diff --git a/1- Databricks Lakehouse Platform/1.0 - Creating Clusters.py b/1- Databricks Lakehouse Platform/1.0 - Creating Clusters.py
new file mode 100644
index 0000000..210da5a
--- /dev/null
+++ b/1- Databricks Lakehouse Platform/1.0 - Creating Clusters.py
@@ -0,0 +1,75 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC ## Creating Clusters
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Creating a Demo Cluster
+# MAGIC
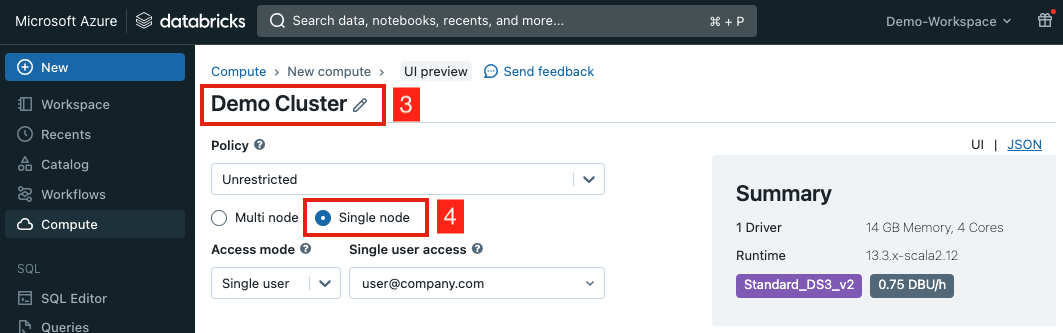
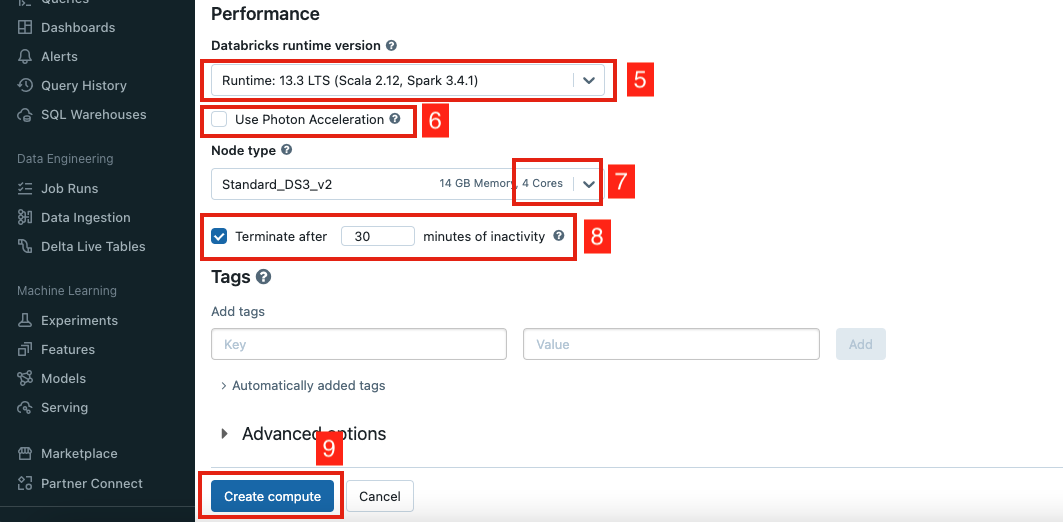
+# MAGIC Create a cluster with the following configurations:
+# MAGIC
+# MAGIC | Setting | Instructions |
+# MAGIC |--|--|
+# MAGIC |Cluster name|**Demo Cluster**|
+# MAGIC |Cluster mode|**Signle node**|
+# MAGIC |Runtime version|Select the Databricks runtime version 13.3 LTS|
+# MAGIC |Photon Acceleration| Uncheck the option |
+# MAGIC |Node type|4 cores|
+# MAGIC |Auto termination|30 minutes|
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %md
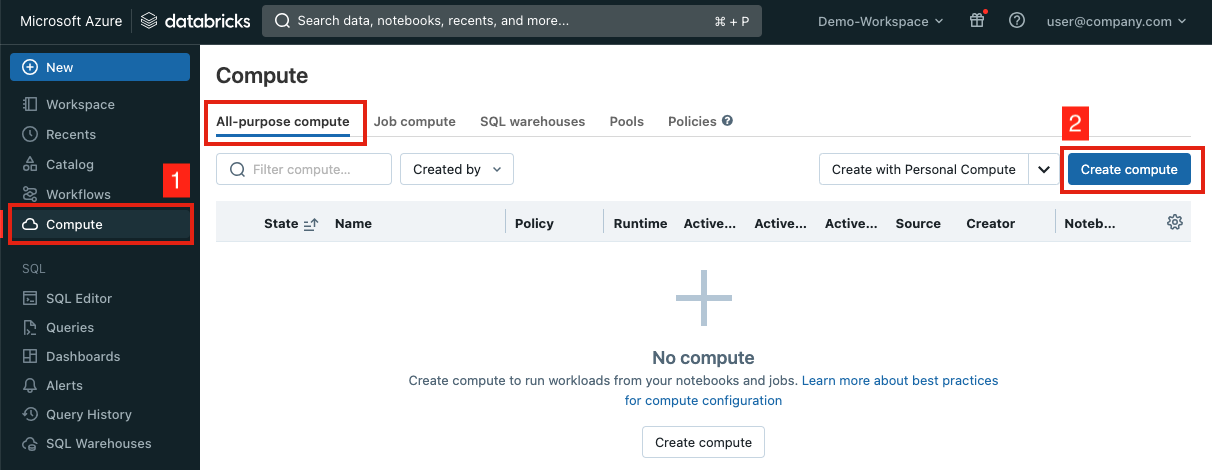
+# MAGIC 1- Navigate to the **Compute** tab in the left side bar.
+# MAGIC
+# MAGIC 2- Under **All-purpose compute** tab, click **Create compute**.
