Commit 631143d
## Summary
Phase 1 of #225: a single-image → componentized `ui_kit/` decomposition
pipeline that emits a coding-agent-ready bundle, plus deterministic +
vision verifiers that self-check parity using a 12-question boolean
rubric and re-iterate on gaps. Uses existing `userImages` plumbing (PR
#193) and adds three new agent tools that mirror existing patterns
(`done.ts` / `generate-image-asset.ts`). Ends in the chat sidebar with a
one-click trigger that fires a structured prompt, walks the agent
through decompose → verify → reconcile → done, and surfaces
per-decompose cost as a toast. No new prod deps, no SQLite schema
change, in-memory output via the Files panel.
This PR addresses Phase 1 of #225 only. The Phase 2 (gpt-image-2
generation in the loop) and Phase 3 (multi-page flow) cuts I committed
to in the issue thread are intentionally not included.
## 2026-06-06 rebase update
Rebased onto current `OpenCoworkAI/open-codesign:main` at `b2d020d` and
force-pushed the PR branch to `eed7cbc`. GitHub now reports the PR as
mergeable again.
The conflict resolution preserves current `main` architecture:
- `packages/core/src/index.ts` keeps the current `inspect_workspace`
public exports and only appends the visual parity types/functions. The
legacy `read_design_system` core public export was not restored.
- Generate IPC wiring now lives in
`apps/desktop/src/main/ipc/generate.ts`; runtime FS source-image seeding
lives in `apps/desktop/src/main/ipc/runtime-fs.ts`.
- Renderer cost-toast logic now lives in the sliced store at
`apps/desktop/src/renderer/src/store/slices/chat.ts`.
- The first image attachment is seeded as `source.png` for
`verify_ui_kit_visual_parity`, with regression coverage in
`apps/desktop/src/main/index.workspace.test.ts`.
Local verification after rebase:
- `pnpm lint`
- `pnpm --filter @open-codesign/core typecheck`
- `pnpm --filter @open-codesign/desktop typecheck`
- `pnpm --filter @open-codesign/core test`
- `pnpm --filter @open-codesign/desktop test --
src/main/index.workspace.test.ts
src/main/ipc/generate.workspace-rename.test.ts`
- `pnpm --filter @open-codesign/providers test`
Note: local pre-push full `pnpm test` hit a transient timeout in
`packages/providers/src/codex/oauth-server.test.ts` during the
concurrent turbo run; the same providers test passed immediately when
rerun directly. GitHub CI is now the source of truth for the full matrix
on the pushed head.
## Type of change
- [x] New feature
## Linked issue
Refs #225 (Phase 1 only — Phase 2/3 deferred per [my
comment](#225 (comment)))
## What's in here
**3 new agent tools** in `packages/core/src/tools/`:
1. `decompose-to-ui-kit.ts` — orchestrator. Takes a source image (from
chat context) + design brief, emits `ui_kits/<slug>/{index.html,
components/*.tsx, tokens.css, manifest.json, README.md}` to the virtual
FS. Output carries `schemaVersion: 1` so downstream coding agents
(Claude Code, Cursor) can evolve safely.
2. `verify-ui-kit-parity.ts` — deterministic verifier. 3 signals:
element-count parity, visible-text coverage, token coverage. Returns a
`ParityReport` with `passCount/totalChecks` derived score (no LLM in the
loop, no floats).
3. `verify-ui-kit-visual-parity.ts` — vision-LLM judge wrapper. Takes a
host-injected `judgeVisualParity` callback, runs a 12-check boolean
rubric across 5 dimensions (layout / color / typography / content /
components), returns `parityScore = passCount / totalChecks` and a
bounded-enum `status` (`verified | needs_review | needs_iteration |
failed | unavailable`).
