-
Notifications
You must be signed in to change notification settings - Fork 2.3k
Expand file tree
/
Copy pathgailan.md
More file actions
767 lines (561 loc) · 27.3 KB
/
gailan.md
File metadata and controls
767 lines (561 loc) · 27.3 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
---
title: Java集合框架全面解析
shortTitle: List、Set、Queue和Map
category:
- Java核心
tag:
- 集合框架(容器)
description: 本文为您提供一个全面的 Java 集合框架概览,详细介绍了集合框架的构成、各种集合类的功能与应用场景。学习本文将帮助您更好地理解和使用 Java 集合框架,提高编程效率。
head:
- - meta
- name: keywords
content: Java,集合框架,容器,java 集合框架,java集合,java容器, List, Set, Map, 队列
---
眼瞅着三妹的王者荣耀杀得正嗨,我趁机喊到:“别打了,三妹,我们来一起学习 Java 的集合框架吧。”
“才不要呢,等我打完这一局啊。”三妹倔强地说。
“好吧。”我只好摊摊手地说,“那我先画张集合框架的结构图等着你。”
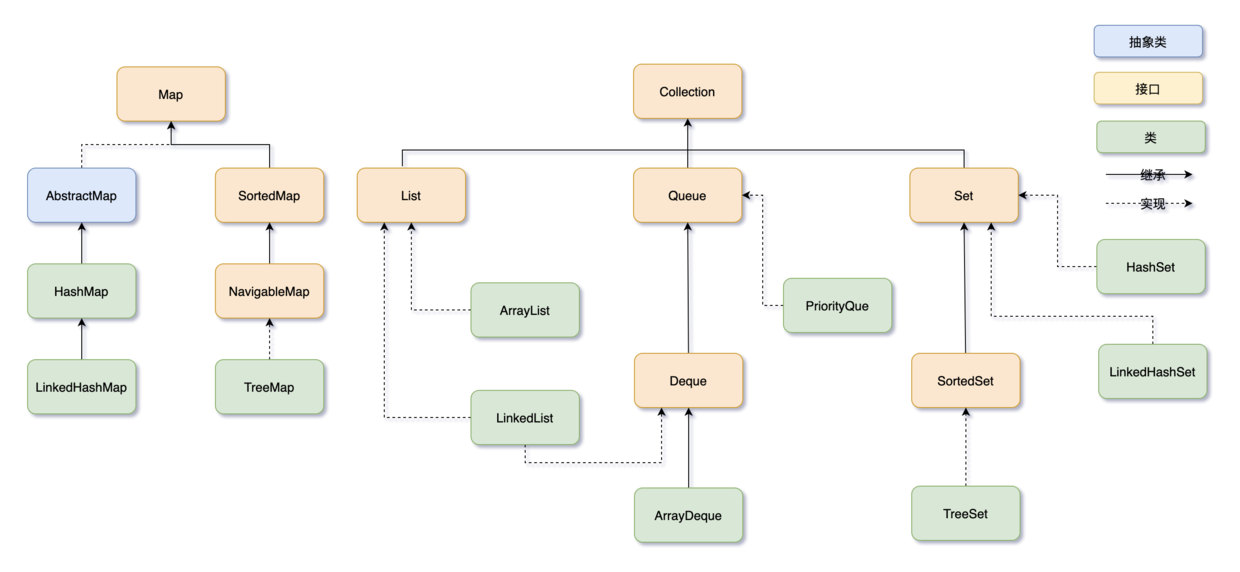
“完了没?三妹。”
“完了好一会儿了,二哥,你图画得真慢,让我瞧瞧怎么样?”
“害,图要画得清晰明了,不容易的。三妹,你瞧,不错吧。”
“哇,果然很棒,哥,你可真认真!”