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
--- MAGIC

+-- MAGIC
-- MAGIC
--- MAGIC
+-- MAGIC
-- MAGIC
--- MAGIC
+-- MAGIC
-- MAGIC
--- MAGIC
+-- MAGIC
-- MAGIC
-# MAGIC
+# MAGIC
# MAGIC
-# MAGIC
+# MAGIC
# MAGIC
-# MAGIC
+# MAGIC
# MAGIC
--- MAGIC
+-- MAGIC
-- MAGIC
+# MAGIC

+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+-- MAGIC
+-- MAGIC
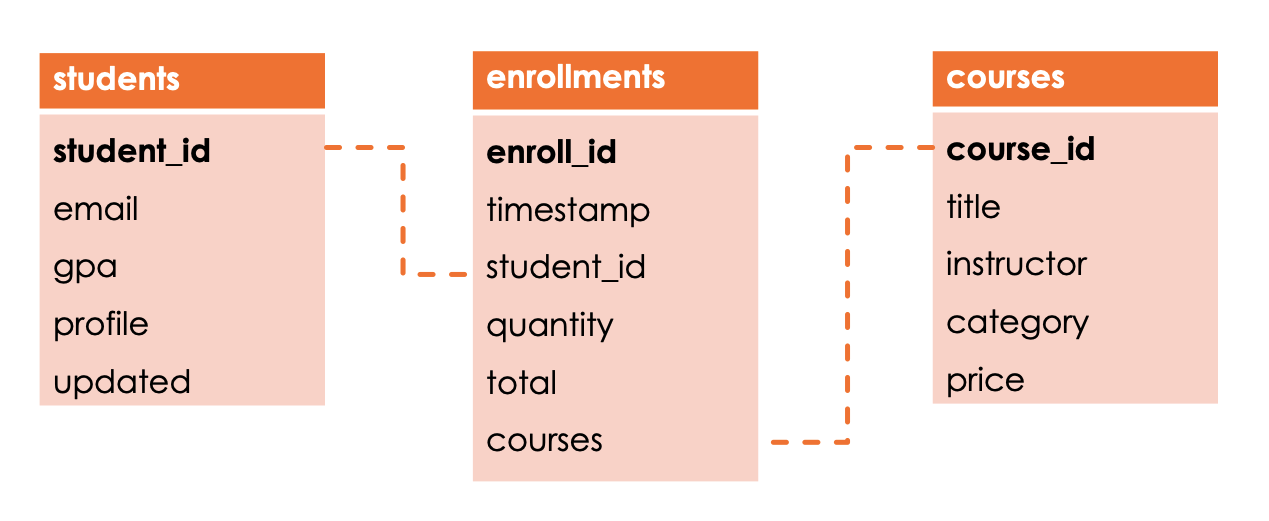
- Key: **datasets.path**
- Value: **dbfs:/mnt/DE-Associate/datasets/school** |
+-- MAGIC | Channel | Choose **Current**|
+-- MAGIC
+-- MAGIC Finally, click **Create**.
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ### Q5 - Run your Pipeline
+-- MAGIC
+-- MAGIC Select **Development** mode and Click **Start** to begin the update to your pipeline's tables
diff --git a/Labs/4- Production Pipelines/4.2L - Jobs - Land New Data.py b/Labs/4- Production Pipelines/4.2L - Jobs - Land New Data.py
new file mode 100644
index 0000000..e5f60c9
--- /dev/null
+++ b/Labs/4- Production Pipelines/4.2L - Jobs - Land New Data.py
@@ -0,0 +1,91 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC ## Lab: Creating a multi-task job
+# MAGIC
+# MAGIC In this lab, we will create a job that has 2 tasks:
+# MAGIC 1. The current notebook that lands a new batch of data in the lab dataset directory
+# MAGIC 1. The Delta Live Table pipeline created in the previous lab to processes this data
+# MAGIC
+# MAGIC * Help: Databricks Jobs documentation.
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC
+# MAGIC

+# MAGIC
+# MAGIC
+# MAGIC 1. Set the job name in the top-left of the screen to **School Job**
+# MAGIC 1. Configure the first task as specified below:
+# MAGIC | Setting | Value |
+# MAGIC |--|--|
+# MAGIC | Task name | Enter **Land New Data** |
+# MAGIC | Type | Choose **Notebook** |
+# MAGIC | Source | Choose **Workspace** |
+# MAGIC | Path | Use the navigator to choose the current notebook (4.2L - Jobs - Land New Data) |
+# MAGIC | Cluster | Select your cluster from the dropdown, under **Existing All Purpose Clusters** |
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC 3. Click the **Create** button
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Q2- Configuring Task 2 - DLT pipeline
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC 1. Click the add button (**+**) to add a new **Delta Live Tables pipeline** task
+# MAGIC 1. Configure the task:
+# MAGIC
+# MAGIC | Setting | Value |
+# MAGIC |--|--|
+# MAGIC | Task name | Enter **DLT pipeline** |
+# MAGIC | Type | Choose **Delta Live Tables pipeline** |
+# MAGIC | Pipeline | Choose the DLT pipeline created in the previous lab |
+# MAGIC | Depends on | Choose **Land New Data**, which is the previous task we defined above |
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC 3. Click the **Create task** button
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Q3- Run the job
+# MAGIC
+# MAGIC Click the **Run now** button in the top right to run this job. From the **Runs** tab, check your job run
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Q4- Review the finished job
+# MAGIC
+# MAGIC Once all tasks completed successfully, review the contents of each task to verify its result
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC > **Note**: The below cells are to be run as part of the **Task 1** to land new batch of data in the dataset directory
+
+# COMMAND ----------
+
+# MAGIC %run ../Includes/Setup-Lab
+
+# COMMAND ----------
+
+load_new_json_data()
diff --git a/Labs/4- Production Pipelines/4.3L - Databricks SQL.sql b/Labs/4- Production Pipelines/4.3L - Databricks SQL.sql
new file mode 100644
index 0000000..6a878b5
--- /dev/null
+++ b/Labs/4- Production Pipelines/4.3L - Databricks SQL.sql
@@ -0,0 +1,121 @@
+-- Databricks notebook source
+-- MAGIC %md
+-- MAGIC
+-- MAGIC ## Lab: Design a Dashboard with DBSQL
+-- MAGIC
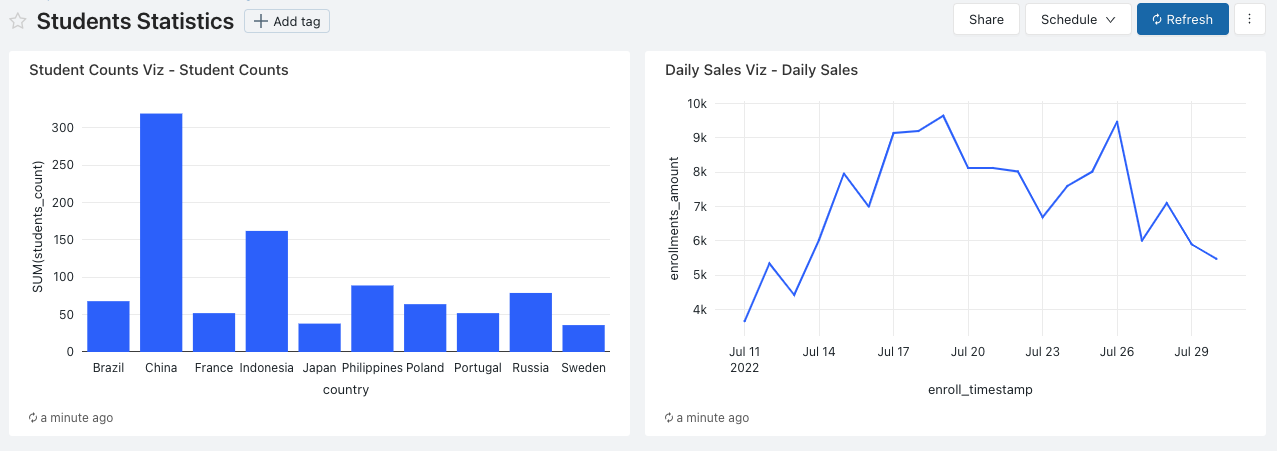
+-- MAGIC In this lab, we will design a dashboard in DBSQL that has 2 graphs:
+-- MAGIC 1. Bar graph that shows the number of students per country
+-- MAGIC 1. Line graph that shows the daily enrollments amount
+-- MAGIC
+-- MAGIC * Help: Databricks SQL documentation.
