diff --git a/.vitepress/en.ts b/.vitepress/en.ts
index d12bfba0..e3e05855 100644
--- a/.vitepress/en.ts
+++ b/.vitepress/en.ts
@@ -43,7 +43,7 @@ export const en = defineConfig({
{ text: 'Swift', link: base_path_guide_cloud + '/integration/integration-swift'},
{ text: 'Ultralytics', link: base_path_guide_cloud + '/integration/integration-ultralytics'},
{ text: 'veRL', link: base_path_guide_cloud + '/integration/integration-verl'},
- { text: 'Sb3', link: base_path_guide_cloud + '/integration/integration-sb3'},
+ { text: 'SB3', link: base_path_guide_cloud + '/integration/integration-sb3'},
]
},
{
@@ -62,7 +62,7 @@ export const en = defineConfig({
{ text: 'Community', link: 'https://swanlab.cn/benchmarks' },
{ text: 'Join Us', link: 'https://rcnpx636fedp.feishu.cn/wiki/BxtVwAc0siV0xrkCbPTcldBEnNP' },
{ text: 'Feedback', link: 'https://geektechstudio.feishu.cn/share/base/form/shrcn8koDFRcH2mMcBYMh9tiKfI' },
- { text: 'Docs Github', link: 'https://github.com/SwanHubX/SwanLab-Docs' },
+ { text: 'Docs GitHub', link: 'https://github.com/SwanHubX/SwanLab-Docs' },
] },
{
component: 'HeaderDocHelperButtonEN',
@@ -206,7 +206,7 @@ function sidebarGuideCloud(): SidebarItemEx[] {
// collapsed: false,
items: [
{ text: 'Online support', link: 'community/online-support'},
- { text: 'Github badge', link: 'community/github-badge'},
+ { text: 'GitHub badge', link: 'community/github-badge'},
{ text: 'Paper citation', link: 'community/paper-cite'},
{ text: 'Contributing code', link: 'community/contributing-code'},
{ text: 'Contributing docs', link: 'community/contributing-docs'},
@@ -225,7 +225,7 @@ function sidebarIntegration(): DefaultTheme.SidebarItem[] {
{ text: 'Argparse', link:'integration-argparse' },
{ text: 'Areal', link: 'integration-areal' },
{ text: 'Ascend NPU & MindSpore', link: 'integration-ascend' },
- { text: 'Catboost', link: 'integration-catboost'},
+ { text: 'CatBoost', link: 'integration-catboost'},
{ text: 'DiffSynth-Studio', link: 'integration-diffsynth-studio' },
{ text: 'EasyR1', link: 'integration-easyr1' },
{ text: 'EvalScope', link: 'integration-evalscope' },
@@ -238,20 +238,20 @@ function sidebarIntegration(): DefaultTheme.SidebarItem[] {
items: [
{ text: 'HuggingFace Accelerate', link: 'integration-huggingface-accelerate' },
{ text: 'HuggingFace Transformers', link: 'integration-huggingface-transformers' },
- { text: 'HuggingFace Trl', link: 'integration-huggingface-trl' },
+ { text: 'HuggingFace TRL', link: 'integration-huggingface-trl' },
{ text: 'Hydra', link: 'integration-hydra' },
{ text: 'Keras', link: 'integration-keras' },
{ text: 'LightGBM', link: 'integration-lightgbm'},
{ text: 'LLaMA Factory', link: 'integration-llama-factory'},
{ text: 'LLaMA Factory Online', link: 'integration-llama-factory-online' },
{ text: 'MindSpeed-RL', link: 'integration-mindspeed-rl' },
- { text: 'MLFlow', link: 'integration-mlflow'},
+ { text: 'MLflow', link: 'integration-mlflow'},
{ text: 'MLX LM', link: 'integration-mlx-lm' },
{ text: 'MMEngine', link: 'integration-mmengine' },
{ text: 'MMPretrain', link: 'integration-mmpretrain' },
{ text: 'MMDetection', link: 'integration-mmdetection' },
{ text: 'MMSegmentation', link: 'integration-mmsegmentation' },
- { text: 'Modelscope Swift', link: 'integration-swift' },
+ { text: 'ModelScope Swift', link: 'integration-swift' },
{ text: 'NVIDIA-NeMo RL', link: 'integration-nvidia-nemo-rl' },
]
},
@@ -260,7 +260,7 @@ function sidebarIntegration(): DefaultTheme.SidebarItem[] {
// collapsed: false,
items: [
{ text: 'OpenAI', link: 'integration-openai' },
- { text: 'Omegaconf', link: 'integration-omegaconf' },
+ { text: 'OmegaConf', link: 'integration-omegaconf' },
{ text: 'PaddleDetection', link: 'integration-paddledetection' },
{ text: 'PaddleNLP', link: 'integration-paddlenlp' },
{ text: 'PaddleYOLO', link: 'integration-paddleyolo' },
@@ -271,9 +271,9 @@ function sidebarIntegration(): DefaultTheme.SidebarItem[] {
{ text: 'RLinf', link: 'integration-rlinf'},
{ text: 'ROLL', link: 'integration-roll' },
{ text: 'Sentence Transformers', link: 'integration-sentence-transformers'},
- { text: 'Specforge', link: 'integration-specforge'},
- { text: 'Stable Baseline3', link: 'integration-sb3' },
- { text: 'Tensorboard', link: 'integration-tensorboard'},
+ { text: 'SpecForge', link: 'integration-specforge'},
+ { text: 'Stable Baselines3', link: 'integration-sb3' },
+ { text: 'TensorBoard', link: 'integration-tensorboard'},
]
},
{
@@ -297,7 +297,7 @@ function sidebarExamples(): DefaultTheme.SidebarItem[] {
text: 'Quick Start',
// collapsed: false,
items: [
- { text: 'Hello_World', link: 'hello_world' },
+ { text: 'Hello World', link: 'hello_world' },
{ text: 'MNIST', link: 'mnist' },
{ text: 'FashionMNIST', link: 'fashionmnist' },
{ text: 'CIFAR10', link: 'cifar10' },
diff --git a/.vitepress/theme/custom.css b/.vitepress/theme/custom.css
index f331f80a..13ce80b1 100644
--- a/.vitepress/theme/custom.css
+++ b/.vitepress/theme/custom.css
@@ -1,59 +1,280 @@
:root {
--vp-c-brand-1: #107d8b;
- --vp-layout-max-width:1660px;
+ --vp-layout-max-width: 100%;
--vp-sidebar-bg-color: var(--vp-c-bg-alt);
- --vp-sidebar-width: 320px;
+ --vp-sidebar-width: 280px;
--vp-sidebar-padding-left: 16px;
- /* --vp-layout-max-width: 65%; */
+ --swanlab-nav-search-max-width: 420px;
+ --swanlab-nav-search-min-width: 180px;
+ --swanlab-nav-title-width: 208px;
}
-
.dark {
--vp-c-brand-1: #2e9dac;
}
-/* .VPSidebar {
- padding-left: 32px !important;
-} */
+/* ===== Header: always fixed, consistent across all pages ===== */
+.VPNav {
+ position: fixed !important;
+ z-index: 30;
+}
-.VPDoc.has-aside .content-container {
- max-width: 800px !important;
+.VPNavBar {
+ border-bottom: 0 !important;
}
-.VPDoc.has-aside .content {
- max-width: 800px !important;
+.VPNavBar::after {
+ position: absolute;
+ right: 0;
+ bottom: 0;
+ left: 0;
+ z-index: 3;
+ height: 1px;
+ background-color: var(--vp-c-divider);
+ content: "";
+ pointer-events: none;
+}
+
+.VPNavBar .divider {
+ display: none;
+}
+
+.VPNavBar .container {
+ max-width: none !important;
}
.title {
border-bottom: transparent !important;
}
-/* 调整搜索框位置 */
+/* Logo: ensure the horizontal logo image renders at proper size in header */
+.VPNavBarTitle .title {
+ min-width: 0;
+}
+
+.VPNavBarTitle .logo {
+ display: block;
+ height: 28px;
+ width: auto;
+ max-width: none;
+ flex-shrink: 0;
+ object-fit: contain;
+}
+
+/* Sidebar clearly below header */
+.VPSidebar {
+ top: var(--vp-nav-height) !important;
+ bottom: 0 !important;
+ max-height: calc(100vh - var(--vp-nav-height));
+ box-sizing: border-box;
+ border-right: 1px solid var(--vp-c-divider);
+ overflow-x: hidden;
+ overflow-y: auto;
+}
+
+@media (min-width: 960px) {
+ .VPNavBar:not(.has-sidebar) .wrapper {
+ padding: 0;
+ }
+
+ .VPNavBar .container > .title,
+ .VPNavBar.has-sidebar .container > .title {
+ width: var(--swanlab-nav-title-width) !important;
+ height: var(--vp-nav-height);
+ padding: 0 24px !important;
+ flex-shrink: 0;
+ }
+
+ .VPNavBarTitle .title {
+ padding: 0 !important;
+ }
+
+ .VPNavBar.has-sidebar .content {
+ padding-left: var(--swanlab-nav-title-width) !important;
+ padding-right: 24px !important;
+ }
+
+ .VPNavBar:not(.has-sidebar) .content {
+ padding-left: 0 !important;
+ padding-right: 24px !important;
+ }
+
+ .VPSidebar {
+ padding-top: 24px !important;
+ }
+
+ .VPSidebar .curtain {
+ display: none;
+ }
+}
+
+/* ===== Search bar: fixed desktop rhythm, responsive smaller screens ===== */
div.VPNavBarSearch.search {
- padding: 0px;
- margin-left: 20px;
- margin-right: 20px;
- flex-grow: 1;
+ padding: 0;
+ margin-left: 24px;
+ margin-right: 18px;
+ min-width: var(--swanlab-nav-search-min-width);
+ width: var(--swanlab-nav-search-max-width);
+ max-width: var(--swanlab-nav-search-max-width);
+ flex: 0 1 var(--swanlab-nav-search-max-width);
+}
+
+/* Header nav content: keep homepage and docs pages on the same baseline */
+.VPNavBar .content {
+ max-width: none !important;
+ min-width: 0;
+}
+
+.VPNavBar .content-body {
+ min-width: 0;
+}
+
+.VPNavBarSearchButton {
+ width: 100%;
+ justify-content: flex-start;
+}
+
+.VPNavBarSearchButton .text {
+ min-width: 0;
+ overflow: hidden;
+ text-overflow: ellipsis;
+ white-space: nowrap;
+}
+
+.VPNavBarSearchButton .keys {
+ margin-left: auto;
+ flex-shrink: 0;
}
+@media (min-width: 1280px) and (max-width: 1439px) {
+ .VPNavBar .content-body {
+ justify-content: flex-start !important;
+ }
+
+ .VPNavBarMenuLink,
+ .VPFlyout .button {
+ padding-right: 8px !important;
+ padding-left: 8px !important;
+ }
+
+ .header-button,
+ .vp-header-doc-helper-btn,
+ .github-button {
+ margin-left: 6px !important;
+ padding-right: 8px !important;
+ padding-left: 8px !important;
+ }
+}
+
+@media (max-width: 1759px) {
+ div.VPNavBarSearch.search {
+ width: 300px;
+ max-width: 300px;
+ flex-basis: 300px;
+ }
+}
+
+@media (max-width: 1439px) {
+ div.VPNavBarSearch.search {
+ width: 260px;
+ max-width: 260px;
+ flex-basis: 260px;
+ }
+}
+
+@media (min-width: 1280px) and (max-width: 1320px) {
+ div.VPNavBarSearch.search {
+ min-width: 160px;
+ width: 160px;
+ max-width: 160px;
+ margin-left: 16px;
+ margin-right: 12px;
+ flex-basis: 160px;
+ }
+}
+
+@media (min-width: 768px) and (max-width: 1279px) {
+ .VPNavBarMenu,
+ .VPNavBarTranslations,
+ .VPNavBarAppearance,
+ .VPNavBarSocialLinks,
+ .VPNavBarExtra {
+ display: none !important;
+ }
+
+ .VPNavBarHamburger {
+ display: flex !important;
+ }
+
+ .VPNavScreen {
+ display: block !important;
+ }
+
+ div.VPNavBarSearch.search {
+ min-width: 160px;
+ width: clamp(180px, 36vw, 360px);
+ max-width: 360px;
+ margin-left: 24px;
+ margin-right: 8px;
+ flex: 1 1 280px;
+ }
+}
+
+@media (max-width: 767px) {
+ div.VPNavBarSearch.search {
+ min-width: 0;
+ max-width: none;
+ margin-left: auto;
+ margin-right: 0;
+ flex: 0 0 auto;
+ }
+
+ .VPNavBarSearchButton {
+ width: auto;
+ }
+}
+
+/* ===== 宽屏布局:content 居中,aside 贴右 ===== */
+.VPDoc.has-aside .content {
+ max-width: none !important;
+}
+
+.VPDoc.has-aside .content-container {
+ max-width: 56rem !important;
+ margin: 0 auto;
+ flex: 0 1 auto;
+}
-/* 调整右侧导航栏的定位 */
.VPDoc.has-aside .aside {
position: sticky;
- top: var(--vp-header-height);
+ top: var(--vp-nav-height);
width: 240px;
- max-height: calc(100vh - var(--vp-header-height));
+ flex: 0 0 240px;
