diff --git a/chapters/kn/_toctree.yml b/chapters/kn/_toctree.yml
new file mode 100644
index 000000000..2349d4148
--- /dev/null
+++ b/chapters/kn/_toctree.yml
@@ -0,0 +1,53 @@
+- title: 0. ಸೆಟಪ್
+ sections:
+ - local: chapter0/1
+ title: ಪರಿಚಯ
+
+
+- title: 1. ಟ್ರಾನ್ಸ್ಫಾರ್ಮರ್ ಮಾದರಿಗಳು
+ sections:
+ # - local: chapter1/1
+ # title: Introduction
+ - local: chapter1/2
+ title: ನೈಸರ್ಗಿಕ ಭಾಷಾ ಸಂಸ್ಕರಣೆ ಮತ್ತು ದೊಡ್ಡ ಭಾಷಾ ಮಾದರಿ
+ # - local: chapter1/3
+ # title: Transformers, what can they do?
+ # - local: chapter1/4
+ # title: How do Transformers work?
+ # - local: chapter1/5
+ # title: How 🤗 Transformers solve tasks
+ # - local: chapter1/6
+ # title: Transformer Architectures
+ # - local: chapter1/7
+ # title: Quick quiz
+ # - local: chapter1/8
+ # title: Inference with LLMs
+ - local: chapter1/9
+ title: ಪಕ್ಷಪಾತ ಮತ್ತು ಮಿತಿಗಳು
+ - local: chapter1/10
+ title: ಸಾರಾಂಶ
+ - local: chapter1/11
+ title: ಪರೀಕ್ಷೆಯ ಸಮಯ!
+ quiz: 1
+
+- title: 2. ಟ್ರಾನ್ಸ್ಫಾರ್ಮರ್ಗಳನ್ನು 🤗 ಬಳಸುವುದು
+ sections:
+ - local: chapter2/1
+ title: ಪರಿಚಯ
+ - local: chapter2/2
+ title: ಪೈಪ್ಲೈನ್ ಹಿಂದೆ
+ # - local: chapter2/3
+ # title: Models
+ # - local: chapter2/4
+ # title: Tokenizers
+ # - local: chapter2/5
+ # title: Handling multiple sequences
+ # - local: chapter2/6
+ # title: Putting it all together
+ - local: chapter2/7
+ title: ಮೂಲ ಬಳಕೆ ಪೂರ್ಣಗೊಂಡಿದೆ!
+ # - local: chapter2/8
+ # title: Optimized Inference Deployment
+ # - local: chapter2/9
+ # title: End-of-chapter quiz
+ # quiz: 2
diff --git a/chapters/kn/chapter0/1.mdx b/chapters/kn/chapter0/1.mdx
new file mode 100644
index 000000000..331a2da18
--- /dev/null
+++ b/chapters/kn/chapter0/1.mdx
@@ -0,0 +1,110 @@
+# ಪರಿಚಯ[[ಪರಿಚಯ]]
+
+ಹಗ್ಗಿಂಗ್ ಫೇಸ್ ಕೋರ್ಸ್ಗೆ ಸುಸ್ವಾಗತ! .ಈ ಪರಿಚಯವು ಕೆಲಸದ ವಾತಾವರಣವನ್ನು ಹೊಂದಿಸುವ ಬಗ್ಗೆ ನಿಮಗೆ ಮಾರ್ಗದರ್ಶನ ನೀಡುತ್ತದೆ. ನೀವು ಕೋರ್ಸ್ ಅನ್ನು ಪ್ರಾರಂಭಿಸುತ್ತಿದ್ದರೆ, ಮೊದಲು [ಅಧ್ಯಾಯ 1](/course/chapter1) ಅನ್ನು ನೋಡಿ, ನಂತರ ಹಿಂತಿರುಗಿ ಮತ್ತು ನಿಮ್ಮ ಪರಿಸರವನ್ನು ಹೊಂದಿಸಿ ಇದರಿಂದ ನೀವು ಕೋಡ್ ಅನ್ನು ನೀವೇ ಪ್ರಯತ್ನಿಸಬಹುದು ಎಂದು ನಾವು ಶಿಫಾರಸು ಮಾಡುತ್ತೇವೆ.
