diff --git a/.readme_assets/CCF-Deadlines_TUI_2026-05-01T19_50_27_068657.svg b/.readme_assets/CCF-Deadlines_TUI_2026-05-01T19_50_27_068657.svg
new file mode 100644
index 000000000..835fb7a55
--- /dev/null
+++ b/.readme_assets/CCF-Deadlines_TUI_2026-05-01T19_50_27_068657.svg
@@ -0,0 +1,306 @@
+
diff --git a/README.md b/README.md
index b1ea6dbb4..0be0a1dc3 100644
--- a/README.md
+++ b/README.md
@@ -31,17 +31,19 @@ English | [简体中文](https://translate.google.com/translate?sl=auto&tl=zh&u=
SwiftBar Plugin
|
-  |
+ |
 |
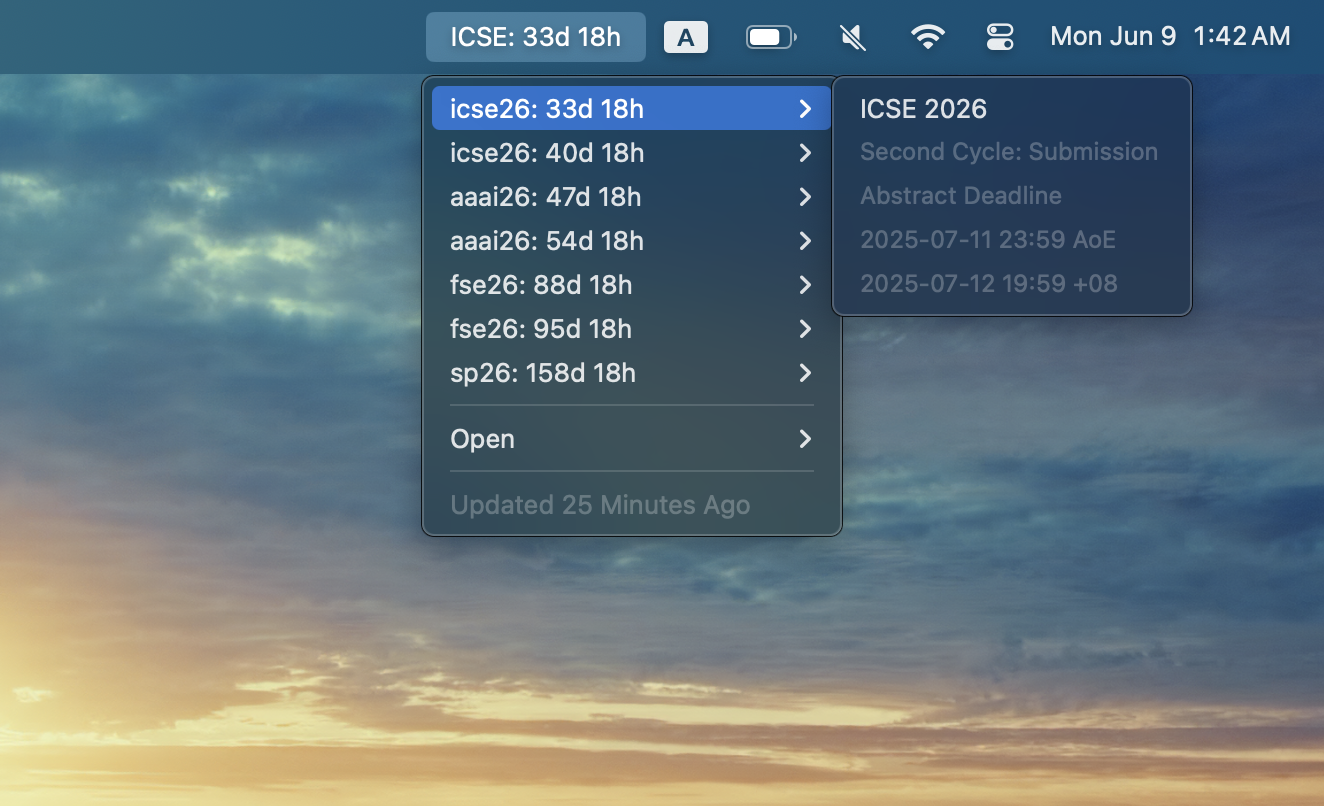 |
iCal Subscription
|
Chrome Extension
|
+ TUI App
|
 |
 |
+  |
diff --git a/extensions/cli/ccfddl/__init__.py b/extensions/cli/ccfddl/__init__.py
index e69de29bb..d2357501e 100755
--- a/extensions/cli/ccfddl/__init__.py
+++ b/extensions/cli/ccfddl/__init__.py
@@ -0,0 +1,48 @@
+"""CCFDDL CLI - Conference Deadline Tracker."""
+
+__version__ = "0.2.0"
+__author__ = "0x4f5da2"
+
+from ccfddl.utils import load_mapping, get_timezone, reverse_index, format_duration, parse_datetime_with_tz
+from ccfddl.models import (
+ Conference,
+ ConferenceYear,
+ Timeline,
+ Rank,
+ Category,
+ CATEGORIES,
+ VALID_SUBS,
+ get_category_by_sub,
+ get_all_subs,
+ is_valid_sub,
+)
+from ccfddl.fetch import fetch_conferences, process_conference_deadlines, filter_results, extract_alpha_id
+from ccfddl.output import output_table, output_json, list_categories, format_colored_duration
+
+__all__ = [
+ "__version__",
+ "__author__",
+ "load_mapping",
+ "get_timezone",
+ "reverse_index",
+ "format_duration",
+ "parse_datetime_with_tz",
+ "Conference",
+ "ConferenceYear",
+ "Timeline",
+ "Rank",
+ "Category",
+ "CATEGORIES",
+ "VALID_SUBS",
+ "get_category_by_sub",
+ "get_all_subs",
+ "is_valid_sub",
+ "fetch_conferences",
+ "process_conference_deadlines",
+ "filter_results",
+ "extract_alpha_id",
+ "output_table",
+ "output_json",
+ "list_categories",
+ "format_colored_duration",
+]
diff --git a/extensions/cli/ccfddl/__main__.py b/extensions/cli/ccfddl/__main__.py
index 31b5b0bb8..f2a7c098e 100755
--- a/extensions/cli/ccfddl/__main__.py
+++ b/extensions/cli/ccfddl/__main__.py
@@ -1,121 +1,87 @@
-import string
-import requests
-import yaml
-from termcolor import colored
-from argparse import ArgumentParser
-from copy import deepcopy
-from datetime import datetime
-from tabulate import tabulate
-from datetime import timezone
-
-
-def parse_tz(tz):
- if tz == "AoE":
- return "-1200"
- elif tz.startswith("UTC-"):
- return "-{:04d}".format(int(tz[4:]))
- elif tz.startswith("UTC+"):
- return "+{:04d}".format(int(tz[4:]))
- else:
- return "+0000"
-
-
-def parse_args():
- parser = ArgumentParser(description="cli for ccfddl")
- parser.add_argument("--conf", type=str, nargs='+',
- help="A list of conference ids you want to filter, e.g.: '--conf CVPR ICML'")
- parser.add_argument("--sub", type=str, nargs='+',
- help="A list of subcategories ids you want to filter, e.g.: '--sub AI CG'")
- parser.add_argument("--rank", type=str, nargs='+',
- help="A list of ranks you want to filter, e.g.: '--rank C N'")
- args = parser.parse_args()
- # Convert all arguments to lowercase
- for arg_name in vars(args):
- arg_value = getattr(args, arg_name)
- if arg_value:
- setattr(args, arg_name, [arg.lower() for arg in arg_value])
- return args
-
-
-def format_duraton(ddl_time: datetime, now: datetime) -> str:
- duration = ddl_time - now
- months, days= duration.days // 30, duration.days
- hours, remainder= divmod(duration.seconds, 3600)
- minutes, seconds = divmod(remainder, 60)
-
- day_word_str = "days" if days > 1 else "day "
- # for alignment
- months_str, days_str, = str(months).zfill(2), str(days).zfill(2)
- hours_str, minutes_str = str(hours).zfill(2), str(minutes).zfill(2)
-
- if days < 1:
- return colored(f'{hours_str}:{minutes_str}:{seconds}', "red")
- if days < 30:
- return colored(f'{days_str} {day_word_str}, {hours_str}:{minutes_str}', "yellow")
- if days < 100:
- return colored(f"{days_str} {day_word_str}", "blue")
- return colored(f"{months_str} months", "green")
-
-
-def main():
+"""CCFDDL CLI - Conference Deadline Tracker.