+ max-height: calc(100vh - var(--vp-nav-height));
overflow-y: auto;
- margin-left: 32px;
+ padding-right: 32px;
}
-/* 确保在小屏幕上右侧导航栏不会重叠 */
@media (max-width: 1280px) {
.VPDoc.has-aside .aside {
position: static;
width: 100%;
+ flex: none;
margin-top: 24px;
- margin-left: 0;
+ padding-right: 0;
+ }
+}
+
+/* ===== High-resolution screen ===== */
+@media (min-width: 1440px) {
+ .VPDoc.has-aside .content-container {
+ max-width: 60rem !important;
+ }
+}
+
+@media (min-width: 1920px) {
+ .VPDoc.has-aside .content-container {
+ max-width: 64rem !important;
}
}
diff --git a/.vitepress/zh.ts b/.vitepress/zh.ts
index 4482060b..fe13fa3f 100644
--- a/.vitepress/zh.ts
+++ b/.vitepress/zh.ts
@@ -51,7 +51,7 @@ export const zh = defineConfig({
{ text: 'MS-Swift', link: base_path_guide_cloud + '/integration/integration-swift' },
{ text: 'veRL', link: base_path_guide_cloud + '/integration/integration-verl' },
{ text: 'Ultralytics', link: base_path_guide_cloud + '/integration/integration-ultralytics' },
- { text: 'Sb3', link: base_path_guide_cloud + '/integration/integration-sb3' },
+ { text: 'SB3', link: base_path_guide_cloud + '/integration/integration-sb3' },
]
},
{
@@ -255,7 +255,7 @@ function sidebarGuideCloud(): DefaultTheme.SidebarItem[] {
// collapsed: false,
items: [
{ text: '在线支持', link: 'community/online-support' },
- { text: 'Github徽章', link: 'community/github-badge' },
+ { text: 'GitHub徽章', link: 'community/github-badge' },
// { text: '论文引用', link: 'community/paper-cite'},
// { text: '贡献代码', link: 'community/contributing-code'},
// { text: '贡献官方文档', link: 'community/contributing-docs'},
@@ -274,7 +274,7 @@ function sidebarIntegration(): DefaultTheme.SidebarItem[] {
{ text: 'Argparse', link: 'integration-argparse' },
{ text: 'Areal', link: 'integration-areal' },
{ text: 'Ascend NPU & MindSpore', link: 'integration-ascend' },
- { text: 'Catboost', link: 'integration-catboost'},
+ { text: 'CatBoost', link: 'integration-catboost'},
{ text: 'DiffSynth-Studio', link: 'integration-diffsynth-studio' },
{ text: 'EasyR1', link: 'integration-easyr1' },
{ text: 'EvalScope', link: 'integration-evalscope' },
@@ -287,20 +287,20 @@ function sidebarIntegration(): DefaultTheme.SidebarItem[] {
items: [
{ text: 'HuggingFace Accelerate', link: 'integration-huggingface-accelerate' },
{ text: 'HuggingFace Transformers', link: 'integration-huggingface-transformers' },
- { text: 'HuggingFace Trl', link: 'integration-huggingface-trl' },
+ { text: 'HuggingFace TRL', link: 'integration-huggingface-trl' },
{ text: 'Hydra', link: 'integration-hydra' },
{ text: 'Keras', link: 'integration-keras' },
{ text: 'LightGBM', link: 'integration-lightgbm' },
{ text: 'LLaMA-Factory', link: 'integration-llama-factory' },
{ text: 'LLaMA-Factory Online', link: 'integration-llama-factory-online' },
{ text: 'MindSpeed-RL', link: 'integration-mindspeed-rl' },
- { text: 'MLFlow', link: 'integration-mlflow' },
+ { text: 'MLflow', link: 'integration-mlflow' },
{ text: 'MLX LM', link: 'integration-mlx-lm' },
{ text: 'MMEngine', link: 'integration-mmengine' },
{ text: 'MMPretrain', link: 'integration-mmpretrain' },
{ text: 'MMDetection', link: 'integration-mmdetection' },
{ text: 'MMSegmentation', link: 'integration-mmsegmentation' },
- { text: 'Modelscope Swift', link: 'integration-swift' },
+ { text: 'ModelScope Swift', link: 'integration-swift' },
{ text: 'NVIDIA-NeMo RL', link: 'integration-nvidia-nemo-rl' },
]
},
@@ -309,7 +309,7 @@ function sidebarIntegration(): DefaultTheme.SidebarItem[] {
// collapsed: false,
items: [
{ text: 'OpenAI', link: 'integration-openai' },
- { text: 'Omegaconf', link: 'integration-omegaconf' },
+ { text: 'OmegaConf', link: 'integration-omegaconf' },
{ text: 'PaddleDetection', link: 'integration-paddledetection' },
{ text: 'PaddleNLP', link: 'integration-paddlenlp' },
{ text: 'PaddleYOLO', link: 'integration-paddleyolo' },
@@ -320,9 +320,9 @@ function sidebarIntegration(): DefaultTheme.SidebarItem[] {
{ text: 'RLinf', link: 'integration-rlinf' },
{ text: 'ROLL', link: 'integration-roll' },
{ text: 'Sentence Transformers', link: 'integration-sentence-transformers' },
- { text: 'Specforge', link: 'integration-specforge' },
- { text: 'Stable Baseline3', link: 'integration-sb3' },
- { text: 'Tensorboard', link: 'integration-tensorboard' },
+ { text: 'SpecForge', link: 'integration-specforge' },
+ { text: 'Stable Baselines3', link: 'integration-sb3' },
+ { text: 'TensorBoard', link: 'integration-tensorboard' },
]
},
{
@@ -346,10 +346,10 @@ function sidebarExamples(): DefaultTheme.SidebarItem[] {
text: '入门',
// collapsed: false,
items: [
- { text: 'Hello_World', link: 'hello_world' },
+ { text: 'Hello World', link: 'hello_world' },
{ text: 'MNIST手写体识别', link: 'mnist' },
{ text: 'FashionMNIST', link: 'fashionmnist' },
- { text: 'Cifar10图像分类', link: 'cifar10' },
+ { text: 'CIFAR10图像分类', link: 'cifar10' },
]
},
{
diff --git a/en/api/cli-swanlab-convert.md b/en/api/cli-swanlab-convert.md
index d8f7e894..a7a9bdab 100644
--- a/en/api/cli-swanlab-convert.md
+++ b/en/api/cli-swanlab-convert.md
@@ -11,7 +11,7 @@ swanlab convert [OPTIONS]
| `-w`, `--workspace` | Set the workspace where the SwanLab project is located, default is None. |
| `-l`, `--logdir` | Set the log file save path for the SwanLab project, default is None. |
| `--cloud` | Set whether the SwanLab project logs are uploaded to the cloud, default is True. |
-| `--tb-logdir` | Path to the Tensorboard log files (tfevent) to be converted. |
+| `--tb-logdir` | Path to the TensorBoard log files (tfevent) to be converted. |
| `--wb-project` | Name of the Wandb project to be converted. |
| `--wb-entity` | Entity where the Wandb project to be converted is located. |
| `--wb-runid` | ID of the Wandb Run to be converted. |
@@ -19,13 +19,13 @@ swanlab convert [OPTIONS]
## Introduction
Convert content from other logging tools into SwanLab projects.
-Supported tools for conversion include: `Tensorboard`, `Weights & Biases`.
+Supported tools for conversion include: `TensorBoard`, `Weights & Biases`.
## Usage Examples
-### Tensorboard
+### TensorBoard
-[Integration - Tensorboard](/en/guide_cloud/integration/integration-tensorboard.md)
+[Integration - TensorBoard](/en/guide_cloud/integration/integration-tensorboard.md)
### Weights & Biases
diff --git a/en/api/py-sync-mlflow.md b/en/api/py-sync-mlflow.md
index 543bf940..218705cf 100644
--- a/en/api/py-sync-mlflow.md
+++ b/en/api/py-sync-mlflow.md
@@ -1,3 +1,3 @@
# swanlab.sync_mlflow
-Sync MLFlow projects to SwanLab, [Documentation](/en/guide_cloud/integration/integration-mlflow.md)
+Sync MLflow projects to SwanLab, [Documentation](/en/guide_cloud/integration/integration-mlflow.md)
diff --git a/en/examples/audio_classification.md b/en/examples/audio_classification.md
index 585315ae..bf192888 100644
--- a/en/examples/audio_classification.md
+++ b/en/examples/audio_classification.md
@@ -12,7 +12,7 @@ In current audio classification applications, it is often used for audio annotat
In this article, we will train a ResNet series model on the GTZAN dataset using the PyTorch framework, and use [SwanLab](https://swanlab.cn) to monitor the training process and evaluate the model's performance.
-* Github: [https://github.com/Zeyi-Lin/PyTorch-Audio-Classification](https://github.com/Zeyi-Lin/PyTorch-Audio-Classification)
+* GitHub: [https://github.com/Zeyi-Lin/PyTorch-Audio-Classification](https://github.com/Zeyi-Lin/PyTorch-Audio-Classification)
* Dataset: [https://pan.baidu.com/s/14CTI_9MD1vXCqyVxmAbeMw?pwd=1a9e](https://pan.baidu.com/s/14CTI_9MD1vXCqyVxmAbeMw?pwd=1a9e) Extraction Code: 1a9e
* SwanLab Experiment Logs: [https://swanlab.cn/@ZeyiLin/PyTorch\_Audio\_Classification-simple/charts](https://swanlab.cn/@ZeyiLin/PyTorch\_Audio\_Classification-simple/charts)
* More Experiment Logs: [https://swanlab.cn/@ZeyiLin/PyTorch\_Audio\_Classification/charts](https://swanlab.cn/@ZeyiLin/PyTorch\_Audio\_Classification/charts)
diff --git a/en/examples/cats_dogs_classification.md b/en/examples/cats_dogs_classification.md
index 9c616eef..128fa483 100644
--- a/en/examples/cats_dogs_classification.md
+++ b/en/examples/cats_dogs_classification.md
@@ -11,7 +11,7 @@ Cat and dog classification is one of the most fundamental tasks in computer visi
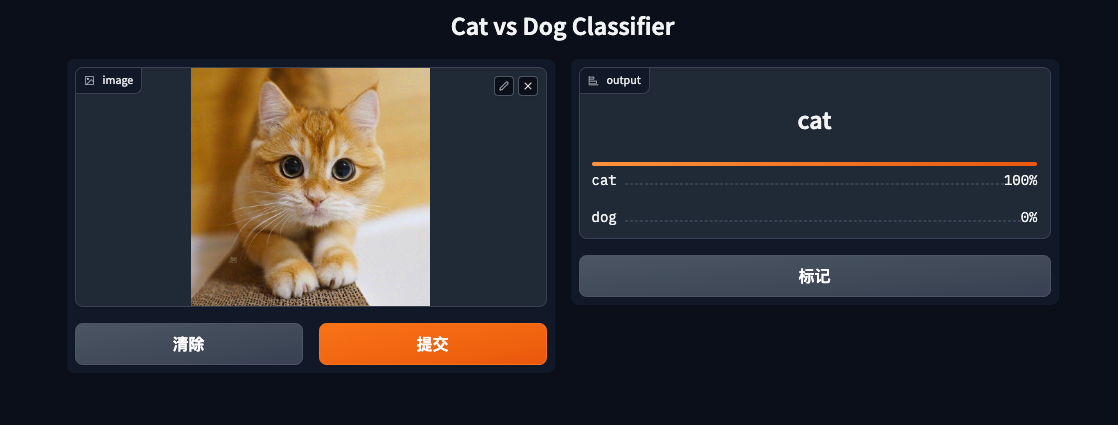
- You can view the experiment process on this webpage: [Cat and Dog Classification | SwanLab](https://swanlab.cn/@ZeyiLin/Cats_Dogs_Classification/runs/jzo93k112f15pmx14vtxf/chart)
-- Code: [Github](https://github.com/Zeyi-Lin/Resnet50-cats_vs_dogs)
+- Code: [GitHub](https://github.com/Zeyi-Lin/Resnet50-cats_vs_dogs)
- Online Demo: [HuggingFace](https://huggingface.co/spaces/TheEeeeLin/Resnet50-cats_vs_dogs)
- Dataset: [Baidu Cloud](https://pan.baidu.com/s/1qYa13SxFM0AirzDyFMy0mQ) Extraction code: 1ybm
- Three open-source libraries: [SwanLab](https://github.com/swanhubx/swanlab), [Gradio](https://github.com/gradio-app/gradio), [PyTorch](https://github.com/pytorch/pytorch)
@@ -46,7 +46,7 @@ Their respective functions are:
### 1.3 Download the Cat and Dog Classification Dataset
-The dataset source is the [Cat and Dog Classification Dataset](https://modelscope.cn/datasets/tany0699/cats_and_dogs/summary) on Modelscope, which contains 275 images for training and 70 images for testing, totaling less than 10MB.
+The dataset source is the [Cat and Dog Classification Dataset](https://modelscope.cn/datasets/tany0699/cats_and_dogs/summary) on ModelScope, which contains 275 images for training and 70 images for testing, totaling less than 10MB.
I have organized the data, so it is recommended to download it using the following Baidu Netdisk link:
> Baidu Netdisk: Link: https://pan.baidu.com/s/1qYa13SxFM0AirzDyFMy0mQ Extraction code: 1ybm
@@ -216,7 +216,7 @@ optimizer = torch.optim.Adam(model.parameters(), lr=lr)
### 2.6 Initialize SwanLab
In training, we use the `swanlab` library as the experiment management and metric visualization tool.
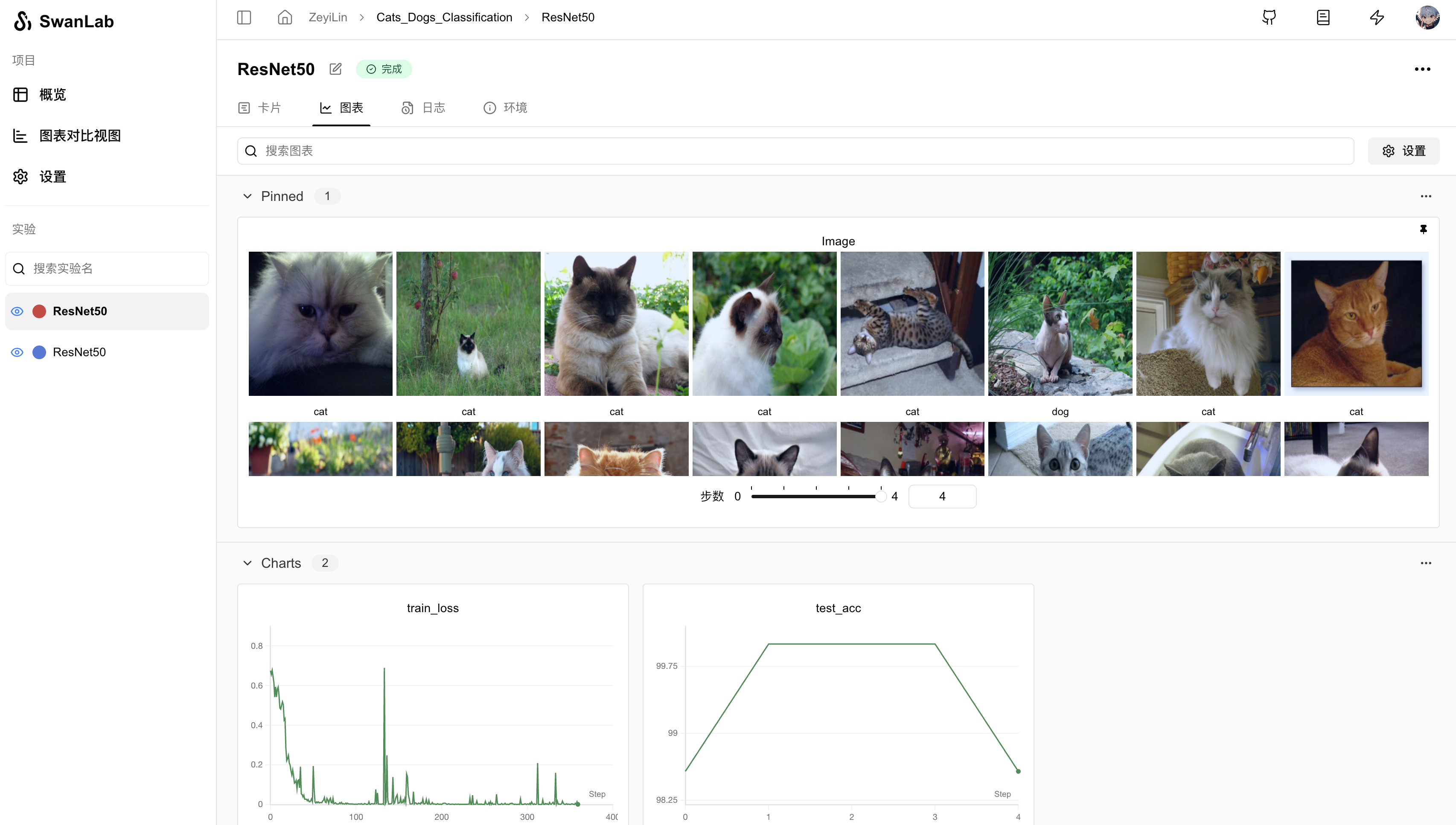
-[swanlab](https://github.com/SwanHubX/SwanLab) is an open-source training chart visualization library similar to Tensorboard, with a lighter volume and more friendly API. In addition to recording metrics, it can automatically record training logs, hardware environment, Python environment, training time, and other information.