**Host wiring** in `apps/desktop/src/main/`:
- `render-ui-kit.ts` — offscreen `BrowserWindow.capturePage()` for the
rendered ui_kit
- `judge-visual-parity.ts` — vision-judge prompt builder + LLM
dispatcher using the existing `complete()` provider abstraction
- `ipc/generate.ts` — injects `renderUiKit` + `judgeVisualParity` into
the agent runtime alongside `generate_image_asset`
- `ipc/runtime-fs.ts` — seeds image attachments into the runtime FS,
including default `source.png` for visual parity
**Renderer**:
- `AddMenu.tsx` — new "Decompose to UI Kit" entry, disabled when no
artifact / generation in flight
- `Sidebar.tsx` — `triggerDecompose(designId, locale)` action wired to
the menu item
- `store.ts` / `store/slices/chat.ts` — 3-branch toast feedback (busy /
unavailable / started) + per-tool-call cost row when the visual judge
resolves
- `hooks/decomposePrompt.ts` — locale-aware (EN/ZH) structured prompt
that walks the agent through decompose → verify → reconcile → iterate
(max 2) → done with HONEST cost summary
**Tests** — full vitest coverage in `*.test.ts` next to each tool:
- `decompose-to-ui-kit.test.ts` (263 LOC)
- `verify-ui-kit-parity.test.ts` (180 LOC)
- `verify-ui-kit-visual-parity.test.ts` (295 LOC)
**i18n** — 9 new keys × EN + ZH for the menu entry, toast
titles/descriptions, and cost row.
## Design decisions
**Boolean rubric, not floats.** Every visual parity check is `{passed:
boolean}`, derived `parityScore = passCount / totalChecks`. The `status`
field is a bounded enum derived from thresholds (100% → `verified`, ≥85%
→ `needs_review`, ≥60% → `needs_iteration`, <60% → `failed`). No
LLM-fabricated confidence floats, no scoring inflation. Aligns with the
project's `HONEST_SCORES` precedent (`done.ts`'s `verified: boolean`
field).
**Host-injected callbacks, not framework lock-in.**
`verify-ui-kit-visual-parity.ts` doesn't import any LLM SDK or any
Electron API. It takes `RenderUiKitFn` and `JudgeVisualParityFn` as
deps. If the host doesn't inject them (e.g. a future headless CLI), the
tool returns `status: 'unavailable'` honestly instead of crashing.
Mirrors how `generate_image_asset` is keyed on
`deps.generateImageAsset`.
**In-memory output via Files panel, no schema bump.** Per my open binary
in the issue thread, this PR ships option (a): the `ui_kits/<slug>/`
lands in the design's virtual FS, surfaces in the existing Files panel,
and uses the existing ZIP export for handoff to a coding agent. No
SQLite migration, smallest blast radius, consistent with how
`polishPrompt.ts`'s second-pass mutates only in-memory state.
**`schemaVersion: 1` on the manifest.** Downstream consumers (Claude
Code, Cursor) need a stable contract. Adding fields requires no version
bump; renaming or removing fields requires `schemaVersion: 2` and a
parallel-emit window.
## Anti-hallucination guardrails
The deterministic verifier (`verify-ui-kit-parity.ts`) checks
visible-text coverage on the emitted ui_kit vs the source brief — if the
agent dropped any text content, it fails BEFORE the LLM judge runs. This
catches data hallucination cheap. The LLM judge then handles only
semantic-quality dimensions (visual hierarchy, color harmony, typography
pairing, etc.).
## Cost surfacing
Every `verify_ui_kit_visual_parity` resolution pushes a toast with
`passCount/totalChecks · status · $cost.NNNN`. Reads defensively from
`result.details` so future contract drift degrades silently rather than
crashing the renderer. The `done` tool's prompt-driven summary
additionally requires the agent to report total run cost, per the
`HONEST_STATUS` precedent.