+
+A command-line tool for viewing and filtering conference deadlines.
+"""
+
+import argparse
+from datetime import datetime, timezone
+
+from ccfddl import __version__
+from ccfddl.fetch import fetch_conferences, filter_results, process_conference_deadlines
+from ccfddl.output import list_categories, output_json, output_table
+
+
+def parse_args() -> argparse.Namespace:
+ """Parse command-line arguments."""
+ parser = argparse.ArgumentParser(
+ description="CCFDDL CLI - Conference Deadline Tracker",
+ epilog="Example: ccfddl --conf CVPR ICML --sub AI --rank A",
+ )
+ parser.add_argument(
+ "--version",
+ action="version",
+ version=f"%(prog)s {__version__}",
+ )
+ parser.add_argument(
+ "--conf",
+ type=str,
+ nargs="+",
+ help="Filter by conference IDs (e.g., --conf CVPR ICML)",
+ )
+ parser.add_argument(
+ "--sub",
+ type=str,
+ nargs="+",
+ help="Filter by subcategories (e.g., --sub AI CG)",
+ )
+ parser.add_argument(
+ "--rank",
+ type=str,
+ nargs="+",
+ help="Filter by CCF ranks (e.g., --rank A B)",
+ )
+ parser.add_argument(
+ "--json",
+ action="store_true",
+ help="Output in JSON format",
+ )
+ parser.add_argument(
+ "--list-categories",
+ action="store_true",
+ help="List all categories",
+ )
+ parser.add_argument(
+ "--url",
+ type=str,
+ default="https://ccfddl.github.io/conference/allconf.yml",
+ help="URL to fetch conference data (default: ccfddl.github.io)",
+ )
+ return parser.parse_args()
+
+
+def main() -> None:
+ """Main entry point."""
args = parse_args()
- yml_str = requests.get(
- "https://ccfddl.github.io/conference/allconf.yml").content.decode("utf-8")
- all_conf = yaml.safe_load(yml_str)
-
- all_conf_ext = []
- now = datetime.now(tz=timezone.utc)
- for conf in all_conf:
- for c in conf["confs"]:
- cur_conf = deepcopy(conf)
- cur_conf["title"] = cur_conf["title"] + str(c["year"])
- cur_conf.update(c)
- time_obj = None
- tz = parse_tz(c["timezone"])
- for d in c["timeline"]:
- try:
- cur_d = datetime.strptime(
- d["deadline"] + " {}".format(tz), '%Y-%m-%d %H:%M:%S %z')
- if cur_d < now:
- continue
- if time_obj is None or cur_d < time_obj:
- time_obj = cur_d
- except Exception as e:
- pass
- if time_obj is not None:
- cur_conf["time_obj"] = time_obj
- if time_obj > now:
- all_conf_ext.append(cur_conf)
- all_conf_ext = sorted(all_conf_ext, key=lambda x: x['time_obj'])
+ if args.list_categories:
+ list_categories()
+ return
- # This is not an elegant solution.
- # The purpose is to keep the above logic untouched,
- # return alpha id(conf name) without digits(year)
- def alpha_id(with_digits: string) -> string:
- return ''.join(char for char in with_digits.lower() if char.isalpha())
-
- table = [["Title", "Sub", "Rank", "DDL", "Link"]]
- # Filter intersection by args
- for x in all_conf_ext:
- skip = False
- if args.conf and alpha_id(x["id"]) not in args.conf:
- skip = True
- if args.sub and alpha_id(x["sub"]) not in args.sub:
- skip = True
- if args.rank and alpha_id(x["rank"]) not in args.rank:
- skip = True
- if skip:
- continue
- table.append(
- [x["title"],
- x["sub"],
- x["rank"],
- format_duraton(x["time_obj"], now),
- x["link"]]
- )
-
- print(tabulate(table, headers='firstrow', tablefmt='fancy_grid'))
+ now = datetime.now(tz=timezone.utc)
+ conferences = fetch_conferences(args.url)
+ results = process_conference_deadlines(conferences, now)
+
+ filtered = filter_results(
+ results,
+ args.conf,
+ args.sub,
+ args.rank,
+ )
+
+ if args.json:
+ output_json(filtered)
+ else:
+ output_table(filtered, now)
if __name__ == "__main__":
diff --git a/extensions/cli/ccfddl/convert_to_ical.py b/extensions/cli/ccfddl/convert_to_ical.py
index 7e250e054..dd041ba8d 100644
--- a/extensions/cli/ccfddl/convert_to_ical.py
+++ b/extensions/cli/ccfddl/convert_to_ical.py
@@ -11,6 +11,8 @@
def load_mapping(path: str = "conference/types.yml"):
with open(path, encoding="utf-8") as f:
types = yaml.safe_load(f)
+ if types is None:
+ return {}
SUB_MAPPING = {}
for types_data in types:
SUB_MAPPING[types_data["sub"]] = types_data["name"]
@@ -220,6 +222,9 @@ def reverse_index(file_paths: list[str], subs: list[str]):
with open(file_path, "r", encoding="utf-8") as f:
conferences = yaml.safe_load(f)
+ if conferences is None:
+ continue
+
for conf_data in conferences:
sub = conf_data["sub"]
rank = conf_data["rank"]
diff --git a/extensions/cli/ccfddl/convert_to_rss.py b/extensions/cli/ccfddl/convert_to_rss.py
index 4bcc92876..30bfc91b7 100644
--- a/extensions/cli/ccfddl/convert_to_rss.py
+++ b/extensions/cli/ccfddl/convert_to_rss.py
@@ -2,7 +2,7 @@
from datetime import datetime, timedelta, timezone
from email.utils import format_datetime
-from convert_to_ical import load_mapping, get_timezone, reverse_index
+from ccfddl.convert_to_ical import load_mapping, get_timezone, reverse_index
import yaml
@@ -31,6 +31,9 @@ def convert_to_rss(
with open(file_path, "r", encoding="utf-8") as f:
conferences = yaml.safe_load(f)
+ if conferences is None:
+ continue
+
for conf_data in conferences:
title = conf_data["title"]
sub = conf_data["sub"]
diff --git a/extensions/cli/ccfddl/fetch.py b/extensions/cli/ccfddl/fetch.py
new file mode 100644
index 000000000..9e8ec8f5f
--- /dev/null
+++ b/extensions/cli/ccfddl/fetch.py
@@ -0,0 +1,119 @@
+"""Data fetching and processing for CCFDDL.
