Effective Go 算是官方文档中很经典的一篇了,这里记录一下自己的阅读笔记。其中有些内容可能稍微显得有些过时了,咱也额外补充了很多个人认为需要注意的点。
这篇笔记是在 Obsidian 中写的。
Somebottle 2025.1
gofmt 能帮助完成工作,包括对于注释的对齐。
- 保持风格统一,便于他人阅读代码。
Go 语言中用到的括号更少,运算符优先级表如下:
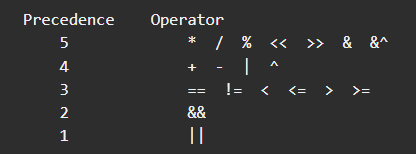
可以看到位运算的优先级还是比较高的,这点和 C++ 不一样:
x<<8 + y<<16
gofmt在这种情况会自动添加一些空格以方便阅读。
会被解析为:
(x<<8) + (y<<16)❗ ++ 和 -- 运算符在 Go 中形成一个语句 ⚠ 而不是表达式,不算在运算符优先级中。而 * 又是优先级最高的运算符之一,因此在 Go 中:
*p++ 和
(*p)++是一样的。
❗ 一般建议是用行级注释 // 。
package级别或者表达式中间的注释可以用块级注释/* */,也可用于注释掉一大片代码。
如果注释出现在顶级声明(如函数、类型、变量等)之前,并且中间没有空行,那么这些注释会被视为该声明的文档注释(类似 Python 的 docstring)。
// 初始化路由
// 2333
func InitRouter() *gin.Engine {比如这样,注释之间没有空行,会被一起认为是 InitRouter 方法的注释。
-
全小写字母
-
用一个词精炼描述(尽量简短,没必要用下划线和驼峰式)
-
❗ 和包所在的目录名一致
-
🤔 一个有用的注释比长命名更有用。
- 💡 对于 Getter 方法,❗ 不建议在方法名中写
Get,而是用首字母大写的相应字段的名字作为 Getter 方法名:student.Age()而不是student.GetAge() - Setter 则照旧:
student.SetAge()
- 如果接口只有一个方法,可以在方法后面加上
-er来表示这是一个执行什么操作的方法,比如Reader,Scraper - ❗ 如果有方法和 Go 语言标准库中方法的功能一致,应当保持相同命名,比如字符串化的方法
String()
- 用小驼峰或者大驼峰即可,而不是下划线分隔单词。
Go 语言中大多数地方分号由编译器的词法分析器(Lexer)自动插入在语句可能结束的地方,主要是在换行的时候进行判断。
❗ 因此在写控制逻辑和函数的时候必须把圆括号和大括号写在同一行,不然编译器会插入分号导致解析失败:
// 正确写法
if i < f() {
g()
}
// 错误写法
if i < f() // wrong!
{ // wrong!
g()
}a := 1
// 左侧至少有一个变量是新声明的
b,a := 3,4
// wrong
a := 4初始化赋值声明语法 := 其实可以复用之前已经声明的变量,比如这里的 a ,并不是每次一定要全部声明新的变量:
- 待赋值的值应当和
a同类型。 - ❗
:=左侧至少有一个变量是新声明的!!!(上面的例子中可以看到)
- 循环控制语句只有
for - 💡
if与switch和for一样可以有一个初始化语句,可以用于设立一个局部变量。if err := file.Chmod(0664); err != nil { log.Print(err) return err }
continue和break都支持一个标签(Label),来控制外层循环的继续与停止
从 range 接受值时可以只接受第一个:
for key := range m {
if key.expired() {
delete(m, key)
}
}💡 对 string 使用 range 时,会以 UTF-8 编码将字串按码点拆分,取得的每个 Unicode 码点用 rune 类型存储。
- ❗ 有问题的编码会被替换为
U+FFFD,即 ”�“ 这个字符。
Warning
for range 遍历字符串时,取出的下标是 rune 开头字节对应的下标!!
var s string = "你好world"
for idx, chr := range s {
fmt.Printf("Index: %d, Char: %c\n", idx, chr)
}
// 输出
// Index: 0, Char: 你
// Index: 3, Char: 好
// Index: 6, Char: w
// Index: 7, Char: o
// Index: 8, Char: r
// Index: 9, Char: l
// Index: 10, Char: d// Reverse a
for i, j := 0, len(a)-1; i < j; i, j = i+1, j-1 {
a[i], a[j] = a[j], a[i]
}❗ Go 语言中 ++ 和 -- 是语句而不是表达式(没有值,每个应该放在单独一行中),也不能用逗号分隔表达式,因此得要像上面这样借助声明和并行赋值语句来写。
比 C 语言的 switch 要灵活很多,可以接受值和逻辑表达式:
func unhex(c byte) byte {
switch {
case '0' <= c && c <= '9':
return c - '0'
case 'a' <= c && c <= 'f':
return c - 'a' + 10
case 'A' <= c && c <= 'F':
return c - 'A' + 10
}
return 0
}这样写甚至可以简化
if-else语句。
case 后面还可以是逗号分隔的表达式列表:
func shouldEscape(c byte) bool {
switch c {
case ' ', '?', '&', '=', '#', '+', '%':
return true
}
return false
}❗ 注意 Go 语言匹配了某个 case 后不会继续尝试执行下一个 case,也就不需要写 break. (可以用 fallthrough 来让程序顺着执行下面的 case。。
- 💡 当然写
break也仍然会立即停止执行case中剩余的语句。
switch 可以结合类型断言来使用,对于不同的类型可以进行不同的处理。
var t interface{} // 即 Go 1.18 以后的 any
t = functionOfSomeType()
switch t := t.(type) { // 这里就写 .(type)
default:
fmt.Printf("unexpected type %T\n", t) // %T prints whatever type t has
case bool:
fmt.Printf("boolean %t\n", t) // t has type bool
case int:
fmt.Printf("integer %d\n", t) // t has type int
case *bool:
fmt.Printf("pointer to boolean %t\n", *t) // t has type *bool
case *int:
fmt.Printf("pointer to integer %d\n", *t) // t has type *int
}可以用于中断上层的循环:
for i := 0; i < 3; i++ {
secondLoop:
for j := 0; j < 3; j++ {
for k := 0; k < 3; k++ {
fmt.Printf("i=%d, j=%d, k=%d\n", i, j, k)
if i == 1 && j == 1 && k == 1 {
// 满足条件时,跳出第二层循环
break secondLoop
}
}
}
}Go 的函数支持多返回值,声明函数时多返回值需要用括号包裹起来:
var a func(i, j int) (int, int)如果返回参数命名了,在调用函数时其会被初始化为零值变量,在函数作用域中都可以使用。
💡 函数中 return 不需要显式返回任何内容。
func ReadFull(r Reader, buf []byte) (n int, err error) {
for len(buf) > 0 && err == nil {
var nr int
nr, err = r.Read(buf)
n += nr
buf = buf[nr:]
}
return // 这样写就行
}把某个函数推迟到当前函数执行完成后,返回之前执行。
- 💡 即使函数执行时发生了
panic,defer也会执行。 - 💡 有点类似于其他语言中的
try...finally,常用于释放资源。- ❗ 为了表达清晰,可以放在资源获取的语句的后面,比如先
open然后紧跟一个defer close。
- ❗ 为了表达清晰,可以放在资源获取的语句的后面,比如先
❗ 有多个 defer 时会形成一个函数推迟执行栈(LIFO),最后的 defer 最先被执行:
func deferExample() {
defer fmt.Println("Defer 1") // 最后执行
defer fmt.Println("Defer 2") // 第二个执行
defer fmt.Println("Defer 3") // 最先执行
fmt.Println("Function body")
}
// Function body
// Defer 3
// Defer 2
// Defer 1❗ 延迟执行的函数参数是在 defer 执行时立即求值的!