“我来简单介绍一下吧。”
Java 集合框架可以分为两条大的支线:
①、Collection,主要由 List、Set、Queue 组成:
- List 代表有序、可重复的集合,典型代表就是封装了动态数组的 [ArrayList](https://javabetter.cn/collection/arraylist.html) 和封装了链表的 [LinkedList](https://javabetter.cn/collection/linkedlist.html);
- Set 代表无序、不可重复的集合,典型代表就是 HashSet 和 TreeSet;
- Queue 代表队列,典型代表就是双端队列 [ArrayDeque](https://javabetter.cn/collection/arraydeque.html),以及优先级队列 [PriorityQueue](https://javabetter.cn/collection/PriorityQueue.html)。
②、Map,代表键值对的集合,典型代表就是 [HashMap](https://javabetter.cn/collection/hashmap.html)。
### 01、List
List 的特点是存取有序,可以存放重复的元素,可以用下标对元素进行操作。
#### **1)ArrayList**
先来一段 ArrayList 的增删改查,学会用。
```java
// 创建一个集合
ArrayList<String> list = new ArrayList<String>();
// 添加元素
list.add("王二");
list.add("沉默");
list.add("陈清扬");
// 遍历集合 for 循环
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
// 遍历集合 for each
for (String s : list) {
System.out.println(s);
}
// 删除元素
list.remove(1);
// 遍历集合
for (String s : list) {
System.out.println(s);
}
// 修改元素
list.set(1, "王二狗");
// 遍历集合
for (String s : list) {
System.out.println(s);
}
```
简单介绍一下 ArrayList 的特征,[后面还会详细讲](https://javabetter.cn/collection/arraylist.html)。
- ArrayList 是由数组实现的,支持随机存取,也就是可以通过下标直接存取元素;
- 从尾部插入和删除元素会比较快捷,从中间插入和删除元素会比较低效,因为涉及到数组元素的复制和移动;
- 如果内部数组的容量不足时会自动扩容,因此当元素非常庞大的时候,效率会比较低。
#### **2)LinkedList**
同样先来一段 LinkedList 的增删改查,和 ArrayList 几乎没什么差别。
```java
// 创建一个集合
LinkedList<String> list = new LinkedList<String>();
// 添加元素
list.add("王二");
list.add("沉默");
list.add("陈清扬");
// 遍历集合 for 循环
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
// 遍历集合 for each
for (String s : list) {
System.out.println(s);
}
// 删除元素
list.remove(1);
// 遍历集合
for (String s : list) {
System.out.println(s);
}
// 修改元素
list.set(1, "王二狗");
// 遍历集合
for (String s : list) {
System.out.println(s);
}
```
不过,LinkedList 和 ArrayList 仍然有较大的不同,[后面也会详细地讲](https://javabetter.cn/collection/linkedlist.html)。
- LinkedList 是由双向链表实现的,不支持随机存取,只能从一端开始遍历,直到找到需要的元素后返回;
- 任意位置插入和删除元素都很方便,因为只需要改变前一个节点和后一个节点的引用即可,不像 ArrayList 那样需要复制和移动数组元素;
- 因为每个元素都存储了前一个和后一个节点的引用,所以相对来说,占用的内存空间会比 ArrayList 多一些。