+
+This module handles fetching conference data from remote sources
+and processing deadlines.
+"""
+
+import sys
+from datetime import datetime
+
+import requests
+import yaml
+
+from ccfddl.models import Conference, get_category_by_sub
+from ccfddl.utils import parse_datetime_with_tz
+
+
+def extract_alpha_id(with_digits: str) -> str:
+ """Extract alphabetic characters from string, converted to lowercase."""
+ return "".join(char for char in with_digits.lower() if char.isalpha())
+
+
+def fetch_conferences(url: str) -> list[Conference]:
+ """Fetch and parse conference data from URL."""
+ try:
+ response = requests.get(url, timeout=30, allow_redirects=True)
+ response.raise_for_status()
+ content = response.content
+ data = yaml.safe_load(content)
+ if data is None:
+ print("Warning: No data returned from URL", file=sys.stderr)
+ return []
+ return [Conference.from_dict(item) for item in data]
+ except requests.RequestException as e:
+ print(f"Error fetching data: {e}", file=sys.stderr)
+ sys.exit(1)
+ except yaml.YAMLError as e:
+ print(f"Error parsing YAML: {e}", file=sys.stderr)
+ sys.exit(1)
+
+
+def process_conference_deadlines(
+ conferences: list[Conference], now: datetime
+) -> list[dict[str, any]]:
+ """Process conferences and extract upcoming deadlines."""
+ results = []
+
+ for conf in conferences:
+ base_info = {
+ "title": conf.title,
+ "description": conf.description,
+ "sub": conf.sub,
+ "rank": conf.rank.ccf,
+ "dblp": conf.dblp,
+ }
+
+ for conf_year in conf.confs:
+ time_obj = None
+
+ for timeline in conf_year.timeline:
+ deadline_str = timeline.deadline
+ if not deadline_str or deadline_str == "TBD":
+ continue
+
+ try:
+ cur_d = parse_datetime_with_tz(deadline_str, conf_year.timezone)
+ if cur_d < now:
+ continue
+ if time_obj is None or cur_d < time_obj:
+ time_obj = cur_d
+ except ValueError:
+ continue
+
+ if time_obj is not None:
+ category = get_category_by_sub(conf.sub)
+ result = {
+ **base_info,
+ "year": conf_year.year,
+ "id": conf_year.id,
+ "link": conf_year.link,
+ "deadline": time_obj,
+ "deadline_str": time_obj.strftime("%Y-%m-%d %H:%M:%S %Z"),
+ "timezone": conf_year.timezone,
+ "date": conf_year.date,
+ "place": conf_year.place,
+ "subname": category.name if category else conf.sub,
+ "subname_en": category.name_en if category else conf.sub,
+ }
+ results.append(result)
+
+ results.sort(key=lambda x: x["deadline"])
+ return results
+
+
+def filter_results(
+ results: list[dict[str, any]],
+ conf_filter: list[str] | None,
+ sub_filter: list[str] | None,
+ rank_filter: list[str] | None,
+) -> list[dict[str, any]]:
+ """Apply filters to results."""
+ filtered = []
+
+ conf_filter_lower = [f.lower() for f in conf_filter] if conf_filter else None
+ sub_filter_lower = [f.lower() for f in sub_filter] if sub_filter else None
+ rank_filter_lower = [f.lower() for f in rank_filter] if rank_filter else None
+
+ for item in results:
+ if conf_filter_lower:
+ id_alpha = extract_alpha_id(item["id"])
+ title_alpha = extract_alpha_id(item["title"])
+ if id_alpha not in conf_filter_lower and title_alpha not in conf_filter_lower:
+ continue
+ if sub_filter_lower and extract_alpha_id(item["sub"]) not in sub_filter_lower:
+ continue
+ if rank_filter_lower and item["rank"].lower() not in rank_filter_lower:
+ continue
+ filtered.append(item)
+
+ return filtered
diff --git a/extensions/cli/ccfddl/models.py b/extensions/cli/ccfddl/models.py
new file mode 100644
index 000000000..21eff5641
--- /dev/null
+++ b/extensions/cli/ccfddl/models.py
@@ -0,0 +1,182 @@
+"""Data models for CCFDDL conference data.
+
+This module contains dataclasses that represent the structure of conference data,
+migrated from the Rust/WASM frontend (src/components/conf.rs).
+"""
+
+from dataclasses import dataclass, field
+from typing import Any, Optional
+
+
+@dataclass
+class Rank:
+ """Conference ranking information."""
+ ccf: str
+ core: Optional[str] = None
+ thcpl: Optional[str] = None
+
+ @classmethod
+ def from_dict(cls, data: dict[str, Any]) -> "Rank":
+ return cls(
+ ccf=data.get("ccf", "N"),
+ core=data.get("core"),
+ thcpl=data.get("thcpl"),
+ )
+
+ def to_dict(self) -> dict[str, Any]:
+ result: dict[str, Any] = {"ccf": self.ccf}
+ if self.core is not None:
+ result["core"] = self.core
+ if self.thcpl is not None:
+ result["thcpl"] = self.thcpl
+ return result
+
+
+@dataclass
+class Timeline:
+ """Timeline entry for a conference deadline."""
