Commit a3172f8
authored
mem: exclude unused spaCy pipeline components to reduce model memory (#4296)
Only tok2vec, tagger, and sentence splitting are used (`pos_tag` and
`sent_tokenize`). Exclude `ner`, `parser`, `lemmatizer`,
`attribute_ruler` when loading `en_core_web_sm`, and add lightweight
`sentencizer` to replace the dependency parser for sentence boundary
detection.
## Benchmark
Measured with [memray](https://github.com/bloomberg/memray) (`memray
run` + `memray stats --json`), 3 rounds × 5 texts through `pos_tag()` +
`sent_tokenize()` + `word_tokenize()`, Python 3.12.
<img width="1400" alt="bench_spacy_exclude"
src="https://raw.githubusercontent.com/codeflash-ai/codeflash/pr-assets/images/bench_spacy_exclude.png"
/>
```
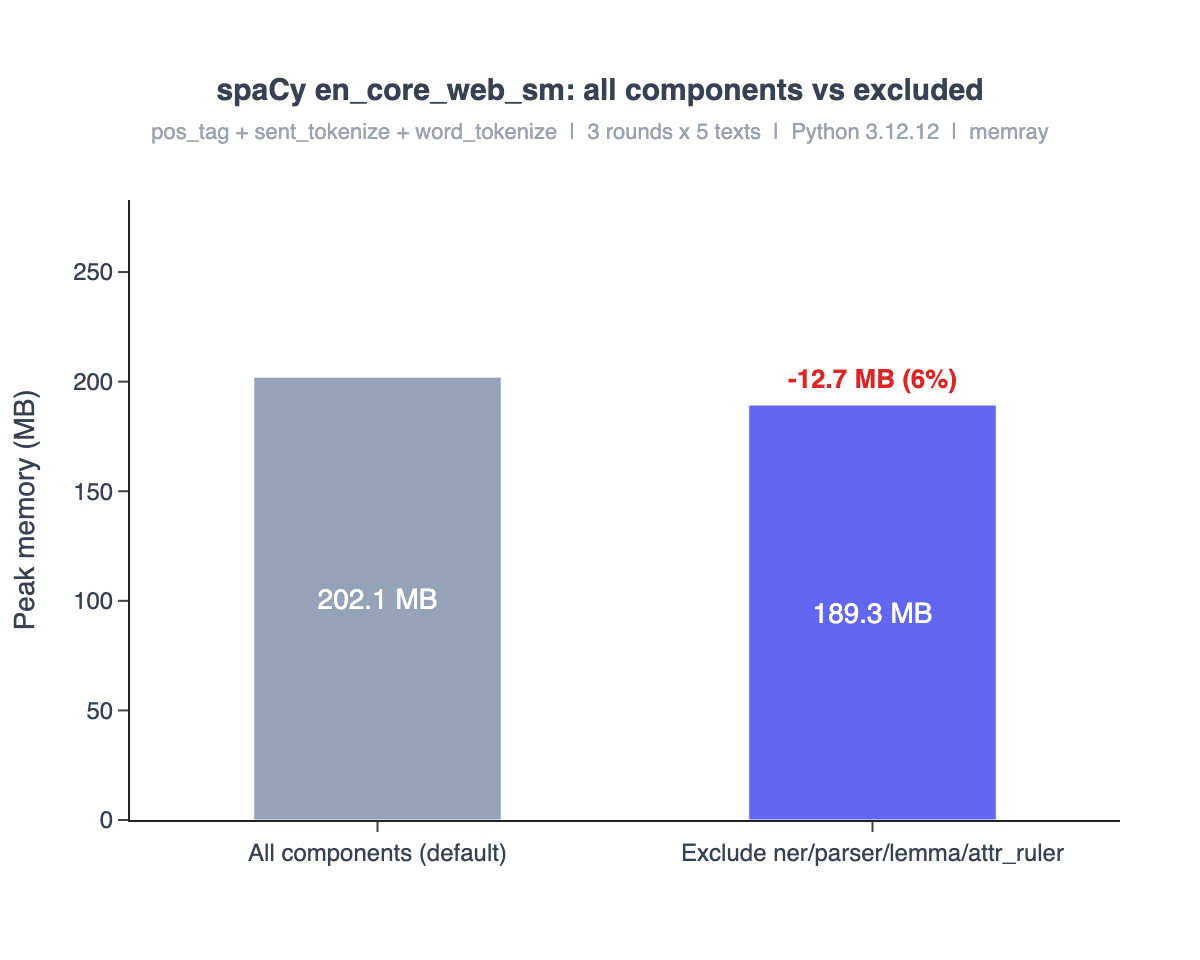
spaCy en_core_web_sm — component exclusion benchmark
pos_tag + sent_tokenize + word_tokenize | 3 rounds x 5 texts | Python 3.12.12
Configuration Peak MB Saved %
----------------------------------------------------------------------
All components (default) 202.1MB 0.0MB 0.0%
Exclude ner/parser/lemma/attr_ruler 189.3MB 12.7MB 6.3%
```{kind=link}
1 parent b6cf510 commit a3172f8
3 files changed
Lines changed: 15 additions & 4 deletions
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
| 1 | + | |
| 2 | + | |
| 3 | + | |
| 4 | + | |
| 5 | + | |
1 | 6 | | |
2 | 7 | | |
3 | 8 | | |
| |||
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
1 | | - | |
| 1 | + | |
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
109 | 109 | | |
110 | 110 | | |
111 | 111 | | |
| 112 | + | |
| 113 | + | |
| 114 | + | |
| 115 | + | |
| 116 | + | |
| 117 | + | |
112 | 118 | | |
113 | 119 | | |
114 | | - | |
| 120 | + | |
115 | 121 | | |
116 | 122 | | |
117 | 123 | | |
| |||
122 | 128 | | |
123 | 129 | | |
124 | 130 | | |
125 | | - | |
| 131 | + | |
126 | 132 | | |
127 | 133 | | |
128 | 134 | | |
129 | 135 | | |
130 | 136 | | |
131 | | - | |
| 137 | + | |
132 | 138 | | |
133 | 139 | | |
134 | 140 | | |
| |||
0 commit comments