#### **3)Vector 和 Stack**
List 的实现类还有一个 Vector,是一个元老级的类,比 ArrayList 出现得更早。ArrayList 和 Vector 非常相似,只不过 Vector 是线程安全的,像 get、set、add 这些方法都加了 `synchronized` 关键字,就导致执行效率会比较低,所以现在已经很少用了。
我就不写太多代码了,只看一下 add 方法的源码就明白了。
```java
public synchronized boolean add(E e) {
elementData[elementCount++] = e;
return true;
}
```
这种加了同步方法的类,注定会被淘汰掉,就像[StringBuilder 取代 StringBuffer](https://javabetter.cn/string/builder-buffer.html)那样。JDK 源码也说了:
> 如果不需要线程安全,建议使用 ArrayList 代替 Vector。
Stack 是 Vector 的一个子类,本质上也是由动态数组实现的,只不过还实现了先进后出的功能(在 get、set、add 方法的基础上追加了 pop「返回并移除栈顶的元素」、peek「只返回栈顶元素」等方法),所以叫栈。
下面是这两个方法的源码,增删改查我就不写了,和 ArrayList 和 LinkedList 几乎一样。
```java
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
```
不过,由于 Stack 执行效率比较低(方法上同样加了 synchronized 关键字),就被双端队列 ArrayDeque 取代了(下面会介绍)。
### 02、Set
Set 的特点是存取无序,不可以存放重复的元素,不可以用下标对元素进行操作,和 List 有很多不同。
#### 1)HashSet
HashSet 其实是由 HashMap 实现的,只不过值由一个固定的 Object 对象填充,而键用于操作。来简单看一下它的源码。
```java
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
}
```
实际开发中,HashSet 并不常用,比如,如果我们需要按照顺序存储一组元素,那么 ArrayList 和 LinkedList 可能更适合;如果我们需要存储键值对并根据键进行查找,那么 HashMap 可能更适合。
来一段增删改查体验一下:
```java
// 创建一个新的HashSet
HashSet<String> set = new HashSet<>();
// 添加元素
set.add("沉默");
set.add("王二");
set.add("陈清扬");
// 输出HashSet的元素个数
System.out.println("HashSet size: " + set.size()); // output: 3
// 判断元素是否存在于HashSet中
boolean containsWanger = set.contains("王二");
System.out.println("Does set contain '王二'? " + containsWanger); // output: true
// 删除元素
boolean removeWanger = set.remove("王二");
System.out.println("Removed '王二'? " + removeWanger); // output: true
// 修改元素,需要先删除后添加
boolean removeChenmo = set.remove("沉默");
boolean addBuChenmo = set.add("不沉默");
System.out.println("Modified set? " + (removeChenmo && addBuChenmo)); // output: true
// 输出修改后的HashSet
System.out.println("HashSet after modification: " + set); // output: [陈清扬, 不沉默]
```
HashSet 主要用于去重,比如,我们需要统计一篇文章中有多少个不重复的单词,就可以使用 HashSet 来实现。
```java
// 创建一个 HashSet 对象
HashSet<String> set = new HashSet<>();
// 添加元素
set.add("沉默");
set.add("王二");
set.add("陈清扬");
set.add("沉默");
// 输出 HashSet 的元素个数
System.out.println("HashSet size: " + set.size()); // output: 3
