Commit 0d26cdf
Add MXFP8/NVFP4 quantization, quantized model init, collator state, a… (#1572)
## Summary
Builds on top of [PR
#1500](#1500)
(`jm/mxfp8-nvfp4-llama3`) with additional features, CI fixes, and
benchmark documentation for the `llama3_native_te` recipe.
### Key changes on top of PR #1500
- **FusedAdam with FP32 master weights**: Replaces
`MixedPrecisionPolicy` approach with TE's
`FusedAdam(master_weight_dtype=torch.float32)` for mixed-precision
training — simpler, better supported for FP8/MXFP8/NVFP4
- **Quantized model init with `preserve_high_precision_init_val`**:
Stores BF16 copies of init values when using `te.quantized_model_init`,
needed for FP32 master weight seeding in FP8 training
- **Unified per-layer init path**: `get_autocast_context(init=True)` now
works both standalone (model tests, no outer context) and under an outer
`te.quantized_model_init` context (recipe training) — BF16 layers exit
the outer FP8 context via `quantized_model_init(enabled=False)`
- **Layer-wise precision control**: `layer_precision` config allows
per-layer FP8/MXFP8/NVFP4/BF16 assignment (e.g., first/last layer BF16
for stability)
- **NVFP4 support**: Added `NVFP4BlockScaling` recipe alongside MXFP8
- **70B configs**: Added Llama-3.1-70B hydra configs with context
parallelism and THD input format
- **CI test fixes**: Parametrized all FP8 tests across recipes
(DelayedScaling, Float8CurrentScaling, Float8BlockScaling,
MXFP8BlockScaling) with automatic `xfail` for unsupported hardware —
matching existing codebase patterns
- **Restored `is_compileable` property**: Required by HuggingFace
`transformers` `generate()` auto-compile check
- **Hydra config cleanup**: Renamed `7b` → `8b` configs, removed
experiment configs, restored pytest markers
## MXFP8 Performance Benchmarks
### Headline: MXFP8 vs BF16 throughput uplift (single B300 node)
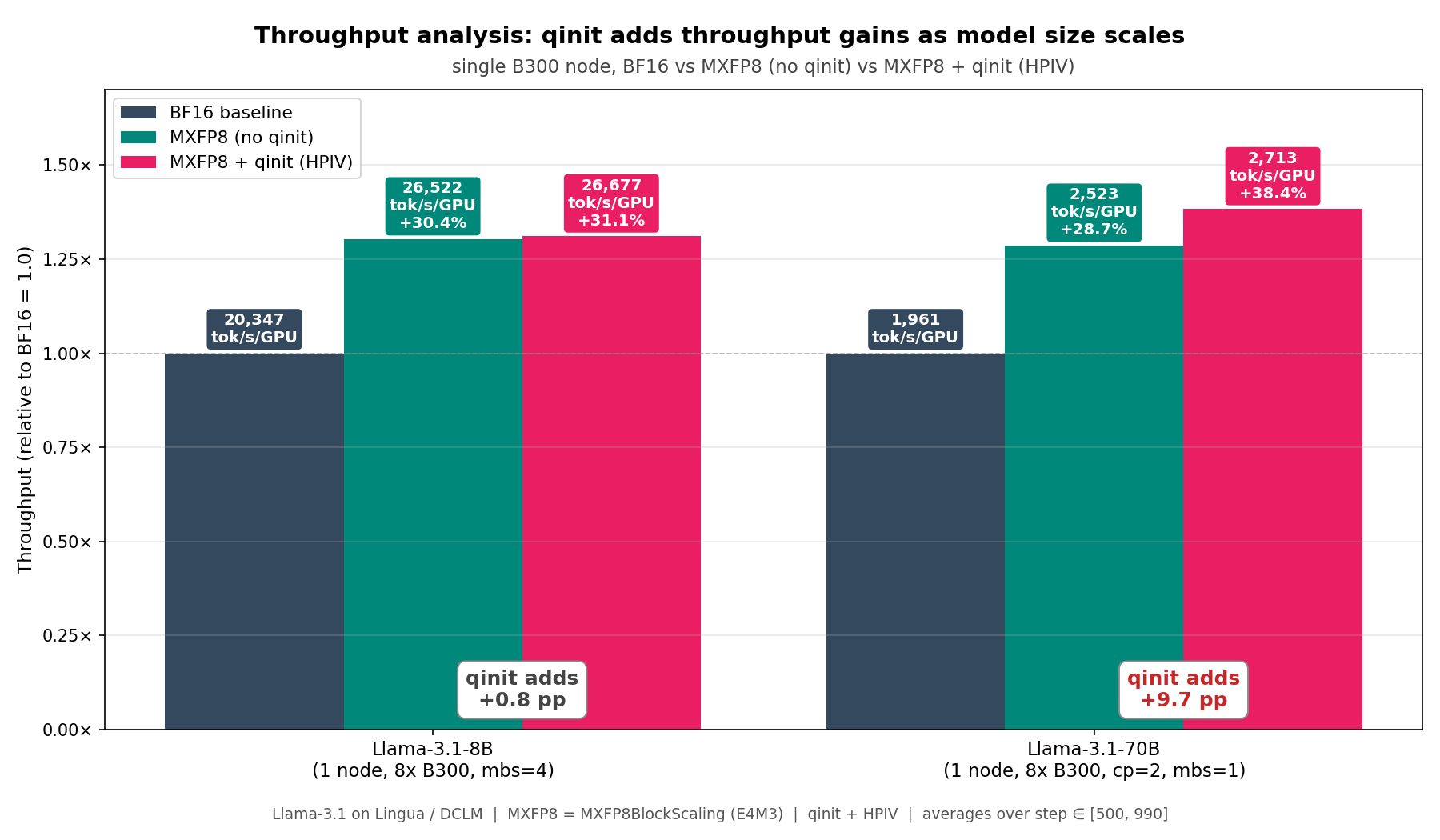
**Key findings:**
- **Single-node:** MXFP8 over BF16 gives ~30% throughput uplift on both
8B and 70B. Quantized model init (`qinit`) adds ~0.8 pp on 8B but **+9.7
pp on 70B** — the per-layer quantize/dequantize work saved by qinit