func trace(s string) string {
fmt.Println("entering:", s)
return s
}
func un(s string) {
fmt.Println("leaving:", s)
}
func a() {
defer un(trace("a")) // 这个时候 trace 函数会被立即执行以进行求值
fmt.Println("in a")
}
func b() {
defer un(trace("b"))
fmt.Println("in b")
a()
}
func main() {
b()
}
// entering: b
// in b
// entering: a
// in a
// leaving: a
// leaving: b- ❗ 可变参数必须放在参数列表中的最后一个位置
- 类型前缀加上
...
func Printf(format string, v ...interface{}) (n int, err error)这里 v 可以接受任意多个任意类型(Go 1.18 后 interface{} 即 any)的实参。
v本身也就被当作一个[]any{}切片进行处理。
✨ 反过来,相应数据类型的切片也可以利用 ... 后缀,让编译器将切片中的元素当作参数传入:
a := [3]any{1, 2, 3}
// 必须转换为切片,然后用 ... 后缀
fmt.Println(a[:]...)内置类型无法像结构体那样可以直接定义其上的方法,不过我可以先给内置类型定义一个自定义类型,就可以直接在这个类型上定义方法了。
type MySize float64 // 别名
func (ms MySize) String() string {
...
}Warning
注意这里 MySize 就是一个新类型,没法直接把 float64 类型赋值给 MySize 类型,需要显式转换。
type MyType1 float64 // 新定义了一个 MyType1 类型
type MyType2 = float64 // 给 float64 取了别名 MyType2
var a float64 = 3.14
var b MyType1
var c MyType2
b = a // 会 panic,Go 语言中必须显式进行转换,即 b = MyType1(a)
c = a // 正常赋值,只是别名💡 初始化一个清零的内存区域,并把指向内存的指针返回。
- 这个指针
*T指向T类型的一个零值对象。 - ❗ 也就是
new了之后立即就可以使用。
p := new(SyncedBuffer) // type *SyncedBuffer
var v SyncedBuffer // type SyncedBuffer
// p, v 都可以直接拿来用💡 Go 语言中构造函数其实就是用户手动写的一个函数,函数名习惯以 New 开头:
// 定义一个结构体
type Person struct {
Name string
Age int
}
// 定义一个构造函数
func NewPerson(name string, age int) *Person {
return &Person{
Name: name,
Age: age,
}
}💡 像映射、切片、结构体、数组等这些复合类型可以用字面量(literal)直接在声明和定义时初始化:
Type{Value1, Value2, ..., ValueN}如:
type Person struct {
Name string
Age int
}
p := Person{Name: "Alice", Age: 30} // 创建一个结构体实例
matrix := [2][2]int{{1, 2}, {3, 4}} // 创建一个 2x2 的二维数组💡💡 对于复合类型,可以用类似 字段:值 的方式来只指定部分值,而不必全部写出来:
s := []string{2: "Hello", 1: "World"}
fmt.Println(s)
// [ World Hello]
v := []int{3: 7, 1: 4}
fmt.Println(v)
// [0 4 0 7]
m := map[string]int{
"hey": 3444,
"there": 5666,
}
fmt.Println(m)
// map[hey:3444 there:5666]
p := Person{name: "Somebottle"}
fmt.Println(p)
// {0 Somebottle}这是常用技巧。对于切片和数组这种结构来说“字段”指的是“下标”。
在 C 语言中返回函数的局部变量的指针(地址)是新手常犯的一个内存管理和作用域错误,函数执行完后相应的局部变量会被释放掉。
💡 但是!在 Go 语言中是完全可以这样写的:
func NewFile(fd int, name string) *File {
if fd < 0 {
return nil
}
f := File{fd, name, nil, 0}
return &f
// 写得更简洁:return &File{fd, name, nil, 0}
}- 💡 因为 Go 语言编译器有“逃逸分析”,如果变量的生命周期逃逸到了函数外部,编译器会自动把这个变量分配到堆上,由 GC 管理。
❗ make 仅用于新分配切片(slice)、映射(map)、通道(channel)
- 返回一个初始化的对象
T(而不是指针)- ❗ 注意,和
new不同,make是初始化了对象而不是内存清零!! - 💡 因为这三种类型是引用类型,其底层的数据结构必须先初始化后才能使用。比如
slice底层可以看作一个结构体,有指针指向数组,并有变量表示了长度和容量。 - ❗ 没有初始化的引用类型默认就是
nil
- ❗ 注意,和
make([]int, 10, 100)分配一个 100 个
int数据的数组,并让一个切片指向其首 10 个元素,返回这个切片。
new([]int)分配一个零化的空切片结构(
nil),并返回其指针。
官方例子:
var p *[]int = new([]int) // 分配一个零切片结构; *p == nil; 几乎不怎么这样写
var v []int = make([]int, 100) // 切片 v 指向至少有 100 个 int 的数组
// 哥你这样写是这给自己找麻烦呢:
var p *[]int = new([]int)
*p = make([]int, 100, 100)
// 常见的写法,地道!
v := make([]int, 100)- ❗ Go 语言中数组是值类型,赋值(比如函数传参)时会拷贝所有元素。
- ❗ 数组的长度是数据类型的一部分,比如
[10]int和[20]int是不同的类型。
💡 定义时可以用 [...]T 自动推断数组长度:
// 相当于 [3]int 类型的数组
arr := [...]int{2,3,3}切片包装了数组,操作起来更方便。
- 切片是引用类型,赋值后底层仍然是指向相同的数组。
- 内置函数
len和cap可以获得切片长度(length)以及底层数组实际容量(capacity),💡 对于nil切片,均为 0.
主要是官方给出了一个神奇的例子:
// Allocate the top-level slice, the same as before.
picture := make([][]uint8, YSize) // One row per unit of y.
// Allocate one large slice to hold all the pixels.
pixels := make([]uint8, XSize*YSize) // Has type []uint8 even though picture is [][]uint8.
