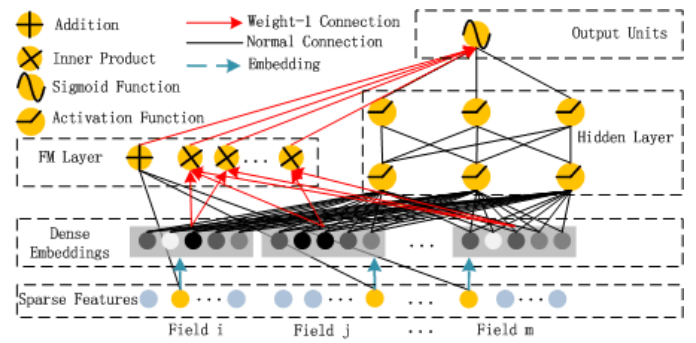
CTR预估是目前推荐系统的核心技术,其目标是预估用户点击推荐内容的概率。DeepFM模型包含FM和DNN两部分,FM模型可以抽取low-order(低阶)特征,DNN可以抽取high-order(高阶)特征。低阶特征可以理解为线性的特征组合,高阶特征,可以理解为经过多次线性-非线性组合操作之后形成的特征,为高度抽象特征。无需Wide&Deep模型人工特征工程。由于输入仅为原始特征,而且FM和DNN共享输入向量特征,DeepFM模型训练速度很快。
注解:Wide&Deep是一种融合浅层(wide)模型和深层(deep)模型进行联合训练的框架,综合利用浅层模型的记忆能力和深层模型的泛化能力,实现单模型对推荐系统准确性和扩展性的兼顾。
为了同时利用low-order和high-order特征,DeepFM包含FM和DNN两部分,两部分共享输入特征。对于特征i,标量wi是其1阶特征的权重,该特征和其他特征的交互影响用隐向量Vi来表示。Vi输入到FM模型获得特征的2阶表示,输入到DNN模型得到high-order高阶特征。
DeepFM模型结构如下图所示,完成对稀疏特征的嵌入后,由FM层和DNN层共享输入向量,经前向反馈后输出。
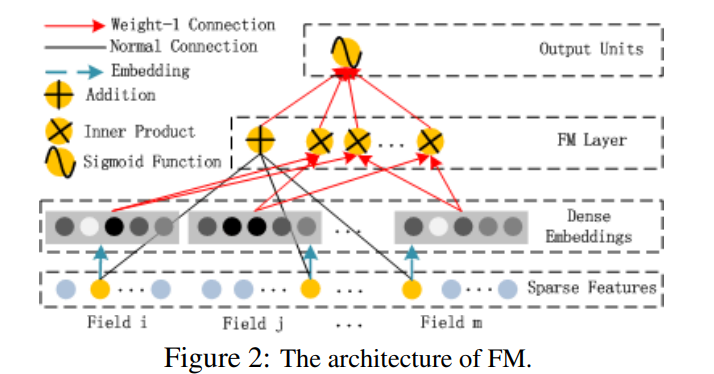
FM(Factorization Machines,因子分解机)最早由Steffen Rendle于2010年在ICDM上提出,它是一种通用的预测方法,在即使数据非常稀疏的情况下,依然能估计出可靠的参数进行预测。与传统的简单线性模型不同的是,因子分解机考虑了特征间的交叉,对所有嵌套变量交互进行建模(类似于SVM中的核函数),因此在推荐系统和计算广告领域关注的点击率CTR(click-through rate)和转化率CVR(conversion rate)两项指标上有着良好的表现。
FM模型不单可以建模1阶特征,还可以通过隐向量点积的方法高效的获得2阶特征表示,即使交叉特征在数据集中非常稀疏甚至是从来没出现过。这也是FM的优势所在。
单独的FM层结构如下图所示:
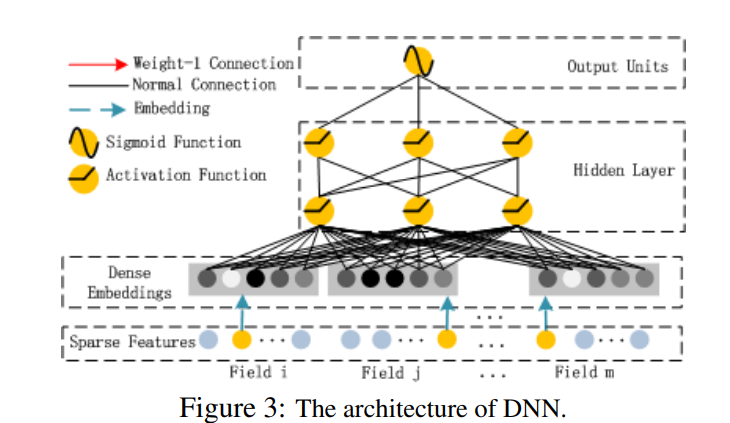
该部分和Wide&Deep模型类似,是简单的前馈网络。在输入特征部分,由于原始特征向量多是高纬度,高度稀疏,连续和类别混合的分域特征,因此将原始的稀疏表示特征映射为稠密的特征向量。
假设子网络的输出层为:
$$ a^{(0)}=[e1,e2,e3,...en] $$ DNN网络第l层表示为:
$$ a^{(l+1)}=\sigma{(W^{(l)}a^{(l)}+b^{(l)})} $$ 再假设有H个隐藏层,DNN部分的预测输出可表示为:
$$ y_{DNN}= \sigma{(W^{|H|+1}\cdot a^H + b^{|H|+1})} $$ DNN深度神经网络层结构如下图所示:
DeepFM模型的损失函数选择Binary_Cross_Entropy(二值交叉熵)函数
$$ H_p(q)=-\frac{1}{N}\sum_{i=1}^Ny_i\cdot log(p(y_i))+(1-y_i) \cdot log(1-p(y_i)) $$ 对于公式的理解,y是样本点,p(y)是该样本为正样本的概率,log(p(y))可理解为对数概率。
Auc是Area Under Curve的首字母缩写,这里的Curve指的就是ROC曲线,AUC就是ROC曲线下面的面积,作为模型评价指标,他可以用来评价二分类模型。其中,ROC曲线全称为受试者工作特征曲线 (receiver operating characteristic curve),它是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(敏感性)为纵坐标,假阳性率(1-特异性)为横坐标绘制的曲线。
可使用paddle.metric.Auc()进行调用。