+
+-- COMMAND ----------
+
+-- MAGIC %md-sandbox
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC 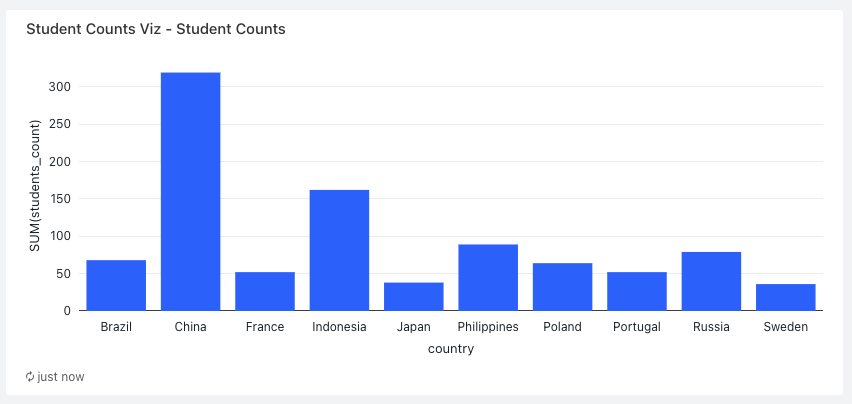 +-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC Steps:
+-- MAGIC 1. Click the Add butoon (**+**) next to the results tab, and select **Visualization** from the dialog box
+-- MAGIC 1. Select **`Bar`** for the **Visualization Type**
+-- MAGIC 1. Set **`country`** for the **X Column**
+-- MAGIC 1. Under **Y columns** click **Add column**, and set it to **`students_count`**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. Finally, set the title of the graph to **Student Counts Viz**
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q3 - Creating a New Dashboard
+-- MAGIC
+-- MAGIC Add the above graph to a new dashboard named **Students Statistics**
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click the three vertical dots button at the top of the graph and select **Add to Dashboard**.
+-- MAGIC 1. Click the **Create new dashboard** option
+-- MAGIC 1. Name your dashboard **Students Statistics**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. With the new dashboard selected as the target, click **OK** to add your visualization
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q4 - Creating a Line Plot Visualization
+-- MAGIC
+-- MAGIC 1. Run the the below query in a new query tab in the **SQL Editor**, and then save it with the name **Daily Sales**
+
+-- COMMAND ----------
+
+SELECT cast(from_unixtime(enroll_timestamp, 'yyyy-MM-dd HH:mm:ss') AS date) enroll_timestamp,
+ sum(total) AS enrollments_amount
+FROM hive_metastore.de_associate_school.enrollments n
+INNER JOIN hive_metastore.de_associate_school.students s ON s.student_id = n.student_id
+GROUP BY enroll_timestamp
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC
+-- MAGIC 2. Create a Line Plot Visualization that shows the daily enrollments amount
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC Steps:
+-- MAGIC 1. Click the Add butoon (**+**) next to the results tab, and select **Visualization** from the dialog box
+-- MAGIC 1. Select **`Bar`** for the **Visualization Type**
+-- MAGIC 1. Set **`country`** for the **X Column**
+-- MAGIC 1. Under **Y columns** click **Add column**, and set it to **`students_count`**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. Finally, set the title of the graph to **Student Counts Viz**
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q3 - Creating a New Dashboard
+-- MAGIC
+-- MAGIC Add the above graph to a new dashboard named **Students Statistics**
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click the three vertical dots button at the top of the graph and select **Add to Dashboard**.
+-- MAGIC 1. Click the **Create new dashboard** option
+-- MAGIC 1. Name your dashboard **Students Statistics**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. With the new dashboard selected as the target, click **OK** to add your visualization
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q4 - Creating a Line Plot Visualization
+-- MAGIC
+-- MAGIC 1. Run the the below query in a new query tab in the **SQL Editor**, and then save it with the name **Daily Sales**
+
+-- COMMAND ----------
+
+SELECT cast(from_unixtime(enroll_timestamp, 'yyyy-MM-dd HH:mm:ss') AS date) enroll_timestamp,
+ sum(total) AS enrollments_amount
+FROM hive_metastore.de_associate_school.enrollments n
+INNER JOIN hive_metastore.de_associate_school.students s ON s.student_id = n.student_id
+GROUP BY enroll_timestamp
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC
+-- MAGIC 2. Create a Line Plot Visualization that shows the daily enrollments amount
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC 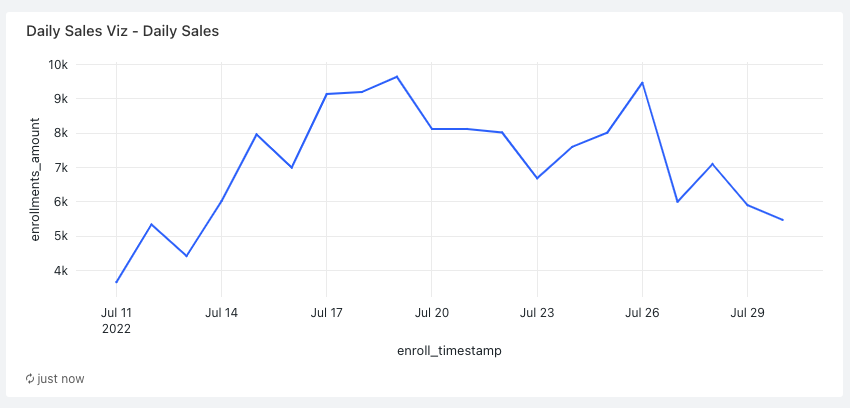 +-- MAGIC
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click the **Add Visualization** button
+-- MAGIC 1. Select **`Line`** for the **Visualization Type**
+-- MAGIC 1. Set **`enroll_timestamp`** for the **X Column**
+-- MAGIC 1. Under **Y columns** click **Add column**, and set it to **`enrollments_amount`**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. Finally, set the title of the graph to **Daily Sales Viz**
+-- MAGIC 1. Click the three vertical dots button at the top of the graph and select **Add to Dashboard**.