+[swanlab](https://github.com/SwanHubX/SwanLab) is an open-source training chart visualization library similar to TensorBoard, with a lighter volume and more friendly API. In addition to recording metrics, it can automatically record training logs, hardware environment, Python environment, training time, and other information.
@@ -544,8 +544,8 @@ If this was helpful, please give it a thumbs up and save it!
## 4. Related Links
- View the experiment process online: [Cat and Dog Classification · SwanLab](https://swanlab.cn/@ZeyiLin/Cats_Dogs_Classification/runs/jzo93k112f15pmx14vtxf/chart)
-- SwanLab: [Github](https://github.com/SwanHubX/SwanLab)
-- Cat and Dog Classification Code: [Github](https://github.com/xiaolin199912/Resnet50-cats_vs_dogs)
+- SwanLab: [GitHub](https://github.com/SwanHubX/SwanLab)
+- Cat and Dog Classification Code: [GitHub](https://github.com/xiaolin199912/Resnet50-cats_vs_dogs)
- Online Demo: [HuggingFace](https://huggingface.co/spaces/TheEeeeLin/Resnet50-cats_vs_dogs)
- Cat and Dog Classification Dataset (300 images): [ModelScope](https://modelscope.cn/datasets/tany0699/cats_and_dogs/summary)
- Baidu Cloud Download: [Link](https://pan.baidu.com/s/1qYa13SxFM0AirzDyFMy0mQ) Extraction code: 1ybm
diff --git a/en/examples/ner.md b/en/examples/ner.md
index f1f7c88b..f9d2b016 100644
--- a/en/examples/ner.md
+++ b/en/examples/ner.md
@@ -12,9 +12,9 @@ Using Qwen2 as the base model, we perform high-precision Named Entity Recognitio
In this tutorial, we'll fine-tune the [Qwen2-1.5b-Instruct](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary) model on the [Chinese NER](https://huggingface.co/datasets/qgyd2021/chinese_ner_sft) dataset while monitoring the training process and evaluating model performance using [SwanLab](https://swanlab.cn).
-• Code: See Section 5 or [Github](https://github.com/Zeyi-Lin/LLM-Finetune)
+• Code: See Section 5 or [GitHub](https://github.com/Zeyi-Lin/LLM-Finetune)
• Training logs: [Qwen2-1.5B-NER-Fintune - SwanLab](https://swanlab.cn/@ZeyiLin/Qwen2-NER-fintune/runs/9gdyrkna1rxjjmz0nks2c/chart)
-• Model: [Modelscope](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary)
+• Model: [ModelScope](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary)
• Dataset: [chinese_ner_sft](https://huggingface.co/datasets/qgyd2021/chinese_ner_sft)
• SwanLab: [https://swanlab.cn](https://swanlab.cn)
@@ -114,7 +114,7 @@ Download the dataset from [chinese_ner_sft - huggingface](https://huggingface.co
## 3. Load the Model
-We'll download the Qwen2-1.5B-Instruct model via Modelscope (which has stable domestic speeds in China) and load it into Transformers for training:
+We'll download the Qwen2-1.5B-Instruct model via ModelScope (which has stable domestic speeds in China) and load it into Transformers for training:
```python
from modelscope import snapshot_download, AutoTokenizer
@@ -123,7 +123,7 @@ from transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataC
model_id = "qwen/Qwen2-1.5B-Instruct"
model_dir = "./qwen/Qwen2-1___5B-Instruct"
-# Download Qwen model from Modelscope
+# Download Qwen model from ModelScope
model_dir = snapshot_download(model_id, cache_dir="./", revision="master")
# Load model weights into Transformers
@@ -443,8 +443,8 @@ Output:
## Related Links
-- Code: See Section 5 or [Github](https://github.com/Zeyi-Lin/LLM-Finetune)
+- Code: See Section 5 or [GitHub](https://github.com/Zeyi-Lin/LLM-Finetune)
- Training logs: [Qwen2-1.5B-NER-Fintune - SwanLab](https://swanlab.cn/@ZeyiLin/Qwen2-NER-fintune/runs/9gdyrkna1rxjjmz0nks2c/chart)
-- Model: [Modelscope](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary)
+- Model: [ModelScope](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary)
- Dataset: [chinese_ner_sft](https://huggingface.co/datasets/qgyd2021/chinese_ner_sft)
- SwanLab: [https://swanlab.cn](https://swanlab.cn)
\ No newline at end of file
diff --git a/en/examples/qwen3-medical.md b/en/examples/qwen3-medical.md
index a5cb2c6f..7f11b7c1 100644
--- a/en/examples/qwen3-medical.md
+++ b/en/examples/qwen3-medical.md
@@ -16,9 +16,9 @@ In this article, we will fine-tune the [Qwen3-1.7b](https://www.modelscope.cn/mo
> Full-parameter fine-tuning requires approximately **32GB of GPU memory**. If your GPU memory is insufficient, consider using Qwen3-0.6b or LoRA fine-tuning.
-- **Code**: [Github](https://github.com/Zeyi-Lin/Qwen3-Medical-SFT) (or see Section 5 below)
+- **Code**: [GitHub](https://github.com/Zeyi-Lin/Qwen3-Medical-SFT) (or see Section 5 below)
- **Training Logs**: [qwen3-1.7B-linear - SwanLab](https://swanlab.cn/@ZeyiLin/qwen3-sft-medical/runs/agps0dkifth5l1xytcdyk/chart) (or search "qwen3-sft-medical" in [SwanLab Benchmark Community](https://swanlab.cn/benchmarks))
-- **Model**: [Modelscope](https://modelscope.cn/models/Qwen/Qwen3-1.7B)
+- **Model**: [ModelScope](https://modelscope.cn/models/Qwen/Qwen3-1.7B)
- **Dataset**: [delicate_medical_r1_data](https://modelscope.cn/datasets/krisfu/delicate_medical_r1_data)
- **SwanLab**: [https://swanlab.cn](https://swanlab.cn)
@@ -155,7 +155,7 @@ model = AutoModelForCausalLM.from_pretrained("./Qwen/Qwen3-1.7B", device_map="au
We use **SwanLab** to monitor training and evaluate model performance.
-SwanLab is an open-source, lightweight AI training tracking and visualization tool, often called the "Chinese Weights & Biases + Tensorboard." It supports cloud/offline use and integrates with 40+ frameworks (PyTorch, Transformers, etc.).
+SwanLab is an open-source, lightweight AI training tracking and visualization tool, often called the "Chinese Weights & Biases + TensorBoard." It supports cloud/offline use and integrates with 40+ frameworks (PyTorch, Transformers, etc.).
@@ -348,7 +348,7 @@ print(predict(messages, model, tokenizer))
## References
-- **Code**: [Github](https://github.com/Zeyi-Lin/Qwen3-Medical-SFT)
+- **Code**: [GitHub](https://github.com/Zeyi-Lin/Qwen3-Medical-SFT)
- **Training Logs**: [SwanLab](https://swanlab.cn/@ZeyiLin/qwen3-sft-medical/runs/agps0dkifth5l1xytcdyk/chart)
- **Model**: [ModelScope](https://modelscope.cn/models/Qwen/Qwen3-1.7B)
- **Dataset**: [delicate_medical_r1_data](https://modelscope.cn/datasets/krisfu/delicate_medical_r1_data)
diff --git a/en/examples/qwen_vl_coco.md b/en/examples/qwen_vl_coco.md
index 50efcd75..38af6fdc 100644
--- a/en/examples/qwen_vl_coco.md
+++ b/en/examples/qwen_vl_coco.md
@@ -15,7 +15,7 @@ Qwen2-VL is a multimodal large model developed by Alibaba's Tongyi Lab. This art
LoRA is an efficient fine-tuning method. For a deeper understanding of its principles, refer to the blog: [Zhihu | An In-Depth Explanation of LoRA](https://zhuanlan.zhihu.com/p/650197598).
• Training Process: [Qwen2-VL-finetune](https://swanlab.cn/@ZeyiLin/Qwen2-VL-finetune/runs/pkgest5xhdn3ukpdy6kv5/chart)
-• Github: [Code Repository](https://github.com/Zeyi-Lin/LLM-Finetune/tree/main/qwen2_vl), [self-llm](https://github.com/datawhalechina/self-llm)
+• GitHub: [Code Repository](https://github.com/Zeyi-Lin/LLM-Finetune/tree/main/qwen2_vl), [self-llm](https://github.com/datawhalechina/self-llm)
• Dataset: [coco_2014_caption](https://modelscope.cn/datasets/modelscope/coco_2014_caption/summary)
• Model: [Qwen2-VL-2B-Instruct](https://modelscope.cn/models/Qwen/Qwen2-VL-2B-Instruct)
@@ -80,7 +80,7 @@ Here, "from" represents the role (`user` for human, `assistant` for the model),
**Dataset Download and Processing Steps**
1. **We need to do four things:**
- ◦ Download the coco_2014_caption dataset via Modelscope.
+ ◦ Download the coco_2014_caption dataset via ModelScope.
◦ Load the dataset and save the images locally.
◦ Convert the image paths and captions into a CSV file.
◦ Convert the CSV file into a JSON file.
@@ -99,7 +99,7 @@ MAX_DATA_NUMBER = 500
# Check if the directory already exists
if not os.path.exists('coco_2014_caption'):
- # Download the COCO 2014 image caption dataset from Modelscope
+ # Download the COCO 2014 image caption dataset from ModelScope
ds = MsDataset.load('modelscope/coco_2014_caption', subset_name='coco_2014_caption', split='train')
print(len(ds))
# Set the maximum number of images to process
@@ -187,14 +187,14 @@ With this, the dataset preparation is complete.
## 3. Model Download and Loading
-Here, we use Modelscope to download the Qwen2-VL-2B-Instruct model and load it into Transformers for training:
+Here, we use ModelScope to download the Qwen2-VL-2B-Instruct model and load it into Transformers for training:
```python
from modelscope import snapshot_download, AutoTokenizer
from transformers import TrainingArguments, Trainer, DataCollatorForSeq2Seq, Qwen2VLForConditionalGeneration, AutoProcessor
import torch
-# Download the Qwen2-VL model from Modelscope to a local directory
+# Download the Qwen2-VL model from ModelScope to a local directory
model_dir = snapshot_download("Qwen/Qwen2-VL-2B-Instruct", cache_dir="./", revision="master")
# Load the model weights using Transformers
@@ -365,7 +365,7 @@ def predict(messages, model):
return output_text[0]
-# Download the Qwen2-VL model from Modelscope to a local directory
+# Download the Qwen2-VL model from ModelScope to a local directory
model_dir = snapshot_download("Qwen/Qwen2-VL-2B-Instruct", cache_dir="./", revision="master")
# Load the model weights using Transformers
diff --git a/en/examples/stable_diffusion.md b/en/examples/stable_diffusion.md
index 5e04bd46..2759e472 100644
--- a/en/examples/stable_diffusion.md
+++ b/en/examples/stable_diffusion.md
@@ -12,7 +12,7 @@ Using SD1.5 as a pre-trained model, fine-tuning a Naruto-style text-to-image mod
In this article, we will use the [SD-1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) model to train on the [Naruto](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions) dataset, while monitoring the training process and evaluating model performance using [SwanLab](https://swanlab.cn).