scales with depth (80 vs 32 layers). On 70B, **MXFP8 + qinit delivers
+38.4% throughput gain over BF16** on a single B300 node.
- **Multi-node 8B** (8 nodes / 64× B200): MXFP8 + qinit reaches **22,517
tokens/s/GPU vs 17,644 BF16 — +27.6% throughput (×1.28 speedup, −21.7%
step time)**.
- **Multi-node 70B** (4 nodes / 32× B200): MXFP8 + qinit reaches **2,725
tokens/s/GPU vs 1,972 BF16 — +38.2% throughput (×1.40 speedup, −27.6%
step time)**. The larger relative gain on 70B vs 8B at scale matches the
size-dependent qinit pattern from single-node.
<details>
<summary><strong>Single-node detail: per-model 3-way
comparisons</strong></summary>
**Llama-3.1-8B** (1 node / 8× B300 SXM6 AC, mbs=4, gbs=32 seqs / 262k
tokens, seq_len=8192):
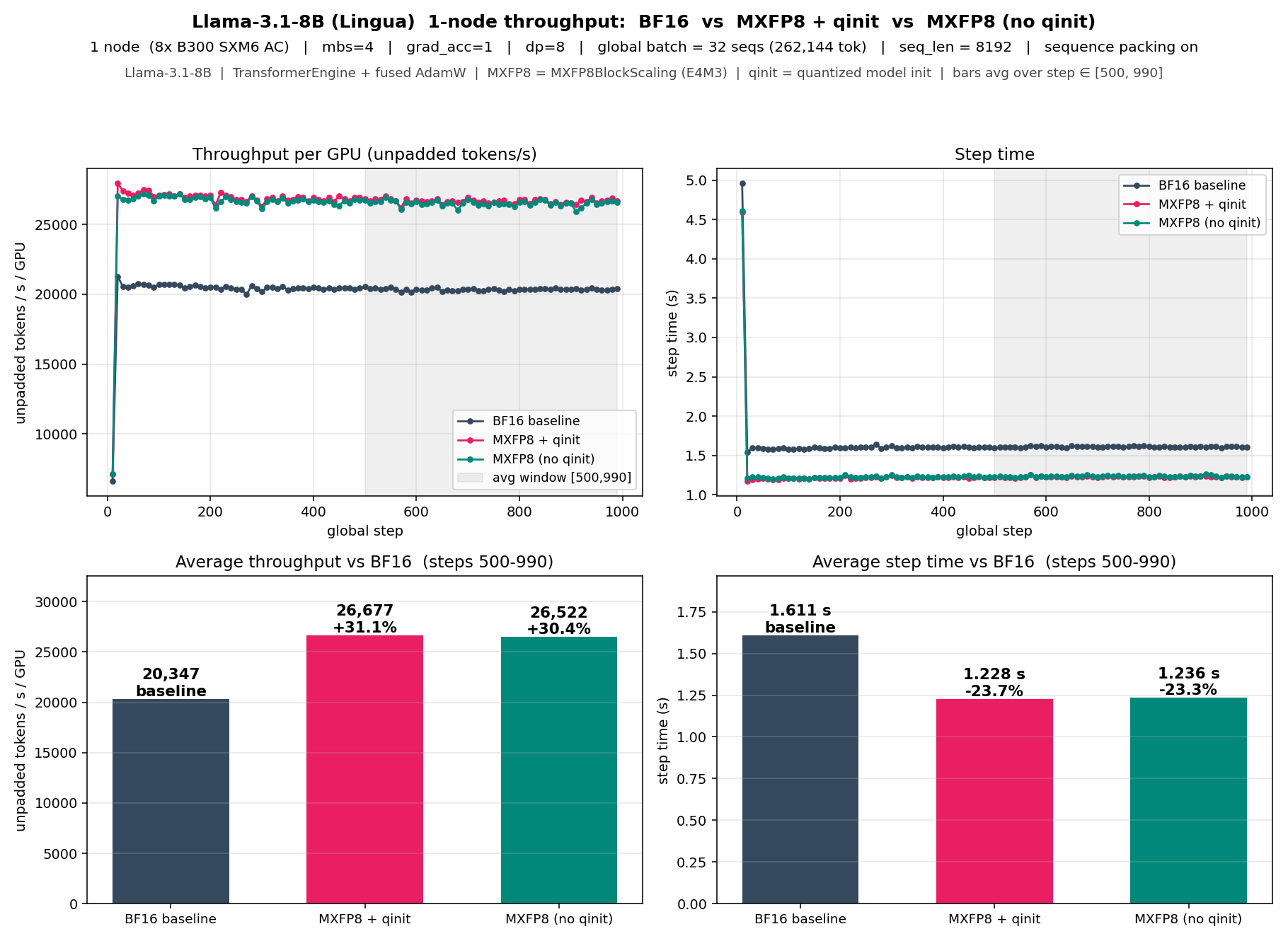
MXFP8 + qinit (+31.1%) and MXFP8 without qinit (+30.4%) deliver
essentially the same throughput gain — at 32 layers the per-layer
quantize/dequantize saving is small.
**Llama-3.1-70B** (1 node / 8× B300 SXM6 AC, mbs=1, cp=2, dp=4, gbs=4
seqs, seq_len=8192):
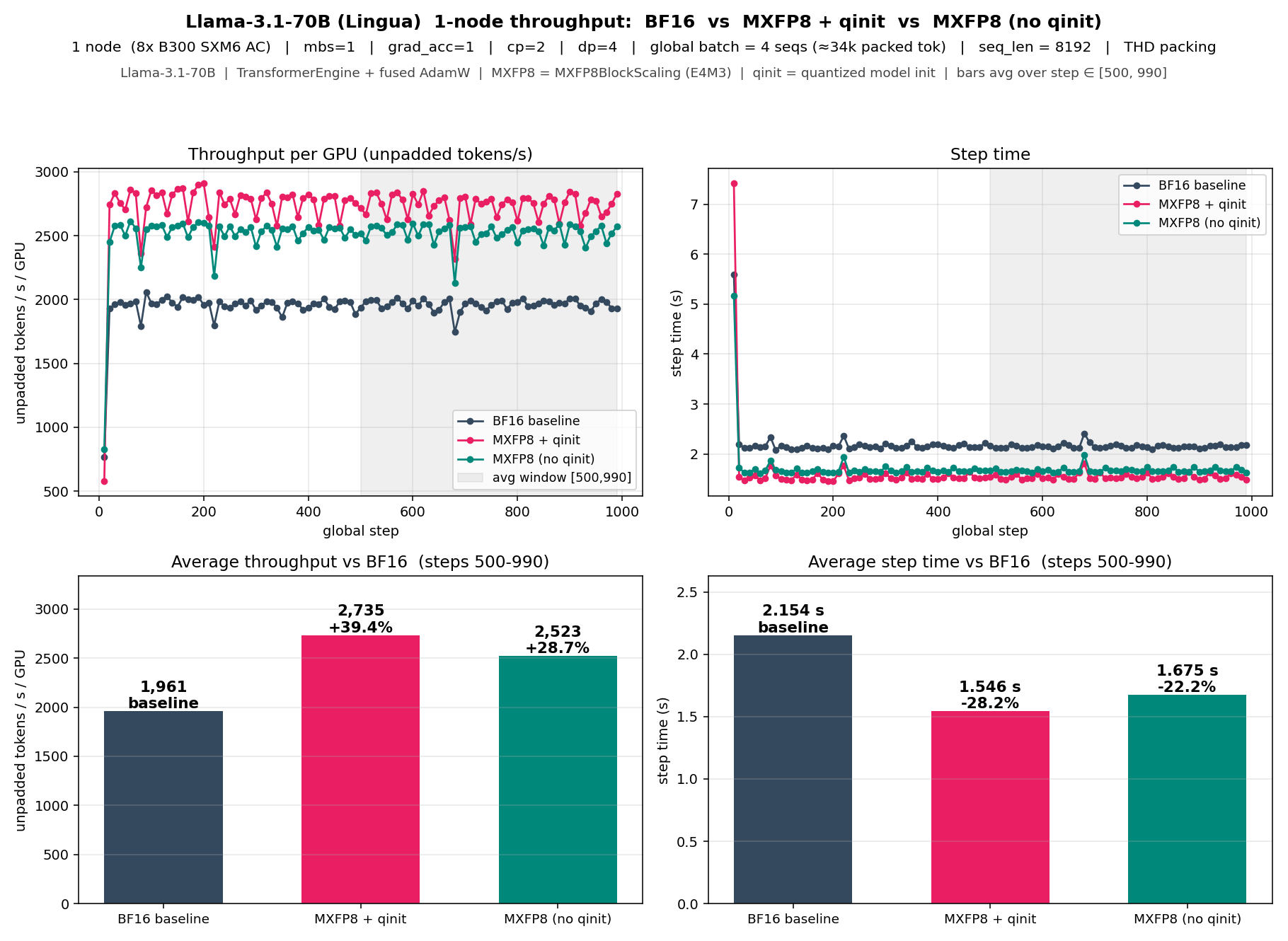