+-- MAGIC 1. Select the dashboard **Students Statistics** created above
+-- MAGIC 1. Click **OK** to add your visualization
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q5 - Review your Dashboard
+-- MAGIC
+-- MAGIC Open your Dashboard and refresh its underlaying data
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click on the **Dashboards** button on left side bar
+-- MAGIC 1. Find the dashboard **Students Statistics** created earlier. Click to open it
+-- MAGIC 1. Click the **Refresh** button to update your dashboard
diff --git a/Labs/Includes/Setup-Lab.py b/Labs/Includes/Setup-Lab.py
new file mode 100644
index 0000000..ac61e86
--- /dev/null
+++ b/Labs/Includes/Setup-Lab.py
@@ -0,0 +1,137 @@
+# Databricks notebook source
+data_source_uri = "s3://dalhussein-courses/datasets/school/v1/"
+dataset_school = 'dbfs:/mnt/DE-Associate/datasets/school'
+checkpoint_path = 'dbfs:/mnt/DE-Associate/checkpoints/school'
+dlt_path = 'dbfs:/mnt/DE-Associate/dlt/school'
+db_name = 'DE_Associate_School'
+dlt_db_name = 'DE_Associate_School_DLT'
+spark.conf.set(f"dataset.school", dataset_school)
+
+# COMMAND ----------
+
+def clean_up():
+ print("Removing Checkpoints ...")
+ dbutils.fs.rm(checkpoint_path, True)
+ print("Removing DLT storage location ...")
+ dbutils.fs.rm(dlt_path, True)
+ print("Dropping Database ...")
+ spark.sql(f"DROP SCHEMA IF EXISTS {db_name} CASCADE")
+ print("Dropping DLT database ...")
+ spark.sql(f"DROP SCHEMA IF EXISTS {dlt_db_name} CASCADE")
+ print("Removing Dataset ...")
+ dbutils.fs.rm(dataset_school, True)
+ print("Done")
+
+# COMMAND ----------
+
+try:
+ clean = int(dbutils.widgets.get("clean"))
+except:
+ clean = 0
+
+if clean:
+ clean_up()
+
+# COMMAND ----------
+
+def path_exists(path):
+ try:
+ dbutils.fs.ls(path)
+ return True
+ except Exception as e:
+ msg = str(e)
+ if ("com.databricks.sql.io.CloudFileNotFoundException" in msg
+ or "java.io.FileNotFoundException" in msg):
+ return False
+ else:
+ raise
+
+# COMMAND ----------
+
+def download_dataset(source, target):
+ files = dbutils.fs.ls(source)
+
+ for f in files:
+ source_path = f"{source}/{f.name}"
+ target_path = f"{target}/{f.name}"
+ if not path_exists(target_path):
+ print(f"Copying {f.name} ...")
+ dbutils.fs.cp(source_path, target_path, True)
+
+# COMMAND ----------
+
+def get_index(dir):
+ files = dbutils.fs.ls(dir)
+ index = 0
+ if files:
+ file = max(files).name
+ index = int(file.rsplit('.', maxsplit=1)[0])
+ return index+1
+
+# COMMAND ----------
+
+def set_current_schema(schema_name, catalog_name='hive_metastore'):
+ spark.sql(f"USE CATALOG {catalog_name}")
+ spark.sql(f"CREATE SCHEMA IF NOT EXISTS {schema_name}")
+ spark.sql(f"USE {schema_name}")
+ print(f"Schema for the hands-on labs: {catalog_name}.{schema_name}")
+
+# COMMAND ----------
+
+# Structured Streaming
+streaming_dir = f"{dataset_school}/enrollments-streaming"
+raw_dir = f"{dataset_school}/enrollments-raw"
+
+def load_file(current_index):
+ latest_file = f"{str(current_index).zfill(2)}.parquet"
+ print(f"Loading {latest_file} file to the school dataset")
+ dbutils.fs.cp(f"{streaming_dir}/{latest_file}", f"{raw_dir}/{latest_file}")
+
+
+def load_new_data(all=False):
+ index = get_index(raw_dir)
+ if index >= 10:
+ print("No more data to load\n")
+
+ elif all == True:
+ while index <= 10:
+ load_file(index)
+ index += 1
+ else:
+ load_file(index)
+ index += 1
+
+# COMMAND ----------
+
+# DLT
+streaming_enrollments_dir = f"{dataset_school}/enrollments-json-streaming"
+streaming_courses_dir = f"{dataset_school}/courses-streaming"
+
+raw_enrollments_dir = f"{dataset_school}/enrollments-json-raw"
+raw_courses_dir = f"{dataset_school}/courses-cdc"
+
+def load_json_file(current_index):
+ latest_file = f"{str(current_index).zfill(2)}.json"
+ print(f"Loading {latest_file} enrollments file to the school dataset")
+ dbutils.fs.cp(f"{streaming_enrollments_dir}/{latest_file}", f"{raw_enrollments_dir}/{latest_file}")
+ #print(f"Loading {latest_file} courses file to the school dataset")
+ #dbutils.fs.cp(f"{streaming_courses_dir}/{latest_file}", f"{raw_courses_dir}/{latest_file}")
+
+
+def load_new_json_data(all=False):
+ index = get_index(raw_enrollments_dir)
+ if index >= 10:
+ print("No more data to load\n")
+
+ elif all == True:
+ while index <= 10:
+ load_json_file(index)
+ index += 1
+ else:
+ load_json_file(index)
+ index += 1
+
+# COMMAND ----------
+
+download_dataset(data_source_uri, dataset_school)
+set_current_schema(db_name)
diff --git a/Labs/Includes/images/bar_graph.png b/Labs/Includes/images/bar_graph.png
new file mode 100644
index 0000000..013c7c2
Binary files /dev/null and b/Labs/Includes/images/bar_graph.png differ
diff --git a/Labs/Includes/images/cluster_par1.png b/Labs/Includes/images/cluster_par1.png
new file mode 100644
index 0000000..801f94e
Binary files /dev/null and b/Labs/Includes/images/cluster_par1.png differ
diff --git a/Labs/Includes/images/cluster_par2.png b/Labs/Includes/images/cluster_par2.png
new file mode 100644
index 0000000..5a10f40
Binary files /dev/null and b/Labs/Includes/images/cluster_par2.png differ