// Loop over the rows, slicing each row from the front of the remaining pixels slice.
for i := range picture {
picture[i], pixels = pixels[:XSize], pixels[XSize:]
}可以看到定义时 pixels 和 picture 是分开的,但通过不断切片和赋值,使得 picture 的第二维和 pixels 关联了起来。
存储映射关系键值对。
- ❗ 键可以是任何支持等号(equality operator)比较的类型。(比如切片类型没有定义等号,因此不能作为键)
map也是引用类型。
上面已经展示过,map 可以通过复合字面量(composite literal)来初始化。
通过 [key] 可以获取到映射中 key 对应的值:
offset := myMap["test"]- 💡 对于不存在的键,会取出值类型对应的零值。
💡 当然还可以接受第二个返回值,这是一个代表键是否存在的布尔值,通常将其赋给一个 ok 变量:
_,ok := myMap["test"]从映射 map 中移除键可以用内置的 delete 方法,从官方文档可以看到这个方法专门用于映射类型:
delete(myMap, "test") // 从 myMap 中移除键 'test' 对应的键值对如果本来就没这个键,那么这就是个空操作。
- 如
Fprintln,Println,Sprintln
这一类输出会在每个参数值之间加空格,最后加上换行符进行输出。
fmt.Println("A", "B", 23, 46, "C", 67, 78, 89)
// A B 23 46 C 67 78 89\n- 如
Fprint,Print,Sprint
❗ 这一类输出仅在相邻两个参数值都不是字串的地方加空格:
fmt.Print("A", "B", 23, 46, "C", 67, 78, []int{89}, "STR")
// AB23 46C67 78 [89]STR- 💡 注:对于无序的
map类型,Printf一类默认会按键进行字典升序排列再输出。
Printf 即类似 C 的格式化输出字串,但格式动词与 C 就有些不同了:
数字格式动词(format verbs),如 %d,不接受一些是否有符号、数值规模等限制的标志。(比如 C 语言中有 %d, %u, %ld,但是 Go 语言会自动推断这些)。
var x uint64 = 1<<64 - 1
// %d 输出十进制,%x 输出十六进制
fmt.Printf("%d %x; %d %x\n", x, x, int64(x), int64(x))
// 18446744073709551615 ffffffffffffffff; -1 -1💡 %v (记:value)可以按默认输出方式输出 Go 中任意类型(就像 Println 和 Print 输出的那样)。
✨ 在输出结构体 struct 时,如果使用 %+v 可以顺带输出结构体字段名,而如果使用 %#v 会按 Go 语言的语法输出这个类型:
type T struct {
a int
b float64
c string
}
t := &T{ 7, -2.35, "abc\tdef" }
fmt.Printf("%v\n", t) // &{7 -2.35 abc def}
fmt.Printf("%+v\n", t) // &{a:7 b:-2.35 c:abc def}
fmt.Printf("%#v\n", t) // &main.T{a:7, b:-2.35, c:"abc\tdef"}
fmt.Printf("%#v\n", timeZone) // map[string]int{"CST":-21600, "EST":-18000, "MST":-25200, "PST":-28800, "UTC":0}✨ 对于自定义结构,比如一个 struct,可以为其写一个 String() string 方法来自定义其默认输出格式:
func (t *T) String() string {
return fmt.Sprintf("%d/%g/%q", t.a, t.b, t.c)
}
fmt.Printf("%v\n", t) // 7/-2.35/"abc\tdef"\n%q (记:quoted)可以输出带引号的字串(双引号)或者字符(单引号),\t,\n 这类特殊字符也会被转义:
// 字符串
fmt.Printf("%q\n", "Hello, World!") // 输出: "Hello, World!"
fmt.Printf("%q\n", "Hello\nWorld!") // 输出: "Hello\nWorld!"
// 字符
fmt.Printf("%q\n", 'H') // 输出: 'H'
fmt.Printf("%q\n", '\n') // 输出: '\n'
// 非字符串和字符类型
fmt.Printf("%q\n", 65) // 输出: 'A'
fmt.Printf("%q\n", []byte("Hello")) // 输出: "Hello"
// 用反引号(backquote)
fmt.Printf("%#q\n", []byte("Hello")) // 输出: `Hello`✨ %x 还可以将字串中每个字节转换为两个十六进制字符,% x 会在输出时用空格分隔开。
fmt.Printf("%x\n", "Hello你好") // 输出: 48656c6c6fe4bda0e5a5bd
fmt.Printf("%x\n", []byte("Hello你好")) // 输出: 48656c6c6fe4bda0e5a5bd
fmt.Printf("% x\n", []byte("Hello你好")) // 输出: 48 65 6c 6c 6f e4 bd a0 e5 a5 bd✨ %T 可以输出一个数据的类型。
fmt.Printf("%T\n", myMap) // map[string]int\n这一类会将内容输出到指定文件流中,第一个参数接受任意实现了 io.Writer 接口的结构,常见的有标准输出 os.Stdout 和 os.Stderr。
通过重写类型上的 String() string 方法可以自定义默认输出格式,可是如果在这种方法中又尝试打印自身,就会造成死循环:
type MyString string
func (m MyString) String() string {
return fmt.Sprintf("MyString=%s", m) // Error: will recur forever.
}✨ 一个解决方法就是让 m 脱离类型 MyString 再进行输出,即转换为 string:
type MyString string
func (m MyString) String() string {
return fmt.Sprintf("MyString=%s", string(m)) // OK: note conversion.
}❗ 注意这种死循环是因为使用 %s (或者 %v)这类输出字串的格式动词时,fmt.Sprintf 会尝试调用 m 的 String() 方法。
✨ 如果用其他格式动词,就不会有这个问题了:
type MyFloat float64
func (f MyFloat) String() string {
// 这里用的是 %f
return fmt.Sprintf("%.3f", f)
}
// main 函数内
var num MyFloat = 1.41421
fmt.Println(num) // 1.414func append(slice []Type, elems ...Type) []Type之前提到,切片实际上是对底层数组的一个引用,因此调用 append 向切片中添加元素时其实就是在修改底层数组。
append会返回修改后的切片
💡 从下面这个例子可以看到 append 的逻辑:
arr := [...]int{1, 2, 3, 4, 5, 6}
s := arr[1:3]
s = append(s, 8, 9)
fmt.Println(s) // [2 3 8 9]
fmt.Println(arr) // [1 2 3 8 9 6]
// re-allocated
s = append(s, 21, 22, 23, 24, 25)
fmt.Println(s) // [2 3 8 9 21 22 23 24 25]
fmt.Println(arr) // [1 2 3 8 9 6]可以看到,底层数组容量足够时,元素附加到切片之后其实就修改了底层数组中切片最后一个位置的后一个元素。
❗ 但是底层元素容量不足时就会自动分配新的底层数组,比如上面我第二次一次附加了 5 个元素,但是原本的底层数组没有进一步被更改,程序中自动分配了新的内存。
还记得上面让编译器把切片元素当作函数参数的语法吗(... 后缀):
s = append(s, []int{1,2,3,4}...)💡 无论是全局(包级别)还是函数内的局部,常量都是在编译时(compile time)创建的。
常量只能是这些类型:
- 数值(
int,float,int64,float64等) - 字符串(
string) - Unicode 码点(
rune,✨ 本质上是int32)(这个其实可以和数值记在一起) - 字节(
byte,✨ 本质上是uint8)(这个其实可以和数值记在一起) - 布尔值(
bool)
❗ 定义常量的表达式必须是常量表达式,能在编译时求值。比如 1<<3 就可以,但是像 math.Sin(math.Pi/4) 这种需要在运行时求值的就不行。
在 Go By Example 的笔记中我已经写过这部分要注意的地方:
iota是按行递增的。- 下一行如果没有指定表达式,默认会继承上一行的表达式。
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota)
MB
GB
TB
PB
EB
ZB
YB
)变量定义时可以写需要在运行时求值的表达式:
var (
home = os.Getenv("HOME")
user = os.Getenv("USER")
gopath = os.Getenv("GOPATH")
)主要用于在程序启动时执行一些初始化操作。
- 每个程序源文件中都可以定义
init() - ✨
init()可以定义多个,会按定义的顺序依次执行。 - ✨ 在当前的
init()执行前,所有导入的包的init()会先执行(先初始化被导入包,再初始化当前包) - ✨ 在
init()执行前,所有包级别(看上去像全局变量)的变量都会被初始化完成(常量就更不用说了)
package main
import "fmt"
func main() {
var (
A = 1
B = 2
C = 3
)
fmt.Println(A, B, C)
}
func init() {
fmt.Println("Init 1")
}
func init() {
fmt.Println(SomeBottle)
}
// Package-level variables
var SomeBottle int = 114514
/*
输出为:
Init 1
114514
1 2 3
*/除了一些难以用声明形式表达的初始化之外,
init还经常用于在程序实际执行开始之前验证或修复程序状态(比如检查必要的文件目录,修复缺失项)
❗ 指针类型(pointer)和接口类型(interface)上不可定义方法!!