MXFP8 + qinit (+39.4%) pulls ahead of MXFP8 without qinit (+28.7%) — a
~10 pp gap that doesn't appear at 8B. With 80 transformer layers,
avoiding per-step quantize/dequantize adds up.
`preserve_high_precision_init_val=True` (HPIV) is within 1% of
qinit-without-HPIV, so HPIV is essentially free at steady state.
</details>
<details>
<summary><strong>Multi-node throughput (B200, production-scale
runs)</strong></summary>
**Llama-3.1-8B** (8 nodes / 64× B200, mbs=2, grad_acc=2, gbs=256,
seq_len=8192):
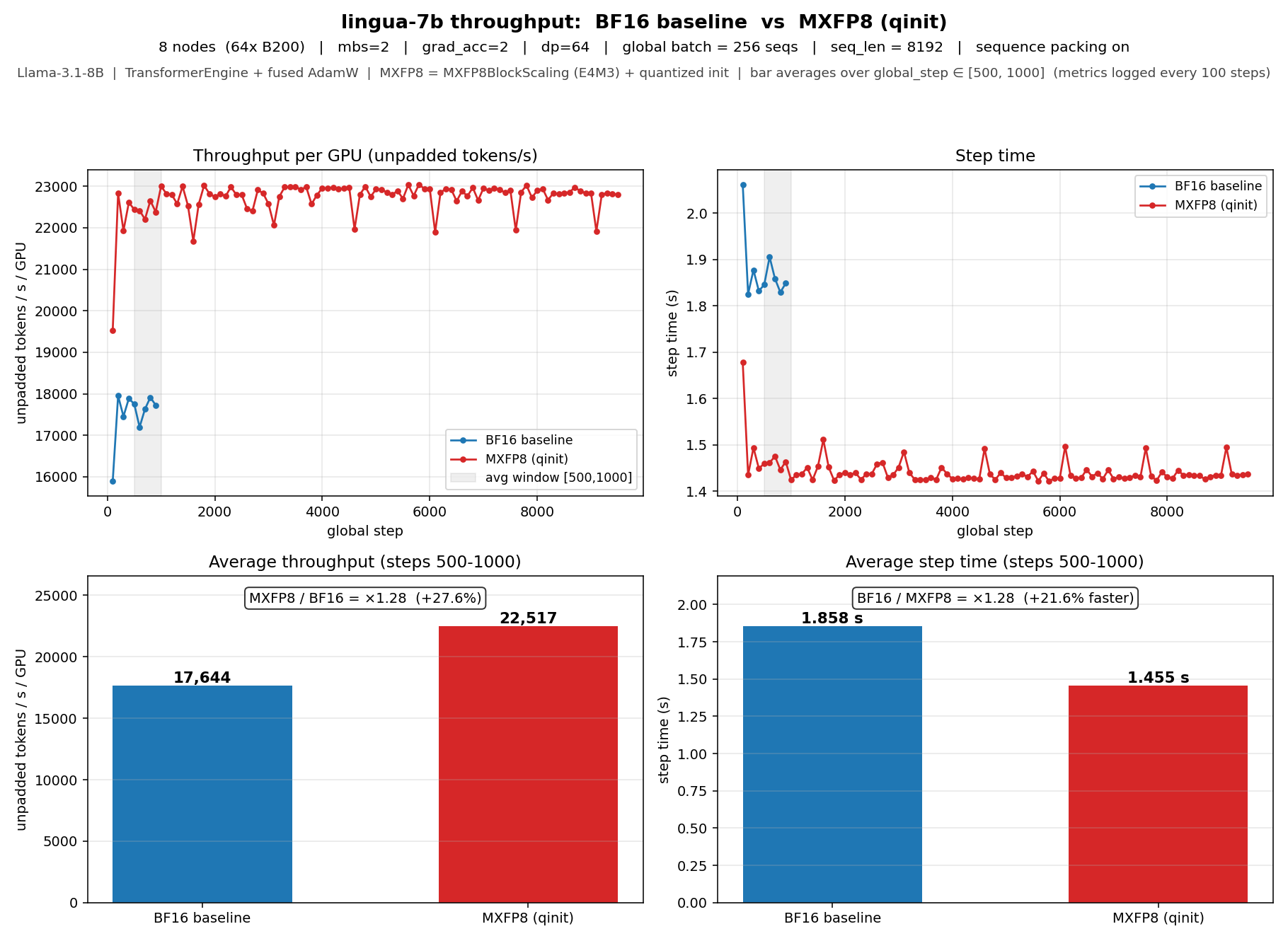
MXFP8 + qinit: **22,517 tokens/s/GPU vs 17,644 BF16 — +27.6% throughput
(×1.28 speedup)**
**Llama-3.1-70B** (4 nodes / 32× B200, cp=2, dp=16, mbs=1, gbs=16,
seq_len=8192):
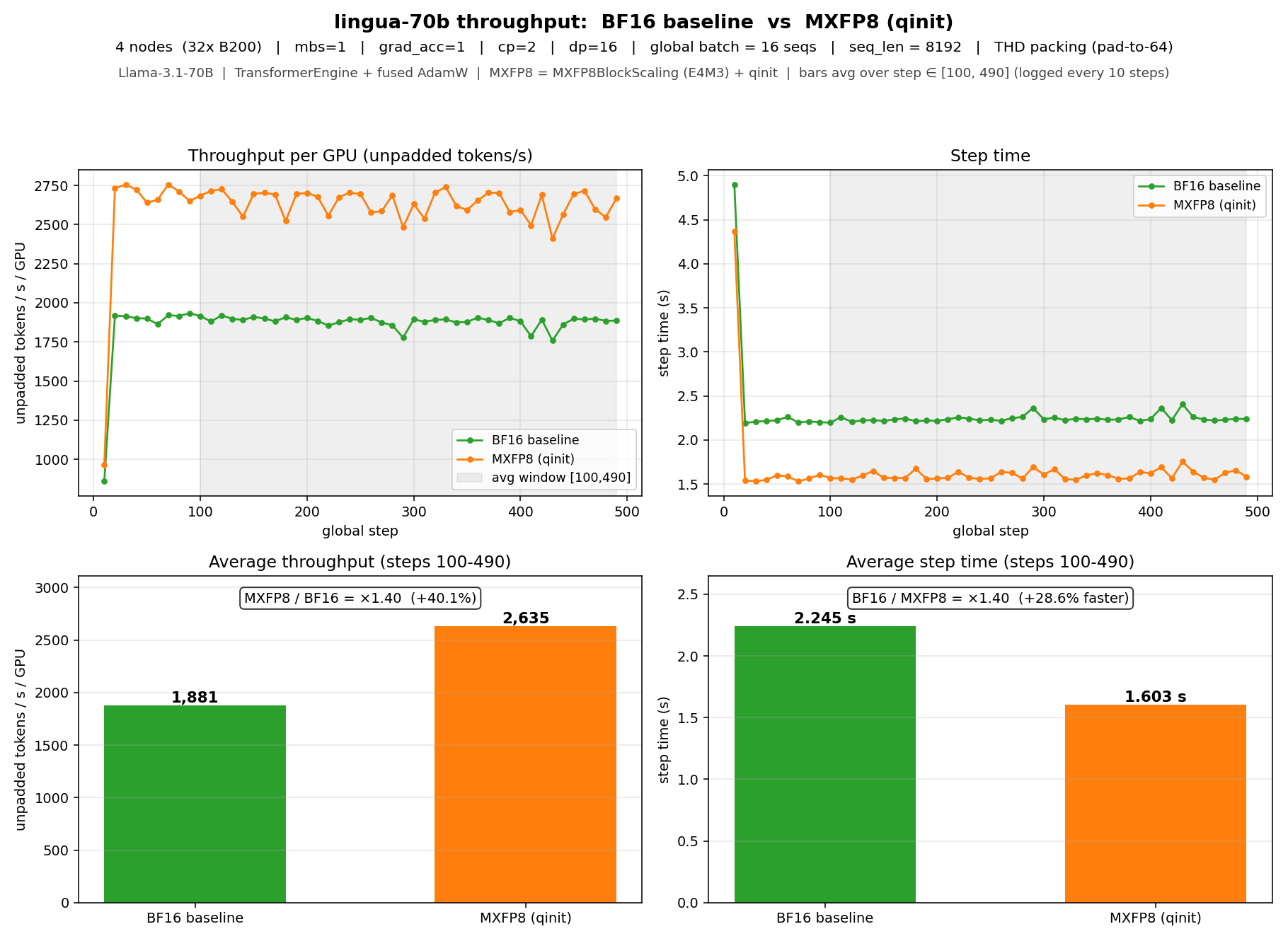
MXFP8 + qinit: **2,725 tokens/s/GPU vs 1,972 BF16 — +38.2% throughput
(×1.40 speedup)**
</details>
<details>
<summary><strong>Wandb run links</strong></summary>
- Single-node 8B —
[BF16](https://wandb.ai/clara-discovery/lingua-7b/runs/lingua_7b_bf16_mbs4_1n_bia)
/ [MXFP8 +
