis fine-tunes the Llama3.2-1B model on the SQuAD dataset using a single GPU.
To use multiple GPUs on a single node, add the --nproc-per-node argument:
automodel examples/llm_finetune/llama3_2/llama3_2_1b_squad.yaml --nproc-per-node 8To launch on a SLURM cluster, copy the reference sbatch script and adapt it to your cluster:
cp slurm.sub my_cluster.sub
# Edit my_cluster.sub — change CONFIG, #SBATCH directives, container, mounts, etc.
sbatch my_cluster.subAll cluster-specific settings (nodes, GPUs, partition, container, mounts) live in your sbatch script.
NeMo-Run (nemo_run:) sections are also supported -- see our
cluster guide for details.
We provide a PEFT example using the HellaSwag dataset.
# Memory-efficient SFT with LoRA
automodel examples/llm_finetune/llama3_2/llama3_2_1b_hellaswag_peft.yaml
# Override any YAML parameter via the command line:
automodel examples/llm_finetune/llama3_2/llama3_2_1b_hellaswag_peft.yaml \
--step_scheduler.local_batch_size 16Note
Launching a multi-node PEFT example uses the same sbatch slurm.sub workflow as the SFT case above.
We provide a VLM SFT example using Qwen2.5-VL for end-to-end fine-tuning on image-text data.
# Qwen2.5-VL on 8 GPUs
automodel examples/vlm_finetune/qwen2_5/qwen2_5_vl_3b_rdr.yaml --nproc-per-node 8We provide a VLM PEFT (LoRA) example for memory-efficient adaptation with Gemma3 VLM.
# Gemma-3-VL PEFT on 8 GPUs
automodel examples/vlm_finetune/gemma3/gemma3_vl_4b_medpix_peft.yaml --nproc-per-node 8NeMo AutoModel provides native support for a wide range of models available on the Hugging Face Hub, enabling efficient fine-tuning for various domains. Below is a small sample of ready-to-use families (train as-is or swap any compatible 🤗 causal LM), you can specify nearly any LLM/VLM model available on 🤗 hub:
Note
Check out more LLM and VLM examples. Any causal LM on Hugging Face Hub can be used with the base recipe template, just overwrite --model.pretrained_model_name_or_path <model-id> in the CLI or in the YAML config.
NeMo AutoModel achieves great training performance on NVIDIA GPUs. Below are highlights from our benchmark results:
| Model | #GPUs | Seq Length | Model TFLOPs/sec/GPU | Tokens/sec/GPU | Kernel Optimizations |
|---|---|---|---|---|---|
| DeepSeek V3 671B | 256 | 4096 | 250 | 1,002 | TE + DeepEP |
| GPT-OSS 20B | 8 | 4096 | 279 | 13,058 | TE + DeepEP + FlexAttn |
| Qwen3 MoE 30B | 8 | 4096 | 212 | 11,842 | TE + DeepEP |
For complete benchmark results including configuration details, see the Performance Summary.
- NeMo RL: Use AutoModel checkpoints directly as starting points for DPO/RM/GRPO pipelines.
- Hugging Face: Train any LLM/VLM from 🤗 without format conversion.
- Megatron Bridge: Optional conversions to/from Megatron formats for specific workflows.
NeMo-Automodel/
├── cli/ # `automodel` / `am` CLI entry-point
│ └── app.py
├── docker/ # Container build files
├── docs/ # Documentation and guides
├── examples/
│ ├── convergence/ # Convergence test configs
│ ├── diffusion/ # Diffusion pretrain/finetune configs
│ ├── dllm_sft/ # Discrete diffusion LM SFT configs
│ ├── dllm_generate/ # Discrete diffusion LM generation
│ ├── llm_benchmark/ # LLM benchmarking configs
│ ├── llm_finetune/ # LLM finetune YAML configs
│ ├── llm_kd/ # LLM knowledge-distillation configs
│ ├── llm_pretrain/ # LLM pretrain configs
│ ├── llm_seq_cls/ # LLM sequence classification configs
│ ├── retrieval/ # Bi-encoder / cross-encoder configs
│ ├── vlm_benchmark/ # VLM benchmarking configs
│ ├── vlm_finetune/ # VLM finetune configs
│ └── vlm_generate/ # VLM generation configs
├── nemo_automodel/
│ ├── _diffusers/ # HF Diffusers integration (NeMoAutoDiffusionPipeline)
│ ├── _transformers/ # HF Transformers integration
│ ├── components/ # Core library
│ │ ├── _peft/ # PEFT implementations (LoRA, QLoRA)
│ │ ├── attention/ # Attention implementations
│ │ ├── checkpoint/ # Distributed checkpointing
│ │ ├── config/
│ │ ├── datasets/ # LLM, VLM, diffusion, retrieval datasets
│ │ ├── distributed/ # FSDP2, Megatron FSDP, pipelining, CP, etc.
│ │ ├── launcher/ # Launcher backends (SLURM, NeMo-Run, SkyPilot)
│ │ ├── loggers/ # Loggers
│ │ ├── loss/ # Optimized loss functions
│ │ ├── models/ # User-defined model examples
│ │ ├── moe/ # Optimized kernels for MoE models
│ │ ├── optim/ # Optimizer/LR scheduler components (incl. Dion)
│ │ ├── quantization/ # FP8, QAT, QLoRA
│ │ ├── training/ # Train utils
│ │ └── utils/ # Misc utils
│ ├── recipes/
│ │ ├── llm/ # Main LLM train loop
│ │ ├── vlm/ # Main VLM train loop
│ │ ├── diffusion/ # Diffusion training loop
│ │ ├── dllm/ # Discrete diffusion LM training loop
│ │ └── retrieval/ # Retrieval / biencoder training loop
│ └── shared/
├── tools/ # Developer tooling
└── tests/ # Comprehensive test suite
If you use NeMo AutoModel in your research, please cite it using the following BibTeX entry:
@misc{nemo-automodel,
title = {NeMo AutoModel: DTensor-native SPMD library for scalable and efficient training},
howpublished = {\url{https://github.com/NVIDIA-NeMo/Automodel}},
year = {2025--2026},
note = {GitHub repository},
}
We welcome contributions! Please see our Contributing Guide for details.
NVIDIA NeMo AutoModel is licensed under the Apache License 2.0.