diff --git a/README.md b/README.md
index d17b5e9e0..871587e22 100644
--- a/README.md
+++ b/README.md
@@ -23,7 +23,11 @@
💬 Discord •
✉️ Contact
-
+
+
+ English · 简体中文
+
+
diff --git a/README.zh-CN.md b/README.zh-CN.md
new file mode 100644
index 000000000..609219f2f
--- /dev/null
+++ b/README.zh-CN.md
@@ -0,0 +1,300 @@
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
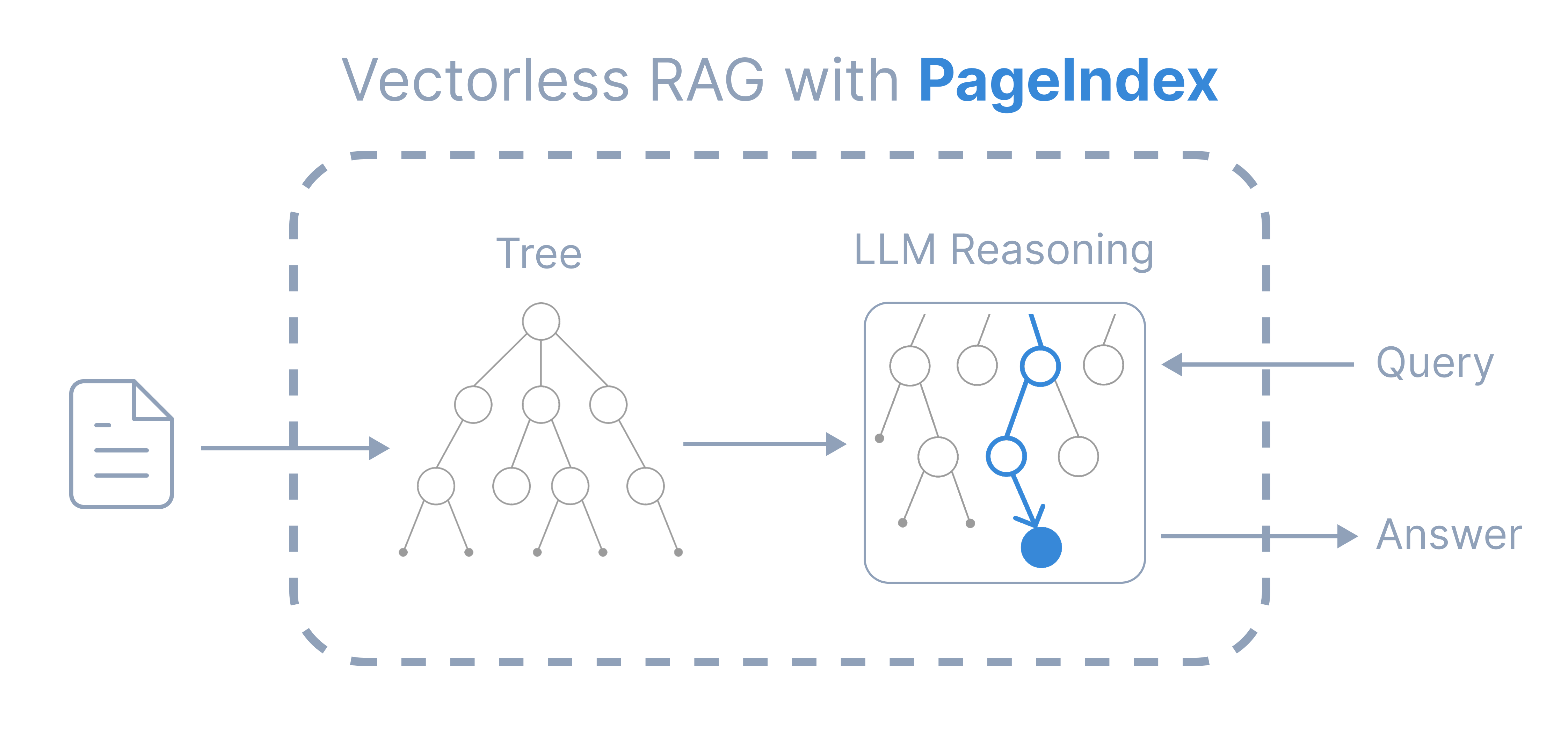
+# PageIndex:无需向量、基于推理的 RAG
+
+
基于推理的 RAG ◦ 无需向量数据库与切块 ◦ 上下文感知 ◦ 类人化检索
+
+
+
+
+ English · 简体中文
+
+
+
+📢 最新进展
+
+- 🔥 [**Agentic Vectorless RAG**](https://github.com/VectifyAI/PageIndex/blob/main/examples/agentic_vectorless_rag_demo.py) — 一个简洁的 *智能体式、无向量 RAG* [示例](https://github.com/VectifyAI/PageIndex/blob/main/examples/agentic_vectorless_rag_demo.py),基于自托管的 PageIndex,使用 OpenAI Agents SDK 实现。
+- [**将 PageIndex 扩展至千万级文档**](https://pageindex.ai/blog/pageindex-filesystem) — *PageIndex File System* 在文件层之上构建了一层树状索引,让 PageIndex 不仅能在单个文档上推理,还能在整个语料库上检索,从而支撑大规模的文档搜索。
+- [PageIndex Chat](https://chat.pageindex.ai) — 面向专业长文档的类人化文档分析智能体[平台](https://chat.pageindex.ai),同时也提供 [MCP](https://pageindex.ai/developer) 与 [API](https://pageindex.ai/developer) 接入方式。
+- [PageIndex 框架](https://pageindex.ai/blog/pageindex-intro) — 深入解读 PageIndex:一种 *智能体式、上下文内的树状索引*,让 LLM 能够在长文档上完成 *基于推理、上下文感知的检索*。
+
+
+
+
+
+---
+
+# 📑 PageIndex 简介
+
+是否曾因向量数据库在长篇专业文档上的检索精度不足而困扰?传统的向量化 RAG 依赖语义*相似度*,而非真正意义上的*相关性*。但 **相似 ≠ 相关**——检索真正需要的是**相关性**,而要做到这一点,离不开**推理**。当文档涉及专业知识与多步推理时,单纯的相似度搜索往往力不从心。
+
+受 AlphaGo 启发,我们提出了 **[PageIndex](https://vectify.ai/pageindex)**——一种**无需向量**、**基于推理**的 RAG 系统:它从长文档中构建**层级化的树状索引**,并让 LLM **在该索引上进行推理**,从而完成**智能体式、上下文感知的检索**。
+PageIndex 模拟了*领域专家*在面对复杂文档时如何借助*树搜索*来定位与提炼知识,让 LLM 能够*思考*并*推理*出最相关的内容片段。检索过程可分为两步:
+
+1. 为文档生成一个"目录式"的**树状结构索引**
+2. 通过**树搜索**完成基于推理的检索
+
+
+
+### 🎯 核心特性
+
+相较于传统的向量化 RAG,**PageIndex** 具备以下优势:
+- **无需向量数据库**:通过文档自身的结构与 LLM 推理完成检索,而非依赖向量相似度搜索。
+- **无需切块**:文档以其原本的章节结构组织,而非被切成人为的小块。