qinit](https://wandb.ai/clara-discovery/lingua-7b/runs/lingua_7b_mxfp8_qinit_mbs4_1n_bia)
/ [MXFP8 (no
qinit)](https://wandb.ai/clara-discovery/lingua-7b/runs/lingua_7b_mxfp8_no_qinit_mbs4_1n_bia)
- Single-node 70B —
[BF16](https://wandb.ai/clara-discovery/lingua-70b/runs/lingua_70b_bf16_mbs1_1n_1k_bia)
/ [MXFP8 +
qinit](https://wandb.ai/clara-discovery/lingua-70b/runs/lingua_70b_mxfp8_qinit_mbs1_1n_1k_bia)
/ [MXFP8 + qinit +
HPIV](https://wandb.ai/clara-discovery/lingua-70b/runs/lingua_70b_mxfp8_qinit_hpiv_mbs1_1n_1k_bia)
/ [MXFP8 (no
qinit)](https://wandb.ai/clara-discovery/lingua-70b/runs/lingua_70b_mxfp8_no_qinit_mbs1_1n_1k_bia)
- Multi-node 8B —
[BF16](https://wandb.ai/clara-discovery/lingua-7b/runs/lingua-7b-bf16-baseline)
/ [MXFP8 +
qinit](https://wandb.ai/clara-discovery/lingua-7b/runs/lingua_7b_mxfp8_qinit_v6_te_main_8n_prenyx)
- Multi-node 70B —
[BF16](https://wandb.ai/clara-discovery/lingua-70b/runs/lingua_70b_bf16_thd_fusedadam_4n_cp2_bia)
/ [MXFP8 +
qinit](https://wandb.ai/clara-discovery/lingua-70b/runs/lingua_70b_mxfp8_qinit_thd_fusedadam_4n_cp2_bia)
</details>
## Test plan
- [x] All existing model-level tests pass (parametrized across
DelayedScaling, Float8CurrentScaling, Float8BlockScaling,
MXFP8BlockScaling with xfail for unsupported hardware)
- [x] All existing recipe-level tests pass (same parametrization
pattern)
- [x] `test_quantized_model_init.py` — 4 tests × 4 recipes = 16 test
cases (8 pass on L4, 8 xfail for Hopper/Blackwell-only recipes)
- [x] `check_copied_files.py` passes — all 3 `modeling_llama_te.py`
copies are identical
- [x] Pre-commit hooks pass
- [ ] Single-node MXFP8 training verified on Blackwell (benchmarked, see
above)
- [ ] Multi-node training verified on B200 cluster (benchmarked, see
above)
### Type of changes
- [x] New feature (non-breaking change which adds functionality)
### CI Pipeline Configuration
-
[ciflow:all-recipes](https://github.com/NVIDIA/bionemo-framework/blob/main/docs/docs/main/contributing/contributing.md#ciflow:all-recipes)
- Run tests for all recipes
> [!NOTE]
> By default, only basic unit tests are run. Add appropriate labels to
enable additional test coverage.