type MyPointer *int
// ⚠ 编译错误: invalid receiver type MyPointer (pointer or interface type)
func (m MyPointer) test() {
fmt.Println(*m)
}其他自定义命名类型都可以用作 receiver,即可以在其上定义方法。
-
💡 没错,函数类型都可以:
type HandlerFunc func(ResponseWriter, *Request) // ServeHTTP calls f(w, req). func (f HandlerFunc) ServeHTTP(w ResponseWriter, req *Request) { f(w, req) }
比如还可以给 []byte 类型取别名后在其上定义方法:
type ByteSlice []byte
func (slice ByteSlice) Append(data []byte) []byte {
return append(slice, data...)
}💡 如果要能原地修改,就需要用指针类型作为 receiver:
func (p *ByteSlice) Append(data []byte) {
*p = append(*p, data...)
}
ByteSlice本身就是引用类型,指向底层的一个数组;*ByteSlice则相当于是引用类型的指针变量,指向一个ByteSlice实例。通过修改指针变量的值,指向append返回的实例,以完成原地修改。
var p *ByteSlice = &ByteSlice{}
*p // 这就是解引用💡 *p 其实就是解引用了指针变量 p,获取其所指向的值。
- ⚠ 注:为了代码可读性,尽量还是用 receiver 对应的类型调用,隐形转换用多了容易混淆。
无论是用了 ByteSlice 还是 *ByteSlice 作为 receiver 定义方法,都可以这样调用:
s := ByteSlice{}
var p *ByteSlice = &s
// 无论 receiver 是用 *ByteSlice 还是 ByteSlice,都可以调用
s.Method()
p.Method()如果是这样定义:
func (o ByteSlice) Method()💡 在通过 p.Method() 调用时其实会自动解引用,相当于这样:(*p).Method()
如果是这样定义:
func (p *ByteSlice) Method()💡 在通过 s.Method() 调用时会自动取地址,相当于这样:(&s).Method()
若定义了:
func (m MyType) Method()且:
var m MyType
var p **MyType = &&m❗ 是不可以通过 p.Method() 调用方法的,Go 语言最多只会自动解一级指针的引用。
即使像这样也不行:
type ByteSlice []byte
func (s *ByteSlice) Method() {
fmt.Println("Can be called on p2")
}
func main() {
s := ByteSlice{}
var p1 *ByteSlice = &s
var p2 **ByteSlice = &p1
s.Method()
// 编译出错: p2.Method undefined (type **ByteSlice has no field or method Method)
p2.Method()
}
p2是多级指针,编译器不会自动解引用。
💡 定义了某个接口中的所有方法后就相当于实现了这个接口。
比如 io.Writer 接口:
type Writer interface {
Write(p []byte) (n int, err error)
}可以在上面的 ByteSlice 上实现一下:
func (p *ByteSlice) Write(bs []byte) (n int, err error) {
*p = append(*p, bs...)
n, err = len(bs), nil
return
}可以看到这里用了命名的函数返回值,这种语法便于代码阅读。
可以看到 fmt.Fprintf 的签名,其接受一个实现 io.Writer 的实例作为首个参数:
func Fprintf(w io.Writer, format string, a ...any) (n int, err error)因此可以这样写:
s := ByteSlice{}
// 注意这里 Write 方法定义在 *ByteSlice 上,所以是 &s
var w io.Writer = &s
fmt.Fprintf(w, "Hello, %s!", "Somebottle")
fmt.Println(string(s)) // Hello, Somebottle! ❗ 注意
func (p *ByteSlice) Write(bs []byte) (n int, err error)是定义在*ByteSlice上的,ByteSlice上并没有Write,因此只有*ByteSlice实现了接口io.Writer。
- ⚠ 注:这里非常容易和上面调用方法时的自动转换机制搞混,要区分开!
-
如果在
ByteSlice上定义了接口方法,*ByteSlice也会继承,因此*ByteSlice也实现了接口。type ByteSlice []byte // Stringer 接口 type Stringer interface { String() string } // 在 ByteSlice 上定义 String 方法 func (b ByteSlice) String() string { return string(b) } func main() { var s Stringer b := ByteSlice{'H', 'e', 'l', 'l', 'o'} s = b // ByteSlice 实现了 Stringer 接口 fmt.Println(s.String()) pb := &b s = pb // *ByteSlice 也实现了 Stringer 接口 fmt.Println(s.String()) }
-
如果在
*ByteSlice上定义了方法,那么就只有*ByteSlice实现了接口,而ByteSlice没有实现接口。// 在 *ByteSlice 上定义 String 方法 func (b *ByteSlice) String() string { return string(*b) } func main() { var s Stringer b := ByteSlice{'H', 'e', 'l', 'l', 'o'} // s = b // 这行会报错,因为 ByteSlice 没有实现 Stringer 接口 pb := &b s = pb // *ByteSlice 实现了 Stringer 接口 fmt.Println(s.String()) }
Go 语言的接口表示了具有相同行为的一类对象,可以认为接口是一组抽象方法的集合。
💡 上面已经提到,为了表意清晰,对于只有一个方法的接口往往以这个方法的名字 + er 来命名,比如 io.Writer 接口只有一个 Write 方法,所以被命名为 Writer。
- 只要在一个类型上定义了接口中所有的方法,那它就实现了这个接口。
- ❗ 一个类型因而能实现多个接口。
对于取了别名的类型是可以在相同类型之间直接进行转换的:
type Sequence []int
func (s Sequence) String() string {
s = s.Copy()
sort.IntSlice(s).Sort()
// 转换回 []int
return fmt.Sprint([]int(s))
}IntSlice的定义是type IntSlice []int,它也是整型切片的别名,因此可以直接把Sequence转换为IntSlice。- ❗ 因为
IntSlice上定义了方法,把Sequence转换为IntSlice后自然也就可以使用这些方法了,比如上面就可以调用IntSlice的Sort方法。
相比让一个类型去实现多个接口,利用这种类型转换来在不同别名类型下调用不同方法的做法也是很有效的。
- ❗ 显然,类型断言只适用于接口类型。
上面已经记录过类型断言 switch 的写法,断言 switch 可以灵活地根据接口变量值的数据类型来路由到不同的转换逻辑上。
type Stringer interface {
String() string
}
var value interface{} // 调用者提供的值
switch str := value.(type) {
case string:
return str
case Stringer:
return str.String()
}可以看到第二个
case就相当于对接口进行了转换。
💡 如果已经知道接口值的具体类型,可以直接用类型断言语法进行显式转换:
value, ok := interfaceVal.(typeName)❗ 类型断言会返回两个值,第二个是一个布尔值,表明
interfaceVal是否持有typeName类型。若不是typeName这个类型,value将会是这个类型的零值。
如果某个类型仅仅是实现了接口,而没有定义其他方法,那么就没有必要把这个类型导出,而只用导出接口类型。
// 导出接口 MyInterface
type MyInterface interface {
DoSomething()
}
// myType 首字母小写,不导出
type myType struct{}
func (t myType) DoSomething() {
// 实现接口方法
}
// 返回接口 MyInterface,而不是 myType
func NewMyType() MyInterface {
return myType{}
}
myType仅仅是实现了MyInterface,其没有额外定义方法。直接导出MyInterface更便于代码可维护性(💡 便于修改具体实现类型),且也不需要重复为myType编写文档。
- 💡 上面这个代码中可以看到,构造函数返回类型时也是遵循这一原则的,对于
myType仅返回接口类型。 - 这样一来便于代码解耦,在修改接口实现类型时,调用方不需要对调用代码进行修改。
比如 Go 加密库中,crc32.NewIEEE 和 adler32.New 就均返回 hash.Hash32 接口类型,而不是具体的实现类型。
空白标识符 _ 可以接受任意类型的任意值,并进行抛弃。其可以视为一个仅可写的占位符。
// 两个返回值,但我只想要 err
if _, err := os.Stat(path); os.IsNotExist(err) {
fmt.Printf("%s does not exist\n", path)
}对于未使用的导入和变量,Go 语言编译器会报错。但是实际开发中,可能会有后面需要用到但现在暂且还没使用的变量,这种时候就可以用占位符,以临时通过编译:
package main
import (
"fmt"
"io"
"log"
"os"
)
var _ = fmt.Printf // For debugging; delete when done.
