|
1 | 1 |
|
2 | | -Lec6-数据库模式设计之层次结构 |
| 2 | +0.1. Lec6-数据库模式设计之层次结构 |
3 | 3 | --- |
4 | 4 |
|
5 | 5 | # 1. 处理层次结构(Hierarchical Data) |
@@ -104,3 +104,157 @@ where inventory.id = 'AZE087564609' |
104 | 104 |
|
105 | 105 | 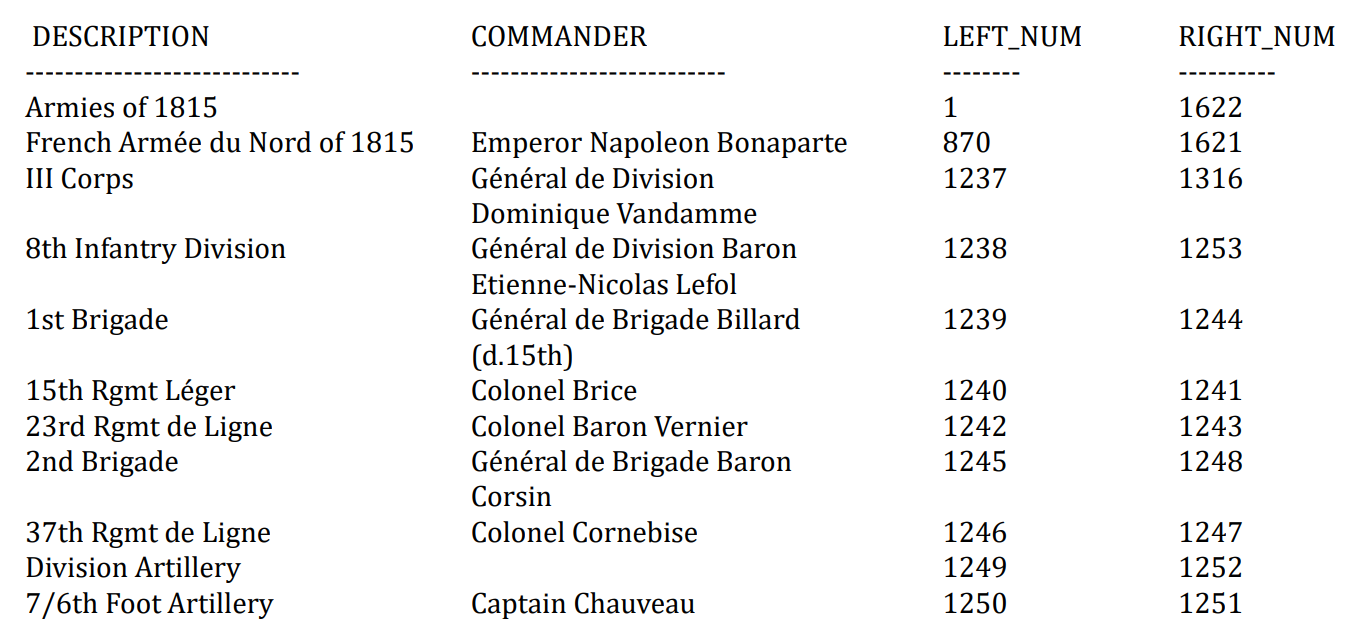 |
106 | 106 |
|
| 107 | +# 6. 用SQL访问树的结构 |
| 108 | +1. 为了检查效率和性能,分别用不同模型解决如下两个问题: |
| 109 | +2. 法国将军Dominique Vandamme指挥哪些部队,以缩排方式或简单列表的方式显示他们。注意,所有的commander字段都构建了索引 (简称Vandamme查询) |
| 110 | +3. Scottish Highlanders的每个团各属于哪个部队(自底向上的查询)。在部队的名称.(description字段).上没有索引, 唯- -的方法是在description字段中查找"Highland" 字符串,在没有任何全文索引的情况下,这个问题简称highland问题 |
| 111 | + 1. 注:层次结构Corp-division-brigade regiment |
| 112 | + 2. Oracle |
| 113 | + |
| 114 | +## 6.1. 自顶向下查询:Vandamme 查询 |
| 115 | + |
| 116 | +### 6.1.1. 邻接模型 |
| 117 | +1. `connect by < a column of the current row > = prior a column of the previous row` |
| 118 | +2. `connect by < a column of the previous row > = prior a column of the current row` |
| 119 | + |
| 120 | +```sql |
| 121 | +select lpad(description, length(description) + level) description, commander |
| 122 | +from adjacency_ model |
