You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Let's learn about Web Scraping via these 224 free blog posts. They are ordered by HackerNoon reader engagement data. Visit the /Learn or LearnRepo.com to find the most read blog posts about any technology.
Data is the new oil, sun, and the moon! This tag is sponsored by Bright Data. Write a story on web scraping for AI and win from $2500!
Ever since Google Web Search API deprecation in 2011, I've been searching for an alternative. I need a way to get links from Google search into my Python script. So I made my own, and here is a quick guide on scraping Google searches with requests and Beautiful Soup.
Financial market data is one of the most valuable data in the current time. If analyzed correctly, it holds the potential of turning an organisation’s economic issues upside down. Among a few of them, Yahoo finance is one such website which provides free access to this valuable data of stocks and commodities prices. In this blog, we are going to implement a simple web crawler in python which will help us in scraping yahoo finance website. Some of the applications of scraping Yahoo finance data can be forecasting stock prices, predicting market sentiment towards a stock, gaining an investive edge and cryptocurrency trading. Also, the process of generating investment plans can make good use of this data!
Digital fingerprinting, identifying users by hardware params. Learn about parameters, manipulation, fingerprint spoofing, online privacy, bot detection systems
In this post we are going to scrape websites to gather data via the API World's top 300 APIs of year. The major reason of doing web scraping is it saves time and avoid manual data gathering and also allows you to have all the data in a structured form.
In this post, we are going to scrape data from Linkedin using Python and a Web Scraping Tool. We are going to extract Company Name, Website, Industry, Company Size, Number of employees, Headquarters Address, and Specialties.
With the massive increase in the volume of data on the Internet, this technique is becoming increasingly beneficial in retrieving information from websites and applying them for various use cases. Typically, web data extraction involves making a request to the given web page, accessing its HTML code, and parsing that code to harvest some information. Since JavaScript is excellent at manipulating the DOM (Document Object Model) inside a web browser, creating data extraction scripts in Node.js can be extremely versatile. Hence, this tutorial focuses on javascript web scraping.
To scrape a website, it’s common to send GET requests, but it's useful to know how to send data. In this article, we'll see how to start with POST requests.
LinkedIn is a great place to find leads and engage with prospects. In order to engage with potential leads, you’ll need a list of users to contact. However, getting that list might be difficult because LinkedIn has made it difficult for web scraping tools. That is why I made a script to search Google for potential LinkedIn user and company profiles.
A while ago I was trying to perform an analysis of a Medium publication for a personal project. But getting the data was a problem – scraping only the publication’s home page does not guarantee that you get all the data you want.
These extensions for scraping Google maps can be used for a number of purposes in various situations that can be either data collection or market research.
La necesidad de extraer datos de sitios web está aumentando. Cuando realizamos proyectos relacionados con datos, como el monitoreo de precios, análisis de negocios o agregador de noticias, siempre tendremos que registrar los datos de los sitios web. Sin embargo, copiar y pegar datos línea por línea ha quedado desactualizado. En este artículo, le enseñaremos cómo convertirse en un "experto" en la extracción de datos de sitios web, que consiste en hacer web scraping con python.
A few years ago, Cambridge Analytica made netizens concerned regarding the gathering of their online data. At that time, affected or interested users had little knowledge of how big the big-data industry actually was.
La necesidad de extraer datos de sitios web está aumentando. Cuando realizamos proyectos relacionados con datos, como el monitoreo de precios, análisis de negocios o agregador de noticias, siempre tendremos que registrar los datos de los sitios web. Sin embargo, copiar y pegar datos línea por línea ha quedado desactualizado. En este artículo, le enseñaremos cómo convertirse en un "experto" en la extracción de datos de sitios web, que consiste en hacer web scraping con python.
The goal of SEO is to get your website to the top of the search engine. One excellent way of tracking SEO progress is by checking the Search engine result pages (SERPs) of a website.
Hi everyone. In this article we are going to talk about how can you write a simple web scraper and a little search application using well known existing technologies which you perhaps didn’t know they can do that.