+
+ಈ ಕೋರ್ಸ್ನಲ್ಲಿ ನಾವು ಬಳಸಲಿರುವ ಎಲ್ಲಾ ಲೈಬ್ರರಿಗಳು ಪೈಥಾನ್ ಪ್ಯಾಕೇಜ್ಗಳಾಗಿ ಲಭ್ಯವಿದೆ, ಆದ್ದರಿಂದ ಪೈಥಾನ್ ಪರಿಸರವನ್ನು ಹೇಗೆ ಹೊಂದಿಸುವುದು ಮತ್ತು ನಿಮಗೆ ಅಗತ್ಯವಿರುವ ನಿರ್ದಿಷ್ಟ ಲೈಬ್ರರಿಗಳನ್ನು ಹೇಗೆ ಸ್ಥಾಪಿಸುವುದು ಎಂಬುದನ್ನು ಇಲ್ಲಿ ನಾವು ನಿಮಗೆ ತೋರಿಸುತ್ತೇವೆ.
+
+ಕೊಲಾಬ್ ನೋಟ್ಬುಕ್ ಅಥವಾ ಪೈಥಾನ್ ವರ್ಚುವಲ್ ಪರಿಸರವನ್ನು ಬಳಸಿಕೊಂಡು ನಿಮ್ಮ ಕೆಲಸದ ವಾತಾವರಣವನ್ನು ಹೊಂದಿಸುವ ಎರಡು ವಿಧಾನಗಳನ್ನು ನಾವು ಒಳಗೊಳ್ಳುತ್ತೇವೆ. ನಿಮಗೆ ಹೆಚ್ಚು ಇಷ್ಟವಾಗುವದನ್ನು ಆಯ್ಕೆ ಮಾಡಲು ಹಿಂಜರಿಯಬೇಡಿ. ಆರಂಭಿಕರಿಗಾಗಿ, ಕೊಲಾಬ್ ನೋಟ್ಬುಕ್ ಬಳಸುವ ಮೂಲಕ ಪ್ರಾರಂಭಿಸಲು ನಾವು ಬಲವಾಗಿ ಶಿಫಾರಸು ಮಾಡುತ್ತೇವೆ.
+
+ನಾವು ವಿಂಡೋಸ್ ಸಿಸ್ಟಮ್ ಅನ್ನು ಒಳಗೊಳ್ಳುವುದಿಲ್ಲ ಎಂಬುದನ್ನು ಗಮನಿಸಿ. ನೀವು ವಿಂಡೋಸ್ನಲ್ಲಿ ಓಡುತ್ತಿದ್ದರೆ, ಕೊಲಾಬ್ ನೋಟ್ಬುಕ್ ಅನ್ನು ಬಳಸಲು ನಾವು ಶಿಫಾರಸು ಮಾಡುತ್ತೇವೆ. ನೀವು ಲಿನಕ್ಸ್ ವಿತರಣೆ ಅಥವಾ ಮ್ಯಾಕ್ಓಎಸ್ಅನ್ನು ಬಳಸುತ್ತಿದ್ದರೆ, ಇಲ್ಲಿ ವಿವರಿಸಿದ ಯಾವುದೇ ವಿಧಾನವನ್ನು ನೀವು ಬಳಸಬಹುದು.
+
+ಹೆಚ್ಚಿನ ಕೋರ್ಸ್ ನೀವು ಹಗ್ಗಿಂಗ್ ಫೇಸ್ ಖಾತೆಯನ್ನು ಹೊಂದಿರುವುದರ ಮೇಲೆ ಅವಲಂಬಿತವಾಗಿದೆ. ಈಗಲೇ ಒಂದನ್ನು ರಚಿಸಲು ನಾವು ಶಿಫಾರಸು ಮಾಡುತ್ತೇವೆ: [ಖಾತೆಯನ್ನು ರಚಿಸಿ](https://huggingface.co/join).
+
+## ಗೂಗಲ್ ಕೊಲಾಬ್ ನೋಟ್ಬುಕ್ ಬಳಸುವುದು[[ಗೂಗಲ್ ಕೊಲಾಬ್ ನೋಟ್ಬುಕ್ ಬಳಸುವುದು]]
+
+ಕೊಲಾಬ್ ನೋಟ್ಬುಕ್ ಬಳಸುವುದು ಸಾಧ್ಯವಾದಷ್ಟು ಸರಳವಾದ ಸೆಟಪ್ ಆಗಿದೆ; ನಿಮ್ಮ ಬ್ರೌಸರ್ನಲ್ಲಿ ನೋಟ್ಬುಕ್ ಅನ್ನು ಬೂಟ್ ಮಾಡಿ ಮತ್ತು ನೇರವಾಗಿ ಕೋಡಿಂಗ್ಗೆ ಹೋಗಿ!