## Checklist
- [x] I read [`docs/VISION.md`](../docs/VISION.md),
[`docs/PRINCIPLES.md`](../docs/PRINCIPLES.md), and
[`CLAUDE.md`](../CLAUDE.md) before starting
- [x] Commits are signed with DCO (`git commit -s`)
- [x] Rebased onto current `main`; `pnpm lint`, targeted typechecks,
core test, desktop runtime/generate tests, and providers test pass
locally (full GitHub CI is re-running on `eed7cbc`)
- [x] Added/updated tests for the change (738 LOC across 3 new test
files)
- [x] Added a changeset (`pnpm changeset`) — see
`.changeset/decompose-to-ui-kit.md`
- [x] Updated docs if behavior changed — `BENCHMARKS.md` (new),
`README.md` + `README.zh-CN.md` (Decompose to UI Kit feature card + hero
PNG + iter-reel GIF)
## Dependency additions (if any)
None. All three new tools use only `@mariozechner/pi-agent-core`'s
`AgentTool` factory pattern that's already a prod dep.
## Screenshots / recordings (UI changes)
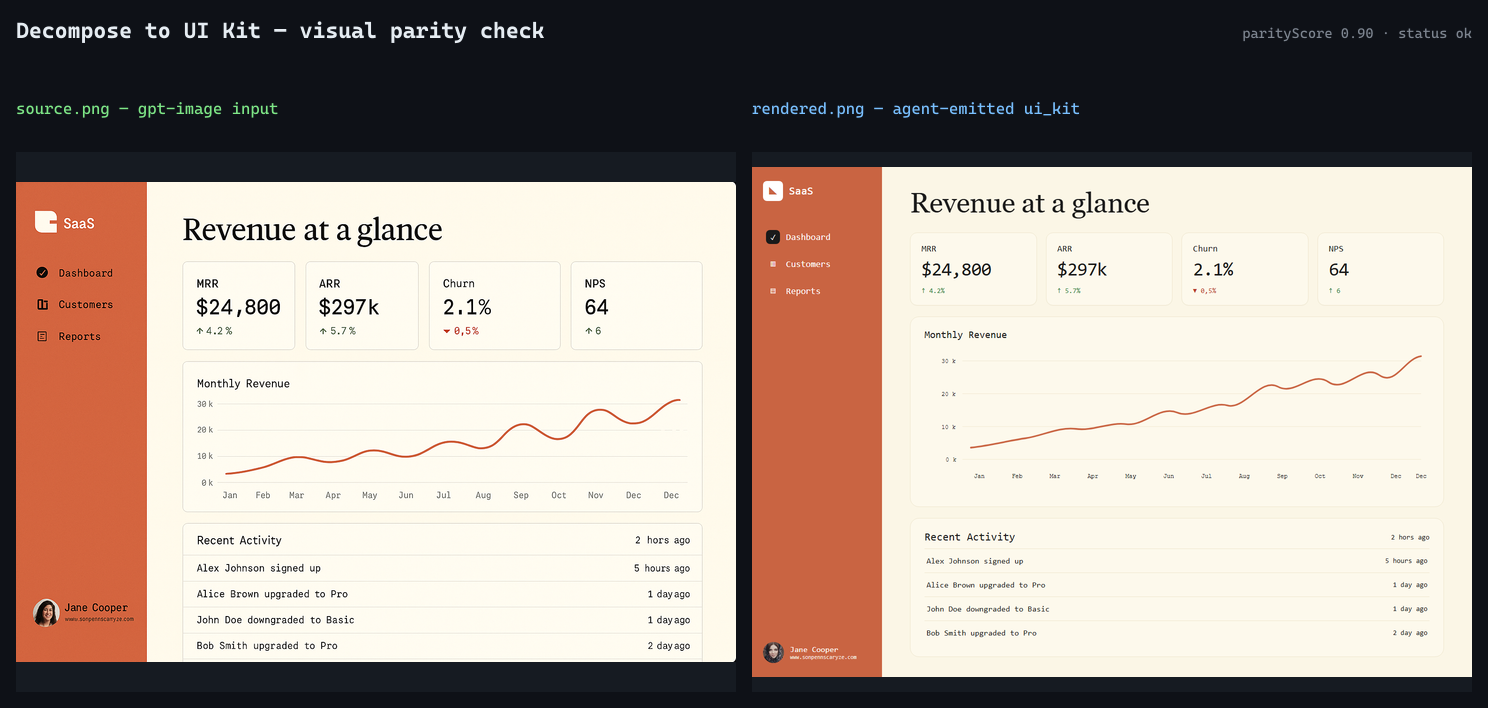
**Side-by-side hero — source vs agent-emitted ui_kit (`e2e-opus-final`
run, parityScore 0.90):**
**4-frame reconcile reel from the `e2e-nodebench-iter` run (iter-0 →
iter-1 with honest score drift 0.82 → 0.78 — boolean rubric exposes the
regression instead of hiding it):**
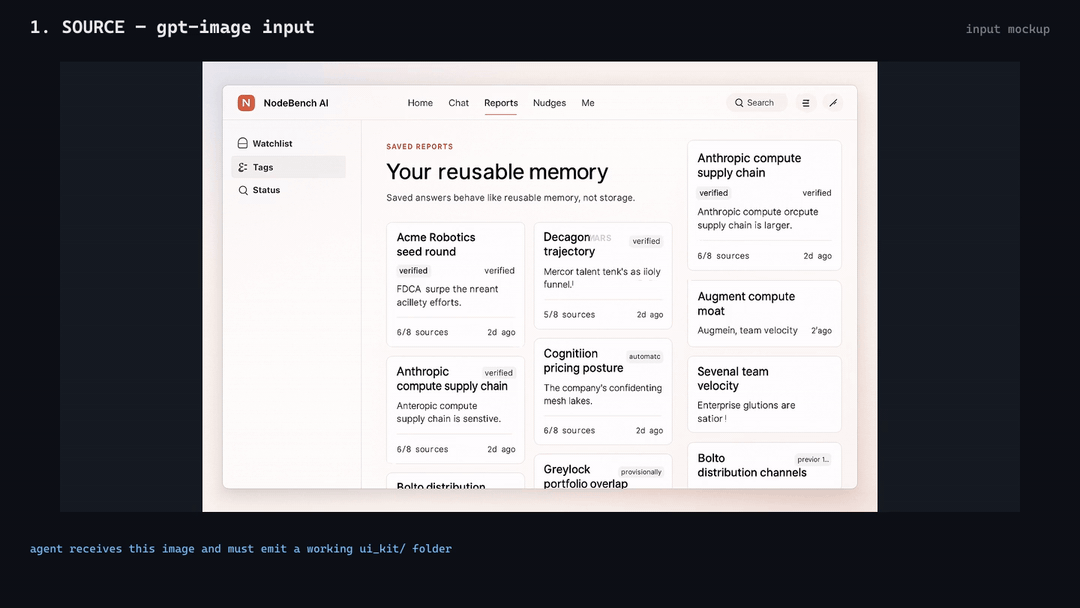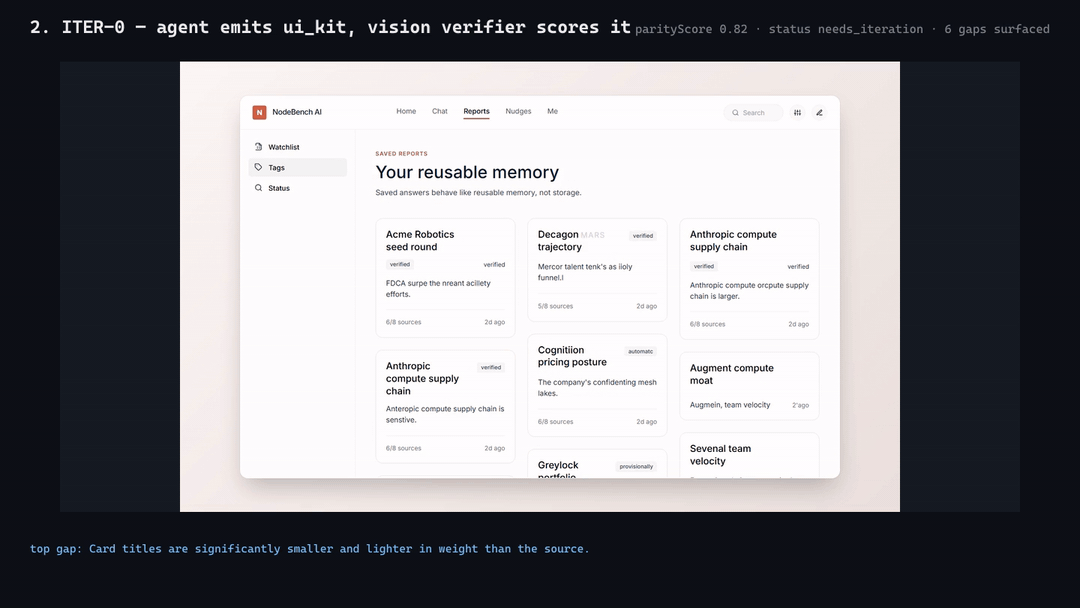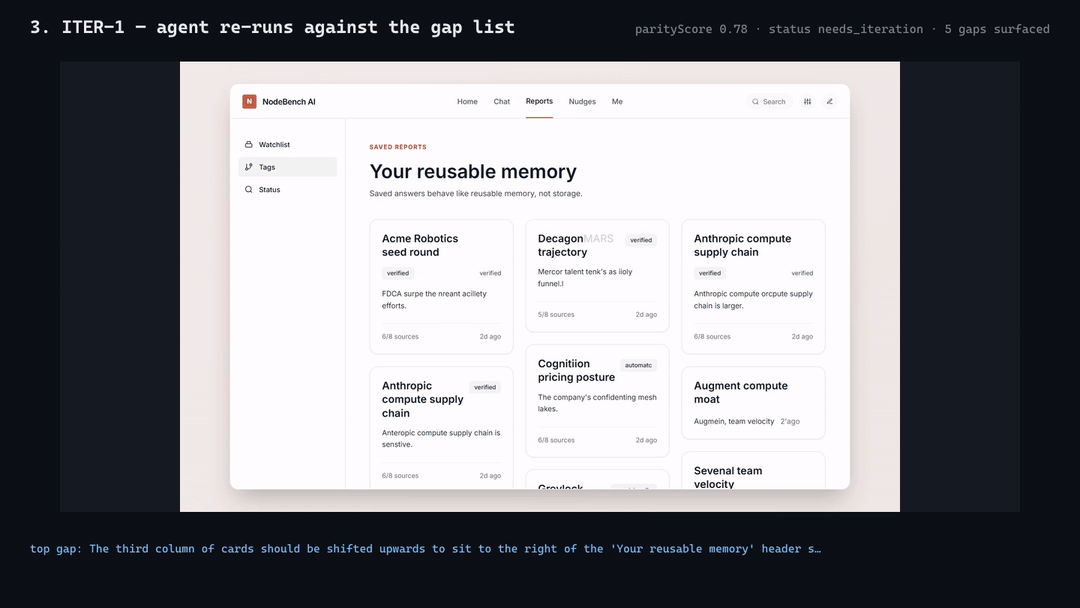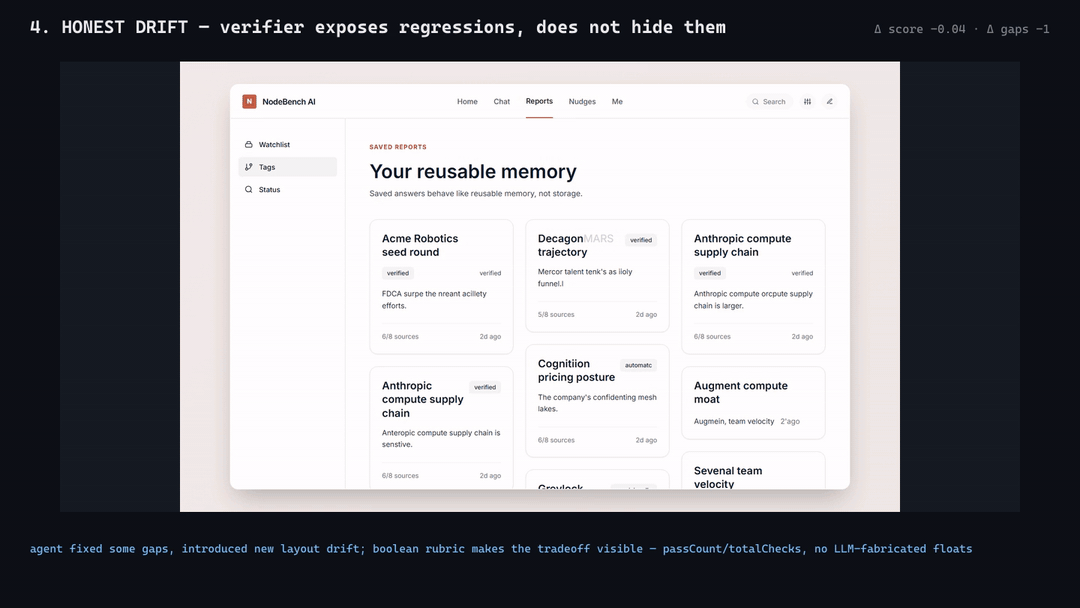
[MP4
version](https://raw.githubusercontent.com/HomenShum/open-codesign/feat/decompose-to-ui-kit/website/public/demos/decompose-iter-reel.mp4)
for higher fidelity.
