🚀 Cerchi un modo ancora più veloce e semplice per fare scraping su larga scala (con sole 5 righe di codice)? Scopri la nostra versione potenziata su ScrapeGraphAI.com! 🚀

English | 中文 | 日本語 | 한국어 | Русский | Türkçe | Deutsch | Español | français | Português | Italiano
ScrapeGraphAI è una libreria Python per il web scraping che utilizza LLM e logica basata sui grafi per creare pipeline di scraping per siti web e documenti locali (XML, HTML, JSON, Markdown, ecc.).
Indica semplicemente quali informazioni vuoi estrarre e la libreria lo farà per te!
ScrapeGraphAI offre integrazioni con i framework e gli strumenti più diffusi per potenziare le tue capacità di scraping. Che tu stia sviluppando in Python o Node.js, usando framework LLM o piattaforme no-code, offriamo un'ampia gamma di opzioni di integrazione.
Puoi trovare ulteriori informazioni al seguente link
Integrazioni:
- API: Documentazione
- SDK: Python, Node
- Framework LLM: Langchain, Llama Index, Crew.ai, Agno, CamelAI
- Framework Low-code: Pipedream, Bubble, Zapier, n8n, Dify, Toolhouse
- Server MCP: Link
La pagina di riferimento per scrapegraph-ai è disponibile sulla pagina ufficiale di PyPI: pypi.
pip install scrapegraphai
# IMPORTANTE (per il recupero del contenuto dei siti web)
playwright installNota: si consiglia di installare la libreria in un ambiente virtuale per evitare conflitti con altre librerie 🐱
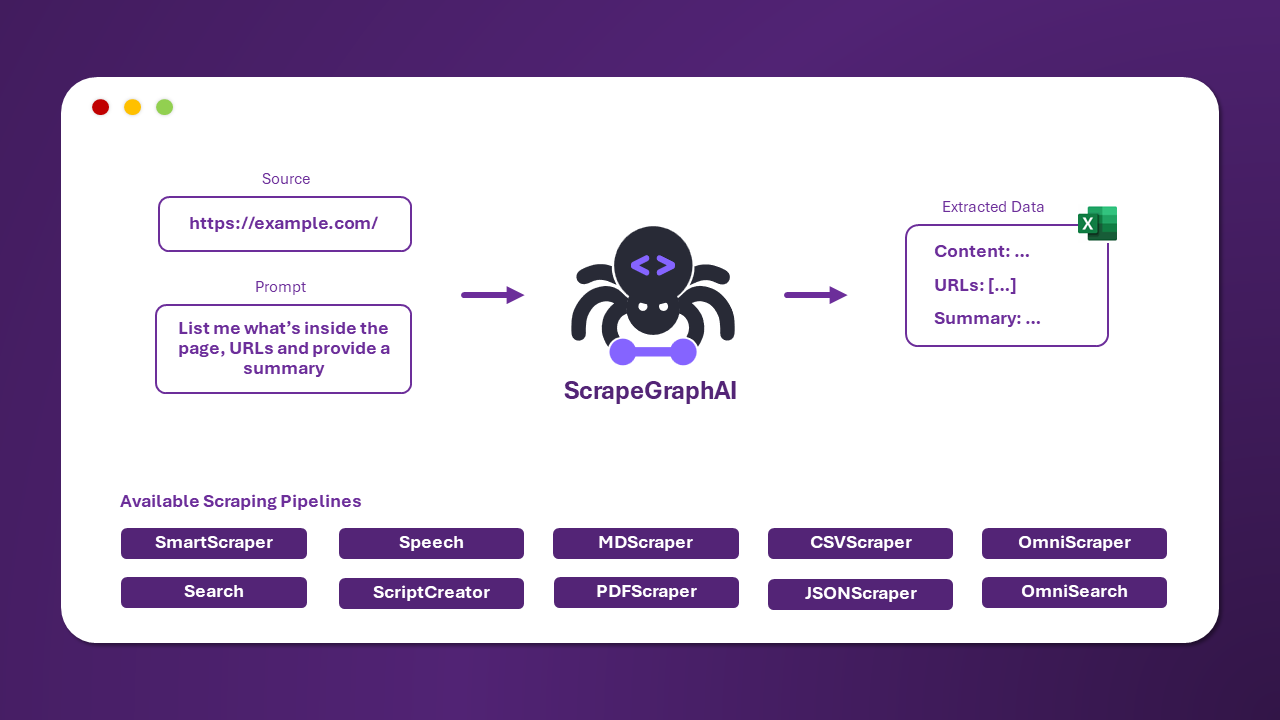
Esistono diverse pipeline di scraping predefinite che possono essere utilizzate per estrarre informazioni da un sito web (o da un file locale).
La più comune è SmartScraperGraph, che estrae informazioni da una singola pagina dato un prompt dell'utente e un URL sorgente.
from scrapegraphai.graphs import SmartScraperGraph
# Definisci la configurazione per la pipeline di scraping
graph_config = {
"llm": {
"model": "ollama/llama3.2",
"model_tokens": 8192,
"format": "json",
},
"verbose": True,
"headless": False,
}
# Crea l'istanza di SmartScraperGraph
smart_scraper_graph = SmartScraperGraph(
prompt="Estrai informazioni utili dalla pagina web, inclusa una descrizione di cosa fa l'azienda, i fondatori e i link ai social media",
source="https://scrapegraphai.com/",
config=graph_config
)
# Esegui la pipeline
result = smart_scraper_graph.run()
import json
print(json.dumps(result, indent=4))Note
Per OpenAI e altri modelli è sufficiente modificare la configurazione llm!
graph_config = {
"llm": {
"api_key": "LA_TUA_OPENAI_API_KEY",
"model": "openai/gpt-4o-mini",
},
"verbose": True,
"headless": False,
}L'output sarà un dizionario simile al seguente:
{
"description": "ScrapeGraphAI transforms websites into clean, organized data for AI agents and data analytics. It offers an AI-powered API for effortless and cost-effective data extraction.",
"founders": [
{
"name": "",
"role": "Founder & Technical Lead",
"linkedin": "https://www.linkedin.com/in/perinim/"
},
{
"name": "Marco Vinciguerra",
"role": "Founder & Software Engineer",
"linkedin": "https://www.linkedin.com/in/marco-vinciguerra-7ba365242/"
},
{
"name": "Lorenzo Padoan",
"role": "Founder & Product Engineer",
"linkedin": "https://www.linkedin.com/in/lorenzo-padoan-4521a2154/"
}
],
"social_media_links": {
"linkedin": "https://www.linkedin.com/company/101881123",
"twitter": "https://x.com/scrapegraphai",
"github": "https://github.com/ScrapeGraphAI/Scrapegraph-ai"
}
}Esistono altre pipeline che possono essere utilizzate per estrarre informazioni da più pagine, generare script Python o persino generare file audio.
| Nome Pipeline | Descrizione |
|---|---|
| SmartScraperGraph | Scraper di singole pagine che richiede solo un prompt utente e una sorgente. |
| SearchGraph | Scraper multi-pagina che estrae informazioni dai primi n risultati di un motore di ricerca. |
| SpeechGraph | Scraper di singole pagine che estrae informazioni da un sito web e genera un file audio. |
| ScriptCreatorGraph | Scraper di singole pagine che estrae informazioni da un sito web e genera uno script Python. |
| SmartScraperMultiGraph | Scraper multi-pagina che estrae informazioni da più pagine dato un singolo prompt e una lista di sorgenti. |
| ScriptCreatorMultiGraph | Scraper multi-pagina che genera uno script Python per estrarre informazioni da più pagine e sorgenti. |
Per ciascuno di questi grafi esiste una versione multi, che consente di effettuare chiamate all'LLM in parallelo.
È possibile utilizzare diversi LLM tramite API, come OpenAI, Groq, Azure, Gemini, MiniMax e altri, oppure modelli locali tramite Ollama.
Ricordati di avere Ollama installato e di scaricare i modelli con il comando ollama pull, se desideri utilizzare modelli locali.
La documentazione di ScrapeGraphAI è disponibile qui. Consulta anche il Docusaurus qui.
Sentiti libero di contribuire e unisciti al nostro server Discord per discutere con noi su cosa migliorare e darci suggerimenti!
Consulta le linee guida per i contributi.
Se stai cercando una soluzione rapida per integrare ScrapeGraph nel tuo sistema, scopri la nostra potente API qui!