+ deadline: str
+ abstract_deadline: Optional[str] = None
+ comment: Optional[str] = None
+
+ @classmethod
+ def from_dict(cls, data: dict[str, Any]) -> "Timeline":
+ return cls(
+ deadline=data.get("deadline", ""),
+ abstract_deadline=data.get("abstract_deadline"),
+ comment=data.get("comment"),
+ )
+
+ def to_dict(self) -> dict[str, Any]:
+ result: dict[str, Any] = {"deadline": self.deadline}
+ if self.abstract_deadline is not None:
+ result["abstract_deadline"] = self.abstract_deadline
+ if self.comment is not None:
+ result["comment"] = self.comment
+ return result
+
+
+@dataclass
+class ConferenceYear:
+ """Conference information for a specific year."""
+ year: int
+ id: str
+ link: str
+ timeline: list[Timeline]
+ timezone: str
+ date: str
+ place: str
+
+ @classmethod
+ def from_dict(cls, data: dict[str, Any]) -> "ConferenceYear":
+ timeline_data = data.get("timeline", [])
+ return cls(
+ year=data.get("year", 0),
+ id=data.get("id", ""),
+ link=data.get("link", ""),
+ timeline=[Timeline.from_dict(t) for t in timeline_data],
+ timezone=data.get("timezone", "UTC"),
+ date=data.get("date", ""),
+ place=data.get("place", ""),
+ )
+
+ def to_dict(self) -> dict[str, Any]:
+ return {
+ "year": self.year,
+ "id": self.id,
+ "link": self.link,
+ "timeline": [t.to_dict() for t in self.timeline],
+ "timezone": self.timezone,
+ "date": self.date,
+ "place": self.place,
+ }
+
+
+@dataclass
+class Conference:
+ """Conference data model matching the YAML schema."""
+ title: str
+ description: str
+ sub: str
+ rank: Rank
+ dblp: str
+ confs: list[ConferenceYear] = field(default_factory=list)
+
+ @classmethod
+ def from_dict(cls, data: dict[str, Any]) -> "Conference":
+ rank_data = data.get("rank", {})
+ confs_data = data.get("confs", [])
+ return cls(
+ title=data.get("title", ""),
+ description=data.get("description", ""),
+ sub=data.get("sub", ""),
+ rank=Rank.from_dict(rank_data),
+ dblp=data.get("dblp", ""),
+ confs=[ConferenceYear.from_dict(c) for c in confs_data],
+ )
+
+ def to_dict(self) -> dict[str, Any]:
+ return {
+ "title": self.title,
+ "description": self.description,
+ "sub": self.sub,
+ "rank": self.rank.to_dict(),
+ "dblp": self.dblp,
+ "confs": [c.to_dict() for c in self.confs],
+ }
+
+
+@dataclass
+class Category:
+ """Conference category with Chinese and English names."""
+ name: str
+ name_en: str
+ sub: str
+
+ @classmethod
+ def from_dict(cls, data: dict[str, Any]) -> "Category":
+ return cls(
+ name=data.get("name", ""),
+ name_en=data.get("name_en", ""),
+ sub=data.get("sub", ""),
+ )
+
+ def to_dict(self) -> dict[str, Any]:
+ return {
+ "name": self.name,
+ "name_en": self.name_en,
+ "sub": self.sub,
+ }
+
+
+CATEGORIES: list[Category] = [
+ Category(name="计算机体系结构/并行与分布计算/存储系统", name_en="Computer Architecture", sub="DS"),
+ Category(name="计算机网络", name_en="Network System", sub="NW"),
+ Category(name="网络与信息安全", name_en="Network and System Security", sub="SC"),
+ Category(name="软件工程/系统软件/程序设计语言", name_en="Software Engineering", sub="SE"),
+ Category(name="数据库/数据挖掘/内容检索", name_en="Database", sub="DB"),
+ Category(name="计算机科学理论", name_en="Computing Theory", sub="CT"),
+ Category(name="计算机图形学与多媒体", name_en="Graphics", sub="CG"),
+ Category(name="人工智能", name_en="Artificial Intelligence", sub="AI"),
+ Category(name="人机交互与普适计算", name_en="Computer-Human Interaction", sub="HI"),
+ Category(name="交叉/综合/新兴", name_en="Interdiscipline", sub="MX"),
+]
+
+SUB_TO_CATEGORY: dict[str, Category] = {cat.sub: cat for cat in CATEGORIES}
+
+VALID_SUBS: set[str] = {cat.sub for cat in CATEGORIES}
+
+
+def get_category_by_sub(sub: str) -> Optional[Category]:
+ """Get category by sub code."""
+ return SUB_TO_CATEGORY.get(sub)
+
+
+def get_all_subs() -> list[str]:
+ """Get all valid sub codes."""
+ return list(VALID_SUBS)
+
+
+def is_valid_sub(sub: str) -> bool:
+ """Check if sub code is valid."""
+ return sub in VALID_SUBS
diff --git a/extensions/cli/ccfddl/output.py b/extensions/cli/ccfddl/output.py
new file mode 100644
index 000000000..7b1cb4d10
--- /dev/null
+++ b/extensions/cli/ccfddl/output.py
@@ -0,0 +1,81 @@
+"""Output formatting for CCFDDL.
+
+This module handles formatting and displaying conference data
+in various formats (table, JSON).
+"""
+
+import json
+from datetime import datetime
+
+from tabulate import tabulate
+from termcolor import colored
+
+from ccfddl.models import CATEGORIES
+from ccfddl.utils import format_duration
+
+
+def format_colored_duration(ddl_time: datetime, now: datetime) -> str:
+ """Format duration with color coding."""
+ duration_str = format_duration(ddl_time, now)
+ days = (ddl_time - now).days
+
+ if days < 1:
+ return colored(duration_str, "red")
+ elif days < 30:
+ return colored(duration_str, "yellow")
+ elif days < 100:
+ return colored(duration_str, "blue")
+ else:
+ return colored(duration_str, "green")
+
+
+def output_table(results: list[dict[str, any]], now: datetime) -> None:
+ """Output results as a formatted table."""
+ if not results:
+ print("No upcoming deadlines found.")
+ return
+
+ table = [["Title", "Sub", "Rank", "DDL", "Link"]]
+
+ for item in results:
+ table.append([
+ f"{item['title']} {item['year']}",
+ item["sub"],
+ item["rank"],
+ format_colored_duration(item["deadline"], now),
+ item["link"],
+ ])
+
+ print(tabulate(table, headers="firstrow", tablefmt="fancy_grid"))
+
+
+def output_json(results: list[dict[str, any]]) -> None:
+ """Output results as JSON."""
+ output = []
+ for item in results:
+ output.append({
+ "title": item["title"],
+ "year": item["year"],
+ "id": item["id"],
+ "sub": item["sub"],
+ "subname": item["subname"],
+ "subname_en": item["subname_en"],
+ "rank": item["rank"],
+ "deadline": item["deadline_str"],
+ "timezone": item["timezone"],
+ "date": item["date"],
+ "place": item["place"],
+ "link": item["link"],
+ "dblp": item["dblp"],
+ })
+ print(json.dumps(output, indent=2, ensure_ascii=False))
+
+
+def list_categories() -> None:
+ """Print all available categories."""