**Live-recorded session demo** (real Electron app, no stitching) —
recording in progress, will edit this PR description when the GIF is
ready. ETA same day.
## Cross-tier benchmarks
`BENCHMARKS.md` at repo root has the full methodology + run-by-run
real-data results across model tiers (Opus, Pro+Pro+iterate,
Kimi+Gemini3, NodeBench iter), reproducibility instructions, honest
non-claims, and research citations (WebDevJudge, Prometheus-Vision,
Trust-but-Verify ICCV 2025).
| Run | Decompose | Judge | parityScore | Gaps surfaced |
|---|---|---|---:|---:|
| e2e-opus-final | claude-opus-4-1 | claude-opus-4-1 | 0.90 | 4 |
| e2e-nodebench-iter (iter-0) | gemini-3-pro-preview |
gemini-3-pro-preview | 0.82 | 6 |
| e2e-nodebench-iter (iter-1) | gemini-3-pro-preview |
gemini-3-pro-preview | 0.78 | 5 |
| e2e-bank-kimi-gemini3 | kimi-k2.6 | gemini-3-pro-preview | 0.78 | 8 |
| e2e-nodebench-B | kimi-k2.6 | gemini-3-pro-preview | 0.60 | 7 |
Note the iter-0 → iter-1 regression on the same source: agent fixed some
gaps but introduced new layout drift. The boolean rubric exposes this
honestly rather than fudging the score upward. This is the intended
behavior, not a bug.
## Scope discipline notes
- **PR size**: ~1500 LOC of substantive change (3 tools + 3 test files +
agent wiring + i18n + 1 hook). Most of the diff stat (`pnpm-lock.yaml`)
is mechanical regen. This is over the soft 400-LOC bar in
CONTRIBUTING.md, but it's been pre-discussed in #225 and the change is a
single concern (one new feature path, no refactor mixed in). Happy to
split into 3 PRs (per-tool) if maintainer prefers — say the word.
