You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+10-2Lines changed: 10 additions & 2 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -85,14 +85,22 @@ python -m pipeline \
85
85
--k 1 \ # run once to quick start
86
86
--models gpt-5 \ # or any model you configured
87
87
--tasks file_property/size_classification
88
+
# Add --task-suite easy to run the lightweight dataset (where available)
88
89
```
89
90
90
-
Results are saved to `./results/{exp_name}/{model}__{mcp}/run-*/...` (e.g., `./results/test-run/gpt-5__filesystem/run-1/...`).
91
+
Results are saved to `./results/{exp_name}/{model}__{mcp}/run-*/...`for the standard suite and `./results/{exp_name}/{model}__{mcp}-easy/run-*/...` when you run `--task-suite easy`(e.g., `./results/test-run/gpt-5__filesystem/run-1/...` or `./results/test-run/gpt-5__github-easy/run-1/...`).
91
92
92
93
---
93
94
94
95
## Run your evaluations
95
96
97
+
### Task suites (standard vs easy)
98
+
99
+
- Each MCP service now stores tasks under `tasks/<mcp>/<task_suite>/<category>/<task>/`.
100
+
-`standard` (default) covers the full benchmark (127 tasks today).
101
+
-`easy` hosts 10 lightweight tasks per MCP, ideal for smoke tests and CI (GitHub’s are already available under `tasks/github/easy`).
102
+
- Switch suites with `--task-suite easy` (defaults to `--task-suite standard`).
Copy file name to clipboardExpand all lines: docs/contributing/make-contribution.md
+2-2Lines changed: 2 additions & 2 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -2,8 +2,8 @@
2
2
3
3
1. Fork the repository and create a feature branch.
4
4
5
-
2. Add new tasks under `tasks/<category>/<task_n>/` with the files of `meta.json`, `description.md` and `verify.py`. Please refer to [Task Page](../datasets/task.md) for detailed instructions.
5
+
2. Add new tasks under `tasks/<mcp>/<task_suite>/<category>/<task_id>/` with the files of `meta.json`, `description.md` and `verify.py`. Please refer to [Task Page](../datasets/task.md) for detailed instructions.
6
6
7
7
3. Ensure all tests pass.
8
8
9
-
4. Submit a pull request — contributions are welcome!
9
+
4. Submit a pull request — contributions are welcome!
Copy file name to clipboardExpand all lines: docs/datasets/task.md
+9-7Lines changed: 9 additions & 7 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -18,15 +18,17 @@ tasks
18
18
│
19
19
└───filesystem
20
20
│
21
-
└───file_context
21
+
└───standard # task_suite (also supports `easy`)
22
22
│
23
-
└───create_file_write
24
-
│ meta.json
25
-
│ description.md
26
-
│ verify.py
23
+
└───file_context # category_id
24
+
│
25
+
└───create_file_write
26
+
│ meta.json
27
+
│ description.md
28
+
│ verify.py
27
29
```
28
30
29
-
Note that all tasks are placed under `tasks/`. `filesystem` refers to the environment for the MCP service.
31
+
All tasks live under `tasks/<mcp>/<task_suite>/<category>/<task_id>/`. `filesystem` refers to the MCP service and `task_suite` captures the difficulty slice (`standard` benchmark vs `easy` smoke tests).
30
32
31
33
`meta.json` includes the meta information about the task, including the following key
32
34
- task_id: the id of the task.