| 123 | +connect by parent_ id = prior id |
| 124 | +start with commander = 'Général de Division Dominique Vandamme' |
| 125 | +``` |
| 126 | + |
| 127 | + |
| 128 | + |
| 129 | +- 邻接矩阵:递归实现 |
| 130 | + |
| 131 | + |
| 132 | + |
| 133 | + |
| 134 | + |
| 135 | +- 添加排序:加粗部分完成排序(优化器会避免出现重复计算) |
| 136 | + |
| 137 | + |
| 138 | + |
| 139 | +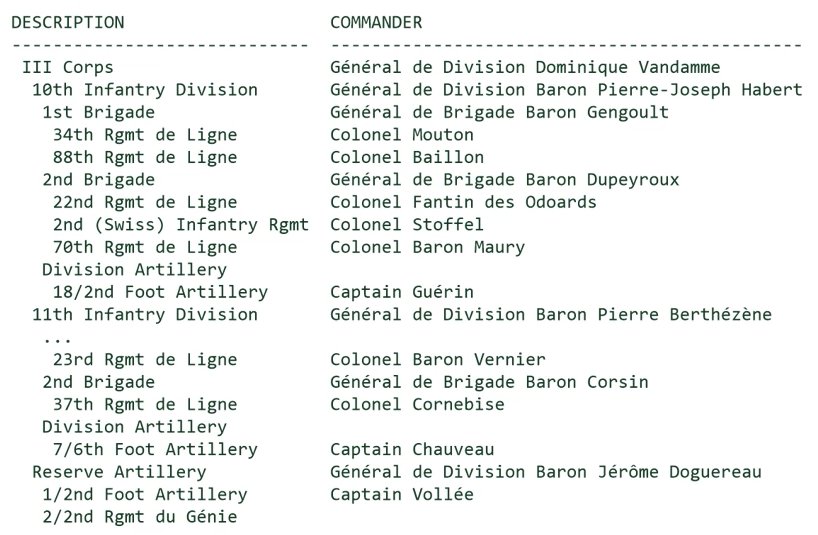 |
| 140 | + |
| 141 | +- 那么MySQL呢?两个方法 |
| 142 | + 1. 手动union |
| 143 | + 2. 在一个查询汇总多次连接 |
| 144 | + 3. 前提都是已知深度(人工获取) |
| 145 | + |
| 146 | + |
| 147 | + |
| 148 | +### 6.1.2. 物化路径模型 |
| 149 | +1. 查询编写不困难 |
| 150 | +2. 计算由路径导出的层次不方便 |
| 151 | +3. 假设mp_depth()函数返回当前节点深度 |
| 152 | + |
| 153 | + |
| 154 | + |
| 155 | +### 6.1.3. 嵌套集合模型 |
| 156 | +1. 很简单,某节点的后代的 left_num 和 right_num 都会在该节点的 left_num 和right_num 范围内 |
| 157 | + |
| 158 | + |
| 159 | + |
| 160 | +2. 缩排怎么办? |
| 161 | + |
| 162 | + |
| 163 | + |
| 164 | +### 6.1.4. 比较各模型下的Vandamme模型 |
| 165 | +1. 返回40条记录,循环执行各个查询5000次,比较每秒返回的记录数 |
| 166 | +2. 邻接模型最高:parentId |
| 167 | +3. 物化路径模型 |
| 168 | + 1. 计算深度:字符串相关操作效率低 |
| 169 | + 2. 缩排:反复处理字符串效率低 |
| 170 | +4. 嵌套集合模型: |
| 171 | + 1. 查找子代完胜其他模型 |