+
+ನಿಮಗೆ ಕೊಲಾಬ್ ಪರಿಚಯವಿಲ್ಲದಿದ್ದರೆ, [ಪರಿಚಯವನ್ನು](https://colab.research.google.com/notebooks/intro.ipynb) ಅನುಸರಿಸುವ ಮೂಲಕ ಪ್ರಾರಂಭಿಸಲು ನಾವು ಶಿಫಾರಸು ಮಾಡುತ್ತೇವೆ. ಕೊಲಾಬ್ ನಿಮಗೆ GPU ಗಳು ಅಥವಾ TPU ಗಳಂತಹ ಕೆಲವು ವೇಗವರ್ಧಕ ಹಾರ್ಡ್ವೇರ್ ಅನ್ನು ಬಳಸಲು ಅನುಮತಿಸುತ್ತದೆ ಮತ್ತು ಇದು ಸಣ್ಣ ಕೆಲಸದ ಹೊರೆಗಳಿಗೆ ಉಚಿತವಾಗಿದೆ.
+
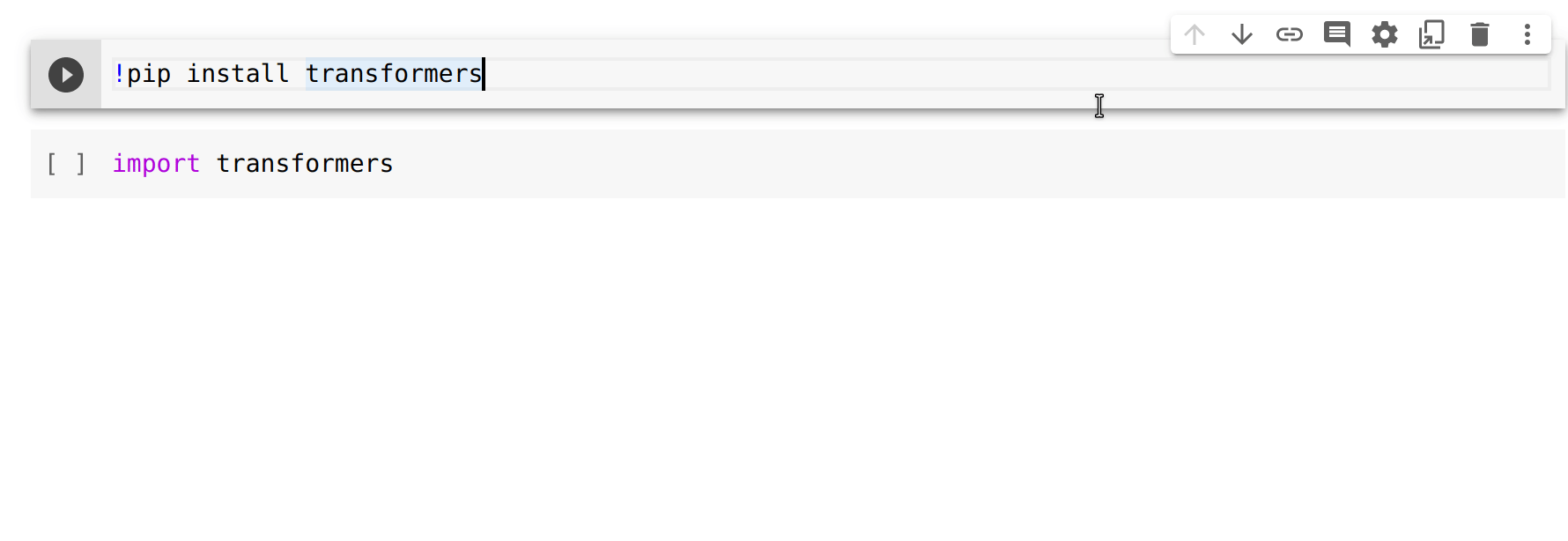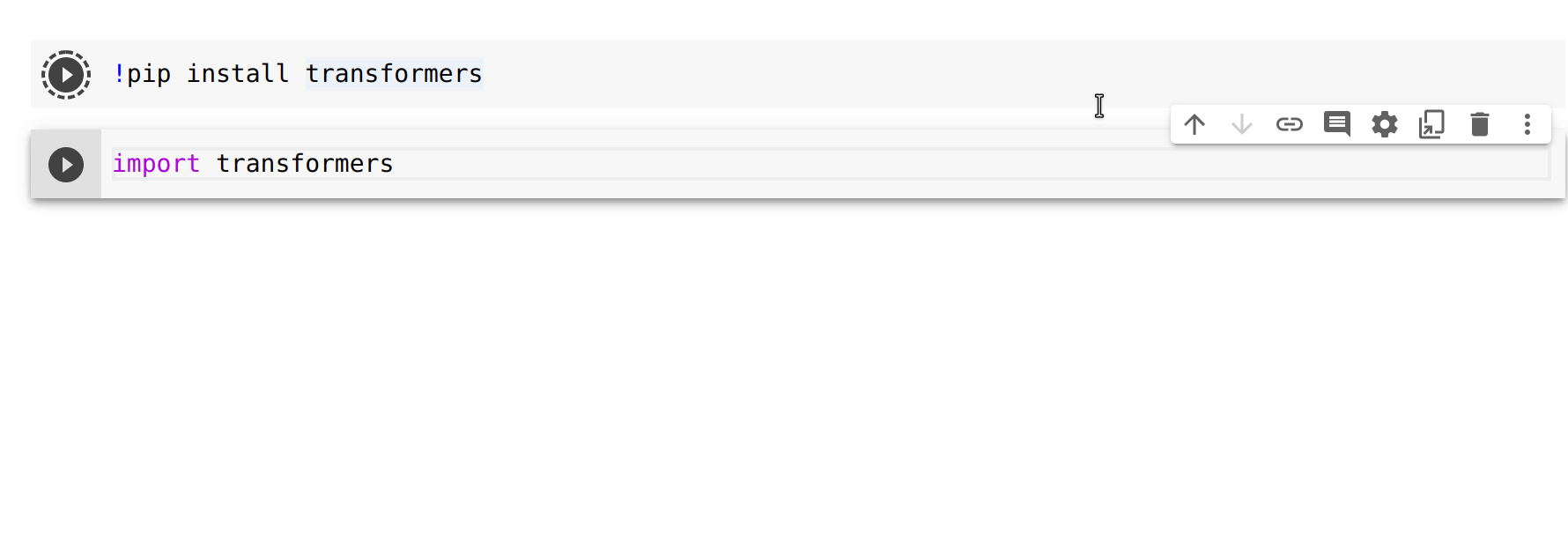