What started as a simple script evolved into a full-fledged data engineering and NLP pipeline that can process a decade's worth of legal decisions in minutes.
Collecting data from the web can be the core of data science. In this article, we'll see how to start with scraping with or without having to write code.
A guide on how to do Web Scraping in DotNet (.NET) CSharp (C#), with examples. Software Development Coding Programming Selenium HtmlAgilityPack Puppeteer
Using Django & BrightData to build a Movie Recommendation Website! With ability to search through data of various rating agencies, Flix-Finder is a must have!
These days we are all scared of the new airborne contagious coronavirus (2019-nCoV). Even if it is a tiny cough or low fever, it might underlie a lethargic symptom. However, what is the real truth?
Scraping the web is about extracting data in a clean and readable format that developers deploy to read and download an entire web page of its data ethically
Con el advenimiento de los grandes datos, las personas comienzan a obtener datos de Internet para el análisis de datos con la ayuda de rastreadores web. Hay varias formas de hacer su propio rastreador: extensiones en los navegadores, codificación de python con Beautiful Soup o Scrapy, y también herramientas de extracción de datos como Octoparse.
Join the AI Writing Contest by Bright Data and HackerNoon! Share your insights on AI, LLMs, and web scraping for a chance to win from a $2500 prize pool.
Use Kali Linux Docker containers and host ephemeral environments to support covert web scraping via Tor Browser, and penetration testing of container networks.
Data extraction has many forms and can be complicated. From Preventing your IP from getting banned to bypassing the captchas, to parsing the source correctly, headerless chrome for javascript rendering, data cleaning, and then generating the data in a usable format, there is a lot of effort that goes in. I have been scraping data from the web for over 8 years. We used web scraping for tracking the prices of other hotel booking vendors. So, when our competitor lowers his prices we get a notification to lower our prices to from our cron web scrapers.
Last week I finished my Ruby curriculum at Microverse. So I was ready to build my Capstone Project. Which is a solo project at the end of each of the Microverse technical curriculum sections.
Web scrapers! JavaScript has Cheerio and Puppeteer. Python has Beautiful Soup, Playwright as well as others. Lets see how well these webs scrapers function.
Scraping football data (soccer in the US) is a great way to build comprehensive datasets to help create stats dashboards. Check out our football data scraper!
Ever since Google Web Search API deprecation in 2011, I’ve been searching for an alternative. I need a way to get links from Google search into my Python script. So I made my own, and here is a quick guide on scraping Google searches with requests and Beautiful Soup.
Can modern AI systems fully automate web data collection and analysis? Let’s delve deeper into ML and web scraping to see if this is more than just a new hype.
From a technical marketer perspective, scraping and automation libraries are extremely important to learn. Here’s an introduction to two of the most widely used web scraping libraries in Node JS.
Para extraer datos de websites, puede usar las herramientas de extracción de datos como Octoparse. Estas herramientas pueden extraer datos de website automáticamente y guardarlos en muchos formatos, como Excel, JSON, CSV, HTML o en su propia base de datos a través de API. Solo toma unos minutos puede extraer miles de líneas de datos, la mejor es que no se necesita codificación en este proceso.
From the most popular seats to the most popular viewing times, we wanted to find out more about the movie trends in Singapore . So we created PopcornData — a website to get a glimpse of Singapore’s Movie trends — by scraping data, finding interesting insights, and visualizing them.
The AI Writing Contest deadline has been extended to December 16, 2024! Explore data collection for AI and LLM training, and compete for $2,500. Enter now!
While building ScrapingBee I'm always checking different forums everyday to help people about web scraping related questions and engage with the community.
In the last few years, web scraping has been one of my day to day and frequently needed tasks. I was wondering if I can make it smart and automatic to save lots of time. So I made AutoScraper!
As the CEO of a proxy service and data scraping solutions provider, I understand completely why global data breaches that appear on news headlines at times have given web scraping a terrible reputation and why so many people feel cynical about Big Data these days.
Playwright is the rock star of browser automation libraries, and just like Santa Claus delivers presents on Christmas Eve... Learn more about the latest update.