// 遍历 HashSet
for (String s : set) {
System.out.println(s);
}
```
从上面的例子可以看得出,HashSet 会自动去重,因为它是用 HashMap 实现的,[HashMap](https://javabetter.cn/collection/hashmap.html) 的键是唯一的(哈希值),相同键的值会覆盖掉原来的值,于是第二次 `set.add("沉默")` 的时候就覆盖了第一次的 `set.add("沉默")`。
我在《[LeetCode 的第 15 题:三数之和](https://paicoding.com/column/7/15)》的时候用到了 HashSet,大家可以通过链接去查看一下。
#### 2)LinkedHashSet
LinkedHashSet 虽然继承自 HashSet,其实是由 [LinkedHashMap](https://javabetter.cn/collection/linkedhashmap.html) 实现的。
这是 LinkedHashSet 的无参构造方法:
```java
public LinkedHashSet() {
super(16, .75f, true);
}
```
[super](https://javabetter.cn/oo/this-super.html) 的意思是它将调用父类的 HashSet 的一个有参构造方法:
```java
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
```
看到 [LinkedHashMap](https://javabetter.cn/collection/linkedhashmap.html) 了吧,这个我们后面会去讲。
好吧,来看一段 LinkedHashSet 的增删改查吧。
```java
LinkedHashSet<String> set = new LinkedHashSet<>();
// 添加元素
set.add("沉默");
set.add("王二");
set.add("陈清扬");
// 删除元素
set.remove("王二");
// 修改元素
set.remove("沉默");
set.add("沉默的力量");
// 查找元素
boolean hasChenQingYang = set.contains("陈清扬");
System.out.println("set包含陈清扬吗?" + hasChenQingYang);
```
在以上代码中,我们首先创建了一个 LinkedHashSet 对象,然后使用 add 方法依次添加了三个元素:沉默、王二和陈清扬。接着,我们使用 remove 方法删除了王二这个元素,并使用 remove 和 add 方法修改了沉默这个元素。最后,我们使用 contains 方法查找了陈清扬这个元素是否存在于 set 中,并打印了结果。
LinkedHashSet 是一种基于哈希表实现的 Set 接口,它继承自 HashSet,并且使用链表维护了元素的插入顺序。因此,它既具有 HashSet 的快速查找、插入和删除操作的优点,又可以维护元素的插入顺序。
#### 3)TreeSet
“二哥,不用你讲了,我能猜到,TreeSet 是由 [TreeMap(后面会讲)](https://javabetter.cn/collection/treemap.html) 实现的,只不过同样操作的键位,值由一个固定的 Object 对象填充。”
哇,三妹都学会了推理。
是的,与 TreeMap 相似,TreeSet 是一种基于红黑树实现的有序集合,它实现了 SortedSet 接口,可以自动对集合中的元素进行排序。按照键的自然顺序或指定的比较器顺序进行排序。
```java
// 创建一个 TreeSet 对象
TreeSet<String> set = new TreeSet<>();
// 添加元素
set.add("沉默");
set.add("王二");
set.add("陈清扬");
System.out.println(set); // 输出 [沉默, 王二, 陈清扬]
// 删除元素
set.remove("王二");
System.out.println(set); // 输出 [沉默, 陈清扬]
// 修改元素:TreeSet 中的元素不支持直接修改,需要先删除再添加
set.remove("陈清扬");
set.add("陈青阳");
System.out.println(set); // 输出 [沉默, 陈青阳]
// 查找元素
System.out.println(set.contains("沉默")); // 输出 true