+ print("Available Categories:")
+ print("-" * 60)
+ for cat in CATEGORIES:
+ print(f" {cat.sub:4s} | {cat.name_en:30s} | {cat.name}")
+ print("-" * 60)
+ print(f"Total: {len(CATEGORIES)} categories")
diff --git a/extensions/cli/ccfddl/tests/__init__.py b/extensions/cli/ccfddl/tests/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/extensions/cli/ccfddl/tests/conftest.py b/extensions/cli/ccfddl/tests/conftest.py
new file mode 100644
index 000000000..62236bd3c
--- /dev/null
+++ b/extensions/cli/ccfddl/tests/conftest.py
@@ -0,0 +1 @@
+pytest_plugins = []
diff --git a/extensions/cli/ccfddl/tests/test_main.py b/extensions/cli/ccfddl/tests/test_main.py
new file mode 100644
index 000000000..6aafe114d
--- /dev/null
+++ b/extensions/cli/ccfddl/tests/test_main.py
@@ -0,0 +1,152 @@
+import pytest
+from datetime import datetime, timezone, timedelta
+from unittest.mock import patch, MagicMock
+
+from ccfddl.__main__ import parse_args, main
+from ccfddl.fetch import extract_alpha_id
+from ccfddl.utils import format_duration, get_timezone
+
+
+class TestGetTimezone:
+ def test_aoe(self):
+ tz = get_timezone("AoE")
+ assert tz == timezone(timedelta(hours=-12))
+
+ def test_utc(self):
+ tz = get_timezone("UTC")
+ assert tz == timezone.utc
+
+ def test_utc_negative(self):
+ tz = get_timezone("UTC-8")
+ assert tz == timezone(timedelta(hours=-8))
+
+ def test_utc_positive(self):
+ tz = get_timezone("UTC+8")
+ assert tz == timezone(timedelta(hours=8))
+
+ def test_invalid_format(self):
+ with pytest.raises(ValueError):
+ get_timezone("GMT+8")
+
+
+class TestParseArgs:
+ def test_no_args(self):
+ with patch("sys.argv", ["ccfddl"]):
+ args = parse_args()
+ assert args.conf is None
+ assert args.sub is None
+ assert args.rank is None
+
+ def test_conf_args(self):
+ with patch("sys.argv", ["ccfddl", "--conf", "CVPR", "ICML"]):
+ args = parse_args()
+ assert args.conf == ["CVPR", "ICML"]
+
+ def test_sub_args(self):
+ with patch("sys.argv", ["ccfddl", "--sub", "AI", "CG"]):
+ args = parse_args()
+ assert args.sub == ["AI", "CG"]
+
+ def test_rank_args(self):
+ with patch("sys.argv", ["ccfddl", "--rank", "A", "B"]):
+ args = parse_args()
+ assert args.rank == ["A", "B"]
+
+ def test_json_flag(self):
+ with patch("sys.argv", ["ccfddl", "--json"]):
+ args = parse_args()
+ assert args.json is True
+
+ def test_list_categories_flag(self):
+ with patch("sys.argv", ["ccfddl", "--list-categories"]):
+ args = parse_args()
+ assert args.list_categories is True
+
+
+class TestFormatDuration:
+ @pytest.fixture
+ def now(self):
+ return datetime(2025, 6, 1, 12, 0, 0, tzinfo=timezone.utc)
+
+ def test_less_than_one_day(self, now):
+ ddl = now + timedelta(hours=5, minutes=30, seconds=45)
+ result = format_duration(ddl, now)
+ assert "05:30:45" in result
+
+ def test_less_than_30_days(self, now):
+ ddl = now + timedelta(days=15, hours=10, minutes=20)
+ result = format_duration(ddl, now)
+ assert "15 days" in result
+
+ def test_less_than_100_days(self, now):
+ ddl = now + timedelta(days=50)
+ result = format_duration(ddl, now)
+ assert "50 day" in result
+
+ def test_more_than_100_days(self, now):
+ ddl = now + timedelta(days=150)
+ result = format_duration(ddl, now)
+ assert "05 months" in result
+
+ def test_single_day(self, now):
+ ddl = now + timedelta(days=1)
+ result = format_duration(ddl, now)
+ assert "01 day" in result
+
+
+class TestExtractAlphaId:
+ def test_with_digits(self):
+ assert extract_alpha_id("CVPR2025") == "cvpr"
+
+ def test_lowercase(self):
+ assert extract_alpha_id("cvpr2025") == "cvpr"
+
+ def test_mixed_case(self):
+ assert extract_alpha_id("IcMl2025") == "icml"
+
+ def test_no_digits(self):
+ assert extract_alpha_id("NEURIPS") == "neurips"
+
+ def test_with_special_chars(self):
+ assert extract_alpha_id("CVPR-2025") == "cvpr"
+
+ def test_empty_string(self):
+ assert extract_alpha_id("") == ""
+
+
+class TestMain:
+ @patch("ccfddl.fetch.requests.get")
+ def test_main_basic(self, mock_get):
+ mock_response = MagicMock()
+ mock_response.content = """
+- title: CVPR
+ description: Test Conference
+ sub: AI
+ rank:
+ ccf: A
+ dblp: cvpr
+ confs:
+ - year: 2030
+ id: cvpr30
+ link: https://example.com
+ timeline:
+ - deadline: '2030-01-01 12:00:00'
+ timezone: UTC+0
+ date: June 2030
+ place: Test City
+""".encode("utf-8")
+ mock_response.raise_for_status = MagicMock()
+ mock_get.return_value = mock_response
+
+ with patch("sys.argv", ["ccfddl"]):
+ main()
+
+ mock_get.assert_called_once()
+
+ @patch("builtins.print")
+ def test_list_categories(self, mock_print):
+ with patch("sys.argv", ["ccfddl", "--list-categories"]):
+ main()
+
+ printed = [str(call) for call in mock_print.call_args_list]
+ assert any("Available Categories" in str(p) for p in printed)
diff --git a/extensions/cli/ccfddl/tests/test_models.py b/extensions/cli/ccfddl/tests/test_models.py
new file mode 100644
index 000000000..b6382f4f6
--- /dev/null
+++ b/extensions/cli/ccfddl/tests/test_models.py
@@ -0,0 +1,175 @@
+import pytest
+
+from ccfddl.models import (
+ Rank,
+ Timeline,
+ ConferenceYear,
+ Conference,
+ Category,
+ CATEGORIES,
+ VALID_SUBS,