This article lists the 5 best X (Twitter) scraping tools available today. We’ll explore what makes each tool unique, focusing on their capabilities for tasks li
The business world is a very cold and hard place where only the best find their way to succeed. The market — each market — has its own limits and even if it’s pretty easy to get into the market, the most difficult part comes when you have to find a way to stay in that market and grow your business when the competition is always growing.
Coronavirus cases are increasing day by day. It’s very important to get vaccinated. so I tried to create an automated notifier to tell me when a lost opened up.
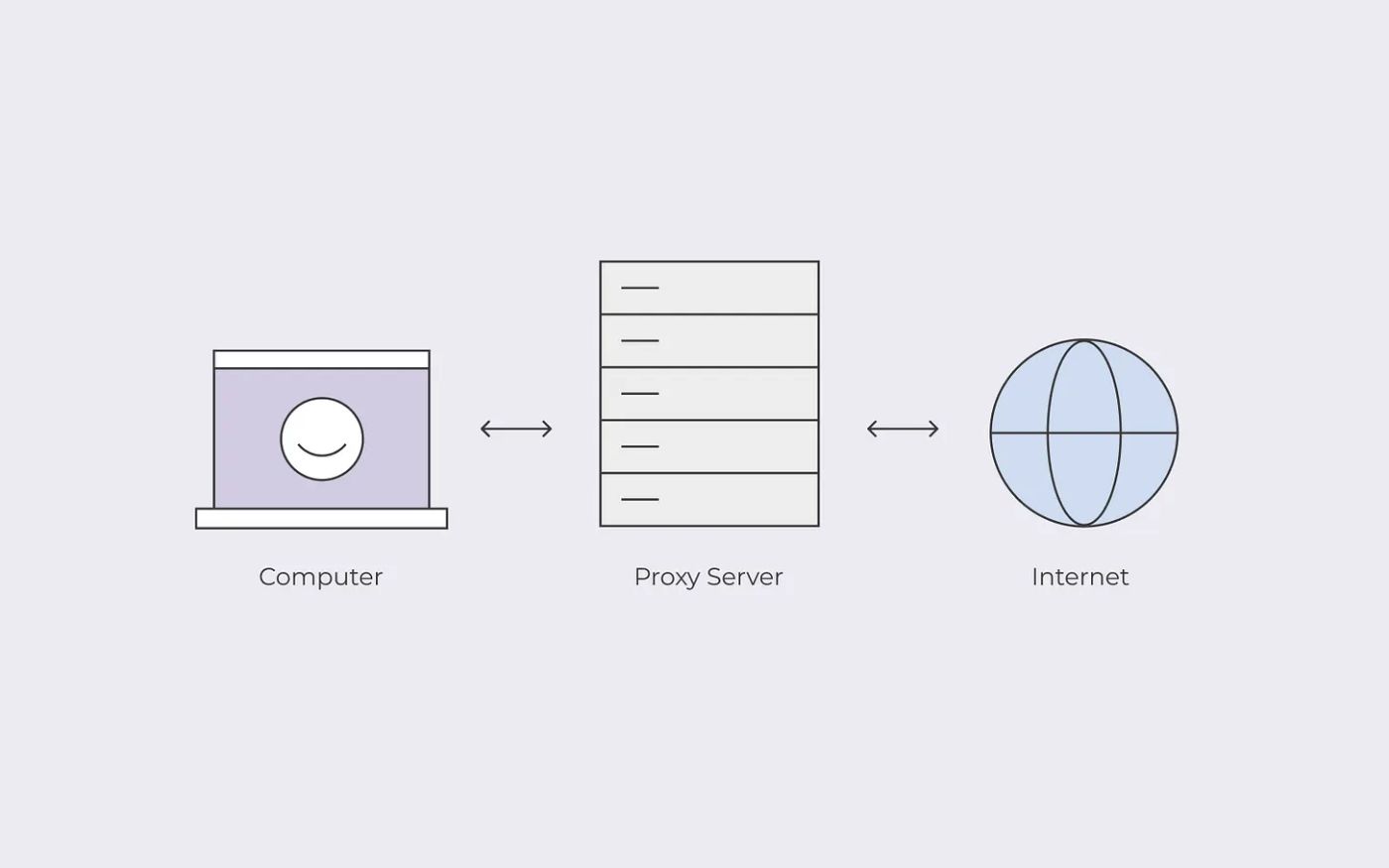
Why in large web scraping projects there's the need of proxy servers? Here a brief explanation of what they are and how they work and their differences.