-- Code: [Github](https://github.com/Zeyi-Lin/Stable-Diffusion-Example)
+- Code: [GitHub](https://github.com/Zeyi-Lin/Stable-Diffusion-Example)
- Experiment Log: [SD-naruto - SwanLab](https://swanlab.cn/@ZeyiLin/SD-Naruto/runs/21flglg1lbnqo67a6f1kr/environment/requirements)
- Model: [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
- Dataset: [lambdalabs/naruto-blip-captions](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions)
@@ -93,7 +93,7 @@ If this is your first time using SwanLab, you need to register an account at htt
## 5. Start Training
-Since the training code is relatively long, I have placed it on [Github](https://github.com/Zeyi-Lin/Stable-Diffusion-Example/tree/main). Please clone the code:
+Since the training code is relatively long, I have placed it on [GitHub](https://github.com/Zeyi-Lin/Stable-Diffusion-Example/tree/main). Please clone the code:
```bash
git clone https://github.com/Zeyi-Lin/Stable-Diffusion-Example.git
@@ -228,7 +228,7 @@ image.save("result.png")
## Related Links
-- Code: [Github](https://github.com/Zeyi-Lin/Stable-Diffusion-Example)
+- Code: [GitHub](https://github.com/Zeyi-Lin/Stable-Diffusion-Example)
- Experiment Log: [SD-naruto - SwanLab](https://swanlab.cn/@ZeyiLin/SD-Naruto/runs/21flglg1lbnqo67a6f1kr/environment/requirements)
- Model: [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
- Dataset: [lambdalabs/naruto-blip-captions](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions)
diff --git a/en/examples/unet-medical-segmentation.md b/en/examples/unet-medical-segmentation.md
index ed40dfa8..bdcf908f 100644
--- a/en/examples/unet-medical-segmentation.md
+++ b/en/examples/unet-medical-segmentation.md
@@ -12,7 +12,7 @@ UNet is a convolutional neural network (CNN)-based model for medical image segme
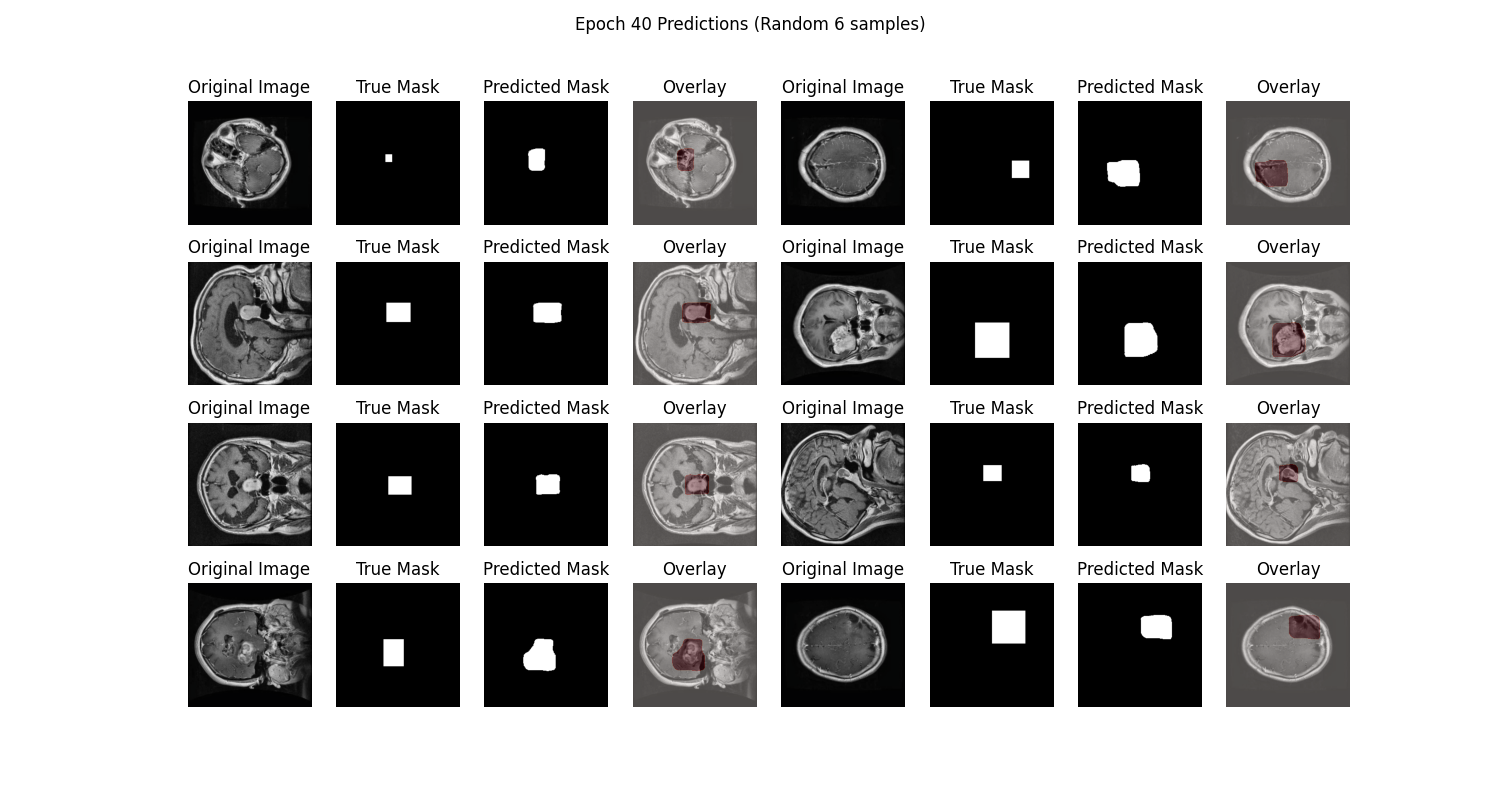
-• **Code**: Full code available in Section 5 or on [Github](https://github.com/Zeyi-Lin/UNet-Medical)
+• **Code**: Full code available in Section 5 or on [GitHub](https://github.com/Zeyi-Lin/UNet-Medical)
• **Training Logs**: [Unet-Medical-Segmentation - SwanLab](https://swanlab.cn/@ZeyiLin/Unet-Medical-Segmentation/runs/67konj7kdqhnfdmusy2u6/chart)
• **Model**: UNet (implemented directly in PyTorch)
• **Dataset**: [brain-tumor-image-dataset-semantic-segmentation - Kaggle](https://www.kaggle.com/datasets/pkdarabi/brain-tumor-image-dataset-semantic-segmentation)
@@ -603,7 +603,7 @@ GPU memory usage was **6.124 GB**, meaning any GPU with ≥6GB VRAM can run this
## References
-• **Code**: Full code in Section 5 or on [Github](https://github.com/Zeyi-Lin/UNet-Medical)
+• **Code**: Full code in Section 5 or on [GitHub](https://github.com/Zeyi-Lin/UNet-Medical)
• **Training Logs**: [Unet-Medical-Segmentation - SwanLab](https://swanlab.cn/@ZeyiLin/Unet-Medical-Segmentation/runs/67konj7kdqhnfdmusy2u6/chart)
• **Model**: UNet (PyTorch implementation)
• **Dataset**: [brain-tumor-image-dataset-semantic-segmentation - Kaggle](https://www.kaggle.com/datasets/pkdarabi/brain-tumor-image-dataset-semantic-segmentation)
diff --git a/en/guide_cloud/community/emotion-machine.md b/en/guide_cloud/community/emotion-machine.md
index 2593208a..32259b24 100644
--- a/en/guide_cloud/community/emotion-machine.md
+++ b/en/guide_cloud/community/emotion-machine.md
@@ -4,5 +4,5 @@ Emotion Machine (Beijing) Technology Co., Ltd. is a high-tech enterprise focused
Mission: To create AI toolchains and empower the global AI developer ecosystem.
**Company**: Emotion Machine (Beijing) Technology Co., Ltd.
-**Location**: Room B205-1, 2nd Floor, Zhongguancun Technology Service Building, No. 1 Building, Courtyard 2, Guanzhuang Road, Chaoyang District, Beijing
+**Location**: Room A402, 4th Floor, Zhongguancun Technology Service Building, No. 1 Building, Courtyard 2, Guanzhuang Road, Chaoyang District, Beijing
**Contact Us**: contact@swanlab.cn
\ No newline at end of file
diff --git a/en/guide_cloud/community/online-support.md b/en/guide_cloud/community/online-support.md
index 9debc61f..92aaa812 100644
--- a/en/guide_cloud/community/online-support.md
+++ b/en/guide_cloud/community/online-support.md
@@ -8,7 +8,7 @@
| Feishu Group |
| --- |
-|
|
+|
|
## 📧 Contact us via Github or email
diff --git a/en/guide_cloud/general/changelog.md b/en/guide_cloud/general/changelog.md
index e8b8e1dd..39fe56a9 100644
--- a/en/guide_cloud/general/changelog.md
+++ b/en/guide_cloud/general/changelog.md
@@ -314,7 +314,7 @@ Released SwanLab Kubernetes version, deployment instructions see [this document]
- Introduced `swanlab.register_callback()`, enabling the registration of callback functions outside of `init`. [Documentation](/api/py-register-callback.html)
- Upgraded `swanlab.login()` with new parameters `host`, `web_host`, and `save`, adapting to the characteristics of self-hosted deployment services and supporting the option to not write user login credentials locally for shared server scenarios. [Documentation](/zh/api/py-login.md)
- Upgraded `swanlab login` with new parameters `host`, `web_host`, and `api-key`. [Documentation](/zh/api/cli-swanlab-login.md)
-- Added support for using `swanlab.sync_mlflow()` to synchronize MLFlow projects to SwanLab. [Documentation](/guide_cloud/integration/integration-mlflow.md)
+- Added support for using `swanlab.sync_mlflow()` to synchronize MLflow projects to SwanLab. [Documentation](/guide_cloud/integration/integration-mlflow.md)
**🤔 Optimizations**
- We have significantly optimized the SDK architecture, improving its performance in scenarios with a large number of metrics.
@@ -343,7 +343,7 @@ Released SwanLab Kubernetes version, deployment instructions see [this document]
**🚀 New Features**
• Added integration with [DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio), [Documentation](/en/guide_cloud/integration/integration-diffsynth-studio.md).
-• Added support for converting **MLFlow** experiments to SwanLab. [Documentation](/en/guide_cloud/integration/integration-mlflow.md).
+• Added support for converting **MLflow** experiments to SwanLab. [Documentation](/en/guide_cloud/integration/integration-mlflow.md).
• Introduced **Project Descriptions**, allowing you to add short notes to your projects.
**Improvements**
@@ -364,7 +364,7 @@ Released SwanLab Kubernetes version, deployment instructions see [this document]
## v0.4.8 - 2025.2.16
**🚀 New Features**
-- Added integration with Modelscope Swift, [Docs](/en/guide_cloud/integration/integration-swift.md)
+- Added integration with ModelScope Swift, [Docs](/en/guide_cloud/integration/integration-swift.md)
- Added `Add Group` and `Move Chart to Another Group` functions
**Optimizations**
@@ -389,7 +389,7 @@ Released SwanLab Kubernetes version, deployment instructions see [this document]
## v0.4.5 - 2025.1.22
**🚀New Features**
-- Added `swanlab.sync_tensorboardX()` and `swanlab.sync_tensorboard_torch()`: Supports synchronizing metrics to SwanLab when using TensorboardX or PyTorch.utils.tensorboard for experiment tracking. [Docs](/en/guide_cloud/integration/integration-tensorboard.md)
+- Added `swanlab.sync_tensorboardX()` and `swanlab.sync_tensorboard_torch()`: Supports synchronizing metrics to SwanLab when using TensorBoardX or PyTorch.utils.tensorboard for experiment tracking. [Docs](/en/guide_cloud/integration/integration-tensorboard.md)
**Optimizations**
- Optimized the code compatibility of `sync_wandb()`
@@ -398,7 +398,7 @@ Released SwanLab Kubernetes version, deployment instructions see [this document]
## v0.4.3 - 2025.1.17
**🚀 New Features**
-- Added `swanlab.sync_wandb()`: Supports synchronizing metrics to SwanLab when using Weights&Biases for experiment tracking. [Docs](/en/guide_cloud/integration/integration-wandb.md)
+- Added `swanlab.sync_wandb()`: Supports synchronizing metrics to SwanLab when using Weights & Biases for experiment tracking. [Docs](/en/guide_cloud/integration/integration-wandb.md)
- Added framework integration: Configuration items will now record the framework being used.
**Optimizations**
diff --git a/en/guide_cloud/general/what-is-swanlab.md b/en/guide_cloud/general/what-is-swanlab.md
index 2d48b63c..f2a4bc14 100644
--- a/en/guide_cloud/general/what-is-swanlab.md
+++ b/en/guide_cloud/general/what-is-swanlab.md
@@ -1,6 +1,6 @@
# Welcome to SwanLab
-[Official Website](https://swanlab.cn) · [Framework Integration](/guide_cloud/integration/integration-huggingface-transformers.html) · [Github](https://github.com/swanhubx/swanlab) · [Quick Start](/guide_cloud/general/quick-start.md) · [Sync WandB](/guide_cloud/integration/integration-wandb.md#_1-sync-tracking) · [Benchmark Community](https://swanlab.cn/benchmarks)
+[Official Website](https://swanlab.cn) · [Framework Integration](/guide_cloud/integration/integration-huggingface-transformers.html) · [GitHub](https://github.com/swanhubx/swanlab) · [Quick Start](/guide_cloud/general/quick-start.md) · [Sync WandB](/guide_cloud/integration/integration-wandb.md#_1-sync-tracking) · [Benchmark Community](https://swanlab.cn/benchmarks)
::: warning 🎉 Self-Hosted Kubernetes Version Officially Released!
The self-hosted Kubernetes version supports local use with features comparable to the public cloud edition. For deployment instructions, see [this document](/en/guide_cloud/self_host/kubernetes-deploy.md).
@@ -62,7 +62,7 @@ Video Demo:
- **Automatic Background Logging**: Logging, hardware environment, Git repo, Python environment, Python library list, project directory.
- **Resume Training Logging**: Supports adding new metric data to the same experiment after training completes/interrupts.
-**2. ⚡️ Comprehensive Framework Integration**: Supports **40+** frameworks including PyTorch, 🤗HuggingFace Transformers, PyTorch Lightning, 🦙LLaMA Factory, MMDetection, Ultralytics, PaddleDetection, LightGBM, XGBoost, Keras, Tensorboard, Weights&Biases, OpenAI, Swift, XTuner, Stable Baseline3, and Hydra.
+**2. ⚡️ Comprehensive Framework Integration**: Supports **40+** frameworks including PyTorch, 🤗HuggingFace Transformers, PyTorch Lightning, 🦙LLaMA Factory, MMDetection, Ultralytics, PaddleDetection, LightGBM, XGBoost, Keras, TensorBoard, Weights & Biases, OpenAI, Swift, XTuner, Stable Baselines3, and Hydra.

@@ -110,12 +110,12 @@ We hope this guide helps you understand SwanLab—we believe it can assist you.
## Comparison with Familiar Tools
-### Tensorboard vs. SwanLab
+### TensorBoard vs. SwanLab
-- **☁️ Online Usage**: SwanLab syncs experiments to the cloud for remote monitoring, sharing, and collaboration. Tensorboard is offline-only.
-- **👥 Collaboration**: SwanLab simplifies team training management, while Tensorboard is designed for individual use.
-- **💻 Centralized Dashboard**: SwanLab aggregates results from any machine; Tensorboard requires manual TFEvent file management.
-- **💪 Powerful Tables**: SwanLab tables support searching/filtering thousands of model versions. Tensorboard struggles with large projects.
+- **☁️ Online Usage**: SwanLab syncs experiments to the cloud for remote monitoring, sharing, and collaboration. TensorBoard is offline-only.
+- **👥 Collaboration**: SwanLab simplifies team training management, while TensorBoard is designed for individual use.