diff --git a/Labs/Includes/images/cluster_par3.png b/Labs/Includes/images/cluster_par3.png
new file mode 100644
index 0000000..bf77236
Binary files /dev/null and b/Labs/Includes/images/cluster_par3.png differ
diff --git a/Labs/Includes/images/dashboard.png b/Labs/Includes/images/dashboard.png
new file mode 100644
index 0000000..e8a8d2c
Binary files /dev/null and b/Labs/Includes/images/dashboard.png differ
diff --git a/Labs/Includes/images/line_graph.png b/Labs/Includes/images/line_graph.png
new file mode 100644
index 0000000..901d4f9
Binary files /dev/null and b/Labs/Includes/images/line_graph.png differ
diff --git a/Labs/Includes/images/markdown.png b/Labs/Includes/images/markdown.png
new file mode 100644
index 0000000..0c93afa
Binary files /dev/null and b/Labs/Includes/images/markdown.png differ
diff --git a/Labs/Includes/images/school_job.png b/Labs/Includes/images/school_job.png
new file mode 100644
index 0000000..66179b2
Binary files /dev/null and b/Labs/Includes/images/school_job.png differ
diff --git a/Labs/Includes/images/school_schema.png b/Labs/Includes/images/school_schema.png
new file mode 100644
index 0000000..2945a2f
Binary files /dev/null and b/Labs/Includes/images/school_schema.png differ
diff --git a/Labs/Solutions/1- Databricks Lakehouse Platform/1.0L Solution - Creating Clusters.py b/Labs/Solutions/1- Databricks Lakehouse Platform/1.0L Solution - Creating Clusters.py
new file mode 100644
index 0000000..ebcb29f
--- /dev/null
+++ b/Labs/Solutions/1- Databricks Lakehouse Platform/1.0L Solution - Creating Clusters.py
@@ -0,0 +1,75 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC ## Lab: Creating Clusters
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Q1 - Creating a Demo Cluster
+# MAGIC
+# MAGIC Create a cluster with the following configurations:
+# MAGIC
+# MAGIC | Setting | Instructions |
+# MAGIC |--|--|
+# MAGIC |Cluster name|**Demo Cluster**|
+# MAGIC |Cluster mode|**Signle node**|
+# MAGIC |Runtime version|Select the Databricks runtime version 13.3 LTS|
+# MAGIC |Photon Acceleration| Uncheck the option |
+# MAGIC |Node type|4 cores|
+# MAGIC |Auto termination|30 minutes|
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC 1- Navigate to the **Compute** tab in the left side bar.
+# MAGIC
+# MAGIC 2- Under **All-purpose compute** tab, click **Create compute**.
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click the **Add Visualization** button
+-- MAGIC 1. Select **`Line`** for the **Visualization Type**
+-- MAGIC 1. Set **`enroll_timestamp`** for the **X Column**
+-- MAGIC 1. Under **Y columns** click **Add column**, and set it to **`enrollments_amount`**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. Finally, set the title of the graph to **Daily Sales Viz**
+-- MAGIC 1. Click the three vertical dots button at the top of the graph and select **Add to Dashboard**.
+-- MAGIC 1. Select the dashboard **Students Statistics** created above
+-- MAGIC 1. Click **OK** to add your visualization
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q5 - Review your Dashboard
+-- MAGIC
+-- MAGIC Open your Dashboard and refresh its underlaying data
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click on the **Dashboards** button on left side bar
+-- MAGIC 1. Find the dashboard **Students Statistics** created earlier. Click to open it
+-- MAGIC 1. Click the **Refresh** button to update your dashboard
diff --git a/Labs/Includes/Setup-Lab.py b/Labs/Includes/Setup-Lab.py
new file mode 100644
index 0000000..ac61e86
--- /dev/null
+++ b/Labs/Includes/Setup-Lab.py
@@ -0,0 +1,137 @@
+# Databricks notebook source
+data_source_uri = "s3://dalhussein-courses/datasets/school/v1/"
+dataset_school = 'dbfs:/mnt/DE-Associate/datasets/school'
+checkpoint_path = 'dbfs:/mnt/DE-Associate/checkpoints/school'
+dlt_path = 'dbfs:/mnt/DE-Associate/dlt/school'
+db_name = 'DE_Associate_School'
+dlt_db_name = 'DE_Associate_School_DLT'
+spark.conf.set(f"dataset.school", dataset_school)
+
+# COMMAND ----------
+
+def clean_up():
+ print("Removing Checkpoints ...")
+ dbutils.fs.rm(checkpoint_path, True)
+ print("Removing DLT storage location ...")
+ dbutils.fs.rm(dlt_path, True)
+ print("Dropping Database ...")
+ spark.sql(f"DROP SCHEMA IF EXISTS {db_name} CASCADE")
+ print("Dropping DLT database ...")
+ spark.sql(f"DROP SCHEMA IF EXISTS {dlt_db_name} CASCADE")
+ print("Removing Dataset ...")
+ dbutils.fs.rm(dataset_school, True)
+ print("Done")
+
+# COMMAND ----------
+
+try:
+ clean = int(dbutils.widgets.get("clean"))
+except:
+ clean = 0
+
+if clean:
+ clean_up()
+
+# COMMAND ----------
+
+def path_exists(path):
+ try:
+ dbutils.fs.ls(path)
+ return True
+ except Exception as e:
+ msg = str(e)
+ if ("com.databricks.sql.io.CloudFileNotFoundException" in msg
+ or "java.io.FileNotFoundException" in msg):
+ return False
+ else:
+ raise
+
+# COMMAND ----------
+
+def download_dataset(source, target):
+ files = dbutils.fs.ls(source)
+
+ for f in files:
+ source_path = f"{source}/{f.name}"
+ target_path = f"{target}/{f.name}"
+ if not path_exists(target_path):
+ print(f"Copying {f.name} ...")