+- **更强的可解释性与可追溯性**:检索基于推理,过程可追溯、可解释,且能精确指向页码与章节,告别那种凭感觉、靠近似的"玄学式"向量检索。
+- **上下文感知的检索**:检索结果会结合完整上下文(如对话历史与领域知识),并能轻松融入新的上下文信息。
+- **类人化的检索方式**:模拟领域专家在复杂文档中查找与提炼知识的过程。
+
+PageIndex 所驱动的基于推理的 RAG 系统,在 FinanceBench 上取得了 **业界领先**的 [98.7% 准确率](https://github.com/VectifyAI/Mafin2.5-FinanceBench),在专业文档分析场景中明显优于传统的向量化 RAG 方案。详情请参见我们的[博客](https://vectify.ai/blog/Mafin2.5)。
+
+### 📍 进一步了解 PageIndex
+
+如想深入了解,请阅读 [PageIndex 框架](https://pageindex.ai/blog/pageindex-intro) 的详细介绍。本仓库提供完整的开源代码,更多用法与示例可参考 [cookbooks](https://docs.pageindex.ai/cookbook)、[教程](https://docs.pageindex.ai/tutorials) 与[博客](https://pageindex.ai/blog)。
+
+PageIndex 服务可作为类 ChatGPT 风格的[对话平台](https://chat.pageindex.ai)使用,也可通过 [MCP](https://pageindex.ai/developer) 或 [API](https://pageindex.ai/developer) 集成到你自己的系统中。
+
+### 🛠️ 部署方式
+- 自托管 — 使用本开源仓库在本地运行(采用标准 PDF 解析)。
+- 云服务 — 配备增强 OCR、树构建与检索流程的生产级管线,可获得最佳效果。可通过我们的[对话平台](https://chat.pageindex.ai/)直接体验,或通过 [MCP](https://pageindex.ai/developer) 与 [API](https://pageindex.ai/developer) 集成。
+- _企业版_ — 私有化或本地化部署。如有需要请[联系我们](https://ii2abc2jejf.typeform.com/to/tK3AXl8T)或[预约演示](https://calendly.com/pageindex/meet)。
+
+### 🧪 快速上手
+
+- 🔥 [**Agentic Vectorless RAG**](examples/agentic_vectorless_rag_demo.py)(**最新**)— 一个简洁但完整的 **智能体式、无向量 RAG** [示例](https://github.com/VectifyAI/PageIndex/blob/main/examples/agentic_vectorless_rag_demo.py),基于*自托管*的 PageIndex,使用 OpenAI Agents SDK 实现。
+- 试用 [Vectorless RAG](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb) notebook —— 一个*精简*、动手即可运行的基于推理的 RAG 示例。
+- 查看 [Vision-based Vectorless RAG](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/vision_RAG_pageindex.ipynb) —— 无需 OCR,直接基于页面图像、原生面向推理的极简视觉 RAG 流程。
+
+
+
+---
+
+# 🌲 PageIndex 树状结构
+
+PageIndex 能将冗长的 PDF 文档转化为语义化的**树状结构**,类似于*"目录"*,但针对大语言模型(LLM)的使用场景做了优化。它特别适用于:财务报告、监管申报材料、学术教科书、法律或技术手册,以及任何超出 LLM 上下文长度的文档。
+
+下面是一个 PageIndex 树状结构的示例,更多示例可参考[文档样本](https://github.com/VectifyAI/PageIndex/tree/main/examples/documents)以及生成的[树状结构](https://github.com/VectifyAI/PageIndex/tree/main/examples/documents/results)。