| 172 | + 2. 缩排成本太高了 |
| 173 | + 3. 改进:每个节点都冗余存储深度,但是维护成本高:树结构不改变、不需要所有节点排序时最好。 |
| 174 | + |
| 175 | + |
| 176 | + |
| 177 | +## 6.2. 自底向上访问:Highland查询 |
| 178 | +1. 在 description 字段中查找“ Highland ”字符串 |
| 179 | +2. 必然导致完整的表扫描:无法使用索引 |
| 180 | +3. 不同模型下 Highland 查询的差异 |
| 181 | + |
| 182 | +### 6.2.1. 邻接模型 |
| 183 | +Connect by 非常容易实现:Connect by不是关系操作 |
| 184 | + |
| 185 | + |
| 186 | + |
| 187 | + |
| 188 | + |
| 189 | +### 6.2.2. 物化路径模型 |
| 190 | +- 仅找出适当的记录并缩排显示算容易 |
| 191 | + - 重复记录的问题 |
| 192 | + - 顺序的问题 |
| 193 | + |
| 194 | + |
| 195 | + |
| 196 | + |
| 197 | + |
| 198 | + |
| 199 | + |
| 200 | +### 6.2.3. 嵌套集合模型 |
| 201 | +1. 动态计算深度依旧是个问题 |
| 202 | +2. 不要显示人造根节点 |
| 203 | +3. 硬编码最大深度(为了缩排显示) |
| 204 | + |
| 205 | + |
| 206 | + |
| 207 | +### 6.2.4. 比较各种模型下的Highland查询 |
| 208 | +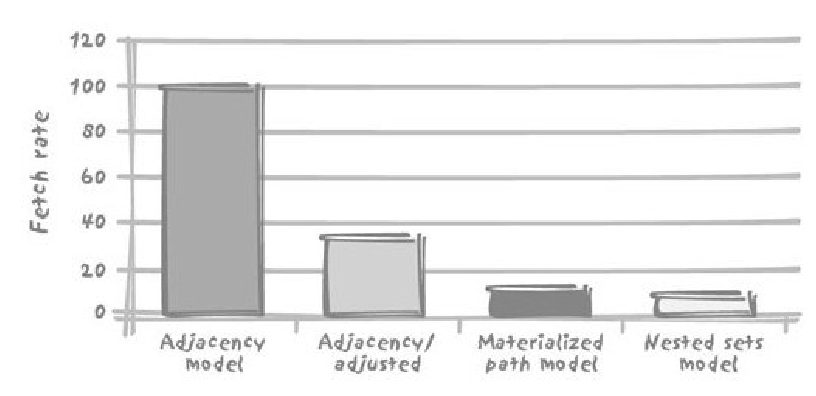 |
| 209 | + |
| 210 | +由于邻接模型中会有重复语句,我们可以使用有效结果的行数来衡量 |
| 211 | + |
| 212 | +### 6.2.5. 一些问题 |
| 213 | +1. 物化路径不该是KEY,即使他们有唯一性:主键最好不要经常被更新 |
| 214 | +2. 物化路径不该暗示任何兄弟节点的排序 |
| 215 | +3. 所选择的编码方式不需要完全中立 |
| 216 | + |
| 217 | +# 7. 聚合来自树的值 |
| 218 | +- 一共有2个大部分 |
| 219 | + - 保存叶节点的值 |