+ dbutils.fs.cp(source_path, target_path, True)
+
+# COMMAND ----------
+
+def get_index(dir):
+ files = dbutils.fs.ls(dir)
+ index = 0
+ if files:
+ file = max(files).name
+ index = int(file.rsplit('.', maxsplit=1)[0])
+ return index+1
+
+# COMMAND ----------
+
+def set_current_schema(schema_name, catalog_name='hive_metastore'):
+ spark.sql(f"USE CATALOG {catalog_name}")
+ spark.sql(f"CREATE SCHEMA IF NOT EXISTS {schema_name}")
+ spark.sql(f"USE {schema_name}")
+ print(f"Schema for the hands-on labs: {catalog_name}.{schema_name}")
+
+# COMMAND ----------
+
+# Structured Streaming
+streaming_dir = f"{dataset_school}/enrollments-streaming"
+raw_dir = f"{dataset_school}/enrollments-raw"
+
+def load_file(current_index):
+ latest_file = f"{str(current_index).zfill(2)}.parquet"
+ print(f"Loading {latest_file} file to the school dataset")
+ dbutils.fs.cp(f"{streaming_dir}/{latest_file}", f"{raw_dir}/{latest_file}")
+
+
+def load_new_data(all=False):
+ index = get_index(raw_dir)
+ if index >= 10:
+ print("No more data to load\n")
+
+ elif all == True:
+ while index <= 10:
+ load_file(index)
+ index += 1
+ else:
+ load_file(index)
+ index += 1
+
+# COMMAND ----------
+
+# DLT
+streaming_enrollments_dir = f"{dataset_school}/enrollments-json-streaming"
+streaming_courses_dir = f"{dataset_school}/courses-streaming"
+
+raw_enrollments_dir = f"{dataset_school}/enrollments-json-raw"
+raw_courses_dir = f"{dataset_school}/courses-cdc"
+
+def load_json_file(current_index):
+ latest_file = f"{str(current_index).zfill(2)}.json"
+ print(f"Loading {latest_file} enrollments file to the school dataset")
+ dbutils.fs.cp(f"{streaming_enrollments_dir}/{latest_file}", f"{raw_enrollments_dir}/{latest_file}")
+ #print(f"Loading {latest_file} courses file to the school dataset")
+ #dbutils.fs.cp(f"{streaming_courses_dir}/{latest_file}", f"{raw_courses_dir}/{latest_file}")
+
+
+def load_new_json_data(all=False):
+ index = get_index(raw_enrollments_dir)
+ if index >= 10:
+ print("No more data to load\n")
+
+ elif all == True:
+ while index <= 10:
+ load_json_file(index)
+ index += 1
+ else:
+ load_json_file(index)
+ index += 1
+
+# COMMAND ----------
+
+download_dataset(data_source_uri, dataset_school)
+set_current_schema(db_name)
diff --git a/Labs/Includes/images/bar_graph.png b/Labs/Includes/images/bar_graph.png
new file mode 100644
index 0000000..013c7c2
Binary files /dev/null and b/Labs/Includes/images/bar_graph.png differ
diff --git a/Labs/Includes/images/cluster_par1.png b/Labs/Includes/images/cluster_par1.png
new file mode 100644
index 0000000..801f94e
Binary files /dev/null and b/Labs/Includes/images/cluster_par1.png differ
diff --git a/Labs/Includes/images/cluster_par2.png b/Labs/Includes/images/cluster_par2.png
new file mode 100644
index 0000000..5a10f40
Binary files /dev/null and b/Labs/Includes/images/cluster_par2.png differ
diff --git a/Labs/Includes/images/cluster_par3.png b/Labs/Includes/images/cluster_par3.png
new file mode 100644
index 0000000..bf77236
Binary files /dev/null and b/Labs/Includes/images/cluster_par3.png differ
diff --git a/Labs/Includes/images/dashboard.png b/Labs/Includes/images/dashboard.png
new file mode 100644
index 0000000..e8a8d2c
Binary files /dev/null and b/Labs/Includes/images/dashboard.png differ
diff --git a/Labs/Includes/images/line_graph.png b/Labs/Includes/images/line_graph.png
new file mode 100644
index 0000000..901d4f9
Binary files /dev/null and b/Labs/Includes/images/line_graph.png differ
diff --git a/Labs/Includes/images/markdown.png b/Labs/Includes/images/markdown.png
new file mode 100644
index 0000000..0c93afa
Binary files /dev/null and b/Labs/Includes/images/markdown.png differ
diff --git a/Labs/Includes/images/school_job.png b/Labs/Includes/images/school_job.png
new file mode 100644
index 0000000..66179b2
Binary files /dev/null and b/Labs/Includes/images/school_job.png differ
diff --git a/Labs/Includes/images/school_schema.png b/Labs/Includes/images/school_schema.png
new file mode 100644
index 0000000..2945a2f
Binary files /dev/null and b/Labs/Includes/images/school_schema.png differ
diff --git a/Labs/Solutions/1- Databricks Lakehouse Platform/1.0L Solution - Creating Clusters.py b/Labs/Solutions/1- Databricks Lakehouse Platform/1.0L Solution - Creating Clusters.py
new file mode 100644
index 0000000..ebcb29f
--- /dev/null
+++ b/Labs/Solutions/1- Databricks Lakehouse Platform/1.0L Solution - Creating Clusters.py
@@ -0,0 +1,75 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC ## Lab: Creating Clusters
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Q1 - Creating a Demo Cluster
+# MAGIC
+# MAGIC Create a cluster with the following configurations:
+# MAGIC
+# MAGIC | Setting | Instructions |
+# MAGIC |--|--|
+# MAGIC |Cluster name|**Demo Cluster**|
+# MAGIC |Cluster mode|**Signle node**|
+# MAGIC |Runtime version|Select the Databricks runtime version 13.3 LTS|
+# MAGIC |Photon Acceleration| Uncheck the option |
+# MAGIC |Node type|4 cores|
+# MAGIC |Auto termination|30 minutes|
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC 1- Navigate to the **Compute** tab in the left side bar.
+# MAGIC
+# MAGIC 2- Under **All-purpose compute** tab, click **Create compute**.
