🚀 ¿Buscas una forma aún más rápida y sencilla de hacer scraping a escala (con solo 5 líneas de código)? ¡Checa nuestra versión mejorada en ScrapeGraphAI.com! 🚀

English | 中文 | 日本語 | 한국어 | Русский | Türkçe | Deutsch | Español | français | Português | Italiano
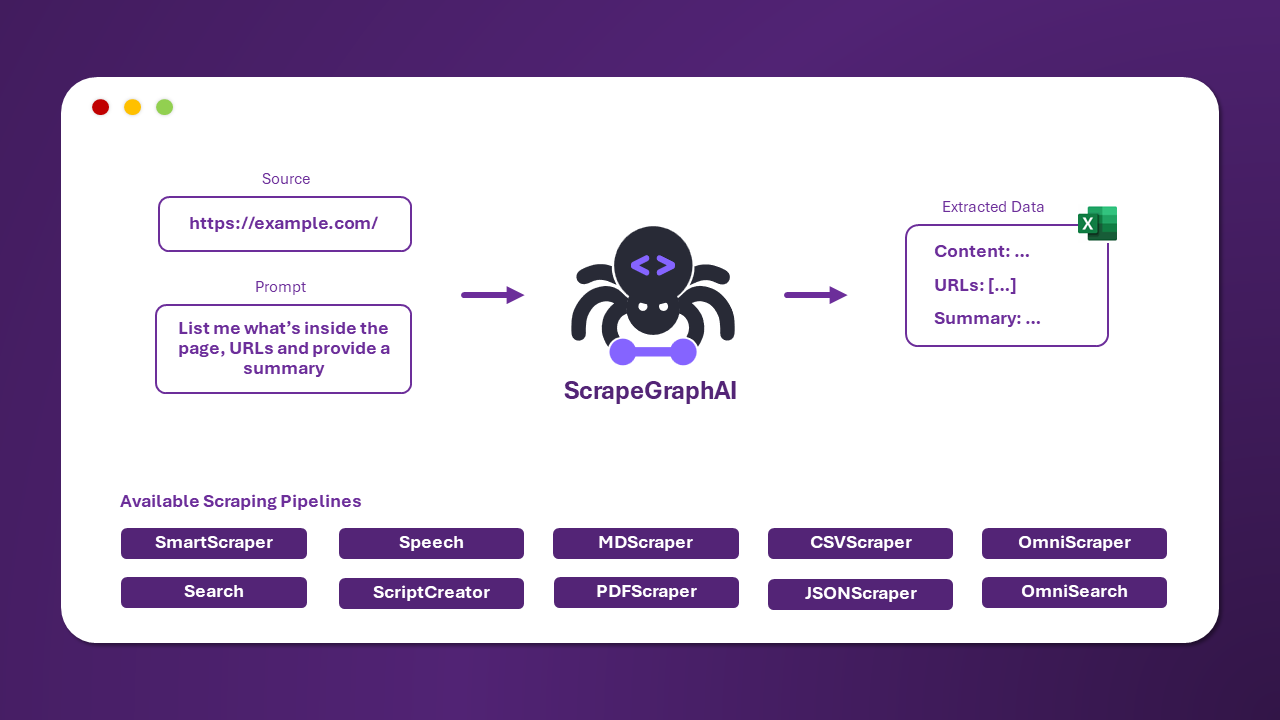
ScrapeGraphAI es una librería de Python para web scraping que usa LLMs y lógica de grafos para crear pipelines de extracción de datos en sitios web y documentos locales (XML, HTML, JSON, Markdown, etc.).
¡Solo dile qué información quieres extraer y la librería lo hace por ti!
ScrapeGraphAI se integra de forma nativa con los frameworks y herramientas más populares para potenciar tus capacidades de scraping. Ya sea que estés desarrollando en Python o Node.js, usando frameworks de LLMs o plataformas no-code, tenemos todo cubierto.
Puedes encontrar más información en el siguiente link
Integraciones:
- API: Documentación
- SDKs: Python, Node
- Frameworks de LLMs: Langchain, Llama Index, Crew.ai, Agno, CamelAI
- Frameworks low-code: Pipedream, Bubble, Zapier, n8n, Dify, Toolhouse
- Servidor MCP: Link
La página de referencia de Scrapegraph-ai está disponible en PyPI: pypi.
pip install scrapegraphai
# IMPORTANTE (para hacer fetch del contenido de los sitios web)
playwright installNota: se recomienda instalar la librería en un entorno virtual para evitar conflictos con otras dependencias 🐱
Hay múltiples pipelines de scraping estándar para extraer información de un sitio web o archivo local.
El más común es SmartScraperGraph, que extrae información de una sola página dado un prompt y una URL de origen.
from scrapegraphai.graphs import SmartScraperGraph
# Define the configuration for the scraping pipeline
graph_config = {
"llm": {
"model": "ollama/llama3.2",
"model_tokens": 8192,
"format": "json",
},
"verbose": True,
"headless": False,
}
# Create the SmartScraperGraph instance
smart_scraper_graph = SmartScraperGraph(
prompt="Extract useful information from the webpage, including a description of what the company does, founders and social media links",
source="https://scrapegraphai.com/",
config=graph_config
)
# Run the pipeline
result = smart_scraper_graph.run()
import json
print(json.dumps(result, indent=4))Note
Para OpenAI y otros modelos solo necesitas cambiar el config del LLM:
graph_config = {
"llm": {
"api_key": "YOUR_OPENAI_API_KEY",
"model": "openai/gpt-4o-mini",
},
"verbose": True,
"headless": False,
}El output será un diccionario como el siguiente:
{
"description": "ScrapeGraphAI transforms websites into clean, organized data for AI agents and data analytics. It offers an AI-powered API for effortless and cost-effective data extraction.",
"founders": [
{
"name": "",
"role": "Founder & Technical Lead",
"linkedin": "https://www.linkedin.com/in/perinim/"
},
{
"name": "Marco Vinciguerra",
"role": "Founder & Software Engineer",
"linkedin": "https://www.linkedin.com/in/marco-vinciguerra-7ba365242/"
},
{
"name": "Lorenzo Padoan",
"role": "Founder & Product Engineer",
"linkedin": "https://www.linkedin.com/in/lorenzo-padoan-4521a2154/"
}
],
"social_media_links": {
"linkedin": "https://www.linkedin.com/company/101881123",
"twitter": "https://x.com/scrapegraphai",
"github": "https://github.com/ScrapeGraphAI/Scrapegraph-ai"
}
}Existen otros pipelines para extraer información de múltiples páginas, generar scripts de Python o incluso generar archivos de audio.
| Nombre del Pipeline | Descripción |
|---|---|
| SmartScraperGraph | Scraper de una sola página que solo requiere un prompt y una fuente de entrada. |
| SearchGraph | Scraper multi-página que extrae información de los primeros n resultados de un motor de búsqueda. |
| SpeechGraph | Scraper de una sola página que extrae información de un sitio web y genera un archivo de audio. |
| ScriptCreatorGraph | Scraper de una sola página que extrae información de un sitio web y genera un script de Python. |
| SmartScraperMultiGraph | Scraper multi-página que extrae información de múltiples páginas con un solo prompt y una lista de fuentes. |
| ScriptCreatorMultiGraph | Scraper multi-página que genera un script de Python para extraer información de múltiples páginas y fuentes. |
Cada uno de estos grafos tiene su versión multi, que permite hacer llamadas al LLM en paralelo.
Es posible usar diferentes LLMs mediante APIs como OpenAI, Groq, Azure, Gemini, MiniMax y más, o modelos locales usando Ollama.
Recuerda tener Ollama instalado y descargar los modelos con el comando ollama pull si quieres usar modelos locales.
La documentación de ScrapeGraphAI está disponible aquí.
¡Siéntete libre de contribuir y únete a nuestro servidor de Discord para discutir mejoras y compartir sugerencias!
Por favor revisa las guías de contribución.
Si buscas una solución rápida para integrar ScrapeGraph en tu sistema, checa nuestra API aquí.