var _ io.Reader // For debugging; delete when done.
func main() {
fd, err := os.Open("test.go")
if err != nil {
log.Fatal(err)
}
// TODO: use fd.
_ = fd
}❗ 对于 var _ = fmt.Printf 这种调试语句应该紧接在 import 语句之后,这样在开发完毕后能及时发现并清理这些语句。
上面提到过,包中可以有 init 函数来进行一些初始化操作,其在导入包时执行。
有时候只需要这个初始化操作,后续并不会使用这个包,就可以将其重命名为 _:
// 仅执行包初始化,后续不使用包
import _ "net/http/pprof"前面写到,实现接口中的所有方法即实现了接口。
接口的实现和转换有很多是在编译时进行检查的,也有在运行时进行检查的情况。
往往我们可能只需要检查接口的类型,而不需要用到其转换后的值,就可以用空白占位符:
// 类型断言
if _, ok := val.(json.Marshaler); ok {
fmt.Printf("value %v of type %T implements json.Marshaler\n", val, val)
}💡 为了在编译时检查一个类型是否实现了接口,可以写一个对 nil 进行转换的表达式:
var _ json.Marshaler = (*RawMessage)(nil)这样一来在编译的时候编译器就会检查
*RawMessage是否实现了json.Marshaler。
- ❗ 这是比较常见的实践,如果接口发生更改,编译器就不会编译成功,开发者也就能及时注意到这些类型的实现并进行修改更新。
- ❗ 并不是所有实现了接口的类型都要这样写一句,当且仅当代码中没有这种静态转换时才会用到。
Go 语言中没有典型的继承和子类,但是在结构体和接口上有嵌入机制。
可以把已有的接口类型直接列在新接口的定义中,新的接口就能继承这些接口的所有方法声明。
加入已经定义了 Reader 和 Writer 接口,那么可以定义 ReadWriter 如下:
// ReadWriter 结合了两个接口
type ReadWriter interface {
Reader
Writer
}❗ Go 语言中能嵌入接口的只有接口(怎么想也不可能把结构体或其他类型嵌入接口啊)。
💡 类型可以嵌入到结构体中,同样是直接把类型名列出,没有字段名。
嵌入类型上的方法以及字段都会提升(promote)到最外部的结构体类型:
type Job struct {
Command string
*log.Logger
}这样一来
Job就隐含了定义在*log.Logger上的所有方法。
再比如自定义类型:
type MyInt int
type MyStruct struct {
MyInt
}可以看到嵌入的只是类型名,没有字段,那初始化结构体的时候该怎么处理?
💡 其实一样可以用字面量来初始化:
func NewJob(command string, logger *log.Logger) *Job {
return &Job{command, logger}
}💡 比较疯狂的是,你甚至还可以对其重新进行赋值:
// 定义 Person 结构体
type Person struct {
Age int
Id int
}
// 定义 Person 的 Tell 方法
func (p Person) Tell() {
fmt.Printf("Age: %d\n", p.Age)
}
// 定义 Group 结构体,并嵌入 Person
type Group struct {
Person
GroupName string
}
func main() {
// 初始化 Group 实例
g := Group{
Person: Person{
Age: 25,
Id : 0,
},
GroupName: "Go Developers",
}
// 调用嵌入的 Tell 方法
g.Tell()
// 💡 重新为嵌入的 Person 赋值
g.Person = Person{
Age: 30,
Id: 1,
}
// 调用嵌入的 Tell 方法查看更新后的 Age
g.Tell()
}Example. 1
job := NewJob(command, log.New(os.Stderr, "Job: ", log.Ldate))
// 忽略嵌入类型的包名
job.Logger = log.New(os.Stderr, "Job 2: ", log.Ldate)Example. 2
❗ 需要注意:
- 没有字段名,直接通过嵌入的 类型名 访问。
- 嵌入类型的 包名 这个时候要 忽略 掉,比如
Job结构体中嵌入的*log.Logger,重新在变量上赋值时用的是job.Logger来指定。 - 💡 也就是说,嵌入类型名可以视作结构体的一个常规字段来用。
这也是嵌入和子类很不相同的一点。
把类型 A 嵌入到结构体 B 中时:
- 类型 A 的方法变成了外层类型结构体 B 的方法。
- ❗ 但是在结构体 B 的实例上调用这些方法时,其接受者(receiver)仍然是嵌入类型 A 的实例。
// 定义类型 A
type A struct {
Name string
}
// 为类型 A 定义方法 Tell
func (a A) Tell() {
fmt.Printf("Name: %s\n", a.Name)
}
// 定义结构体 B,并嵌入类型 A
type B struct {
A
}
func main() {
// 初始化结构体 B 的实例
b := B{
A: A{
Name: "John",
},
}
// 在结构体 B 上调用 A 的方法 Tell
// 💡 此时 Tell 的 receiver 仍然是 A{Name: "John"} 这个实例
b.Tell()
}接下来来个记忆大恢复术:
type Job struct {
Command string
*log.Logger
}Job 结构体中嵌入了 *log.Logger 方法,*log.Logger 的方法的接受者可能是指针类型,那我在非指针类型的 job 实例上能访问到 *log.Logger 的方法吗?