+- **💻 Centralized Dashboard**: SwanLab aggregates results from any machine; TensorBoard requires manual TFEvent file management.
+- **💪 Powerful Tables**: SwanLab tables support searching/filtering thousands of model versions. TensorBoard struggles with large projects.
### W&B vs. SwanLab
@@ -135,7 +135,7 @@ Use SwanLab with your favorite frameworks! Below is our integration list. Submit
- [PyTorch Lightning](/guide_cloud/integration/integration-pytorch-lightning.html)
- [HuggingFace Transformers](/guide_cloud/integration/integration-huggingface-transformers.html)
- [LLaMA Factory](/guide_cloud/integration/integration-llama-factory.html)
-- [Modelscope Swift](/guide_cloud/integration/integration-swift.html)
+- [ModelScope Swift](/guide_cloud/integration/integration-swift.html)
- [DiffSynth-Studio](/guide_cloud/integration/integration-diffsynth-studio.html)
- [Sentence Transformers](/guide_cloud/integration/integration-sentence-transformers.html)
- [OpenMind](https://modelers.cn/docs/zh/openmind-library/1.0.0/basic_tutorial/finetune/finetune_pt.html#%E8%AE%AD%E7%BB%83%E7%9B%91%E6%8E%A7)
@@ -157,9 +157,9 @@ Use SwanLab with your favorite frameworks! Below is our integration list. Submit
- [PaddleYOLO](/guide_cloud/integration/integration-paddleyolo.html)
**Reinforcement Learning**
-- [Stable Baseline3](/guide_cloud/integration/integration-sb3.html)
+- [Stable Baselines3](/guide_cloud/integration/integration-sb3.html)
- [veRL](/guide_cloud/integration/integration-verl.html)
-- [HuggingFace trl](/guide_cloud/integration/integration-huggingface-trl.html)
+- [HuggingFace TRL](/guide_cloud/integration/integration-huggingface-trl.html)
- [EasyR1](/guide_cloud/integration/integration-easyr1.html)
- [AReaL](/guide_cloud/integration/integration-areal.html)
- [ROLL](/guide_cloud/integration/integration-roll.html)
@@ -167,12 +167,12 @@ Use SwanLab with your favorite frameworks! Below is our integration list. Submit
- [MindSpeed-RL](/guide_cloud/integration/integration-mindspeed-rl.html)
**Other Frameworks**:
-- [Tensorboard](/guide_cloud/integration/integration-tensorboard.html)
-- [Weights&Biases](/guide_cloud/integration/integration-wandb.html)
-- [MLFlow](/guide_cloud/integration/integration-mlflow.html)
+- [TensorBoard](/guide_cloud/integration/integration-tensorboard.html)
+- [Weights & Biases](/guide_cloud/integration/integration-wandb.html)
+- [MLflow](/guide_cloud/integration/integration-mlflow.html)
- [HuggingFace Accelerate](/guide_cloud/integration/integration-huggingface-accelerate.html)
- [Hydra](/guide_cloud/integration/integration-hydra.html)
-- [Omegaconf](/guide_cloud/integration/integration-omegaconf.html)
+- [OmegaConf](/guide_cloud/integration/integration-omegaconf.html)
- [OpenAI](/guide_cloud/integration/integration-openai.html)
- [ZhipuAI](/guide_cloud/integration/integration-zhipuai.html)
diff --git a/en/guide_cloud/integration/index.md b/en/guide_cloud/integration/index.md
index 0916e8a9..188b818e 100644
--- a/en/guide_cloud/integration/index.md
+++ b/en/guide_cloud/integration/index.md
@@ -12,7 +12,7 @@ Below is a list of frameworks we have integrated, please submit [Issue](https://
- [PyTorch Lightning](/en/guide_cloud/integration/integration-pytorch-lightning.html)
- [HuggingFace Transformers](/en/guide_cloud/integration/integration-huggingface-transformers.html)
- [LLaMA Factory](/en/guide_cloud/integration/integration-llama-factory.html)
-- [Modelscope Swift](/en/guide_cloud/integration/integration-swift.html)
+- [ModelScope Swift](/en/guide_cloud/integration/integration-swift.html)
- [DiffSynth-Studio](/en/guide_cloud/integration/integration-diffsynth-studio.html)
- [Sentence Transformers](/en/guide_cloud/integration/integration-sentence-transformers.html)
- [PaddleNLP](/en/guide_cloud/integration/integration-paddlenlp.md)
@@ -36,9 +36,9 @@ Below is a list of frameworks we have integrated, please submit [Issue](https://
- [PaddleYOLO](/en/guide_cloud/integration/integration-paddleyolo.html)
## Reinforcement Learning
-- [Stable Baseline3](/en/guide_cloud/integration/integration-sb3.html)
+- [Stable Baselines3](/en/guide_cloud/integration/integration-sb3.html)
- [veRL](/en/guide_cloud/integration/integration-verl.html)
-- [HuggingFace trl](/en/guide_cloud/integration/integration-huggingface-trl.html)
+- [HuggingFace TRL](/en/guide_cloud/integration/integration-huggingface-trl.html)
- [EasyR1](/en/guide_cloud/integration/integration-easyr1.html)
- [AReaL](/en/guide_cloud/integration/integration-areal.html)
- [ROLL](/en/guide_cloud/integration/integration-roll.html)
@@ -47,13 +47,13 @@ Below is a list of frameworks we have integrated, please submit [Issue](https://
- [MindSpeed-RL](/en/guide_cloud/integration/integration-mindspeed-rl.html)
## Others:
-- [Tensorboard](/en/guide_cloud/integration/integration-tensorboard.html)
-- [Weights&Biases](/en/guide_cloud/integration/integration-wandb.html)
-- [MLFlow](/en/guide_cloud/integration/integration-mlflow.html)
+- [TensorBoard](/en/guide_cloud/integration/integration-tensorboard.html)
+- [Weights & Biases](/en/guide_cloud/integration/integration-wandb.html)
+- [MLflow](/en/guide_cloud/integration/integration-mlflow.html)
- [HuggingFace Accelerate](/en/guide_cloud/integration/integration-huggingface-accelerate.html)
- [Ray](/en/guide_cloud/integration/integration-ray.html)
- [Hydra](/en/guide_cloud/integration/integration-hydra.html)
-- [Omegaconf](/en/guide_cloud/integration/integration-omegaconf.html)
+- [OmegaConf](/en/guide_cloud/integration/integration-omegaconf.html)
- [OpenAI](/en/guide_cloud/integration/integration-openai.html)
- [ZhipuAI](/en/guide_cloud/integration/integration-zhipuai.html)
-- [Specforge](/en/guide_cloud/integration/integration-specforge.html)
\ No newline at end of file
+- [SpecForge](/en/guide_cloud/integration/integration-specforge.html)
\ No newline at end of file
diff --git a/en/guide_cloud/integration/integration-huggingface-trl.md b/en/guide_cloud/integration/integration-huggingface-trl.md
index 605ad90a..6f454552 100644
--- a/en/guide_cloud/integration/integration-huggingface-trl.md
+++ b/en/guide_cloud/integration/integration-huggingface-trl.md
@@ -1,4 +1,4 @@
-# 🤗HuggingFace Trl
+# 🤗HuggingFace TRL
[TRL](https://github.com/huggingface/trl) (Transformers Reinforcement Learning) is a leading Python library designed to optimize foundational models through advanced techniques such as Supervised Fine-Tuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Built on top of the 🤗 Transformers ecosystem, TRL supports multiple model architectures and modalities, and can scale across various hardware configurations.
diff --git a/en/guide_cloud/integration/integration-mlflow.md b/en/guide_cloud/integration/integration-mlflow.md
index c8abede9..011edca1 100644
--- a/en/guide_cloud/integration/integration-mlflow.md
+++ b/en/guide_cloud/integration/integration-mlflow.md
@@ -1,6 +1,6 @@
-# MLFlow
+# MLflow
-[MLFlow](https://github.com/mlflow/mlflow) is an open-source platform for managing the machine learning lifecycle, created and maintained by Databricks. It aims to help data scientists and machine learning engineers manage the entire lifecycle of machine learning projects more efficiently, including experiment tracking, model management, model deployment, and collaboration. MLflow is modular and can integrate with any machine learning library, framework, or tool.
+[MLflow](https://github.com/mlflow/mlflow) is an open-source platform for managing the machine learning lifecycle, created and maintained by Databricks. It aims to help data scientists and machine learning engineers manage the entire lifecycle of machine learning projects more efficiently, including experiment tracking, model management, model deployment, and collaboration. MLflow is modular and can integrate with any machine learning library, framework, or tool.

diff --git a/en/guide_cloud/integration/integration-mmengine.md b/en/guide_cloud/integration/integration-mmengine.md
index efcaf42a..34df9df6 100644
--- a/en/guide_cloud/integration/integration-mmengine.md
+++ b/en/guide_cloud/integration/integration-mmengine.md
@@ -25,7 +25,7 @@ Frameworks using MMEngine can all use the following methods to introduce SwanLab
> You can check out which excellent frameworks are available under the [OpenMMLab official GitHub account](https://github.com/open-mmlab).
-Some frameworks, such as [Xtuner](https://github.com/InternLM/xtuner), are not fully compatible with MMEngine and require some simple modifications. You can refer to [SwanLab's Xtuner Integration](https://docs.swanlab.cn/zh/guide_cloud/integration/integration-xtuner.html) to see how to use SwanLab in Xtuner.
+Some frameworks, such as [XTuner](https://github.com/InternLM/xtuner), are not fully compatible with MMEngine and require some simple modifications. You can refer to [SwanLab's XTuner Integration](https://docs.swanlab.cn/zh/guide_cloud/integration/integration-xtuner.html) to see how to use SwanLab in XTuner.
There are two methods to introduce SwanLab for experiment visualization tracking using MMEngine:
diff --git a/en/guide_cloud/integration/integration-omegaconf.md b/en/guide_cloud/integration/integration-omegaconf.md
index 7f273f95..6ae2ec65 100644
--- a/en/guide_cloud/integration/integration-omegaconf.md
+++ b/en/guide_cloud/integration/integration-omegaconf.md
@@ -1,4 +1,4 @@
-# Omegaconf
+# OmegaConf
OmegaConf is a Python library for handling configurations, especially useful in scenarios that require flexible configurations and configuration merging.
Integrating OmegaConf with swanlab is very simple; just pass the `omegaconf` object to `swanlab.config` to record it as hyperparameters:
diff --git a/en/guide_cloud/integration/integration-paddledetection.md b/en/guide_cloud/integration/integration-paddledetection.md
index 7fd6fd40..33a1de9a 100644
--- a/en/guide_cloud/integration/integration-paddledetection.md
+++ b/en/guide_cloud/integration/integration-paddledetection.md
@@ -123,7 +123,7 @@ if self.cfg.get('use_swanlab', False) or 'swanlab' in self.cfg:
self._callbacks.append(SwanLabCallback(self))
```
-With this, you have completed the integration of SwanLab with PaddleYolo! Next, simply add `use_swanlab: True` to the training configuration file to start visualizing and tracking the training.
+With this, you have completed the integration of SwanLab with PaddleYOLO! Next, simply add `use_swanlab: True` to the training configuration file to start visualizing and tracking the training.
## 3. Modify the Configuration File
diff --git a/en/guide_cloud/integration/integration-paddleyolo.md b/en/guide_cloud/integration/integration-paddleyolo.md
index 5582d339..7be7f37d 100644
--- a/en/guide_cloud/integration/integration-paddleyolo.md
+++ b/en/guide_cloud/integration/integration-paddleyolo.md
@@ -1,14 +1,14 @@
-# PaddleYolo
+# PaddleYOLO
-[PaddleYolo](https://github.com/PaddlePaddle/PaddleYOLO) is an object detection library under the PaddlePaddle framework, primarily used for object detection in images and videos. PaddleYOLO contains code related to the YOLO series models, supporting models such as YOLOv3, PP-YOLO, PP-YOLOv2, PP-YOLOE, PP-YOLOE+, RT-DETR, YOLOX, YOLOv5, YOLOv6, YOLOv7, YOLOv8, YOLOv5u, YOLOv7u, YOLOv6Lite, RTMDet, etc.
+[PaddleYOLO](https://github.com/PaddlePaddle/PaddleYOLO) is an object detection library under the PaddlePaddle framework, primarily used for object detection in images and videos. PaddleYOLO contains code related to the YOLO series models, supporting models such as YOLOv3, PP-YOLO, PP-YOLOv2, PP-YOLOE, PP-YOLOE+, RT-DETR, YOLOX, YOLOv5, YOLOv6, YOLOv7, YOLOv8, YOLOv5u, YOLOv7u, YOLOv6Lite, RTMDet, etc.
-You can use PaddleYolo to quickly train object detection models while using SwanLab for experiment tracking and visualization.
+You can use PaddleYOLO to quickly train object detection models while using SwanLab for experiment tracking and visualization.
[Demo](https://swanlab.cn/@ZeyiLin/PaddleYOLO/runs/10zy8zickn2062kubch34/chart)
## 1. Import SwanLabCallback
-First, in your cloned PaddleYolo project, find the `ppdet/engine/callbacks.py` file and add the following code at the bottom:
+First, in your cloned PaddleYOLO project, find the `ppdet/engine/callbacks.py` file and add the following code at the bottom:
```python
class SwanLabCallback(Callback):
@@ -123,7 +123,7 @@ if self.cfg.get('use_swanlab', False) or 'swanlab' in self.cfg:
self._callbacks.append(SwanLabCallback(self))
```
-With this, you have completed the integration of SwanLab with PaddleYolo! Next, simply add `use_swanlab: True` to the training configuration file to start visualizing and tracking the training.
+With this, you have completed the integration of SwanLab with PaddleYOLO! Next, simply add `use_swanlab: True` to the training configuration file to start visualizing and tracking the training.
## 3. Modify the Configuration File
diff --git a/en/guide_cloud/integration/integration-sb3.md b/en/guide_cloud/integration/integration-sb3.md
index 12af81ad..7981b060 100644
--- a/en/guide_cloud/integration/integration-sb3.md
+++ b/en/guide_cloud/integration/integration-sb3.md
@@ -1,4 +1,4 @@
-# Stable-Baseline3
+# Stable Baselines3
[](https://colab.research.google.com/drive/1JfU4oCKCS7FQE_AXqZ3k9Bt1vmK-6pMO?usp=sharing)
diff --git a/en/guide_cloud/integration/integration-specforge.md b/en/guide_cloud/integration/integration-specforge.md
index adda89f2..c39e998d 100644
--- a/en/guide_cloud/integration/integration-specforge.md
+++ b/en/guide_cloud/integration/integration-specforge.md
@@ -1,4 +1,4 @@
-# Specforge
+# SpecForge
[SpecForge](https://github.com/sgl-project/SpecForge) is an ecosystem project developed by the SGLang team. It is a framework for training speculative decoding models, enabling developers to seamlessly integrate them into the SGLang service framework to accelerate inference speed.