+ get_category_by_sub,
+ get_all_subs,
+ is_valid_sub,
+)
+
+
+class TestRank:
+ def test_from_dict_full(self):
+ data = {"ccf": "A", "core": "A*", "thcpl": "A"}
+ rank = Rank.from_dict(data)
+ assert rank.ccf == "A"
+ assert rank.core == "A*"
+ assert rank.thcpl == "A"
+
+ def test_from_dict_minimal(self):
+ data = {"ccf": "B"}
+ rank = Rank.from_dict(data)
+ assert rank.ccf == "B"
+ assert rank.core is None
+ assert rank.thcpl is None
+
+ def test_to_dict_full(self):
+ rank = Rank(ccf="A", core="A*", thcpl="A")
+ result = rank.to_dict()
+ assert result == {"ccf": "A", "core": "A*", "thcpl": "A"}
+
+ def test_to_dict_minimal(self):
+ rank = Rank(ccf="B")
+ result = rank.to_dict()
+ assert result == {"ccf": "B"}
+
+
+class TestTimeline:
+ def test_from_dict_full(self):
+ data = {"deadline": "2025-01-15 23:59:59", "abstract_deadline": "2025-01-08 23:59:59", "comment": "Main"}
+ timeline = Timeline.from_dict(data)
+ assert timeline.deadline == "2025-01-15 23:59:59"
+ assert timeline.abstract_deadline == "2025-01-08 23:59:59"
+ assert timeline.comment == "Main"
+
+ def test_from_dict_minimal(self):
+ data = {"deadline": "2025-01-15 23:59:59"}
+ timeline = Timeline.from_dict(data)
+ assert timeline.deadline == "2025-01-15 23:59:59"
+ assert timeline.abstract_deadline is None
+ assert timeline.comment is None
+
+ def test_to_dict(self):
+ timeline = Timeline(deadline="2025-01-15 23:59:59", comment="Test")
+ result = timeline.to_dict()
+ assert result["deadline"] == "2025-01-15 23:59:59"
+ assert result["comment"] == "Test"
+
+
+class TestConferenceYear:
+ def test_from_dict(self):
+ data = {
+ "year": 2025,
+ "id": "cvpr25",
+ "link": "https://example.com",
+ "timeline": [{"deadline": "2025-01-15 23:59:59"}],
+ "timezone": "UTC-8",
+ "date": "June 2025",
+ "place": "Seattle",
+ }
+ conf_year = ConferenceYear.from_dict(data)
+ assert conf_year.year == 2025
+ assert conf_year.id == "cvpr25"
+ assert len(conf_year.timeline) == 1
+
+ def test_to_dict(self):
+ conf_year = ConferenceYear(
+ year=2025,
+ id="cvpr25",
+ link="https://example.com",
+ timeline=[Timeline(deadline="2025-01-15 23:59:59")],
+ timezone="UTC-8",
+ date="June 2025",
+ place="Seattle",
+ )
+ result = conf_year.to_dict()
+ assert result["year"] == 2025
+ assert result["id"] == "cvpr25"
+
+
+class TestConference:
+ def test_from_dict(self):
+ data = {
+ "title": "CVPR",
+ "description": "Test Conference",
+ "sub": "AI",
+ "rank": {"ccf": "A"},
+ "dblp": "cvpr",
+ "confs": [
+ {
+ "year": 2025,
+ "id": "cvpr25",
+ "link": "https://example.com",
+ "timeline": [{"deadline": "2025-01-15 23:59:59"}],
+ "timezone": "UTC-8",
+ "date": "June 2025",
+ "place": "Seattle",
+ }
+ ],
+ }
+ conf = Conference.from_dict(data)
+ assert conf.title == "CVPR"
+ assert conf.sub == "AI"
+ assert conf.rank.ccf == "A"
+ assert len(conf.confs) == 1
+
+ def test_to_dict(self):
+ conf = Conference(
+ title="CVPR",
+ description="Test",
+ sub="AI",
+ rank=Rank(ccf="A"),
+ dblp="cvpr",
+ confs=[],
+ )
+ result = conf.to_dict()
+ assert result["title"] == "CVPR"
+ assert result["rank"]["ccf"] == "A"
+
+
+class TestCategory:
+ def test_from_dict(self):
+ data = {"name": "人工智能", "name_en": "Artificial Intelligence", "sub": "AI"}
+ cat = Category.from_dict(data)
+ assert cat.name == "人工智能"
+ assert cat.name_en == "Artificial Intelligence"
+ assert cat.sub == "AI"
+
+ def test_to_dict(self):
+ cat = Category(name="人工智能", name_en="Artificial Intelligence", sub="AI")
+ result = cat.to_dict()
+ assert result == {"name": "人工智能", "name_en": "Artificial Intelligence", "sub": "AI"}
+
+
+class TestCategoriesConstants:
+ def test_categories_count(self):
+ assert len(CATEGORIES) == 10
+
+ def test_valid_subs(self):
+ assert "AI" in VALID_SUBS
+ assert "DB" in VALID_SUBS
+ assert "INVALID" not in VALID_SUBS
+
+ def test_get_category_by_sub(self):
+ cat = get_category_by_sub("AI")
+ assert cat is not None
+ assert cat.name_en == "Artificial Intelligence"
+
+ def test_get_category_by_sub_invalid(self):
+ cat = get_category_by_sub("INVALID")
+ assert cat is None
+
+ def test_get_all_subs(self):
+ subs = get_all_subs()
+ assert len(subs) == 10
+ assert "AI" in subs
+
+ def test_is_valid_sub(self):
+ assert is_valid_sub("AI") is True
+ assert is_valid_sub("INVALID") is False
diff --git a/extensions/cli/ccfddl/tests/test_utils.py b/extensions/cli/ccfddl/tests/test_utils.py
new file mode 100644
index 000000000..cf080a4d1
--- /dev/null
+++ b/extensions/cli/ccfddl/tests/test_utils.py
@@ -0,0 +1,109 @@
+import pytest
+from datetime import datetime, timedelta, timezone
+
+from ccfddl.utils import get_timezone, load_mapping, reverse_index
+
+
+class TestGetTimezone:
+ def test_aoe(self):
+ tz = get_timezone("AoE")
+ expected = timezone(timedelta(hours=-12))
+ assert tz == expected
+
+ def test_utc(self):
+ tz = get_timezone("UTC")
+ assert tz == timezone.utc
+
+ def test_utc_positive(self):
+ tz = get_timezone("UTC+8")
+ expected = timezone(timedelta(hours=8))
+ assert tz == expected
+
+ def test_utc_negative(self):
+ tz = get_timezone("UTC-5")
+ expected = timezone(timedelta(hours=-5))
+ assert tz == expected