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+-- MAGIC
+-- MAGIC
- Key: **datasets.path**
- Value: **dbfs:/mnt/DE-Associate/datasets/school** |
+-- MAGIC | Channel | Choose **Current**|
+-- MAGIC
+-- MAGIC Finally, click **Create**.
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ### Q5 - Run your Pipeline
+-- MAGIC
+-- MAGIC Select **Development** mode and Click **Start** to begin the update to your pipeline's tables
diff --git a/Labs/Solutions/4- Production Pipelines/4.2L Solution - Jobs - Land New Data.py b/Labs/Solutions/4- Production Pipelines/4.2L Solution - Jobs - Land New Data.py
new file mode 100644
index 0000000..4a3af21
--- /dev/null
+++ b/Labs/Solutions/4- Production Pipelines/4.2L Solution - Jobs - Land New Data.py
@@ -0,0 +1,91 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC ## Lab Solution: Creating a multi-task job
+# MAGIC
+# MAGIC In this lab, we will create a job that has 2 tasks:
+# MAGIC 1. The current notebook that lands a new batch of data in the lab dataset directory
+# MAGIC 1. The Delta Live Table pipeline created in the previous lab to processes this data
+# MAGIC
+# MAGIC * Help: Databricks Jobs documentation.
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC 1. Set the job name in the top-left of the screen to **School Job**
+# MAGIC 1. Configure the first task as specified below:
+# MAGIC | Setting | Value |
+# MAGIC |--|--|
+# MAGIC | Task name | Enter **Land New Data** |
+# MAGIC | Type | Choose **Notebook** |
+# MAGIC | Source | Choose **Workspace** |
+# MAGIC | Path | Use the navigator to choose the current notebook (4.2L - Jobs - Land New Data) |
+# MAGIC | Cluster | Select your cluster from the dropdown, under **Existing All Purpose Clusters** |
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC 3. Click the **Create** button
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Q2- Configuring Task 2 - DLT pipeline
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC 1. Click the add button (**+**) to add a new **Delta Live Tables pipeline** task
+# MAGIC 1. Configure the task:
+# MAGIC
+# MAGIC | Setting | Value |
+# MAGIC |--|--|
+# MAGIC | Task name | Enter **DLT pipeline** |
+# MAGIC | Type | Choose **Delta Live Tables pipeline** |
+# MAGIC | Pipeline | Choose the DLT pipeline created in the previous lab |
+# MAGIC | Depends on | Choose **Land New Data**, which is the previous task we defined above |
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC 3. Click the **Create task** button
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Q3- Run the job
+# MAGIC
+# MAGIC Click the **Run now** button in the top right to run this job. From the **Runs** tab, check your job run
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #### Q4- Review the finished job
+# MAGIC
+# MAGIC Once all tasks completed successfully, review the contents of each task to verify its result
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC > **Note**: The below cells are to be run as part of the **Task 1** to land new batch of data in the dataset directory
+
+# COMMAND ----------
+
+# MAGIC %run ../Includes/Setup-Lab
+
+# COMMAND ----------
+
+load_new_json_data()
diff --git a/Labs/Solutions/4- Production Pipelines/4.3L Solution - Databricks SQL.sql b/Labs/Solutions/4- Production Pipelines/4.3L Solution - Databricks SQL.sql
new file mode 100644
index 0000000..c5b32dd
--- /dev/null
+++ b/Labs/Solutions/4- Production Pipelines/4.3L Solution - Databricks SQL.sql
@@ -0,0 +1,121 @@
+-- Databricks notebook source
+-- MAGIC %md
+-- MAGIC
+-- MAGIC ## Lab Solution: Design a Dashboard with DBSQL
+-- MAGIC
+-- MAGIC In this lab, we will design a dashboard in DBSQL that has 2 graphs:
+-- MAGIC 1. Bar graph that shows the number of students per country
+-- MAGIC 1. Line graph that shows the daily enrollments amount
+-- MAGIC
+-- MAGIC * Help: Databricks SQL documentation.
+
+-- COMMAND ----------
+
+-- MAGIC %md-sandbox
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC Steps:
+-- MAGIC 1. Click the Add butoon (**+**) next to the results tab, and select **Visualization** from the dialog box
+-- MAGIC 1. Select **`Bar`** for the **Visualization Type**
+-- MAGIC 1. Set **`country`** for the **X Column**
+-- MAGIC 1. Under **Y columns** click **Add column**, and set it to **`students_count`**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. Finally, set the title of the graph to **Student Counts Viz**
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q3 - Creating a New Dashboard
+-- MAGIC
+-- MAGIC Add the above graph to a new dashboard named **Students Statistics**
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click the three vertical dots button at the top of the graph and select **Add to Dashboard**.
+-- MAGIC 1. Click the **Create new dashboard** option
+-- MAGIC 1. Name your dashboard **Students Statistics**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. With the new dashboard selected as the target, click **OK** to add your visualization
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q4 - Creating a Line Plot Visualization
+-- MAGIC
+-- MAGIC 1. Run the the below query in a new query tab in the **SQL Editor**, and then save it with the name **Daily Sales**
+
+-- COMMAND ----------
+
+SELECT cast(from_unixtime(enroll_timestamp, 'yyyy-MM-dd HH:mm:ss') AS date) enroll_timestamp,
+ sum(total) AS enrollments_amount
+FROM hive_metastore.de_associate_school.enrollments n
+INNER JOIN hive_metastore.de_associate_school.students s ON s.student_id = n.student_id
+GROUP BY enroll_timestamp
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC
+-- MAGIC 2. Create a Line Plot Visualization that shows the daily enrollments amount
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click the **Add Visualization** button
+-- MAGIC 1. Select **`Line`** for the **Visualization Type**
+-- MAGIC 1. Set **`enroll_timestamp`** for the **X Column**
+-- MAGIC 1. Under **Y columns** click **Add column**, and set it to **`enrollments_amount`**
+-- MAGIC 1. Click **Save**
+-- MAGIC 1. Finally, set the title of the graph to **Daily Sales Viz**
+-- MAGIC 1. Click the three vertical dots button at the top of the graph and select **Add to Dashboard**.