@@ -8,7 +8,7 @@
You can use SpecForge for rapid model training while employing SwanLab for experiment tracking and visualization.
-## Integrating Specforge with SwanLab
+## Integrating SpecForge with SwanLab
> Reference Documentation: https://docs.sglang.io/SpecForge/basic_usage/training.html#experiment-tracking
diff --git a/en/guide_cloud/integration/integration-swift.md b/en/guide_cloud/integration/integration-swift.md
index 46b77dc7..252542ad 100644
--- a/en/guide_cloud/integration/integration-swift.md
+++ b/en/guide_cloud/integration/integration-swift.md
@@ -1,9 +1,9 @@
-# Modelscope Swift
+# ModelScope Swift
> SwanLab has been officially integrated with Swift, see: [#3142](https://github.com/modelscope/ms-swift/pull/3142)
> Online Demo: [swift-robot](https://swanlab.cn/@ZeyiLin/swift-robot/runs/9lc9rmmwm4hh7ay1vkzd7/chart)
-[Modelscope](https://modelscope.cn/)'s [Swift](https://github.com/modelscope/swift) is a framework that integrates model training, fine-tuning, inference, and deployment.
+[ModelScope](https://modelscope.cn/)'s [Swift](https://github.com/modelscope/swift) is a framework that integrates model training, fine-tuning, inference, and deployment.

diff --git a/en/guide_cloud/integration/integration-tensorboard.md b/en/guide_cloud/integration/integration-tensorboard.md
index 9053077b..fb506b6a 100644
--- a/en/guide_cloud/integration/integration-tensorboard.md
+++ b/en/guide_cloud/integration/integration-tensorboard.md
@@ -1,13 +1,13 @@
-# Tensorboard
+# TensorBoard
[TensorBoard](https://github.com/tensorflow/tensorboard) is a visualization tool provided by Google TensorFlow, designed to help understand, debug, and optimize machine learning models. It displays various metrics and data during the training process through a graphical interface, allowing developers to intuitively understand the performance and behavior of their models.
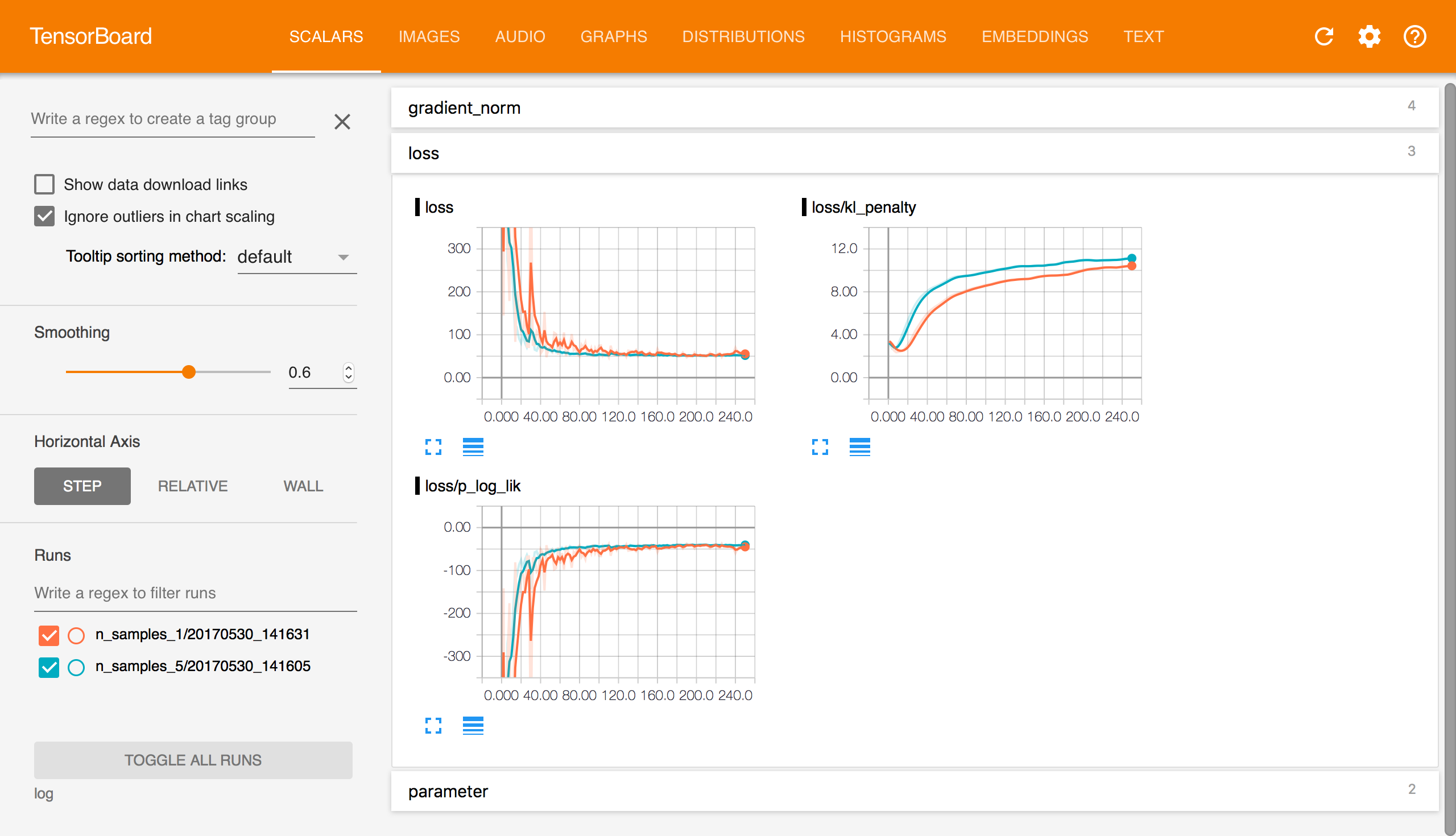
-**You can synchronize projects tracked with Tensorboard to SwanLab in two ways:**
+**You can synchronize projects tracked with TensorBoard to SwanLab in two ways:**
-- **Synchronous Tracking**: If your current project uses Tensorboard for experiment tracking, you can use the `swanlab.sync_tensorboardX()` or `swanlab.sync_tensorboard_torch()` commands to synchronize metrics to SwanLab while running your training script.
-- **Convert Existing Projects**: If you want to copy a project from Tensorboard to SwanLab, you can use `swanlab convert` to convert a directory containing TFevent files into a SwanLab project.
+- **Synchronous Tracking**: If your current project uses TensorBoard for experiment tracking, you can use the `swanlab.sync_tensorboardX()` or `swanlab.sync_tensorboard_torch()` commands to synchronize metrics to SwanLab while running your training script.
+- **Convert Existing Projects**: If you want to copy a project from TensorBoard to SwanLab, you can use `swanlab convert` to convert a directory containing TFevent files into a SwanLab project.
::: info
The current version only supports converting scalar and image charts.
@@ -17,9 +17,9 @@ The current version only supports converting scalar and image charts.
## 1. Synchronous Tracking
-### 1.1 TensorboardX: Add the `sync_tensorboardX` Command
+### 1.1 TensorBoardX: Add the `sync_tensorboardX` Command
-If you are using TensorboardX, you can add the `swanlab.sync_tensorboardX()` command anywhere before executing `tensorboardX.SummaryWriter()` to synchronize metrics to SwanLab during training.
+If you are using TensorBoardX, you can add the `swanlab.sync_tensorboardX()` command anywhere before executing `tensorboardX.SummaryWriter()` to synchronize metrics to SwanLab during training.
```python
import swanlab
@@ -32,7 +32,7 @@ writer = SummaryWriter(log_dir='./runs')
### 1.2 PyTorch: Add the `sync_tensorboard_torch` Command
-If you are using PyTorch's built-in Tensorboard, you can add the `swanlab.sync_tensorboard_torch()` command anywhere before executing `torch.utils.tensorboard.SummaryWriter()` to synchronize metrics to SwanLab during training.
+If you are using PyTorch's built-in TensorBoard, you can add the `swanlab.sync_tensorboard_torch()` command anywhere before executing `torch.utils.tensorboard.SummaryWriter()` to synchronize metrics to SwanLab during training.
```python
import swanlab
@@ -45,11 +45,11 @@ writer = torch.utils.tensorboard.SummaryWriter(log_dir='./runs')
### 1.3 Alternative Approach
-You can also manually initialize SwanLab first and then run the Tensorboard code.
+You can also manually initialize SwanLab first and then run the TensorBoard code.
::: code-group
-```python [TensorboardX]
+```python [TensorBoardX]
import swanlab
from tensorboardX import SummaryWriter
@@ -78,7 +78,7 @@ writer = SummaryWriter(log_dir='./runs')
::: code-group
-```python [TensorboardX]
+```python [TensorBoardX]
import swanlab
from tensorboardX import SummaryWriter
import random
@@ -134,7 +134,7 @@ Use the following command to synchronize tensorboard logs:
swanlab convert -t tensorboard --tb_logdir [TFEVENT_LOGDIR]
```
-Here, `[TFEVENT_LOGDIR]` refers to the path of the log files generated when you previously recorded experiments with Tensorboard.
+Here, `[TFEVENT_LOGDIR]` refers to the path of the log files generated when you previously recorded experiments with TensorBoard.
The SwanLab Converter will automatically detect `tfevent` files in the specified directory and its subdirectories (default depth is 3) and create a SwanLab experiment for each `tfevent` file.
@@ -166,7 +166,7 @@ from swanlab.converter import TFBConverter
tfb_converter = TFBConverter(
convert_dir="./runs",
- project="Tensorboard-Converter",
+ project="TensorBoard-Converter",
workspace="SwanLab",
logdir="./logs",
)
@@ -175,14 +175,14 @@ tfb_converter.run()
The equivalent CLI command:
```bash
-swanlab convert -t tensorboard --tb_logdir ./runs -p Tensorboard-Converter -w SwanLab -l ./logs
+swanlab convert -t tensorboard --tb_logdir ./runs -p TensorBoard-Converter -w SwanLab -l ./logs
```
-Executing the above script will create a project named `Tensorboard-Converter` in the `SwanLab` workspace, convert the `tfevent` files in the `./runs` directory into SwanLab experiments, and save the logs generated by SwanLab in the `./logs` directory.
+Executing the above script will create a project named `TensorBoard-Converter` in the `SwanLab` workspace, convert the `tfevent` files in the `./runs` directory into SwanLab experiments, and save the logs generated by SwanLab in the `./logs` directory.
## 3. API Mapping Table
-| Function | Tensorboard | SwanLab |
+| Function | TensorBoard | SwanLab |
| ---- | ---------- | --------------------- |
| Create Experiment | writer = SummaryWriter(logdir="./runs") | swanlab.init(logdir="./runs") |
| Record Scalar Metrics | writer.add_scalar(key, value, step) | swanlab.log({key, value}, step=step) |
diff --git a/en/guide_cloud/integration/integration-wandb.md b/en/guide_cloud/integration/integration-wandb.md
index d179e317..7227cb2e 100644
--- a/en/guide_cloud/integration/integration-wandb.md
+++ b/en/guide_cloud/integration/integration-wandb.md
@@ -1,19 +1,19 @@
# Weights & Biases
-Weights & Biases (Wandb) is a platform for experiment tracking, model optimization, and collaboration in machine learning and deep learning projects. W&B provides powerful tools to log and visualize experimental results, helping data scientists and researchers better manage and share their work.
+Weights & Biases (W&B) is a platform for experiment tracking, model optimization, and collaboration in machine learning and deep learning projects. W&B provides powerful tools to log and visualize experimental results, helping data scientists and researchers better manage and share their work.

:::warning Synchronization Tutorials for Other Tools
- [TensorBoard](/guide_cloud/integration/integration-tensorboard.md)
-- [MLFlow](/guide_cloud/integration/integration-mlflow.md)
+- [MLflow](/guide_cloud/integration/integration-mlflow.md)
:::
-**You can sync projects from Wandb to SwanLab in three ways:**
+**You can sync projects from W&B to SwanLab in three ways:**
1. **Real-time Syncing**: If your current project uses wandb for experiment tracking, you can use the `swanlab.sync_wandb()` command to simultaneously log metrics to SwanLab while running your training script.
-2. **Convert existing projects from the wandb website**: If you want to copy projects from the wandb server (wandb.ai or privately deployed wandb) to SwanLab, you can use `swanlab convert` to transform existing Wandb projects into SwanLab projects.
+2. **Convert existing projects from the W&B website**: If you want to copy projects from the wandb server (wandb.ai or privately deployed wandb) to SwanLab, you can use `swanlab convert` to transform existing W&B projects into SwanLab projects.
3. **Convert existing projects from local wandb log files**: If you want to upload local wandb log files to SwanLab, you can use `swanlab convert` to transform local wandb log files into SwanLab projects.
::: info
@@ -26,7 +26,7 @@ The current version only supports converting scalar charts.
### 1.1 Add the `sync_wandb` Command
-Add the `swanlab.sync_wandb()` command anywhere in your code before `wandb.init()` to synchronize Wandb metrics to SwanLab during training.
+Add the `swanlab.sync_wandb()` command anywhere in your code before `wandb.init()` to synchronize W&B metrics to SwanLab during training.
```python
import swanlab
@@ -45,7 +45,7 @@ With this implementation, `wandb.init()` will simultaneously initialize SwanLab,
**`sync_wandb` supports two parameters:**
- `mode`: SwanLab logging mode, supporting `cloud`, `local`, and `disabled`.
-- `wandb_run`: If set to **False**, data will not be uploaded to Wandb (equivalent to `wandb.init(mode="offline")`).
+- `wandb_run`: If set to **False**, data will not be uploaded to W&B (equivalent to `wandb.init(mode="offline")`).
:::
@@ -106,7 +106,7 @@ Location of `runid`:
### 2.2 Method 1: Command-Line Conversion
-First, ensure you are logged into Wandb and have access to the target project.
+First, ensure you are logged into W&B and have access to the target project.
Conversion command:
@@ -121,9 +121,9 @@ Supported parameters:
- `-w`: SwanLab workspace name.