+
+```jsonc
+...
+{
+ "title": "Financial Stability",
+ "node_id": "0006",
+ "start_index": 21,
+ "end_index": 22,
+ "summary": "The Federal Reserve ...",
+ "nodes": [
+ {
+ "title": "Monitoring Financial Vulnerabilities",
+ "node_id": "0007",
+ "start_index": 22,
+ "end_index": 28,
+ "summary": "The Federal Reserve's monitoring ..."
+ },
+ {
+ "title": "Domestic and International Cooperation and Coordination",
+ "node_id": "0008",
+ "start_index": 28,
+ "end_index": 31,
+ "summary": "In 2023, the Federal Reserve collaborated ..."
+ }
+ ]
+}
+...
+```
+
+你可以使用本开源仓库自行生成 PageIndex 树状结构;也可以使用我们的 [API](https://pageindex.ai/developer),通过增强的 OCR 与树构建流程获得更高质量的结果。
+
+---
+
+# ⚙️ 包用法
+
+> **说明:** 本开源包采用标准的 PDF 解析。如需处理复杂 PDF,建议使用我们的[云服务](https://pageindex.ai/developer)(通过 MCP 与 API),其提供了增强的 OCR、树构建与检索能力。
+
+按照以下步骤即可基于 PDF 文档生成 PageIndex 树。
+
+### 1. 安装依赖
+
+```bash
+pip3 install --upgrade -r requirements.txt
+```
+
+### 2. 配置 LLM API 密钥
+
+在仓库根目录创建 `.env` 文件并填入 LLM API 密钥,借助 [LiteLLM](https://docs.litellm.ai/docs/providers) 可支持多种模型提供方:
+
+```bash
+OPENAI_API_KEY=your_openai_key_here
+```
+
+### 3. 为 PDF 生成 PageIndex 结构
+
+```bash
+python3 run_pageindex.py --pdf_path /path/to/your/document.pdf
+```
+
+
+可选参数
+
+你可以通过下列可选参数自定义处理流程:
+
+```
+--model 使用的 LLM 模型(默认:gpt-4o-2024-11-20)
+--toc-check-pages 用于检测目录的页数(默认:20)
+--max-pages-per-node 每个节点的最大页数(默认:10)
+--max-tokens-per-node 每个节点的最大 token 数(默认:20000)
+--if-add-node-id 是否添加节点 ID(yes/no,默认:yes)
+--if-add-node-summary 是否添加节点摘要(yes/no,默认:yes)
+--if-add-doc-description 是否添加文档描述(yes/no,默认:yes)
+```
+
+
+
+Markdown 支持
+
+PageIndex 同样支持 Markdown 文件。你可以通过 --md_path 参数为 Markdown 文档生成树状结构。
+
+```bash
+python3 run_pageindex.py --md_path /path/to/your/document.md
+```
+
+> 说明:在该模式下,我们以 "#" 来判断节点的标题及其层级。例如 "##" 为二级,"###" 为三级,依此类推。请确保你的 Markdown 文件格式规范。如果该 Markdown 文件是从 PDF 或 HTML 转换而来,则不建议使用此模式,因为大多数现有的转换工具难以保留原始的层级结构。这种情况下,建议使用我们的 [PageIndex OCR](https://pageindex.ai/blog/ocr) 将 PDF 转为 Markdown(它专门针对保留原有层级结构进行了优化),再使用本模式。
