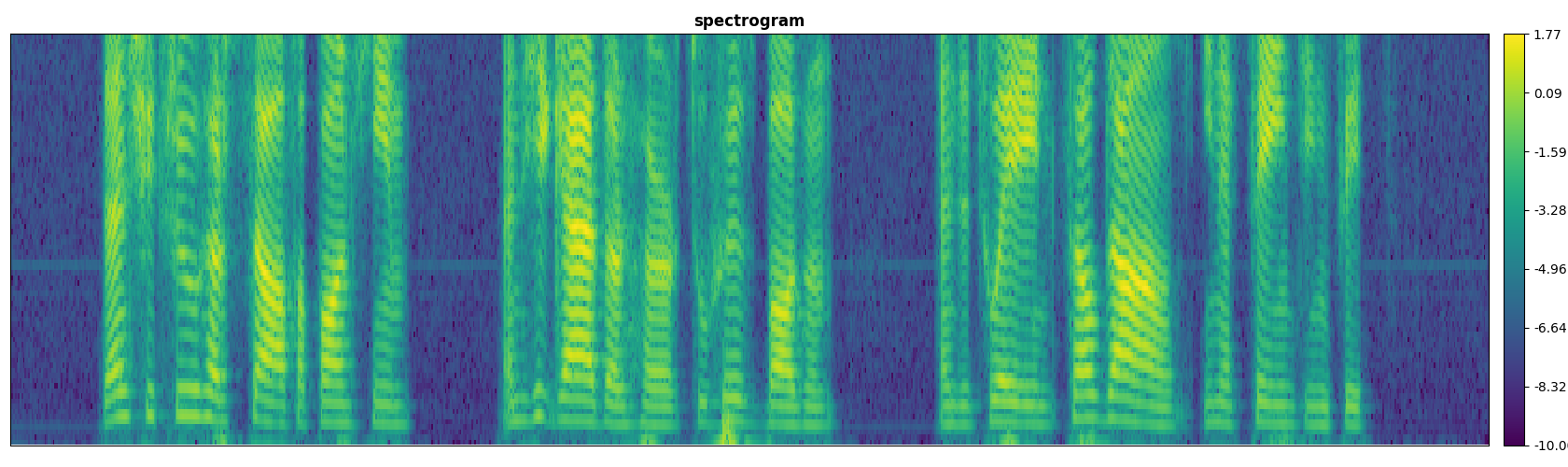
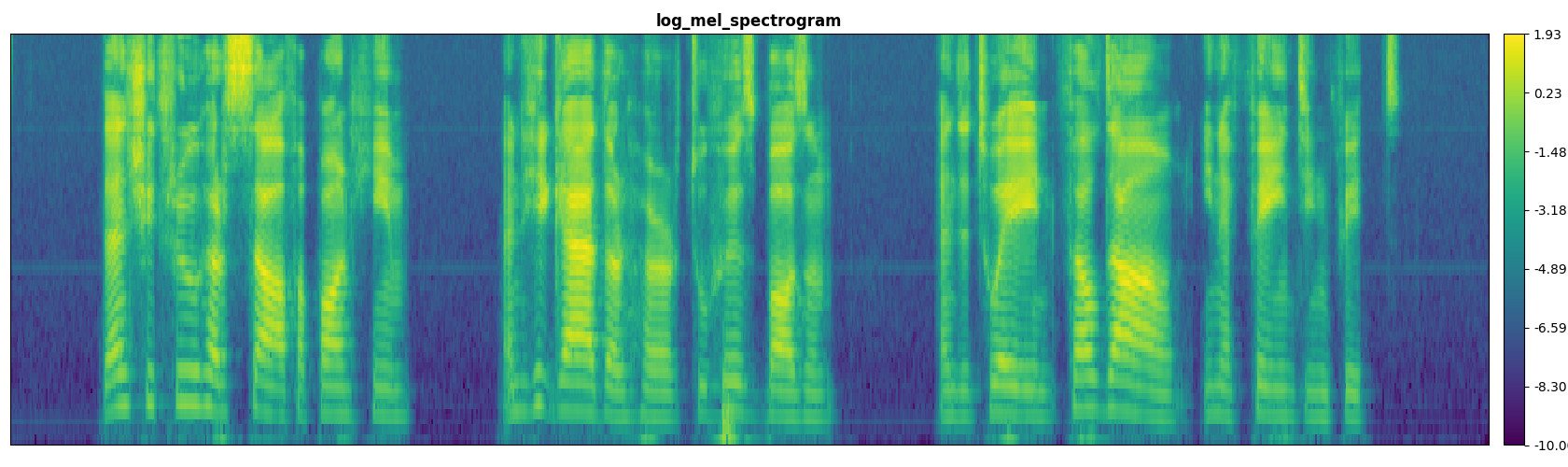
features
See feature_extraction.py for more detail
Speech features are extracted from the Signal with sample_rate, frame_ms, stride_ms and num_feature_bins.
Speech features has the shape (B, T, num_feature_bins, num_channels) and it contains from 1-4 channels:
- Spectrogram, Log Mel Spectrogram, Log Gammatone Spectrogram or MFCCs
- TODO: Delta features: like
librosa.feature.deltafrom the features extracted on channel 1. - TODO: Delta deltas features: like
librosa.feature.deltawithorder=2from the features extracted on channel 1. - TODO: Pitch features: like
librosa.core.piptrackfrom the signal
Implementation in tensorflow keras layer