---------
Signed-off-by: Savitha Srinivasan <savithas@nvidia.com>
Co-authored-by: Claude Opus 4.6 <noreply@anthropic.com>{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 parent 3a9d005 commit 0d26cdf
39 files changed
Lines changed: 2576 additions & 192 deletions
File tree
- bionemo-recipes
- models/llama3
- tests
- recipes
- llama3_native_te
- hydra_config
- model_configs/meta-llama
- Llama-3.1-70B
- Llama-3.1-8B
- tests
- opengenome2_llama_native_te
- docs/docs/assets/images/llama3
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
52 | 52 | | |
53 | 53 | | |
54 | 54 | | |
| 55 | + | |
55 | 56 | | |
56 | 57 | | |
57 | 58 | | |
| |||
217 | 218 | | |
218 | 219 | | |
219 | 220 | | |
| 221 | + | |
| 222 | + | |
| 223 | + | |
220 | 224 | | |
221 | 225 | | |
222 | 226 | | |
223 | 227 | | |
224 | 228 | | |
| 229 | + | |
| 230 | + | |
| 231 | + | |
| 232 | + | |
| 233 | + | |
| 234 | + | |
| 235 | + | |
| 236 | + | |
| 237 | + | |
| 238 | + | |
| 239 | + | |
| 240 | + | |
| 241 | + | |
| 242 | + | |
| 243 | + | |
| 244 | + | |
| 245 | + | |
| 246 | + | |
| 247 | + | |
| 248 | + | |
| 249 | + | |
| 250 | + | |
| 251 | + | |
| 252 | + | |
| 253 | + | |
| 254 | + | |
| 255 | + | |
| 256 | + | |
| 257 | + | |
| 258 | + | |
| 259 | + | |
| 260 | + | |
| 261 | + | |
| 262 | + | |
| 263 | + | |
| 264 | + | |
| 265 | + | |
| 266 | + | |
| 267 | + | |
| 268 | + | |
225 | 269 | | |
226 | 270 | | |
227 | 271 | | |
| |||
298 | 342 | | |
299 | 343 | | |
300 | 344 | | |
301 | | - | |
302 | | - | |
| 345 | + | |
| 346 | + | |
| 347 | + | |
| 348 | + | |
303 | 349 | | |
304 | 350 | | |
305 | 351 | | |
306 | | - | |
| 352 | + | |
307 | 353 | | |
308 | 354 | | |
309 | 355 | | |
| |||
363 | 409 | | |
364 | 410 | | |
365 | 411 | | |
366 | | - | |
367 | | - | |
| 412 | + | |
| 413 | + | |
| 414 | + | |
| 415 | + | |
368 | 416 | | |
369 | 417 | | |
370 | 418 | | |
| |||
583 | 631 | | |
584 | 632 | | |
585 | 633 | | |
| 634 | + | |
| 635 | + | |
| 636 | + | |
| 637 | + | |
| 638 | + | |
586 | 639 | | |
587 | 640 | | |
588 | 641 | | |
| |||
591 | 644 | | |
592 | 645 | | |
593 | 646 | | |
594 | | - | |
595 | | - | |
596 | | - | |
597 | | - | |
598 | | - | |
| |||
Lines changed: 243 additions & 0 deletions
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
| 1 | + | |
| 2 | + | |
| 3 | + | |
| 4 | + | |
| 5 | + | |
| 6 | + | |
| 7 | + | |
| 8 | + | |
| 9 | + | |
| 10 | + | |
| 11 | + | |
| 12 | + | |
| 13 | + | |
| 14 | + | |
| 15 | + | |
| 16 | + | |
| 17 | + | |
| 18 | + | |
| 19 | + | |
| 20 | + | |
| 21 | + | |
| 22 | + | |
| 23 | + | |
| 24 | + | |
| 25 | + | |
| 26 | + | |
| 27 | + | |
| 28 | + | |
| 29 | + | |
| 30 | + | |
| 31 | + | |
| 32 | + | |
| 33 | + | |
| 34 | + | |
| 35 | + | |
| 36 | + | |
| 37 | + | |
| 38 | + | |
| 39 | + | |
| 40 | + | |