+
+
+## 智能体式、无向量 RAG 示例
+
+如需查看一个完整的、端到端的*智能体式、无向量 RAG*示例(基于 PageIndex 与 OpenAI Agents SDK),请见 [`examples/agentic_vectorless_rag_demo.py`](examples/agentic_vectorless_rag_demo.py)。
+
+```bash
+# 安装可选依赖
+pip3 install openai-agents
+
+# 运行示例
+python3 examples/agentic_vectorless_rag_demo.py
+```
+
+
+
+---
+
+# 📈 案例研究:PageIndex 在金融问答基准上领跑
+
+[Mafin 2.5](https://vectify.ai/mafin) 是一个面向金融文档分析的、基于推理的 RAG 系统,其底层由 **PageIndex** 提供支撑。它在 [FinanceBench](https://arxiv.org/abs/2311.11944) 基准上取得了业界领先的 [**98.7% 准确率**](https://vectify.ai/blog/Mafin2.5),显著超越传统的向量化 RAG 方案。
+
+PageIndex 的层级化索引与基于推理的检索,能够在 SEC 申报材料、财报披露等复杂金融文档中精准定位并抽取相关上下文。
+
+完整的[基准测试结果](https://github.com/VectifyAI/Mafin2.5-FinanceBench)与对比指标可见我们的[博客文章](https://vectify.ai/blog/Mafin2.5)。
+
+
+
+---
+
+# 🧭 资源
+
+* 📝 [博客](https://pageindex.ai/blog):技术文章、研究洞察与产品更新。
+* 🔧 [开发者](https://pageindex.ai/developer):MCP 配置、API 文档与集成指南。
+* 🧪 [Cookbooks](https://docs.pageindex.ai/cookbook):可直接运行的实战示例与进阶用例。
+* 📖 [教程](https://docs.pageindex.ai/tutorials):实用指南与策略,包含 *Document Search* 与 *Tree Search* 等主题。
+
+---
+
+# ⭐ 支持我们
+
+如果你喜欢这个项目,欢迎给我们点一个 🌟,谢谢!
+
+
+  +
+
+
+引用方式:
+```
+Mingtian Zhang, Yu Tang and PageIndex Team,
+"PageIndex: Next-Generation Vectorless, Reasoning-based RAG",
+PageIndex Blog, Sep 2025.
+```
+
+
+BibTeX 引用
+
+```bibtex
+@article{zhang2025pageindex,
+ author = {Mingtian Zhang and Yu Tang and PageIndex Team},
+ title = {PageIndex: Next-Generation Vectorless, Reasoning-based RAG},
+ journal = {PageIndex Blog},
+ year = {2025},
+ month = {September},
+ note = {https://pageindex.ai/blog/pageindex-intro},
+}
+```
+
+
+
+### 联系我们
+
+
+
+[](https://x.com/PageIndexAI)
+[](https://www.linkedin.com/company/vectify-ai/)
+[](https://discord.com/invite/VuXuf29EUj)
+[](https://ii2abc2jejf.typeform.com/to/tK3AXl8T)
+
+
+
+---
+
+© 2026 [Vectify AI](https://vectify.ai)
 +
+
+
+