// 使用非指针类型创建 Job 实例
job := Job{
Command: "example",
Logger: log.New(os.Stdout, "INFO: ", log.LstdFlags),
}
// 直接访问 Logger 的方法
job.Println("This is a log message.")答案是当然可以。上面已经提到,嵌入方法的接受者在这里仍然是 *log.Logger 。以 Println 为例,在调用 job.Println 时, job 是值而不是指针,根据上面第 11 节的纪录,Go 语言是有自动取地址机制的,因此 job.Println 的写法也是可以接受的。
等等,我怎么记得有一个机制是指针类型的接受者不能干啥来着...回去看看第 11.3.1 节,其实这是实现接口时的限制,而不是调用方法时的,一定要区分开!
💡 很明显,嵌入后可能嵌入类型和结构体有方法和字段上的冲突,解决规则如下:
- 外层类型的方法
X会覆盖嵌入类型的方法X。 - 如果嵌入类型的名字和结构体已有的字段或者方法名重合了,是无法通过编译的。
对于第 2 点,如果重复的名字从未在结构体定义之外被使用,是可以接受的:
type A struct {
Name string
}
type B struct {
Name string
}
type C struct {
A
B
}
func main() {
// 虽然 A 和 B 都有 Name 字段,但在 C 的定义之外没有使用它们
c := C{
A: A{Name: "Name from A"},
B: B{Name: "Name from B"},
}
// 手动访问 A 和 B 的 Name 字段
fmt.Println(c.A.Name)
fmt.Println(c.B.Name)
}这个时候如果用
c.Name,编译器会报错,因为不知道到底是指的哪个。
💡 建议还是尽量避开这种容易造成混淆的局面。
Share by communicating.
💡 比起其他编程语言里用各种机制来共享变量这种内存信息,Go 语言鼓励让共享变量在通道(channels)之间传递,而不是让其在各个执行线程间不停被共享。
这种并发模型下,在任意一个时间点,某个共享数据只会有一个 Go 协程(Goroutine)访问,因而数据竞态问题就不会发生。
不要通过共享内存来通信,而是通过通信来共享内存。
❗ 不过死磕这种思路可能会过犹不及,比如引用计数当然还是用互斥量(mutex)搭配一个计数变量来实现更好。
但是作为一种高级别的手段,用通道来控制访问或许能让程序更加清晰。
比如 A、B 是在 CPU 上独立运行的两个单线程的程序,它们各自显然不需要同步原语(primitives)。
如果让 A、B 进行通信,且通信机制本身就能保证同步,那么就不需要额外的同步机制了。
- 例如:程序 A 发送消息给程序 B 时,A 会阻塞直到 B 接收,消息的发送 / 接收本身就是同步的。
💡 Unix 系统的管道 | 机制就是这种同步模型的典型实现,写入和读取会自动阻塞,通信本身同步。
💡 Go 语言的通道 chan 可以视作类型安全的 Unix 管道,因为 Go 语言的通道是有严格的类型检查的。
💡 一个 Goroutine 其实是一个简单的模型:在同一个地址空间中和其他 goroutines 一起并发执行的一个函数。
- Go 协程是轻量的,除了必要的栈空间分配外几乎不怎么占用额外的空间,最开始需要分配的栈空间往往很小,仅在有需要的时候随着分配或释放堆内存而变化。
Goroutines 在底层多路复用(multiplexed)了多条操作系统线程,包装并简化了线程的创建和管理。
💡 在函数调用时,在调用语句前加上一个 go 关键字就能在新的 goroutine 中执行函数调用。函数返回后,Goroutine 也就安静地退出了(很像 Unix Shell 中的后台执行标记 &)。
// 并发运行 list.Sort,不阻塞
go list.Sort()匿名函数调用(函数字面量)也可以转换为 Goroutine 来执行:
func Announce(message string, delay time.Duration) {
go func() {
time.Sleep(delay)
fmt.Println(message)
}() // 匿名函数调用
}❗ 这种匿名函数在 Go 中本质上是闭包(closures),实现上保证被其引用的变量在函数执行期间一直是可用的。
之前提到过,通道 chan 作为复合类型,可以用 make 来创建并初始化:
ci := make(chan int) // 整型通道,无缓冲(unbuffered)如果在 make 第二个参数处传入整型,则会为这个通道配置缓冲(buffer)大小。
cs := make(chan *os.File, 100) // 缓冲大小 100- ❗ 没有缓冲的通道就是一个同步通道,发送方的内容没有被接受时,发送方会一直阻塞下去!适用于对同步要求很高的情况。
💡 同步的(无缓冲)通道把通信(一个值的递交)和同步(确保两个协程的计算顺序是确定的)结合在了一起。
c := make(chan int) // Allocate a channel.
// Start the sort in a goroutine; when it completes, signal on the channel.
go func() {
list.Sort()
c <- 1 // Send a signal; value does not matter.
}()
doSomethingForAWhile()
<-c // Wait for sort to finish; discard sent value.利用无缓冲通道,可以让一个 Goroutine 等待另一个 Goroutine 执行结束以实现同步。
- 再回忆一下,无缓冲通道中,发送者在接收者接受数据前会一直阻塞。
- 如果通道有缓冲,且还有空间,只要数据被复制到了通道内,发送者就会解除阻塞,继续执行后续代码。
- 当通道缓冲区填满时,发送者无法发送数据,也就会被阻塞(直至接收者取走了一个数据)。
可以利用这个性质来实现信号量(Semaphore)机制,以限制吞吐量:
var sem = make(chan int, MaxOutstanding)
func handle(r *Request) {
sem <- 1 // Wait for active queue to drain.
process(r) // May take a long time.
<-sem // Done; enable next request to run.
}
func Serve(queue chan *Request) {
for {
req := <-queue
go handle(req) // Don't wait for handle to finish.
}
}这个例子中,新来的请求会被传递到
handle方法。方法中先将一个值送入通道(Acquire),如果通道满了,说明现在有过多的请求在处理。每一个请求处理完成后,从通道取走一个值(Release)。显然通道缓冲区的大小即限制了同时在处理的请求数量。
❗❗❗ 注意,这个设计有些问题,对于每个到来的请求,
Serve都会创建一个新的 Goroutine,尽管任何时候最多只有MaxOutstanding个 Goroutine 能在同一时刻运行。 如果在某一段时间有巨多请求突然涌入,很容易就会消耗很多资源(创建了很多执行被阻塞的 Goroutine)。
💡 可以通过把这种”信号量“移动到 Serve 方法内来解决问题,仅在实际要执行的时候才创建 Goroutine:
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func() {
process(req)
<-sem
}()
}
}另一种管理资源的方式是启动固定数量的 handle Goroutine,每个 Goroutine 都在尝试从请求队列(一个通道)中读取请求进行处理,Goroutine 的数量也就自然而然决定了同时能处理的请求数量:
func handle(queue chan *Request) {
for r := range queue {
process(r)
}
}
func Serve(clientRequests chan *Request, quit chan bool) {
// Start handlers
for i := 0; i < MaxOutstanding; i++ {
go handle(clientRequests)
}
<-quit // Wait to be told to exit.