As the world is facing the worst pandemic ever, I was just looking at how countries spend on their healthcare infrastructure. So, I thought of doing a data visualization of the medical expense of several countries. My search led to this article, which has data from many countries for the year 2016. I did not found any authentic source for the latest year. So, we’ll continue with 2016.
In this post, we are going to learn web scraping with python. Using python we are going to Scrape websites like Walmart, eBay, and Amazon for the pricing of Microsoft Xbox One X 1TB Black Console. Using that scraper you would be able to scrape pricing for any product from these websites. As you know I like to make things pretty simple, for that, I will also be using a web scraper which will increase your scraping efficiency.
Usually forgotten in all Data Science masters and courses, Web Scraping is, in my honest opinion a basic tool in the Data Scientist toolset, as is the tool for getting and therefore using external data from your organization when public databases are not available.
In this post, we are going to scrape Yahoo Finance using python. This is a great source for stock-market data. We will code a scraper for that. Using that scraper you would be able to scrape stock data of any company from yahoo finance. As you know I like to make things pretty simple, for that, I will also be using a web scraper which will increase your scraping efficiency.
La paginación es una técnica ampliamente utilizada en el diseño web que divide el contenido en varias páginas, presentando grandes conjuntos de datos de una manera mucho más fácil de digerir para los internautas.
Anti-bot techniques are getting life harder for web scrapers. In this post we'll see how Kasada protects a website and how a misconfiguration of it can be used
Some time ago, a few friends and I decided to build an app. We duck-taped our code together, launched our first version, then attracted a few users with a small marketing budget.
Business Intelligence (BI) es un negocio basado en datos, un proceso de toma de decisiones basado en datos recopilados. A menudo es utilizado por gerentes y ejecutivos para generar ideas procesables. Como resultado, BI siempre se conoce indistintamente como "Business Analytics" o "Data Analytics".
Welcome to the new way of scraping the web. In the following guide, we will scrape BestBuy product pages, without writing any parsers, using one simple library: Scrapezone SDK.
A device fingerprint - or device fingerprinting - is a method to identify a device using a combination of attributes provided by the device itself, via its brow
Built a real-time sneaker scraper using Bright Data’s MCP Server, LangChain, Claude, and FastAPI. This tool bypasses scraping blocks and extracts live Nike prod
Web development has moved at a tremendous pace in the last decade with a lot of frameworks coming in for both backend and frontend development. Websites have become smarter and so have the underlying frameworks used in developing them. All these advancements in web development have led to the development of the browsers themselves too.
Oxylabs' AI-driven tool, OxyCopilot, simplifies web data collection, saving time and money by automating complex tasks using just a URL and natural prompts.
Explore how proxies enhance online privacy and security, including types like data center and residential proxies. Learn proxy usage in Python for web scraping.
When you need tons of data quickly, a web scraper is the best option. Luckily, making your own scraper isn't as hard as it seems. Here's how to do it in NodeJS!
Learn the basics of data engineering with a practical ETL pipeline project. Explore how weather, flight, city data are extracted, transformed, loaded into a DB.
La necesidad de crawling datos web ha aumentado en los últimos años. Los datos crawled se pueden usar para evaluación o predicción en diferentes campos. Aquí, me gustaría hablar sobre 3 métodos que podemos adoptar para scrape datos desde un sitio web.
It’s safe to say that the amount of data available on the internet nowadays is practically limitless, with much of it no more than a few clicks away. However, gaining access to the information you need sometimes involves a lot of time, money, and effort.
Are you looking for a method of scraping Amazon reviews and do not know where to begin with? In that case, you may find this blog very useful in scraping Amazon reviews. In this blog, we will discuss scraping amazon reviews using Scrapy in python. Web scraping is a simple means of collecting data from different websites, and Scrapy is a web crawling framework in python.