Offriamo gli SDK sia in Python che in Node.js, per una facile integrazione nei tuoi progetti. Scoprili di seguito:
| SDK | Linguaggio | Link GitHub |
|---|---|---|
| Python SDK | Python | scrapegraph-py |
| Node.js SDK | Node.js | scrapegraph-js |
La documentazione ufficiale dell'API è disponibile qui.
Secondo il benchmark di Firecrawl Firecrawl benchmark, ScrapeGraph è il miglior fetcher sul mercato!

Raccogliamo metriche di utilizzo anonimizzate per migliorare la qualità e la user experience del nostro pacchetto. I dati ci aiutano a stabilire le priorità e a garantire la compatibilità. Se desideri disattivare la telemetria, imposta la variabile d'ambiente SCRAPEGRAPHAI_TELEMETRY_ENABLED=false. Per ulteriori informazioni, consulta la documentazione qui.
Se hai utilizzato la nostra libreria per scopi di ricerca, citaci con il seguente riferimento:
@misc{scrapegraph-ai,
author = {Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
url = {https://github.com/ScrapeGraphAI/Scrapegraph-ai},
note = {A Python library for scraping leveraging large language models}
}
| Contatti | |
|---|---|
| Marco Vinciguerra | |
| Lorenzo Padoan |
ScrapeGraphAI è rilasciato sotto la Licenza MIT. Consulta il file LICENSE per ulteriori informazioni.
- Ringraziamo tutti i collaboratori del progetto e la comunità open-source per il loro supporto.
- ScrapeGraphAI è destinato esclusivamente a scopi di esplorazione dei dati e ricerca. Non siamo responsabili per eventuali usi impropri della libreria.
Fatto con il ❤️ da ScrapeGraph AI
{kind=link}