}这里
Serve函数还有一个quit通道,用来接受结束执行Serve的信号。
💡 Go 语言中通道类型是一等公民(first-class citizen),即可以被当作基本数据类型来进行自由操作,可以像其他基本类型一样被分配和传递(比如作为实参、返回值)。
通道的一大用途是实现安全、并行的多路分解(demultiplexing,解复用,💡 即把合并的信号拆分回原始信号,并分发给正确的接收方)。
比如上述的每个请求 Request 类型,就可以附带有一个通道,以告诉程序处理完时候应答信息应该递交给谁:
type Request struct {
args []int
f func([]int) int
resultChan chan int
}比如这个请求结构体中包括处理函数、函数参数以及一个用于传递结果对象的通道。
用起来大概是这样:
func sum(a []int) (s int) {
for _, v := range a {
s += v
}
return
}
request := &Request{[]int{3, 4, 5}, sum, make(chan int)}
// 发送请求
clientRequests <- request
// 等待接受请求执行结果
fmt.Printf("answer: %d\n", <-request.resultChan)服务端唯一要变动的就是 handle 函数,把处理结果回传:
func handle(queue chan *Request) {
for req := range queue {
// 处理结果回传
req.resultChan <- req.f(req.args)
}
}如果一个繁杂的运算可以分解成多部分独立执行,这种运算就可以被并行化。
💡 Go 语言中协程会自动被调度,有多个 CPU 时,协程可在多 CPU 上并行执行(CPU 数量不够则会有部分并发执行)。
type Vector []float64
// Apply the operation to v[i], v[i+1] ... up to v[n-1].
func (v Vector) DoSome(i, n int, u Vector, c chan int) {
for ; i < n; i++ {
v[i] += u.Op(v[i])
}
c <- 1 // signal that this piece is done
}
const numCPU = 4 // number of CPU cores
func (v Vector) DoAll(u Vector) {
c := make(chan int, numCPU) // Buffering optional but sensible.
for i := 0; i < numCPU; i++ {
go v.DoSome(i*len(v)/numCPU, (i+1)*len(v)/numCPU, u, c)
}
// Drain the channel.
for i := 0; i < numCPU; i++ {
<-c // wait for one task to complete
}
// All done.
}这个例子中把一个向量中不同分量的运算分成了多片来进行,并用通道
c来标记运算是否全部完成。
其实 Go 语言 runtime 包内有方法可以直接获取主机拥有的 CPU 核数:
var numCPU = runtime.NumCPU()也可以通过这个方法来设置最大可并行使用的 CPU 数量:
runtime.GOMAXPROCS(n int)
runtime.GOMAXPROCS(0) // <1 时不会执行操作,仅获得先前的设置,相当于 runtime.NumCPU()❗ 不过要注意,Go 语言终究还是并发语言,而不是并行语言,因此不是所有的并行化问题都符合 Go 语言的模型。
LeakyBuffer 是一种资源池实现,其特点是:
- 当池中有可用资源时,直接返回给请求者。
- 当池为空时,不是阻塞等待或拒绝请求,而是"泄漏"(创建)一个新的资源实例。
Go 语言中可以利用有缓冲通道实现泄漏缓冲区机制: s
var freeList = make(chan *Buffer, 100)
var serverChan = make(chan *Buffer)
func client() {
for {
var b *Buffer
// Grab a buffer if available; allocate if not.
select {
case b = <-freeList:
// Got one; nothing more to do.
default:
// None free, so allocate a new one.
b = new(Buffer)
}
load(b) // Read next message from the net.
serverChan <- b // Send to server.
}
}
client模拟从某个信息源不断接受消息的场景。为了避免频繁分配和释放缓冲区(buffers),这里维护了一个空闲缓冲区池freeList(也是用通道实现的),当没有多的空闲缓冲区时(freeList为空),则会分配一个新的缓冲区,否则直接取出空闲缓冲区。 在向缓冲区中读取消息后就通过管道serverChan发给服务端。
func server() {
for {
b := <-serverChan // Wait for work.
process(b)
// Reuse buffer if there's room.
select {
case freeList <- b:
// Buffer on free list; nothing more to do.
default:
// Free list full, just carry on.
}
}
}服务端通过
serverChan接收缓冲区(信息)后进行处理,然后归还这个缓冲区到空闲缓冲区列表中。
❗ 注意,这里如果freeList已经满了,这个缓冲区会被直接抛弃掉(跳转到空的default分支),让 GC 自动处理掉。
库方法往往会返回一个指示是否出现错误的状态信息,正好利用了 Go 语言函数可以有多返回值的性质。
- 比如
os.Open在执行出错时就会返回一个错误值来描述发生了什么错误。
Go 语言中 error 类似是一个简单的内置接口类型:
type error interface {
Error() string
}💡 具体实现的时候可以让结构体携带更多错误相关的信息,以辅助诊断:
type PathError struct {
Op string // "open", "unlink", etc.
Path string // The associated file.
Err error // Returned by the system call.
}
func (e *PathError) Error() string {
return e.Op + " " + e.Path + ": " + e.Err.Error()
}比如
PathError就携带了错误相关的:文件操作、文件路径以及系统调用的错误信息。
上面这个实现的 Error() 方法会返回类似于这样的详细信息:
open /etc/passwx: no such file or directory发生了什么问题简直一目了然有木有!
💡 Error() 返回的字串信息应该包含错误发生的源头,比如可以加个前缀来指明是哪个操作或者在哪个包中产生了这个错误。
在处理的时候为了提取错误的详细信息,可以用类型 switch 或类型断言语法来进行处理:
for try := 0; try < 2; try++ {
file, err = os.Create(filename)
if err == nil {
return
}
if e, ok := err.(*os.PathError); ok && e.Err == syscall.ENOSPC {
deleteTempFiles() // Recover some space.
continue
}
return
}先用
ok判断是不是这个类型的错误,如果是,则提取其中的系统调用错误信息Err。
Error 当然也是分等级滴,有的错误一旦发生,程序可能难以继续执行下去(unrecoverable)。
为了报告这种情况,Go 语言内置了 panic 这个函数,其会抛出一个运行时错误(Run-time Error),导致程序终止执行。
- 💡
panic往往只接受一个任意类型的参数,往往是字符串,在程序无法继续执行时会将其打印出来。
❗ 当然,在写库函数时要尽量避免 panic,总不能方法每次执行异常就让进程终止了吧!
