You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Let's learn about Dynamic Programming via these 50 free blog posts. They are ordered by HackerNoon reader engagement data. Visit the /Learn or LearnRepo.com to find the most read blog posts about any technology.
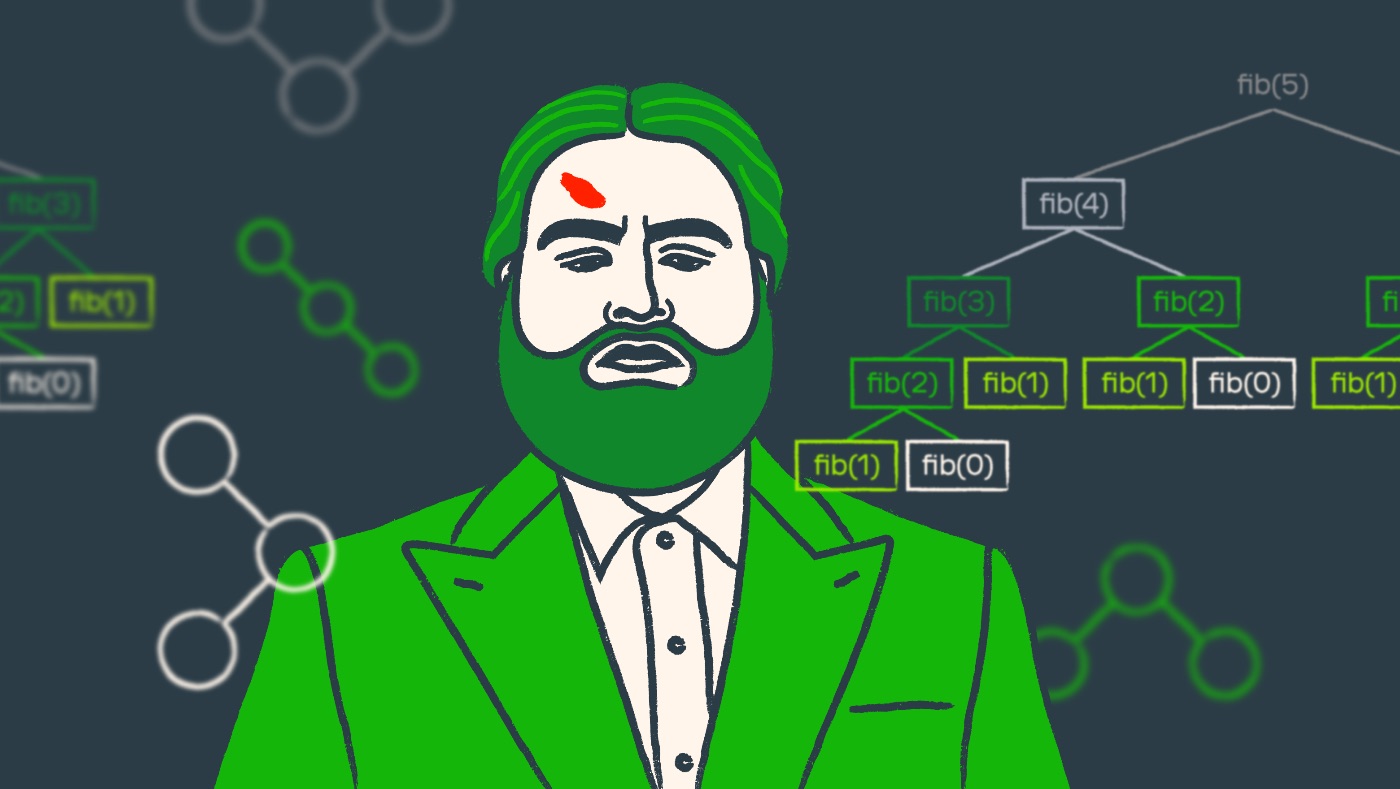
Dynamic programming is a method for solving complex problems by breaking them down into simpler overlapping subproblems and storing their results. It matters for efficiently tackling optimization challenges in computer science, significantly improving algorithmic performance.
Shelf label is nothing but labels to put on a rack or a shelf where an item is stored. These labels are printed and put on store rack or shelf. For example, when you go to a supermarket you can see labels are displayed with various information where the product is stored.
Memoization is an optimization technique that speeds up programs by caching the results of previous function calls. Python 3 makes it easy to memoize functions.
In this article, I gave you an introduction to Dynamic Programming with several examples. Here I will solve 6 harder Dynamic Programming problems to show you how to approach them.
In this article, we will learn about what memoization is, what value memoization provides to Javascript developers, and how to use it to improve JS functions.
This article is for them, who have heard about Dynamic Programming and for them also, who have not heard but want to know about Dynamic Programming (or DP) . In this article, I will cover all those topics which can help you to work with DP .
You need to solve this: given an integer array nums representing the amount of money of each house, return the maximum amount of money you can rob tonight.
Review prior works on value iteration, RL algorithms, and acceleration methods, including Nesterov and Anderson acceleration, in dynamic programming and RL.
Explore the fundamental concepts of MDP and RL, including Bellman operators, Q-value functions, and value iteration for optimal reinforcement learning.
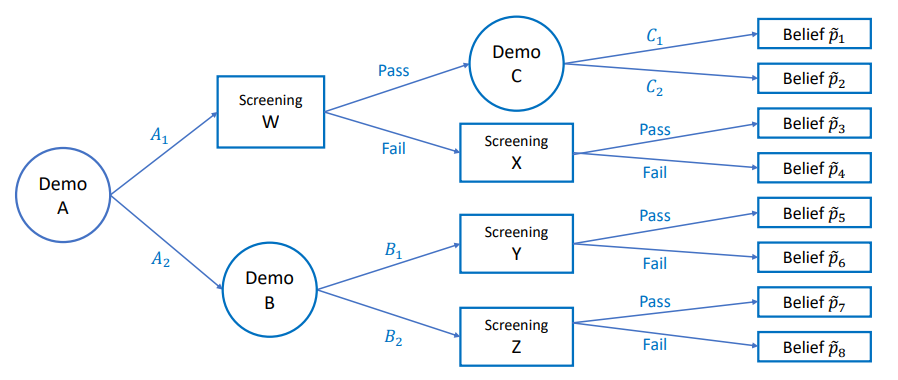
Explore a Bayesian persuasion framework in multi-phase trials where the sender faces constraints on signals due to exogenous experiment determinations.
Learn how Anc-VI's complexity lower bound proves its optimality. Discover the span condition’s role in establishing performance limits in optimization theory
Discover how Anc-VI converges to fixed points in undiscounted MDPs (γ = 1), addressing challenges typically overlooked in traditional DP and RL theory.
Explore the omitted proofs for Theorem 2, including the inductive approach to establishing the accelerated convergence rates for the Bellman optimality and anti
Learn about Gauss-Seidel Anchored Value Iteration, a method combining anchoring with Gauss-Seidel updates to improve convergence in finite state-action spaces.