- `--mode`: (str) Logging mode (default: `"cloud"`), options: `["cloud", "local", "offline", "disabled"]`.
- `-l`: Log directory path.
-- `--wb-project`: Wandb project name to convert.
-- `--wb-entity`: Wandb entity (username/team) where the project resides.
-- `--wb-runid`: Wandb Run ID (specific experiment under the project).
+- `--wb-project`: W&B project name to convert.
+- `--wb-entity`: W&B entity (username/team) where the project resides.
+- `--wb-runid`: W&B Run ID (specific experiment under the project).
If `--wb-runid` is omitted, all Runs under the project will be converted. If specified, only the selected Run will be converted.
@@ -167,8 +167,8 @@ This achieves the same result as command-line conversion.
`WandbConverter.run` parameters:
- `wb_project`: Wandb project name.
-- `wb_entity`: Wandb entity (username/team).
-- `wb_runid`: Wandb Run ID (specific experiment).
+- `wb_entity`: W&B entity (username/team).
+- `wb_runid`: W&B Run ID (specific experiment).
**Asynchronous Conversion (Download Data Locally First, Then Upload to SwanLab)**
diff --git a/en/guide_cloud/integration/integration-xtuner.md b/en/guide_cloud/integration/integration-xtuner.md
index d136aa34..2f0dd512 100644
--- a/en/guide_cloud/integration/integration-xtuner.md
+++ b/en/guide_cloud/integration/integration-xtuner.md
@@ -1,4 +1,4 @@
-# Xtuner
+# XTuner
[XTuner](https://github.com/InternLM/xtuner) is a highly efficient, flexible, and versatile tool library for fine-tuning large models.
@@ -6,15 +6,15 @@
-Xtuner supports adaptation with multiple open-source large models such as InternLM and Llama, and can perform tasks such as incremental pre-training, instruction fine-tuning, and tool-based instruction fine-tuning. In terms of hardware requirements, developers can train with the lowest consumer-grade graphics cards, such as Tesla T4 and A100, to achieve specific demand capabilities of large models.
+XTuner supports adaptation with multiple open-source large models such as InternLM and Llama, and can perform tasks such as incremental pre-training, instruction fine-tuning, and tool-based instruction fine-tuning. In terms of hardware requirements, developers can train with the lowest consumer-grade graphics cards, such as Tesla T4 and A100, to achieve specific demand capabilities of large models.
-Xtuner supports online tracking using SwanLab through MMEngine. By adding a few lines of code to the configuration file, you can track and visualize metrics such as loss and memory usage.
+XTuner supports online tracking using SwanLab through MMEngine. By adding a few lines of code to the configuration file, you can track and visualize metrics such as loss and memory usage.
-## Visualizing and Tracking Xtuner Fine-Tuning Progress with SwanLab
+## Visualizing and Tracking XTuner Fine-Tuning Progress with SwanLab
Open the configuration file you want to train (for example, [qwen1_5_7b_chat_full_alpaca_e3.py](https://github.com/InternLM/xtuner/blob/main/xtuner/configs/qwen/qwen1_5/qwen1_5_7b_chat/qwen1_5_7b_chat_full_alpaca_e3.py)), find the `visualizer` parameter, and replace it with:
diff --git a/en/index.md b/en/index.md
index 9059b589..f366c2c9 100644
--- a/en/index.md
+++ b/en/index.md
@@ -187,10 +187,9 @@ features:
-
diff --git a/en/plugin/notification-bark.md b/en/plugin/notification-bark.md
index 5c2830f5..9459d14b 100644
--- a/en/plugin/notification-bark.md
+++ b/en/plugin/notification-bark.md
@@ -7,7 +7,7 @@ You can think of it as a "privately customized" push service, similar to IFTTT o
If you want to be notified via a Bark message as soon as training is complete or an error occurs, it is highly recommended that you use the Bark notification plugin.
:::warning Improving the Plugin
-SwanLab plugins are open source. You can view the [Github source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). We welcome your suggestions and PRs!
+SwanLab plugins are open source. You can view the [GitHub source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). We welcome your suggestions and PRs!
:::
[[toc]]
diff --git a/en/plugin/notification-dingtalk.md b/en/plugin/notification-dingtalk.md
index b39a8a5a..d7ca250c 100644
--- a/en/plugin/notification-dingtalk.md
+++ b/en/plugin/notification-dingtalk.md
@@ -5,7 +5,7 @@
If you wish to receive immediate notifications via [DingTalk](https://www.dingtalk.com/) when training completes or an error occurs, the DingTalk notification plugin is highly recommended.
:::warning Plugin Improvement
-SwanLab plugins are open-source. You can view the [Github source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Your suggestions and PRs are welcome!
+SwanLab plugins are open-source. You can view the [GitHub source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Your suggestions and PRs are welcome!
:::
[[toc]]
diff --git a/en/plugin/notification-discord.md b/en/plugin/notification-discord.md
index fca3f508..8f61f598 100644
--- a/en/plugin/notification-discord.md
+++ b/en/plugin/notification-discord.md
@@ -5,7 +5,7 @@ If you wish to receive immediate [Discord](https://discord.com/) notifications u

:::warning Improve the Plugin
-SwanLab plugins are open-source. You can view the [Github source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
+SwanLab plugins are open-source. You can view the [GitHub source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
:::
[[toc]]
diff --git a/en/plugin/notification-email.md b/en/plugin/notification-email.md
index 2ee7c991..b6c984dc 100644
--- a/en/plugin/notification-email.md
+++ b/en/plugin/notification-email.md
@@ -5,7 +5,7 @@
If you wish to receive immediate email notifications upon training completion or errors, the `Email Notification` plugin is highly recommended.
:::warning Improve the Plugin
-SwanLab plugins are open-source. You can view the [Github source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
+SwanLab plugins are open-source. You can view the [GitHub source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
:::
[[toc]]
diff --git a/en/plugin/notification-lark.md b/en/plugin/notification-lark.md
index c061c49a..328737b4 100644
--- a/en/plugin/notification-lark.md
+++ b/en/plugin/notification-lark.md
@@ -5,7 +5,7 @@
If you wish to receive immediate Lark notifications upon training completion or errors, the Lark Notification plugin is highly recommended.
:::warning Improve the Plugin
-SwanLab plugins are open-source. You can view the [Github source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
+SwanLab plugins are open-source. You can view the [GitHub source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
:::
[[toc]]
diff --git a/en/plugin/notification-slack.md b/en/plugin/notification-slack.md
index ae8de7e7..6d2e2383 100644
--- a/en/plugin/notification-slack.md
+++ b/en/plugin/notification-slack.md
@@ -5,7 +5,7 @@ If you wish to receive immediate [Slack](https://slack.com) notifications upon t

:::warning Improve the Plugin
-SwanLab plugins are open-source. You can view the [Github source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
+SwanLab plugins are open-source. You can view the [GitHub source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
:::
[[toc]]
diff --git a/en/plugin/notification-telegram.md b/en/plugin/notification-telegram.md
index 42e83788..2127efb4 100644
--- a/en/plugin/notification-telegram.md
+++ b/en/plugin/notification-telegram.md
@@ -3,7 +3,7 @@
If you wish to receive immediate [Telegram](https://web.telegram.org) notifications upon training completion or errors, the Telegram Notification plugin is highly recommended.
:::warning Improve the Plugin
-SwanLab plugins are open-source. You can view the [Github source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
+SwanLab plugins are open-source. You can view the [GitHub source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
:::
[[toc]]
diff --git a/en/plugin/notification-wxwork.md b/en/plugin/notification-wxwork.md
index bacab688..510a1847 100644
--- a/en/plugin/notification-wxwork.md
+++ b/en/plugin/notification-wxwork.md
@@ -5,7 +5,7 @@
If you wish to receive immediate [WXWork](https://work.weixin.qq.com/) notifications upon training completion or errors, the WXWork Notification plugin is highly recommended.
:::warning Improve the Plugin
-SwanLab plugins are open-source. You can view the [Github source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
+SwanLab plugins are open-source. You can view the [GitHub source code](https://github.com/swanhubx/swanlab/blob/main/swanlab/plugin/notification.py). Suggestions and PRs are welcome!
:::
diff --git a/en/plugin/writer-csv.md b/en/plugin/writer-csv.md
index 9505a719..cefa23d4 100644
--- a/en/plugin/writer-csv.md
+++ b/en/plugin/writer-csv.md
@@ -3,7 +3,7 @@
If you wish to record some configuration information and metrics locally in a CSV file during training (in a format consistent with the "Table View" on the SwanLab webpage), we highly recommend using the `CSV Logger` plugin.
:::warning Improving the Plugin
-All SwanLab plugins are open-source. You can view the [Github source code](https://github.com/SwanHubX/SwanLab/blob/main/swanlab/plugin/writer.py). We welcome your suggestions and PRs!
+All SwanLab plugins are open-source. You can view the [GitHub source code](https://github.com/SwanHubX/SwanLab/blob/main/swanlab/plugin/writer.py). We welcome your suggestions and PRs!
:::
## Plugin Usage
diff --git a/zh/api/cli-swanlab-convert.md b/zh/api/cli-swanlab-convert.md
index b190bfcb..1fe4e80d 100644
--- a/zh/api/cli-swanlab-convert.md
+++ b/zh/api/cli-swanlab-convert.md
@@ -11,28 +11,28 @@ swanlab convert [OPTIONS]
| `-w`, `--workspace` | 设置SwanLab项目所在空间,默认为None。 |
| `-l`, `--logdir` | 设置SwanLab项目的日志文件保存路径,默认为None。 |
| `--cloud` | 设置SwanLab项目是否将日志上传到云端,默认为True。 |
-| `--tb-logdir` | 需要转换的Tensorboard日志文件路径(tfevent) |
-| `--wb-project` | 需要转换的Wandb项目名 |
-| `--wb-entity` | 需要转换的Wandb项目所在实体 |
-| `--wb-runid` | 需要转换的Wandb Run的id |
-| `--mlflow-uri` | 需要转换的MLFlow项目URI |
-| `--mlflow-exp` | 需要转换的MLFlow实验ID |
+| `--tb-logdir` | 需要转换的TensorBoard日志文件路径(tfevent) |
+| `--wb-project` | 需要转换的W&B项目名 |
+| `--wb-entity` | 需要转换的W&B项目所在实体 |
+| `--wb-runid` | 需要转换的W&B Run的id |
+| `--mlflow-uri` | 需要转换的MLflow项目URI |
+| `--mlflow-exp` | 需要转换的MLflow实验ID |
## 介绍
将其他日志工具的内容转换为SwanLab项目。
-支持转换的工具包括:`Tensorboard`、`Weights & Biases`、`MLFlow`。
+支持转换的工具包括:`TensorBoard`、`Weights & Biases`、`MLflow`。
## 使用案例
-### Tensorboard
+### TensorBoard
-[集成-Tensorboard](/guide_cloud/integration/integration-tensorboard.md)
+[集成-TensorBoard](/guide_cloud/integration/integration-tensorboard.md)
### Weights & Biases
[集成-Weights & Biases](/guide_cloud/integration/integration-wandb.md)
-### MLFlow
+### MLflow
-[集成-MLFlow](/guide_cloud/integration/integration-mlflow.md)
\ No newline at end of file
+[集成-MLflow](/guide_cloud/integration/integration-mlflow.md)
\ No newline at end of file
diff --git a/zh/api/py-sync-mlflow.md b/zh/api/py-sync-mlflow.md
index f78f56e2..d7d51666 100644