Web Scraping with Python is a popular subject around data science enthusiasts. Here is a piece of content aimed at beginners who want to learn Web Scraping with Python lxml library.
I’m sure almost everyone reading this has been affected by the emergence of the novel coronavirus disease (COVID-19), in addition to noticing some serious disruptive economic changes across most industries. Our data research department here at Oxylabs has confirmed these movements, especially in the e-commerce, human resources (HR), travel, accommodation and cybersecurity segments.
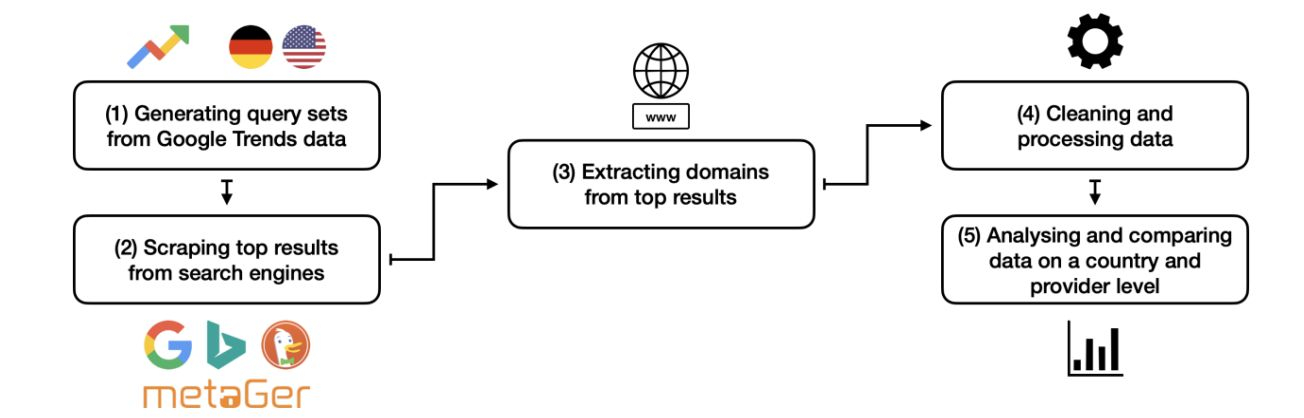
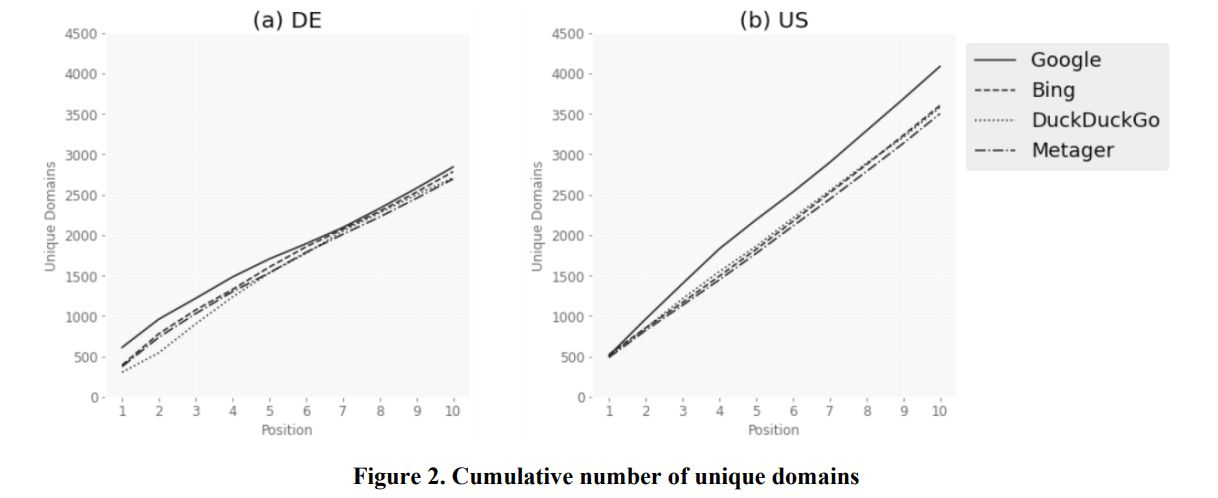
Explore a comprehensive analysis of search result overlaps and source diversity across major search engines like Google, Bing, and meta search engines.