+
+ def test_utc_plus_zero(self):
+ tz = get_timezone("UTC+0")
+ expected = timezone(timedelta(hours=0))
+ assert tz == expected
+
+ def test_invalid_format(self):
+ with pytest.raises(ValueError, match="Invalid timezone format"):
+ get_timezone("INVALID")
+
+ def test_invalid_format_no_sign(self):
+ with pytest.raises(ValueError, match="Invalid timezone format"):
+ get_timezone("UTC8")
+
+
+class TestLoadMapping:
+ def test_load_mapping_file_not_found(self, tmp_path):
+ non_existent = tmp_path / "non_existent.yml"
+ with pytest.raises(FileNotFoundError):
+ load_mapping(str(non_existent))
+
+
+class TestReverseIndex:
+ @pytest.fixture
+ def sample_yaml_files(self, tmp_path):
+ conf1 = tmp_path / "conf1.yml"
+ conf1.write_text("""
+- title: CVPR
+ sub: AI
+ rank:
+ ccf: A
+ core: A*
+ thcpl: A
+ dblp: cvpr
+ confs:
+ - year: 2025
+ id: cvpr25
+ link: https://cvpr2025.org
+ timeline:
+ - deadline: '2025-01-15 23:59:59'
+ timezone: UTC-8
+ date: June 2025
+ place: Seattle, USA
+""")
+ conf2 = tmp_path / "conf2.yml"
+ conf2.write_text("""
+- title: ICML
+ sub: AI
+ rank:
+ ccf: A
+ core: A*
+ thcpl: N
+ dblp: icml
+ confs:
+ - year: 2025
+ id: icml25
+ link: https://icml2025.org
+ timeline:
+ - deadline: '2025-02-01 23:59:59'
+ timezone: UTC-8
+ date: July 2025
+ place: Vienna, Austria
+""")
+ return [str(conf1), str(conf2)]
+
+ def test_reverse_index_basic(self, sample_yaml_files):
+ index = reverse_index(sample_yaml_files, ["AI"])
+
+ assert "AI" in index
+ assert len(index["AI"]) == 2
+
+ assert "ccf_A" in index
+ assert len(index["ccf_A"]) == 2
+
+ assert "ccf_A_AI" in index
+
+ assert "core_A*" in index
+ assert "thcpl_A" in index
+
+ def test_reverse_index_empty_files(self, tmp_path):
+ empty_yaml = tmp_path / "empty.yml"
+ empty_yaml.write_text("[]")
+ index = reverse_index([str(empty_yaml)], ["AI"])
+ assert index == {}
diff --git a/extensions/cli/ccfddl/utils.py b/extensions/cli/ccfddl/utils.py
new file mode 100644
index 000000000..927cadef2
--- /dev/null
+++ b/extensions/cli/ccfddl/utils.py
@@ -0,0 +1,156 @@
+"""Utility functions for CCFDDL.
+
+This module provides common utilities for timezone handling, YAML loading,
+and conference data processing.
+"""
+
+import re
+from collections import defaultdict
+from datetime import datetime, timedelta, timezone
+from itertools import combinations
+
+import yaml
+
+
+def load_mapping(path: str = "conference/types.yml") -> dict[str, str]:
+ """Load sub-category name mapping from YAML file.
+
+ Args:
+ path: Path to the types.yml file
+
+ Returns:
+ Dictionary mapping sub codes to Chinese names
+ """
+ with open(path, encoding="utf-8") as f:
+ types = yaml.safe_load(f)
+ if types is None:
+ return {}
+ sub_mapping: dict[str, str] = {}
+ for types_data in types:
+ sub_mapping[types_data["sub"]] = types_data["name"]
+ return sub_mapping
+
+
+def get_timezone(tz_str: str) -> timezone:
+ """Convert timezone string to datetime.timezone object.
+
+ Supported formats:
+ - 'AoE' (Anywhere on Earth, UTC-12)
+ - 'UTC' (UTC+0)
+ - 'UTC+8', 'UTC-5' (UTC with offset)
+
+ Args:
+ tz_str: Timezone string
+
+ Returns:
+ A timezone object
+
+ Raises:
+ ValueError: If the timezone format is invalid
+ """
+ if tz_str == "AoE":
+ return timezone(timedelta(hours=-12))
+ if tz_str == "UTC":
+ return timezone.utc
+ match = re.match(r"UTC([+-])(\d{1,2})$", tz_str)
+ if not match:
+ raise ValueError(f"Invalid timezone format: {tz_str}")
+ sign, hours = match.groups()
+ offset = int(hours) if sign == "+" else -int(hours)
+ return timezone(timedelta(hours=offset))
+
+
+def parse_datetime_with_tz(
+ dt_str: str, tz_str: str, format_str: str = "%Y-%m-%d %H:%M:%S"
+) -> datetime:
+ """Parse datetime string with timezone.
+
+ Args:
+ dt_str: Datetime string (e.g., '2025-01-15 23:59:59')
+ tz_str: Timezone string (e.g., 'UTC-8', 'AoE')
+ format_str: Datetime format string
+
+ Returns:
+ Timezone-aware datetime object
+
+ Raises:
+ ValueError: If datetime or timezone format is invalid
+ """
+ tz = get_timezone(tz_str)
+ dt = datetime.strptime(dt_str, format_str)
+ return dt.replace(tzinfo=tz)
+
+
+def format_duration(ddl_time: datetime, now: datetime) -> str:
+ """Format the remaining duration until deadline.
+
+ Args:
+ ddl_time: Deadline datetime (timezone-aware)
+ now: Current datetime (timezone-aware)
+
+ Returns:
+ Formatted duration string
+ """
+ duration = ddl_time - now
+ months, days = duration.days // 30, duration.days
+ hours, remainder = divmod(duration.seconds, 3600)
+ minutes, seconds = divmod(remainder, 60)
+
+ day_word_str = "days" if days > 1 else "day"
+ months_str, days_str = str(months).zfill(2), str(days).zfill(2)
+ hours_str, minutes_str = str(hours).zfill(2), str(minutes).zfill(2)
+
+ if days < 1:
+ return f"{hours_str}:{minutes_str}:{seconds:02d}"
+ if days < 30:
+ return f"{days_str} {day_word_str}, {hours_str}:{minutes_str}"
+ if days < 100:
+ return f"{days_str} {day_word_str}"
+ return f"{months_str} months"
+
+
+def reverse_index(file_paths: list[str], subs: list[str]) -> dict[str, list[str]]:
+ """Build reverse index of conferences by category and rank.