- **What's NOT in scope** (from #225 thread): multi-page flow (Phase 3,
separate issue), gpt-image-2 generation step (Phase 2, separate
Discussion), persistence-to-disk (option (b) from the binary I posed —
staying with option (a) for blast radius)
- **Three systemic dependencies surfaced during dogfood** (rollback /
capability-aware failover / spiral-detector): filing as separate
Discussions in `Ideas` category, not bundling here. Each is a meaningful
subsystem that deserves alignment before code.
## Branch state at PR open
- 9 commits ahead of `upstream/main`
- 11 commits behind (mostly `chore(deps)` bumps including pi-agent-core
0.67.68 → 0.70.2; my branch is on 0.67.68)
- **Will rebase against latest main on request** — wanted to open the PR
with the as-built state for clarity first. The pi-agent-core 0.70.2 bump
may require small adjustments to the new tools' `AgentTool` shape; I'll
handle that in the rebase pass.
## Why this is ready to review now
- Real cross-tier benchmarks in `BENCHMARKS.md`, not synthetic
- Visual proof embedded above (hero + reel)
- Test coverage matches existing tools
- Pattern conformance: every new file mirrors an existing precedent
- Deliberate scope: closes Phase 1 of the issue cleanly, defers the rest
visibly
Looking forward to feedback. Happy to address structural concerns first
before iterating on smaller polish.
---------
Signed-off-by: homen <hshum2018@gmail.com>
Signed-off-by: Sun-sunshine06 <Sun-sunshine06@users.noreply.github.com>
Co-authored-by: Sun-sunshine06 <Sun-sunshine06@users.noreply.github.com>
{kind=link}
{kind=link}
1 parent b2d020d commit 631143d
30 files changed
Lines changed: 2660 additions & 3 deletions
File tree
- .changeset
- apps/desktop/src
- main
- ipc
- renderer/src
- components
- chat
- hooks
- store/slices
- packages
- core/src
- tools
- i18n/src/locales
- website/public
- demos
- screenshots
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
| 1 | + | |
| 2 | + | |
| 3 | + | |
| 4 | + | |
| 5 | + | |
| 6 | + | |
| 7 | + | |
| 8 | + | |
| 9 | + | |
| 10 | + | |
| 11 | + | |
| 12 | + | |
| 13 | + | |
| 14 | + | |
| 15 | + | |
| 16 | + | |
| 17 | + | |
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
| 1 | + | |
| 2 | + | |
| 3 | + | |
| 4 | + | |
| 5 | + | |
| 6 | + | |
| 7 | + | |
| 8 | + | |
| 9 | + | |
| 10 | + | |
| 11 | + | |
| 12 | + | |
| 13 | + | |
| 14 | + | |
| 15 | + | |
| 16 | + | |
| 17 | + | |
| 18 | + | |
| 19 | + | |
| 20 | + | |
| 21 | + | |
| 22 | + | |
| 23 | + | |
| 24 | + | |
| 25 | + | |
| 26 | + | |
| 27 | + | |
| 28 | + | |
| 29 | + | |
| 30 | + | |
| 31 | + | |
| 32 | + | |
| 33 | + | |
| 34 | + | |
| 35 | + | |
| 36 | + | |
| 37 | + | |
| 38 | + | |
| 39 | + | |
| 40 | + | |
| 41 | + | |
| 42 | + | |