| 41 | + | |
| 42 | + | |
| 43 | + | |
| 44 | + | |
| 45 | + | |
| 46 | + | |
| 47 | + | |
| 48 | + | |
| 49 | + | |
| 50 | + | |
| 51 | + | |
| 52 | + | |
| 53 | + | |
| 54 | + | |
| 55 | + | |
| 56 | + | |
| 57 | + | |
| 58 | + | |
| 59 | + | |
| 60 | + | |
| 61 | + | |
| 62 | + | |
| 63 | + | |
| 64 | + | |
| 65 | + | |
| 66 | + | |
| 67 | + | |
| 68 | + | |
| 69 | + | |
| 70 | + | |
| 71 | + | |
| 72 | + | |
| 73 | + | |
| 74 | + | |
| 75 | + | |
| 76 | + | |
| 77 | + | |
| 78 | + | |
| 79 | + | |
| 80 | + | |
| 81 | + | |
| 82 | + | |
| 83 | + | |
| 84 | + | |
| 85 | + | |
| 86 | + | |
| 87 | + | |
| 88 | + | |
| 89 | + | |
| 90 | + | |
| 91 | + | |
| 92 | + | |
| 93 | + | |
| 94 | + | |
| 95 | + | |
| 96 | + | |
| 97 | + | |
| 98 | + | |
| 99 | + | |
| 100 | + | |
| 101 | + | |
| 102 | + | |
| 103 | + | |
| 104 | + | |
| 105 | + | |
| 106 | + | |
| 107 | + | |
| 108 | + | |
| 109 | + | |
| 110 | + | |
| 111 | + | |
| 112 | + | |
| 113 | + | |
| 114 | + | |
| 115 | + | |
| 116 | + | |
| 117 | + | |
| 118 | + | |
| 119 | + | |
| 120 | + | |
| 121 | + | |
| 122 | + | |
| 123 | + | |
| 124 | + | |
| 125 | + | |
| 126 | + | |
| 127 | + | |
| 128 | + | |
| 129 | + | |
| 130 | + | |
| 131 | + | |
| 132 | + | |
| 133 | + | |
| 134 | + | |
| 135 | + | |
| 136 | + | |
| 137 | + | |
| 138 | + | |
| 139 | + | |
| 140 | + | |
| 141 | + | |
| 142 | + | |
| 143 | + | |
| 144 | + | |
| 145 | + | |
| 146 | + | |
| 147 | + | |
| 148 | + | |
| 149 | + | |
| 150 | + | |
| 151 | + | |
| 152 | + | |
| 153 | + | |
| 154 | + | |
| 155 | + | |
| 156 | + | |
| 157 | + | |
| 158 | + | |
| 159 | + | |
| 160 | + | |
| 161 | + | |
| 162 | + | |
| 163 | + | |
| 164 | + | |
| 165 | + | |
| 166 | + | |
| 167 | + | |
| 168 | + | |
| 169 | + | |
| 170 | + | |
| 171 | + | |
| 172 | + | |
| 173 | + | |
| 174 | + | |
| 175 | + | |
| 176 | + | |
| 177 | + | |
| 178 | + | |
| 179 | + | |
| 180 | + | |
| 181 | + | |
| 182 | + | |
| 183 | + | |
| 184 | + | |
| 185 | + | |
| 186 | + | |
| 187 | + | |
| 188 | + | |
| 189 | + | |
| 190 | + | |
| 191 | + | |
| 192 | + | |
| 193 | + | |
| 194 | + | |
| 195 | + | |
| 196 | + | |
| 197 | + | |
| 198 | + | |
| 199 | + | |
| 200 | + | |
| 201 | + | |
| 202 | + | |
| 203 | + | |
| 204 | + | |
| 205 | + | |
| 206 | + | |
| 207 | + | |
| 208 | + | |
| 209 | + | |
| 210 | + | |
| 211 | + | |
| 212 | + | |
| 213 | + | |
| 214 | + | |
| 215 | + | |
| 216 | + | |
| 217 | + | |
| 218 | + | |
| 219 | + | |
| 220 | + | |
| 221 | + | |
| 222 | + | |
| 223 | + | |
| 224 | + | |
| 225 | + | |
| 226 | + | |
| 227 | + | |
| 228 | + | |
| 229 | + | |
| 230 | + | |
| 231 | + | |
| 232 | + | |
| 233 | + | |
| 234 | + | |
| 235 | + | |
| 236 | + | |
| 237 | + | |
| 238 | + | |
| 239 | + | |
| 240 | + | |
| 241 | + | |
| 242 | + | |
| 243 | + | |
0 commit comments