+-- MAGIC 1. Select the dashboard **Students Statistics** created above
+-- MAGIC 1. Click **OK** to add your visualization
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC #### Q5 - Review your Dashboard
+-- MAGIC
+-- MAGIC Open your Dashboard and refresh its underlaying data
+-- MAGIC
+-- MAGIC ##### Anwser:
+-- MAGIC
+-- MAGIC Steps:
+-- MAGIC 1. Click on the **Dashboards** button on left side bar
+-- MAGIC 1. Find the dashboard **Students Statistics** created earlier. Click to open it
+-- MAGIC 1. Click the **Refresh** button to update your dashboard
diff --git a/Labs/Solutions/Includes/Setup-Lab.py b/Labs/Solutions/Includes/Setup-Lab.py
new file mode 100644
index 0000000..ac61e86
--- /dev/null
+++ b/Labs/Solutions/Includes/Setup-Lab.py
@@ -0,0 +1,137 @@
+# Databricks notebook source
+data_source_uri = "s3://dalhussein-courses/datasets/school/v1/"
+dataset_school = 'dbfs:/mnt/DE-Associate/datasets/school'
+checkpoint_path = 'dbfs:/mnt/DE-Associate/checkpoints/school'
+dlt_path = 'dbfs:/mnt/DE-Associate/dlt/school'
+db_name = 'DE_Associate_School'
+dlt_db_name = 'DE_Associate_School_DLT'
+spark.conf.set(f"dataset.school", dataset_school)
+
+# COMMAND ----------
+
+def clean_up():
+ print("Removing Checkpoints ...")
+ dbutils.fs.rm(checkpoint_path, True)
+ print("Removing DLT storage location ...")
+ dbutils.fs.rm(dlt_path, True)
+ print("Dropping Database ...")
+ spark.sql(f"DROP SCHEMA IF EXISTS {db_name} CASCADE")
+ print("Dropping DLT database ...")
+ spark.sql(f"DROP SCHEMA IF EXISTS {dlt_db_name} CASCADE")
+ print("Removing Dataset ...")
+ dbutils.fs.rm(dataset_school, True)
+ print("Done")
+
+# COMMAND ----------
+
+try:
+ clean = int(dbutils.widgets.get("clean"))
+except:
+ clean = 0
+
+if clean:
+ clean_up()
+
+# COMMAND ----------
+
+def path_exists(path):
+ try:
+ dbutils.fs.ls(path)
+ return True
+ except Exception as e:
+ msg = str(e)
+ if ("com.databricks.sql.io.CloudFileNotFoundException" in msg
+ or "java.io.FileNotFoundException" in msg):
+ return False
+ else:
+ raise
+
+# COMMAND ----------
+
+def download_dataset(source, target):
+ files = dbutils.fs.ls(source)
+
+ for f in files:
+ source_path = f"{source}/{f.name}"
+ target_path = f"{target}/{f.name}"
+ if not path_exists(target_path):
+ print(f"Copying {f.name} ...")
+ dbutils.fs.cp(source_path, target_path, True)
+
+# COMMAND ----------
+
+def get_index(dir):
+ files = dbutils.fs.ls(dir)
+ index = 0
+ if files:
+ file = max(files).name
+ index = int(file.rsplit('.', maxsplit=1)[0])
+ return index+1
+
+# COMMAND ----------
+
+def set_current_schema(schema_name, catalog_name='hive_metastore'):
+ spark.sql(f"USE CATALOG {catalog_name}")
+ spark.sql(f"CREATE SCHEMA IF NOT EXISTS {schema_name}")
+ spark.sql(f"USE {schema_name}")
+ print(f"Schema for the hands-on labs: {catalog_name}.{schema_name}")
+
+# COMMAND ----------
+
+# Structured Streaming
+streaming_dir = f"{dataset_school}/enrollments-streaming"
+raw_dir = f"{dataset_school}/enrollments-raw"
+
+def load_file(current_index):
+ latest_file = f"{str(current_index).zfill(2)}.parquet"
+ print(f"Loading {latest_file} file to the school dataset")
+ dbutils.fs.cp(f"{streaming_dir}/{latest_file}", f"{raw_dir}/{latest_file}")
+
+
+def load_new_data(all=False):
+ index = get_index(raw_dir)
+ if index >= 10:
+ print("No more data to load\n")
+
+ elif all == True:
+ while index <= 10:
+ load_file(index)
+ index += 1
+ else:
+ load_file(index)
+ index += 1
+
+# COMMAND ----------
+
+# DLT
+streaming_enrollments_dir = f"{dataset_school}/enrollments-json-streaming"
+streaming_courses_dir = f"{dataset_school}/courses-streaming"
+
+raw_enrollments_dir = f"{dataset_school}/enrollments-json-raw"
+raw_courses_dir = f"{dataset_school}/courses-cdc"
+
+def load_json_file(current_index):
+ latest_file = f"{str(current_index).zfill(2)}.json"
+ print(f"Loading {latest_file} enrollments file to the school dataset")
+ dbutils.fs.cp(f"{streaming_enrollments_dir}/{latest_file}", f"{raw_enrollments_dir}/{latest_file}")
+ #print(f"Loading {latest_file} courses file to the school dataset")
+ #dbutils.fs.cp(f"{streaming_courses_dir}/{latest_file}", f"{raw_courses_dir}/{latest_file}")
+
+
+def load_new_json_data(all=False):
+ index = get_index(raw_enrollments_dir)
+ if index >= 10:
+ print("No more data to load\n")
+
+ elif all == True:
+ while index <= 10:
+ load_json_file(index)
+ index += 1
+ else:
+ load_json_file(index)
+ index += 1
+
+# COMMAND ----------
+
+download_dataset(data_source_uri, dataset_school)
+set_current_schema(db_name)
diff --git a/README.md b/README.md
index 07e748f..c81d2d5 100644
--- a/README.md
+++ b/README.md
@@ -1,8 +1,16 @@
# Databricks Certified Data Engineer Associate
+ This repository contains the resources of the preparation course for Databricks Data Engineer Associate certification exam on Udemy:
+
This repository contains the resources of the preparation course for Databricks Data Engineer Associate certification exam on Udemy:
+
+https://www.udemy.com/course/databricks-certified-data-engineer-associate/?referralCode=F0FA48E9A0546C975F14.
+
+
-https://www.udemy.com/course/databricks-certified-data-engineer-associate/?referralCode=F0FA48E9A0546C975F14.
+## Practice Exams
-To import these resources into your Databricks workspace, clone this repository via Databricks Repos.
+ +Practice exams for this certification are available in the following Udemy course:
+
+Practice exams for this certification are available in the following Udemy course:
+
+https://www.udemy.com/course/practice-exams-databricks-certified-data-engineer-associate/?referralCode=9AA679C03D1F51B2C956.