Ofrecemos SDKs en Python y Node.js para facilitar la integración en tus proyectos:
| SDK | Lenguaje | GitHub Link |
|---|---|---|
| Python SDK | Python | scrapegraph-py |
| Node.js SDK | Node.js | scrapegraph-js |
La documentación oficial de la API está disponible aquí.
¡Según el benchmark de Firecrawl Firecrawl benchmark, ScrapeGraph es el mejor fetcher del mercado!

Recopilamos métricas de uso anónimas para mejorar la calidad del paquete y la experiencia del usuario. Los datos nos ayudan a priorizar mejoras y garantizar compatibilidad. Si deseas hacer opt-out, configura la variable de entorno SCRAPEGRAPHAI_TELEMETRY_ENABLED=false. Para más información consulta la documentación aquí.
Si usaste nuestra librería para investigación, por favor cítanos con la siguiente referencia:
@misc{scrapegraph-ai,
author = {Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
url = {https://github.com/ScrapeGraphAI/Scrapegraph-ai},
note = {A Python library for scraping leveraging large language models}
}
| Contacto | |
|---|---|
| Marco Vinciguerra | |
| Lorenzo Padoan |
ScrapeGraphAI está licenciado bajo la Licencia MIT. Consulta el archivo LICENSE para más información.
- Queremos agradecer a todos los contributors del proyecto y a la comunidad open-source por su apoyo.
- ScrapeGraphAI está pensado únicamente para exploración de datos e investigación. No nos hacemos responsables del mal uso de la librería.
Hecho con ❤️ por ScrapeGraph AI
{kind=link}