+
+ Args:
+ file_paths: List of YAML file paths to process
+ subs: List of valid sub codes
+
+ Returns:
+ Dictionary mapping category/rank keys to file paths
+ """
+ index: dict[str, set[str]] = defaultdict(set)
+
+ for file_path in file_paths:
+ with open(file_path, "r", encoding="utf-8") as f:
+ conferences = yaml.safe_load(f)
+
+ if conferences is None:
+ continue
+
+ for conf_data in conferences:
+ sub = conf_data["sub"]
+ rank = conf_data["rank"]
+ ccf_rank = rank.get("ccf", "N")
+ core_rank = rank.get("core", "N")
+ thcpl_rank = rank.get("thcpl", "N")
+ rank_keys = [
+ f"ccf_{ccf_rank}",
+ f"core_{core_rank}",
+ f"thcpl_{thcpl_rank}",
+ ]
+
+ _add_index_entry(index, sub, file_path)
+
+ for size in range(1, len(rank_keys) + 1):
+ for combo in combinations(rank_keys, size):
+ key = "_".join(combo)
+ _add_index_entry(index, key, file_path)
+ _add_index_entry(index, f"{key}_{sub}", file_path)
+
+ return {key: sorted(paths) for key, paths in index.items()}
+
+
+def _add_index_entry(index: dict[str, set[str]], key: str, file_path: str) -> None:
+ """Add entry to reverse index."""
+ index[key].add(file_path)
diff --git a/extensions/cli/pyproject.toml b/extensions/cli/pyproject.toml
new file mode 100644
index 000000000..7e4bc5755
--- /dev/null
+++ b/extensions/cli/pyproject.toml
@@ -0,0 +1,51 @@
+[build-system]
+requires = ["setuptools>=61.0"]
+build-backend = "setuptools.build_meta"
+
+[project]
+name = "ccfddl"
+version = "0.2.0"
+description = "CLI tool for CCFDDL - Conference Deadline Tracker"
+readme = "readme.md"
+license = {text = "MIT"}
+requires-python = ">=3.10"
+authors = [
+ {name = "0x4f5da2", email = "me@4f5da2.com"}
+]
+dependencies = [
+ "tabulate",
+ "pyyaml",
+ "requests",
+ "termcolor",
+ "icalendar",
+ "xlin",
+]
+
+[project.optional-dependencies]
+dev = [
+ "mypy",
+ "pytest>=7.0",
+ "pytest-cov",
+]
+
+[project.scripts]
+ccfddl = "ccfddl.__main__:main"
+
+[tool.setuptools.packages.find]
+where = ["."]
+
+[tool.pytest.ini_options]
+testpaths = ["ccfddl/tests"]
+python_files = ["test_*.py"]
+python_functions = ["test_*"]
+addopts = "-v --tb=short"
+
+[tool.mypy]
+python_version = "3.10"
+warn_return_any = true
+warn_unused_ignores = true
+disallow_untyped_defs = true
+
+[[tool.mypy.overrides]]
+module = ["icalendar.*", "xlin.*", "termcolor.*"]
+ignore_missing_imports = true
diff --git a/extensions/cli/readme.md b/extensions/cli/readme.md
index 579296cfa..ae3e5fa6e 100755
--- a/extensions/cli/readme.md
+++ b/extensions/cli/readme.md
@@ -1,22 +1,108 @@
# ccfddl cli
-WIP
+CLI tool for CCFDDL - Conference Deadline Tracker
-## install
+## Install
```bash
-pip install -r req.txt
-python setup.py install
+pip install -e ".[dev]"
```
-## usage
+## Usage
```bash
-python -m ccfddl
+# Show help
+ccfddl --help
+
+# List all categories
+ccfddl --list-categories
+
+# Filter by conference, subcategory, rank
+ccfddl --conf CVPR ICCV --sub AI --rank A
+
+# JSON output
+ccfddl --json --sub AI
+
+# Show version
+ccfddl --version
```
+### Arguments
+
| Argument | Type | Description | Example |
-| -------- | ----- | ------------------------------------ | ------------------ |
+| -------- | ----- | -------------------------------- ----| ------------------ |
| `--conf` | str[] | A list of conference IDs to filter. | `--conf CVPR ICCV` |
-| `--sub` | str[] | A list of subcategory IDs to filter. | `--sub AI ML` |
+| `--sub` | str[] | A list of subcategory IDs to filter. | `--sub AI CG` |
| `--rank` | str[] | A list of ranks to filter. | `--rank A B` |
+| `--json` | flag | Output in JSON format. | `--json` |
+| `--list-categories` | flag | List all categories. | `--list-categories`|
+| `--url` | str | Custom URL for conference data. | `--url https://...`|
+| `--version` | flag | Show version. | `--version` |
+
+## Generate iCal/RSS Feeds
+
+```bash
+# Generate iCal files (requires xlin package)
+python -m ccfddl.convert_to_ical
+
+# Generate RSS files
+python -m ccfddl.convert_to_rss
+```
+
+## Project Structure
+
+```
+ccfddl/
+├── __init__.py # Package entry, exports public API
+├── __main__.py # CLI entry point
+├── fetch.py # Data fetching and processing
+├── output.py # Output formatting (table, JSON)
+├── models.py # Data models
+├── utils.py # Utility functions
+├── convert_to_ical.py
+├── convert_to_rss.py
+└── tests/ # Test suite
+```
+
+## Development
+
+```bash
+# Install dev dependencies
+pip install -e ".[dev]"
+
+# Run tests
+python -m pytest ccfddl/tests/ -v
+
+# Run tests with coverage
+python -m pytest ccfddl/tests/ --cov=ccfddl --cov-report=html
+
+# Type checking
+mypy ccfddl/
+```
+
+## Python API
+
+```python
+from ccfddl import (
+ # Models
+ Conference, ConferenceYear, Timeline, Rank, Category,
+ CATEGORIES, VALID_SUBS,
+ get_category_by_sub, get_all_subs, is_valid_sub,
+ # Utils
+ load_mapping, get_timezone, reverse_index,
+ format_duration, parse_datetime_with_tz,
+ # Fetch & Output
+ fetch_conferences, process_conference_deadlines, filter_results,
+ output_table, output_json, list_categories,
+)
+
+# Get category info
+cat = get_category_by_sub("AI")
+print(cat.name) # 人工智能
+print(cat.name_en) # Artificial Intelligence
+
+# Parse timezone
+from datetime import datetime
+tz = get_timezone("UTC+8")
+dt = datetime(2025, 1, 15, 23, 59, 59, tzinfo=tz)
+```
diff --git a/extensions/cli/req.txt b/extensions/cli/req.txt
deleted file mode 100644
index b1a4bdcbc..000000000
--- a/extensions/cli/req.txt
+++ /dev/null
@@ -1,5 +0,0 @@
-tabulate
-yaml
-pyyaml
-requests
-termcolor
diff --git a/extensions/cli/setup.py b/extensions/cli/setup.py
deleted file mode 100755
index 1d2b2c6f8..000000000
--- a/extensions/cli/setup.py
+++ /dev/null
@@ -1,12 +0,0 @@
-
-from setuptools import setup, find_packages
-
-setup(
- name='ccfddl',
- version='0.1',
- packages=find_packages(),
- license='MIT',
- description='ccfddl cli',
- author='0x4f5da2',
- author_email='me@4f5da2.com'
-)