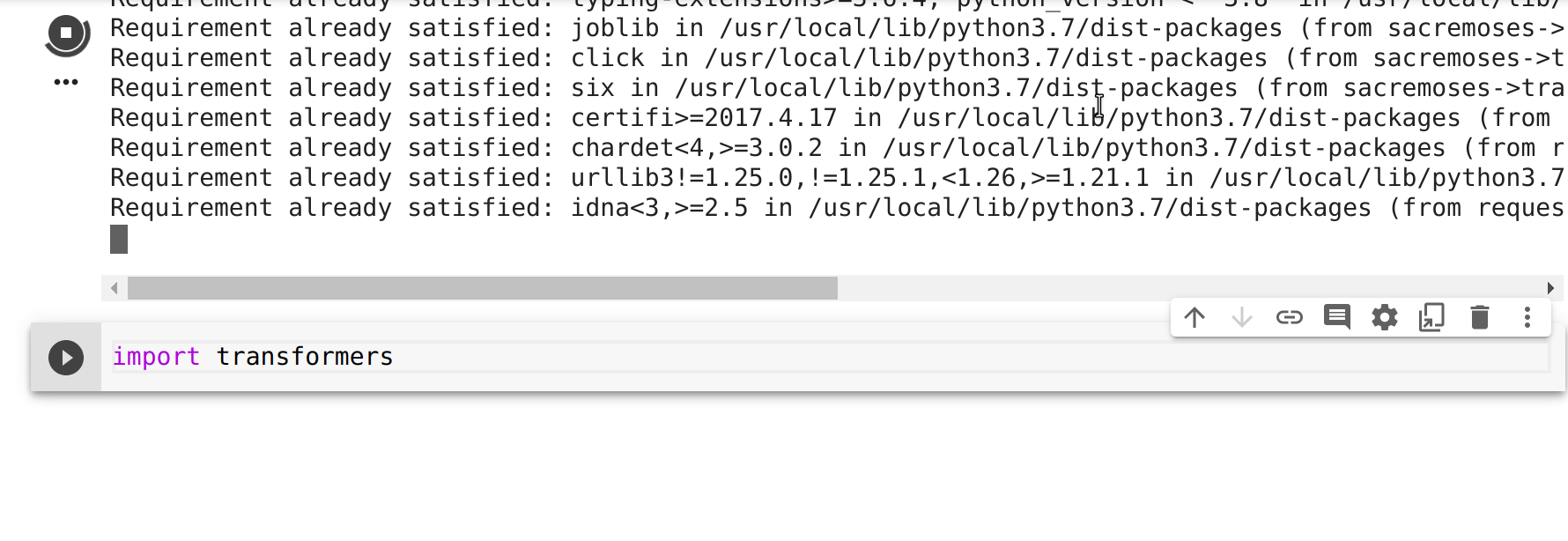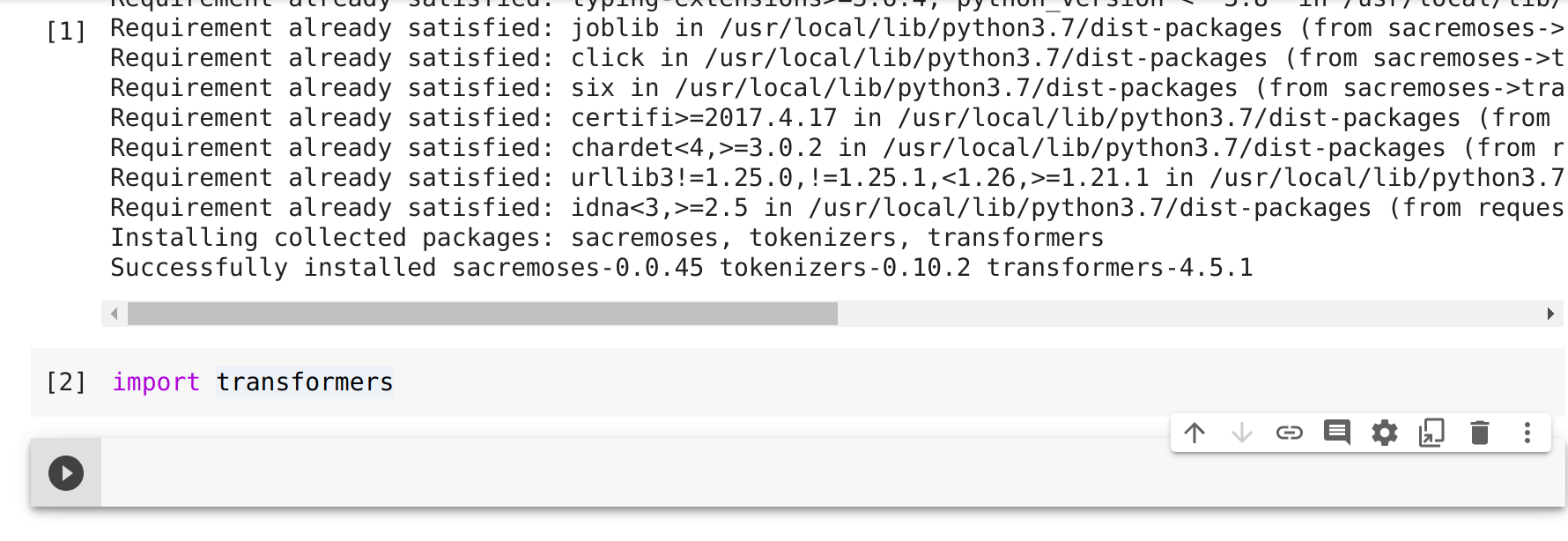
+ಕೊಲಾಬ್ನಲ್ಲಿ ನೀವು ಆರಾಮದಾಯಕವಾಗಿ ಓಡಾಡಲು ಪ್ರಾರಂಭಿಸಿದ ನಂತರ, ಹೊಸ ನೋಟ್ಬುಕ್ ರಚಿಸಿ ಮತ್ತು ಸೆಟಪ್ನೊಂದಿಗೆ ಪ್ರಾರಂಭಿಸಿ:
+
+
+
+
+
+
+

+

+
+

+

+