--- a/zh/api/py-sync-mlflow.md
+++ b/zh/api/py-sync-mlflow.md
@@ -1,3 +1,3 @@
# swanlab.sync_mlflow
-将MLFlow项目同步到SwanLab,[文档](/guide_cloud/integration/integration-mlflow.md)
+将MLflow项目同步到SwanLab,[文档](/guide_cloud/integration/integration-mlflow.md)
diff --git a/zh/course/llm_train_course/01-traditionmodel/3.rnn/rnn_tutorial_2.md b/zh/course/llm_train_course/01-traditionmodel/3.rnn/rnn_tutorial_2.md
index 26b6d64c..8ded28ab 100644
--- a/zh/course/llm_train_course/01-traditionmodel/3.rnn/rnn_tutorial_2.md
+++ b/zh/course/llm_train_course/01-traditionmodel/3.rnn/rnn_tutorial_2.md
@@ -140,7 +140,7 @@ class RnnClsNet(nn.Module):
## 完整训练代码获取与运行
-完整训练代码可以通过Github查看(后文也附了训练代码,防止有读者无法访问github,见[#附录:训练代码](#附录:训练代码)
+完整训练代码可以通过GitHub查看(后文也附了训练代码,防止有读者无法访问github,见[#附录:训练代码](#附录:训练代码)
* GitHub链接:
diff --git a/zh/course/llm_train_course/03-sft/2.ner/README.md b/zh/course/llm_train_course/03-sft/2.ner/README.md
index 12c27313..54909c3f 100644
--- a/zh/course/llm_train_course/03-sft/2.ner/README.md
+++ b/zh/course/llm_train_course/03-sft/2.ner/README.md
@@ -12,9 +12,9 @@
在本文中,我们会使用 [Qwen2-1.5b-Instruct](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary) 模型在 [中文NER](https://huggingface.co/datasets/qgyd2021/chinese_ner_sft) 数据集上做指令微调训练,同时使用[SwanLab](https://swanlab.cn)监控训练过程、评估模型效果。
-- 代码:完整代码直接看本文第5节 或 [Github](https://github.com/Zeyi-Lin/LLM-Finetune)
+- 代码:完整代码直接看本文第5节 或 [GitHub](https://github.com/Zeyi-Lin/LLM-Finetune)
- 实验日志过程:[Qwen2-1.5B-NER-Fintune - SwanLab](https://swanlab.cn/@ZeyiLin/Qwen2-NER-fintune/runs/9gdyrkna1rxjjmz0nks2c/chart)
-- 模型:[Modelscope](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary)
+- 模型:[ModelScope](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary)
- 数据集:[chinese_ner_sft](https://huggingface.co/datasets/qgyd2021/chinese_ner_sft)
- SwanLab:[https://swanlab.cn](https://swanlab.cn)
@@ -455,8 +455,8 @@ print(response)
## 相关链接
-- 代码:完整代码直接看本文第5节 或 [Github](https://github.com/Zeyi-Lin/LLM-Finetune)
+- 代码:完整代码直接看本文第5节 或 [GitHub](https://github.com/Zeyi-Lin/LLM-Finetune)
- 实验日志过程:[Qwen2-1.5B-NER-Fintune - SwanLab](https://swanlab.cn/@ZeyiLin/Qwen2-NER-fintune/runs/9gdyrkna1rxjjmz0nks2c/chart)
-- 模型:[Modelscope](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary)
+- 模型:[ModelScope](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary)
- 数据集:[chinese_ner_sft](https://huggingface.co/datasets/qgyd2021/chinese_ner_sft)
- SwanLab:[https://swanlab.cn](https://swanlab.cn)
\ No newline at end of file
diff --git a/zh/course/llm_train_course/03-sft/4.qwen3-medical-finetune/README.md b/zh/course/llm_train_course/03-sft/4.qwen3-medical-finetune/README.md
index 25b7cc60..a00e9663 100644
--- a/zh/course/llm_train_course/03-sft/4.qwen3-medical-finetune/README.md
+++ b/zh/course/llm_train_course/03-sft/4.qwen3-medical-finetune/README.md
@@ -16,11 +16,11 @@
> 全参数微调需要大约32GB显存,如果你的显存大小不足,可以使用Qwen3-0.6b,或Lora微调。
-- **代码**:[Github](https://github.com/Zeyi-Lin/Qwen3-Medical-SFT),或直接看本文第5节
+- **代码**:[GitHub](https://github.com/Zeyi-Lin/Qwen3-Medical-SFT),或直接看本文第5节
- **实验日志过程**:[qwen3-1.7B-linear - SwanLab](https://swanlab.cn/@ZeyiLin/qwen3-sft-medical/runs/agps0dkifth5l1xytcdyk/chart),或 [SwanLab基线社区](https://swanlab.cn/benchmarks) 搜索“qwen3-sft-medical”
-- **模型**:[Modelscope](https://modelscope.cn/models/Qwen/Qwen3-1.7B)
+- **模型**:[ModelScope](https://modelscope.cn/models/Qwen/Qwen3-1.7B)
- **数据集**:[delicate_medical_r1_data](https://modelscope.cn/datasets/krisfu/delicate_medical_r1_data)
@@ -165,7 +165,7 @@ model = AutoModelForCausalLM.from_pretrained("./Qwen/Qwen3-1.7B", device_map="au
我们使用SwanLab来监控整个训练过程,并评估最终的模型效果。
-SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,面向人工智能与深度学习开发者,提供了一个跟踪、记录、比较、和协作实验的平台,常被称为"中国版 Weights & Biases + Tensorboard"。SwanLab同时支持云端和离线使用,并适配了从PyTorch、Transformers、Lightning再到LLaMA Factory、veRL等40+ AI训练框架。
+SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,面向人工智能与深度学习开发者,提供了一个跟踪、记录、比较、和协作实验的平台,常被称为"中国版 Weights & Biases + TensorBoard"。SwanLab同时支持云端和离线使用,并适配了从PyTorch、Transformers、Lightning再到LLaMA Factory、veRL等40+ AI训练框架。
@@ -491,9 +491,9 @@ print(response)
## 相关链接
-- 代码:完整代码直接看本文第5节 或 [Github](https://github.com/Zeyi-Lin/Qwen3-Medical-SFT)
+- 代码:完整代码直接看本文第5节 或 [GitHub](https://github.com/Zeyi-Lin/Qwen3-Medical-SFT)
- 实验日志过程:[qwen3-1.7B-linear - SwanLab](https://swanlab.cn/@ZeyiLin/qwen3-sft-medical/runs/agps0dkifth5l1xytcdyk/chart),或 [SwanLab基线社区](https://swanlab.cn/benchmarks) 搜索“qwen3-sft-medical”
-- 模型:[Modelscope](https://modelscope.cn/models/Qwen/Qwen3-1.7B)
+- 模型:[ModelScope](https://modelscope.cn/models/Qwen/Qwen3-1.7B)
- 数据集:[delicate_medical_r1_data](https://modelscope.cn/datasets/krisfu/delicate_medical_r1_data)
- SwanLab:[https://swanlab.cn](https://swanlab.cn)
diff --git a/zh/course/llm_train_course/03-sft/8.other_frameworks/paddlenlp_finetune.md b/zh/course/llm_train_course/03-sft/8.other_frameworks/paddlenlp_finetune.md
index 88852225..bbb9da17 100644
--- a/zh/course/llm_train_course/03-sft/8.other_frameworks/paddlenlp_finetune.md
+++ b/zh/course/llm_train_course/03-sft/8.other_frameworks/paddlenlp_finetune.md
@@ -207,7 +207,7 @@ model = AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir, dt
我们使用SwanLab来监控整个训练过程,并评估最终的模型效果。
-SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,面向人工智能与深度学习开发者,提供了一个跟踪、记录、比较、和协作实验的平台,常被称为"中国版 Weights & Biases + Tensorboard"。SwanLab同时支持云端和离线使用,并适配了从PyTorch、Transformers、Lightning再到LLaMA Factory、veRL等30+ AI训练框架。
+SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,面向人工智能与深度学习开发者,提供了一个跟踪、记录、比较、和协作实验的平台,常被称为"中国版 Weights & Biases + TensorBoard"。SwanLab同时支持云端和离线使用,并适配了从PyTorch、Transformers、Lightning再到LLaMA Factory、veRL等30+ AI训练框架。
您可以参考下面的代码在paddlenlp上尝试使用swanlab:
diff --git a/zh/course/llm_train_course/06-multillm/1.qwen_vl_coco/README.md b/zh/course/llm_train_course/06-multillm/1.qwen_vl_coco/README.md
index a673a7dc..04d8d971 100644
--- a/zh/course/llm_train_course/06-multillm/1.qwen_vl_coco/README.md
+++ b/zh/course/llm_train_course/06-multillm/1.qwen_vl_coco/README.md
@@ -16,7 +16,7 @@ Qwen2-VL是阿里通义实验室推出的多模态大模型。本文我们将简
Lora 是一种高效微调方法,深入了解其原理可参见博客:[知乎|深入浅出 Lora](https://zhuanlan.zhihu.com/p/650197598)。
- 训练过程:[Qwen2-VL-finetune](https://swanlab.cn/@ZeyiLin/Qwen2-VL-finetune/runs/pkgest5xhdn3ukpdy6kv5/chart)
-- Github:[代码仓库](https://github.com/Zeyi-Lin/LLM-Finetune/tree/main/qwen2_vl)、[self-llm](https://github.com/datawhalechina/self-llm)
+- GitHub:[代码仓库](https://github.com/Zeyi-Lin/LLM-Finetune/tree/main/qwen2_vl)、[self-llm](https://github.com/datawhalechina/self-llm)
- 数据集:[coco_2014_caption](https://modelscope.cn/datasets/modelscope/coco_2014_caption/summary)
- 模型:[Qwen2-VL-2B-Instruct](https://modelscope.cn/models/Qwen/Qwen2-VL-2B-Instruct)
@@ -82,7 +82,7 @@ pip install qwen-vl-utils==0.0.8
**数据集下载与处理方式**
1. **我们需要做四件事情:**
- - 通过Modelscope下载coco_2014_caption数据集
+ - 通过ModelScope下载coco_2014_caption数据集
- 加载数据集,将图像保存到本地
- 将图像路径和描述文本转换为一个csv文件
- 将csv文件转换为json文件
diff --git a/zh/course/llm_train_course/06-multillm/3.stable_diffusion/README.md b/zh/course/llm_train_course/06-multillm/3.stable_diffusion/README.md
index b50765bf..ba5e955a 100644
--- a/zh/course/llm_train_course/06-multillm/3.stable_diffusion/README.md
+++ b/zh/course/llm_train_course/06-multillm/3.stable_diffusion/README.md
@@ -15,7 +15,7 @@
在本文中,我们会使用[SD-1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5)模型在[火影忍者](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions)数据集上做训练,同时使用[SwanLab](https://swanlab.cn)监控训练过程、评估模型效果。
-- 代码:[Github](https://github.com/Zeyi-Lin/Stable-Diffusion-Example)
+- 代码:[GitHub](https://github.com/Zeyi-Lin/Stable-Diffusion-Example)
- 实验日志过程:[SD-naruto - SwanLab](https://swanlab.cn/@ZeyiLin/SD-Naruto/runs/21flglg1lbnqo67a6f1kr)
- 模型:[runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
- 数据集:[lambdalabs/naruto-blip-captions](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions)
@@ -92,7 +92,7 @@ pip install swanlab diffusers datasets accelerate torchvision transformers
## 5.开始训练
-由于训练的代码比较长,所以我把它放到了[Github](https://github.com/Zeyi-Lin/Stable-Diffusion-Example/tree/main)里,请Clone里面的代码:
+由于训练的代码比较长,所以我把它放到了[GitHub](https://github.com/Zeyi-Lin/Stable-Diffusion-Example/tree/main)里,请Clone里面的代码:
```bash
git clone https://github.com/Zeyi-Lin/Stable-Diffusion-Example.git
@@ -229,7 +229,7 @@ image.save("result.png")
## 相关链接
-- 代码:[Github](https://github.com/Zeyi-Lin/Stable-Diffusion-Example)
+- 代码:[GitHub](https://github.com/Zeyi-Lin/Stable-Diffusion-Example)
- 实验日志过程:[SD-naruto - SwanLab](https://swanlab.cn/@ZeyiLin/SD-Naruto/runs/21flglg1lbnqo67a6f1kr/chart)
- 模型:[runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
- 数据集:[lambdalabs/naruto-blip-captions](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions)
diff --git a/zh/course/prompt_engineering_course/11-swanlab_rag/1.swanlab-rag.md b/zh/course/prompt_engineering_course/11-swanlab_rag/1.swanlab-rag.md
index 17d11789..c2aa28fc 100644
--- a/zh/course/prompt_engineering_course/11-swanlab_rag/1.swanlab-rag.md
+++ b/zh/course/prompt_engineering_course/11-swanlab_rag/1.swanlab-rag.md
@@ -12,7 +12,7 @@
AI文档助手在线体验链接:[https://chat.swanlab.cn/](https://chat.swanlab.cn/)
-方案开源Github仓库链接:https://github.com/EmotionMachine/swanlab-rag
+方案开源GitHub仓库链接:https://github.com/EmotionMachine/swanlab-rag

 -Xtuner supports adaptation with multiple open-source large models such as InternLM and Llama, and can perform tasks such as incremental pre-training, instruction fine-tuning, and tool-based instruction fine-tuning. In terms of hardware requirements, developers can train with the lowest consumer-grade graphics cards, such as Tesla T4 and A100, to achieve specific demand capabilities of large models.
+XTuner supports adaptation with multiple open-source large models such as InternLM and Llama, and can perform tasks such as incremental pre-training, instruction fine-tuning, and tool-based instruction fine-tuning. In terms of hardware requirements, developers can train with the lowest consumer-grade graphics cards, such as Tesla T4 and A100, to achieve specific demand capabilities of large models.
-Xtuner supports adaptation with multiple open-source large models such as InternLM and Llama, and can perform tasks such as incremental pre-training, instruction fine-tuning, and tool-based instruction fine-tuning. In terms of hardware requirements, developers can train with the lowest consumer-grade graphics cards, such as Tesla T4 and A100, to achieve specific demand capabilities of large models.
+XTuner supports adaptation with multiple open-source large models such as InternLM and Llama, and can perform tasks such as incremental pre-training, instruction fine-tuning, and tool-based instruction fine-tuning. In terms of hardware requirements, developers can train with the lowest consumer-grade graphics cards, such as Tesla T4 and A100, to achieve specific demand capabilities of large models.
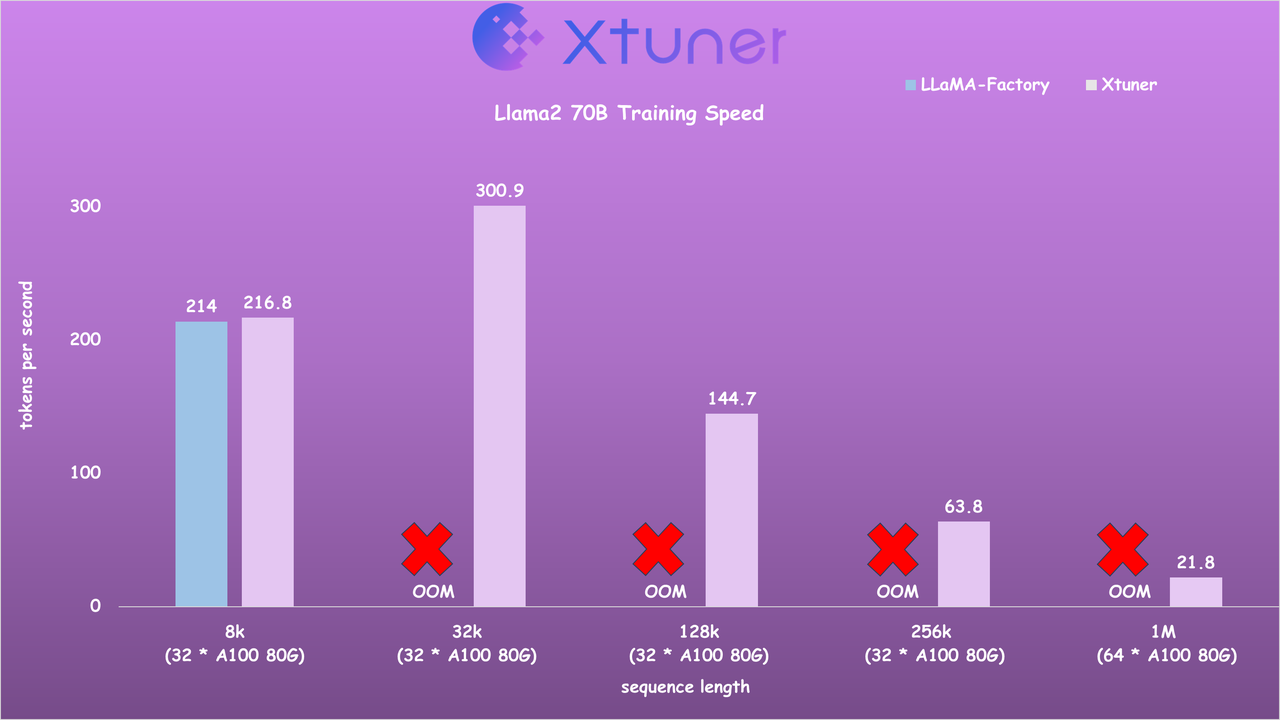
 京公网安备11010502056567号 · 京ICP备2024101706号-1
京公网安备11010502056567号 · 京ICP备2024101706号-1