| 220 | + - 计算某个值散布在整个树中的百分比 |
| 221 | + |
| 222 | +## 7.1. 对保存于叶节点的值做聚合 |
| 223 | +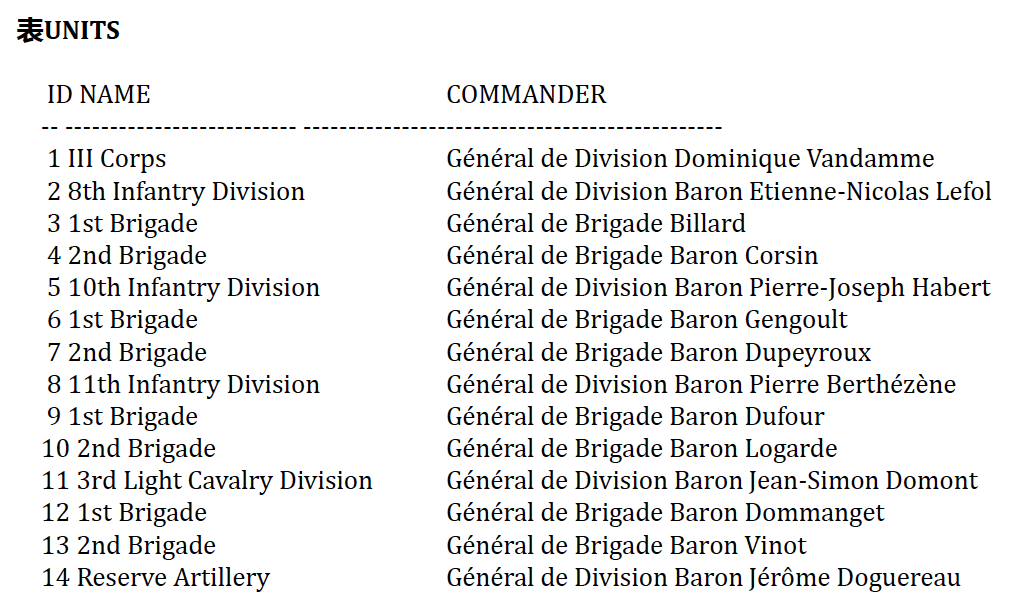 |
| 224 | + |
| 225 | + |
| 226 | + |
| 227 | +## 7.2. 计算每一层的人数 |
| 228 | + |
| 229 | +### 7.2.1. 计算每一层的人数(邻接模型) |
| 230 | + |
| 231 | + |
| 232 | +### 7.2.2. 计算每一层的人数(物化路径) |
| 233 | + |
| 234 | + |
| 235 | +### 7.2.3. 不同模型的性能 |
| 236 | +- 执行查询5000次,比较单位时间返回的记录数 |
| 237 | + |
| 238 | +## 7.3. 散布在各层的百分比 |
| 239 | +1. 假设我们经营魔药。每种魔药由多种成分( ingredient )组成,处方 recipe 列出成分及百分比。处方可以共享某种“基础魔药”,以复合成分 compound ingredient )的形式表示。 |
| 240 | +2. 百分比被分到了每一个部分中 |
| 241 | + |
| 242 | + |
| 243 | + |
| 244 | +3. 某一种可以选择的建模方法 |
| 245 | + 1. Components 表为通用类型 |
| 246 | + 2. 它有 recipes 和 basic_ingredients 两种子类型 |
| 247 | + 3. Composition 表保存处方成分(可以是处方或基本成分及其数量) |
| 248 | + |
| 249 | + |
| 250 | + |
| 251 | + |
| 252 | + |
| 253 | + |
| 254 | + |
| 255 | +## 7.4. 树状结构的问题 |
| 256 | +1. 本章的方法,在数据量很少的情况下效果令人满意 |
| 257 | +2. 对大数据量的处理“像老爷车一样慢” |
| 258 | +3. 同样可以采用非规范化模型、或基于触发器的扁平化数据模型。 |
| 259 | +4. 不建议对关系模型“屡遭诟病的缓慢本性”反规范化,这很容易遮掩程序设计中的问题。 |
| 260 | +5. 不过, SQL 确实缺乏处理树结构的强大的、可伸缩的手段。 |
0 commit comments