System.out.println(set.contains("王二")); // 输出 false
```
需要注意的是,TreeSet 不允许插入 null 元素,否则会抛出 NullPointerException 异常。
“总体上来说,Set 集合不是关注的重点,因为底层都是由 Map 实现的,为什么要用 Map 实现呢?三妹你能猜到原因吗?”
“让我想想。”
“嗯?难道是因为 Map 的键不允许重复、无序吗?”
老天,竟然被三妹猜到了。
“是的,你这水平长进了呀,三妹。”
### 03、Queue
Queue,也就是队列,通常遵循先进先出(FIFO)的原则,新元素插入到队列的尾部,访问元素返回队列的头部。
#### 1)ArrayDeque
从名字上可以看得出,ArrayDeque 是一个基于数组实现的双端队列,为了满足可以同时在数组两端插入或删除元素的需求,数组必须是循环的,也就是说数组的任何一点都可以被看作是起点或者终点。
这是一个包含了 4 个元素的双端队列,和一个包含了 5 个元素的双端队列。
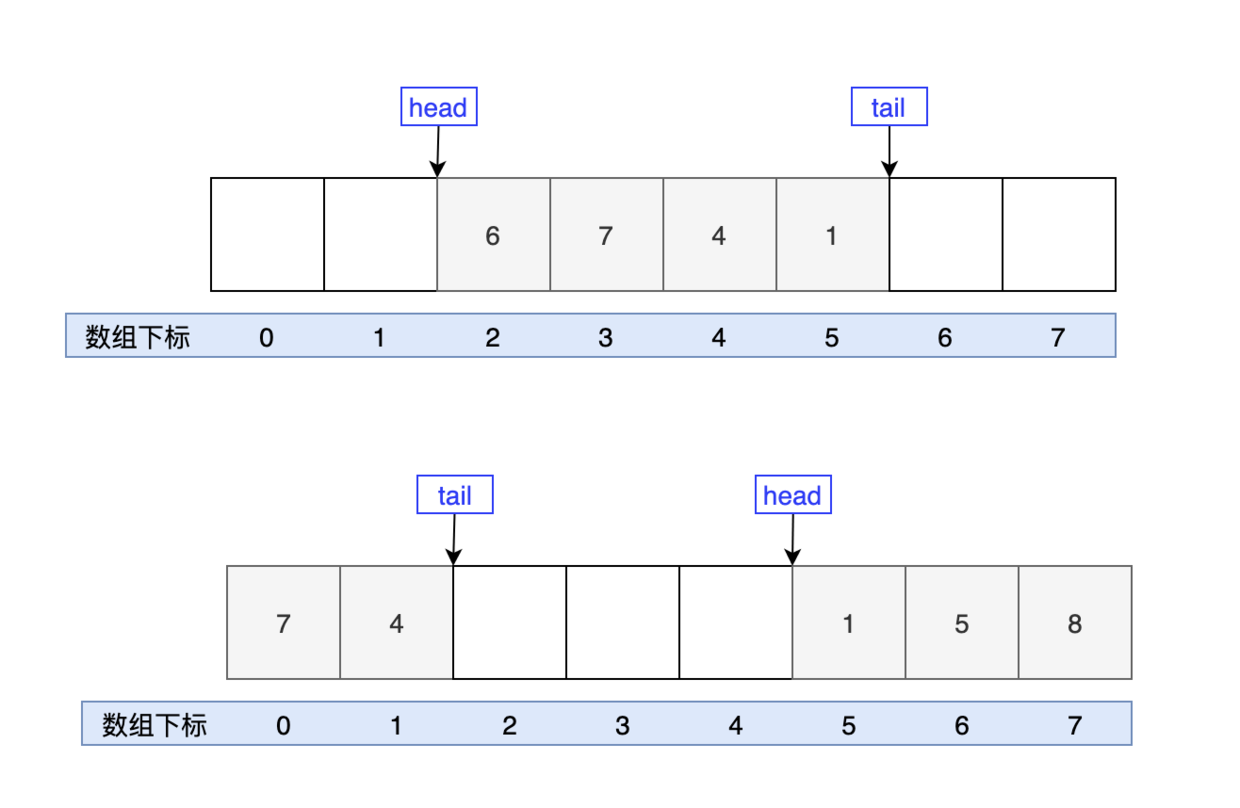
head 指向队首的第一个有效的元素,tail 指向队尾第一个可以插入元素的空位,因为是循环数组,所以 head 不一定从是从 0 开始,tail 也不一定总是比 head 大。
来一段 ArrayDeque 的增删改查吧。
```java
// 创建一个ArrayDeque
ArrayDeque<String> deque = new ArrayDeque<>();
// 添加元素
deque.add("沉默");
deque.add("王二");
deque.add("陈清扬");
// 删除元素
deque.remove("王二");
// 修改元素
deque.remove("沉默");
deque.add("沉默的力量");
// 查找元素
boolean hasChenQingYang = deque.contains("陈清扬");
System.out.println("deque包含陈清扬吗?" + hasChenQingYang);
```
#### 2)LinkedList
LinkedList 一般应该归在 List 下,只不过,它也实现了 Deque 接口,可以作为队列来使用。等于说,LinkedList 同时实现了 Stack、Queue、PriorityQueue 的所有功能。
```java
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{}
```
换句话说,LinkedList 和 ArrayDeque 都是 Java 集合框架中的双向队列(deque),它们都支持在队列的两端进行元素的插入和删除操作。不过,LinkedList 和 ArrayDeque 在实现上有一些不同:
- 底层实现方式不同:LinkedList 是基于链表实现的,而 ArrayDeque 是基于数组实现的。
- 随机访问的效率不同:由于底层实现方式的不同,LinkedList 对于随机访问的效率较低,时间复杂度为 O(n),而 ArrayDeque 可以通过下标随机访问元素,时间复杂度为 O(1)。
- 迭代器的效率不同:LinkedList 对于迭代器的效率比较低,因为需要通过链表进行遍历,时间复杂度为 O(n),而 ArrayDeque 的迭代器效率比较高,因为可以直接访问数组中的元素,时间复杂度为 O(1)。
- 内存占用不同:由于 LinkedList 是基于链表实现的,它在存储元素时需要额外的空间来存储链表节点,因此内存占用相对较高,而 ArrayDeque 是基于数组实现的,内存占用相对较低。
因此,在选择使用 LinkedList 还是 ArrayDeque 时,需要根据具体的业务场景和需求来选择。如果需要在双向队列的两端进行频繁的插入和删除操作,并且需要随机访问元素,可以考虑使用 ArrayDeque;如果需要在队列中间进行频繁的插入和删除操作,可以考虑使用 LinkedList。
来一段 LinkedList 作为队列时候的增删改查吧,注意和它作为 List 的时候有很大的不同。
```java
// 创建一个 LinkedList 对象
LinkedList<String> queue = new LinkedList<>();
// 添加元素
queue.offer("沉默");
queue.offer("王二");
queue.offer("陈清扬");
System.out.println(queue); // 输出 [沉默, 王二, 陈清扬]
// 删除元素
queue.poll();
System.out.println(queue); // 输出 [王二, 陈清扬]
// 修改元素:LinkedList 中的元素不支持直接修改,需要先删除再添加