var user = os.Getenv("USER")
func init() {
if user == "" {
panic("no value for $USER")
}
}👆 一个正确的用例:库初始化时发生错误,这个时候抛出
panic可以理解。
panic 发生时,会立即停止当前函数的执行并开始回溯 Goroutine 的栈(💡从当前发生 panic 的函数开始逐层退出调用栈中的函数),也就会运行所有被 defer 延迟执行的函数,如果一直这样下去,回溯到栈顶(Goroutine 调用栈的最外层)时,进程最终会终止。
- 即一直到最后都没有函数可以处理这个
panic,导致程序崩溃。
💡 而对 recover 函数的调用会停止这个回溯过程,这个函数会返回传递给 panic 的参数。
- ❗❗❗ 因为在这个回溯过程中只有
defer函数 内 的代码会被执行,recover只有在defer的函数中才有效。
func testPanic(){
panic("boom")
}
func catcher1(){
defer func(){
if r:=recover(); r!=nil {
fmt.Println("PANIC CAUGHT: ", r)
}
}() // ❗ 这里的调用括号 () 不要掉了
// ❗❗ 错误写法 ↓
// defer recover()
testPanic()
}
func recoverFunc(){
if r:=recover(); r!=nil {
fmt.Println("PANIC CAUGHT: ", r)
}
}
func catcher2(){
// 这样写也可以捕获到
defer recoverFunc()
// ❗❗ 错误写法 ↓
// defer recover()
// testPanic 没有捕获 panic
testPanic()
}
func catcher3(){
defer func(){
if r:=recover(); r!=nil {
fmt.Println("PANIC CAUGHT: ", r)
}
}() // ❗ 这里的调用括号 () 不要掉了
// ❗❗ 异步函数的 panic 没法在当前协程捕获
// Go 的设计哲学是每个 Goroutine 都要对自己的生命周期负责
// 主协程(Main Goroutine)里的 `recover` 根本感知不到另一个协程的异常
go testPanic()
}
func catcher4() {
defer func() {
// `recover` 的行为受到严格的**调用栈深度限制**
// recover() 必须在 defer 函数的直接内层 (顶层)
// 即必须作为 deferred function 的“第一层”逻辑
// ❗❗ 错误写法 ↓
recoverFunc()
}()
testPanic()
}很重要的例子,一定要熟悉。
recover 的一个用例就是在服务端中,某个 Goroutine 崩溃时及时进行处理,而不是让进程终止,导致所有 Goroutine 都停止执行:
func server(workChan <-chan *Work) {
for work := range workChan {
go safelyDo(work)
}
}
func safelyDo(work *Work) {
defer func() {
if err := recover(); err != nil {
log.Println("work failed:", err)
}
}()
do(work)
}这个例子中如果
do(work)发生了panic,panic信息会被记录下来,而这个有问题的 Goroutine 会正常退出,而不会影响其他 Go 协程。
💡 库函数的 panic/recover 处理不会影响当前 defer 函数中 panic/recover 的处理。
func safelyDo() {
defer func() {
// 先调用日志函数(可能内部有 panic/recover)
logError("something happened") // 即使 logError 内部有 panic,也不会影响外层 recover
// 再捕获当前 panic(仍然有效)
if err := recover(); err != nil {
fmt.Println("Recovered in safelyDo:", err)
}
}()
doSomethingRisky() // 可能触发 panic
}
func logError(msg string) {
// 假设这个日志库内部可能 panic 并自行 recover
defer func() {
if err := recover(); err != nil {
fmt.Println("Logged panic in library:", err)
}
}()
panic("logError fake panic") // 模拟库内部 panic
}💡 即
recover()只会捕获当前层或更内层中未经处理的panic,如果没有panic,recover()只会返回nil。内层处理了panic的不会传播到外层。
❗ 总结大概是这样:
recover必须在defer函数中第一层被调用- 内层捕获、外层无感知
- 内层未捕获,外层可捕获(和 Python 的
except很像)
在复杂软件开发中可以用 panic/recover 来简化错误处理:
// Error is the type of a parse error; it satisfies the error interface.
type Error string
func (e Error) Error() string {
return string(e)
}
// error is a method of *Regexp that reports parsing errors by
// panicking with an Error.
func (regexp *Regexp) error(err string) {
panic(Error(err))
}
// Compile returns a parsed representation of the regular expression.
func Compile(str string) (regexp *Regexp, err error) {
regexp = new(Regexp)
// doParse will panic if there is a parse error.
defer func() {
if e := recover(); e != nil {
regexp = nil // Clear return value.
err = e.(Error) // Will re-panic if not a parse error.
}
}()
return regexp.doParse(str), nil
}这里
Compile方法有已命名的返回值,发生panic时,recover处理块会把返回的regexp设为nil并设置返回的错误值err。❗ 如果
e不是指定的错误Error,类型断言会继续产生一个运行时错误(panic),继续向上层回溯调用栈。如果有未曾预料的错误发生了,会继续panic,注意,上面这个代码的写法中,新的panic没有包含原始e的信息,但是因为是断言时发生的问题,如果直接在上层崩溃,在程序崩溃报告时新的panic和旧的panic信息都会被记录。
defer func() {
if e := recover(); e != nil {
regexp = nil
if parseErr, ok := e.(Error); ok { // 检查是否是预期的 Error 类型
err = parseErr // 如果是,转为 error 返回
} else {
panic(e) // 如果不是,重新 panic(e)
}
}
}()这样写的话,原始错误
e如果无法处理会继续向上panic。
这样一来,在 doParse 中发生错误时,可以直接调用 error 方法来 panic,反正都会被 recover 所捕获,这样就简化了错误处理的写法:
if pos == 0 {
re.error("'*' illegal at start of expression")
}- ❗ 注意:库内部的错误不应该作为
panic抛出到库外部(除非是库所不知道的意外错误),传递到外部时还是得转换为库中定义的Error值。
unsafe 包的 Sizeof 方法可以窥见某个类型变量所占用的内存,可以先看看官方文档的描述:
Sizeoftakes an expression x of any type and returns the size in bytes of a hypothetical variable v as if v was declared via var v = x. The size does not include any memory possibly referenced by x. For instance, if x is a slice, Sizeof returns the size of the slice descriptor, not the size of the memory referenced by the slice; if x is an interface, Sizeof returns the size of the interface value itself, not the size of the value stored in the interface. For a struct, the size includes any padding introduced by field alignment. The return value of Sizeof is a Go constant if the type of the argument x does not have variable size. (A type has variable size if it is a type parameter or if it is an array or struct type with elements of variable size).
Sizeof的输入是一个任意类型的表达式x。假设将其赋值给某个变量v,Sizeof的输出是变量v存储占用的实际字节数,简单说看的是值本身的占用字节数。 ❗❗❗ 这个字节数不包含任何x底层所引用的内存部分。举例来说:
- 如果
x是一个切片,Sizeof会返回切片描述符(x其实是一个结构体)的大小;- 如果
x是一个接口,其返回的是interface本身的占用,而不是接口内部实际存储占用的字节数;- 对于结构体,其返回的字节数包含字段内存对齐所引入的填充。
如果参数
x的类型大小在编译期就能确定,那么unsafe.Sizeof(x)的结果就是一个 Go 常量,可以赋给const常量。 但如果x的类型大小不是固定的,那结果就不是编译期常量。
因此 Sizeof 返回值和类型内存布局有关,典型要注意的有下面几种。
string 虽然是值类型,但他的值本身不是字符串内容字节,而是一个类似结构体的描述符:
type stringStruct struct {
data *byte
len int
}存了一个长度以及指向底层数据的指针。
Sizeof 返回的就是这个描述符占用的大小,data 和 len 各自占一个机器字,因此:
- 64 bit 机器:8+8=16 字节
- 32 bit 机器:4+4=8 字节
slice 则包含数据指针 data、长度 len、底层容量 cap 三个机器字,因此:
- 64 bit 机器:8+8+8=24 字节
- 32 bit 机器:4+4+4=12 字节
interface 值通常包含类型指针 type 和一个数据指针 data,两个机器字,因此:
- 64 bit 机器:16 字节
- 32 bit 机器:8 字节
结构体包含编译器插入的填充(为了字段对齐),因此总占用大小不定。 Sizeof 返回包含填充在内的整个结构体大小。