@@ -68,4 +70,4 @@ Accordingly, the `verify.py` contains the following functionalities
68
70
- Check whether the target directory contains the file with target file name. [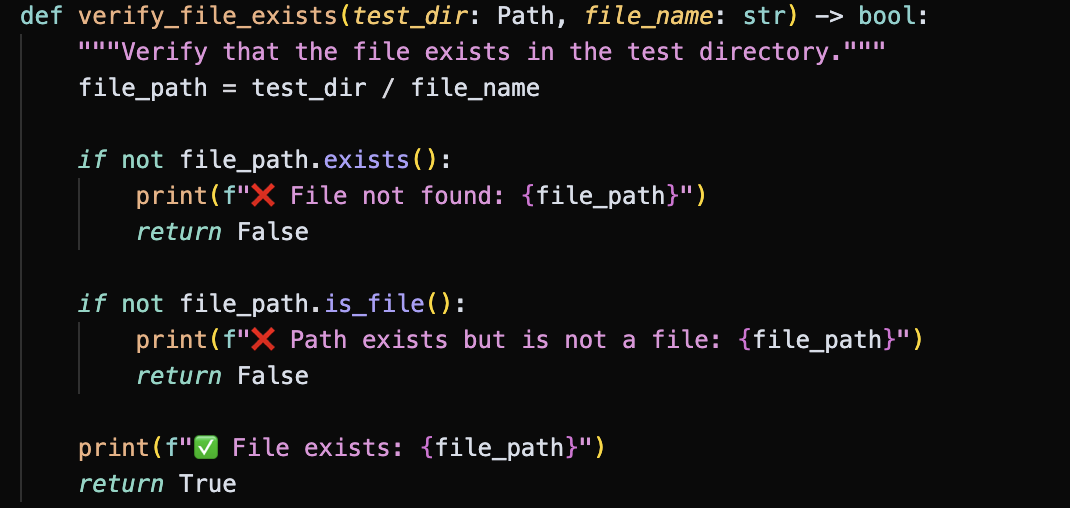](https://postimg.cc/7fGRTX87)
69
71
- Check whether the target file contains the desired content `EXPECTED_PATTERNS = ["Hello Wolrd"]`. [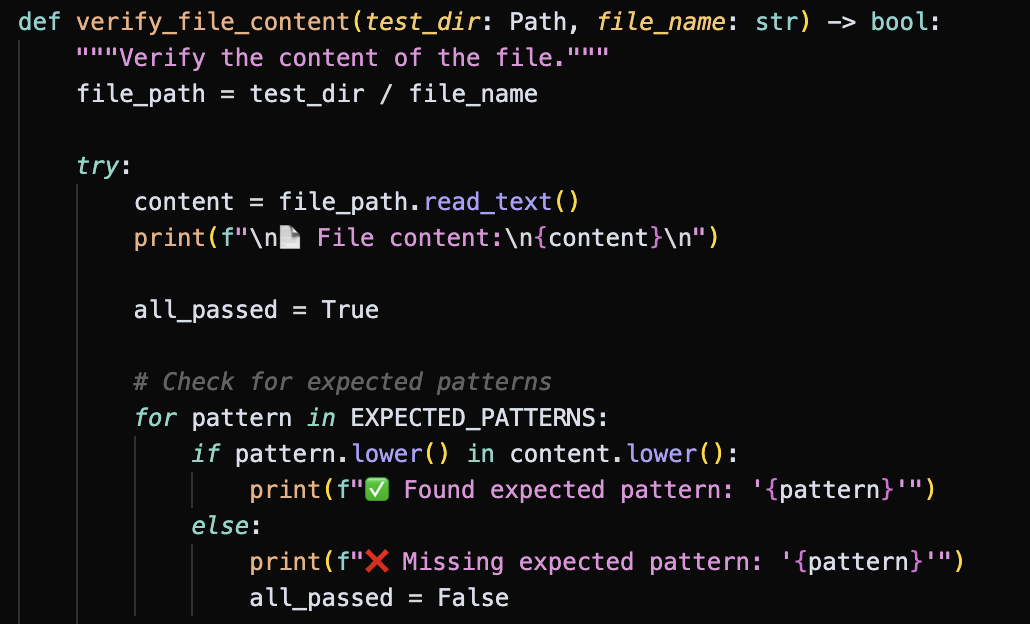](https://postimg.cc/w7ZSWZc0)
70
72
71
-
- If the outcome passes **all the above verification functionalities**, the task would be marked as successfully completed.
73
+
- If the outcome passes **all the above verification functionalities**, the task would be marked as successfully completed.
where *MODEL_NAME* refers to the model choice from the supported models (see [Introduction Page](./introduction.md) for more information), *EXPNAME* refers to customized experiment name, *TASK* refers to specific task or task group (see `tasks/` for more information), *K* refers to the time of independent experiments.
47
+
where *MODEL_NAME* refers to the model choice from the supported models (see [Introduction Page](./introduction.md) for more information), *EXPNAME* refers to customized experiment name, *TASK* refers to specific task or task group (see `tasks/<mcp>/<task_suite>/...` for more information), *K* refers to the time of independent experiments.
48
48
49
49
50
50
Additionally, the `run-benchmark.sh` script evaluates models across all MCP services:
0 commit comments