| 43 | + | |
| 44 | + | |
| 45 | + | |
| 46 | + | |
| 47 | + | |
| 48 | + | |
| 49 | + | |
| 50 | + | |
| 51 | + | |
| 52 | + | |
| 53 | + | |
| 54 | + | |
| 55 | + | |
| 56 | + | |
| 57 | + | |
| 58 | + | |
| 59 | + | |
| 60 | + | |
| 61 | + | |
| 62 | + | |
| 63 | + | |
| 64 | + | |
| 65 | + | |
| 66 | + | |
| 67 | + | |
| 68 | + | |
| 69 | + | |
| 70 | + | |
| 71 | + | |
| 72 | + | |
| 73 | + | |
| 74 | + | |
| 75 | + | |
| 76 | + | |
| 77 | + | |
| 78 | + | |
| 79 | + | |
| 80 | + | |
| 81 | + | |
| 82 | + | |
| 83 | + | |
| 84 | + | |
| 85 | + | |
| 86 | + | |
| 87 | + | |
| 88 | + | |
| 89 | + | |
| 90 | + | |
| 91 | + | |
| 92 | + | |
| 93 | + | |
| 94 | + | |
| 95 | + | |
| 96 | + | |
| 97 | + | |
| 98 | + | |
| 99 | + | |
| 100 | + | |
| 101 | + | |
| 102 | + | |
| 103 | + | |
| 104 | + | |
| 105 | + | |
| 106 | + | |
| 107 | + | |
| 108 | + | |
| 109 | + | |
| 110 | + | |
| 111 | + | |
| 112 | + | |
| 113 | + | |
| 114 | + | |
| 115 | + | |
| 116 | + | |
| 117 | + | |
| 118 | + | |
| 119 | + | |
| 120 | + | |
| 121 | + | |
| 122 | + | |
| 123 | + | |
| 124 | + | |
| 125 | + | |
| 126 | + | |
| 127 | + | |
| 128 | + | |
| 129 | + | |
| 130 | + | |
| 131 | + | |
| 132 | + | |
| 133 | + | |
| 134 | + | |
| 135 | + | |
| 136 | + | |
| 137 | + | |
| 138 | + | |
| 139 | + | |
| 140 | + | |
| 141 | + | |
| 142 | + | |
| 143 | + | |
| 144 | + | |
| 145 | + | |
| 146 | + | |
| 147 | + | |
| 148 | + | |
| 149 | + | |
| 150 | + | |
| 151 | + | |
| 152 | + | |
| 153 | + | |
| 154 | + | |
| 155 | + | |
| 156 | + | |
| 157 | + | |
| 158 | + | |
| 159 | + | |
| 160 | + | |
| 161 | + | |
| 162 | + | |
| 163 | + | |
| 164 | + | |
| 165 | + | |
| 166 | + | |
| 167 | + | |
| 168 | + | |
| 169 | + | |
| 170 | + | |
| 171 | + | |
| 172 | + | |
| 173 | + | |
| 174 | + | |
| 175 | + | |
| 176 | + | |
| 177 | + | |
| 178 | + | |
| 179 | + | |
| 180 | + | |
| 181 | + | |
| 182 | + | |
| 183 | + | |
| 184 | + | |
| 185 | + | |
| 186 | + | |
| 187 | + | |
| 188 | + | |
| 189 | + | |
| 190 | + | |
| 191 | + | |
| 192 | + | |
| 193 | + | |
| 194 | + | |
| 195 | + | |
| 196 | + | |
| 197 | + | |
| 198 | + | |
| 199 | + | |
| 200 | + | |
| 201 | + | |
| 202 | + | |
| 203 | + | |
| 204 | + | |
| 205 | + | |
| 206 | + | |
| 207 | + | |
| 208 | + | |
| 209 | + | |
| 210 | + | |
| 211 | + | |
| 212 | + | |
| 213 | + | |
| 214 | + | |
| 215 | + | |
| 216 | + | |
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
37 | 37 | | |
38 | 38 | | |
39 | 39 | | |
| 40 | + | |
40 | 41 | | |
41 | 42 | | |
42 | 43 | | |
| |||
232 | 233 | | |
233 | 234 | | |
234 | 235 | | |
| 236 | + | |
| 237 | + | |
| 238 | + | |
| 239 | + | |
| 240 | + | |
| 241 | + | |
| 242 | + | |
235 | 243 | | |
236 | 244 | | |
237 | 245 | | |
| |||
0 commit comments