There’s no doubt that in order to make a decent profit on Amazon, it is essential to choose the best product to sell. To find out which product sells the best, we need to conduct product research to understand the market.
Explore data collection for AI and LLM training in the AI writing contest on HackerNoon. Submit your entry by December 1, 2024, for a chance to win from $2,500.
In this part of the ‘Alpha Capture in Digital Commerce series’,we will explore the challenges of data acquisition in retail and discuss data science application
¿Alguna vez te sucede cuando la gente te pide que escribas una API separada para integrar datos de redes sociales y guardar los datos sin procesar en tu base de datos de análisis en el sitio? Definitivamente quieres saber qué es la API, cómo se usa en web scraping y qué puede lograr con ella. Echemos un vistazo.
C# and JavaScript each have their own advantages and disadvantages in web crawling. The choice of language depends on specific needs and development environment
Follow me along on how I explored Germany’s largest travel forum Vielfliegertref. As an inspiring data scientist, building interesting portfolio projects is key to showcase your skills. When I learned coding and data science as a business student through online courses, I disliked that datasets were made up of fake data or were solved before like Boston House Prices or the Titanic dataset on Kaggle.
Amazon is one of the largest e-commerce platforms across the globe. It has one of the largest customer bases and one of the most versatile and adaptive product portfolios. It definitely gets the advantage of a large amount of data and better operational processes in place due to its standing as one of the largest retailers. Having said that, even you can use Amazon’s data as an advantage to yourself to design a better product and price portfolio.
Block specific resources from downloading with Playwright. Save time and money by downloading only the essential resources while web scraping or testing.
The shutdowns brought an opportunity for my daughter to participate in virtual scouting events all over the United States. When the event registration form changed, I took the chance to try out some new web scraping skills while inspiring my daughter about the power of code for everyday tasks.
Unlock AI's potential with Bright Data! Discover methods, tackle challenges, and use pre-configured datasets for efficient, compliant public web data collection
The story of two founders who built a site that tracks liquid rules, airport info, and travel tips, only to have it crushed by a single EU announcement.
Off late, “Fintech” has been and remains to be a buzzword. It is transcending beyond traditional banking and financial services, encompassing online wallets, crypto, crowdfunding, asset management, and pretty much every other activity that includes a financial transaction. Thereby competing directly and fiercely with traditional financing giants and their methods.
Contextual advertising is on the rise, offering a more effective and less costly solution for personalization. Learn more about how ML can drive it further.
Web automation and web scraping are quite popular among people out there. That’s mainly because people tend to use web scraping and other similar automation technologies to grab information they want from the internet. The internet can be considered as one of the biggest sources of information. If we can use that wisely, we will be able to scrape lots of important facts. However, it is important for us to use appropriate methodologies to get the most out of web scraping. That’s where proxies come into play.













































































































 In this post, we are going to scrape Yahoo Finance using python. This is a great source for stock-market data. We will code a scraper for that. Using that scraper you would be able to scrape stock data of any company from yahoo finance. As you know I like to make things pretty simple, for that, I will also be using a web scraper which will increase your scraping efficiency.
In this post, we are going to scrape Yahoo Finance using python. This is a great source for stock-market data. We will code a scraper for that. Using that scraper you would be able to scrape stock data of any company from yahoo finance. As you know I like to make things pretty simple, for that, I will also be using a web scraper which will increase your scraping efficiency.