String first = queue.poll();
queue.offer("王大二");
System.out.println(queue); // 输出 [陈清扬, 王大二]
// 查找元素:LinkedList 中的元素可以使用 get() 方法进行查找
System.out.println(queue.get(0)); // 输出 陈清扬
System.out.println(queue.contains("沉默")); // 输出 false
// 查找元素:使用迭代器的方式查找陈清扬
// 使用迭代器依次遍历元素并查找
Iterator<String> iterator = queue.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (element.equals("陈清扬")) {
System.out.println("找到了:" + element);
break;
}
}
```
在使用 LinkedList 作为队列时,可以使用 offer() 方法将元素添加到队列的末尾,使用 poll() 方法从队列的头部删除元素。另外,由于 LinkedList 是链表结构,不支持随机访问元素,因此不能使用下标访问元素,需要使用迭代器或者 poll() 方法依次遍历元素。
#### 3)PriorityQueue
PriorityQueue 是一种优先级队列,它的出队顺序与元素的优先级有关,执行 remove 或者 poll 方法,返回的总是优先级最高的元素。
```java
// 创建一个 PriorityQueue 对象
PriorityQueue<String> queue = new PriorityQueue<>();
// 添加元素
queue.offer("沉默");
queue.offer("王二");
queue.offer("陈清扬");
System.out.println(queue); // 输出 [沉默, 王二, 陈清扬]
// 删除元素
queue.poll();
System.out.println(queue); // 输出 [王二, 陈清扬]
// 修改元素:PriorityQueue 不支持直接修改元素,需要先删除再添加
String first = queue.poll();
queue.offer("张三");
System.out.println(queue); // 输出 [张三, 陈清扬]
// 查找元素:PriorityQueue 不支持随机访问元素,只能访问队首元素
System.out.println(queue.peek()); // 输出 张三
System.out.println(queue.contains("陈清扬")); // 输出 true
// 通过 for 循环的方式查找陈清扬
for (String element : queue) {
if (element.equals("陈清扬")) {
System.out.println("找到了:" + element);
break;
}
}
```
要想有优先级,元素就需要实现 [Comparable 接口或者 Comparator 接口](https://javabetter.cn/basic-extra-meal/comparable-omparator.html)(我们后面会讲)。
这里先来一段通过实现 Comparator 接口按照年龄姓名排序的优先级队列吧。
```java
import java.util.Comparator;
import java.util.PriorityQueue;
class Student {
private String name;
private int chineseScore;
private int mathScore;
public Student(String name, int chineseScore, int mathScore) {
this.name = name;
this.chineseScore = chineseScore;
this.mathScore = mathScore;
}
public String getName() {
return name;
}
public int getChineseScore() {
return chineseScore;
}
public int getMathScore() {
return mathScore;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", 总成绩=" + (chineseScore + mathScore) +
'}';
}
}
class StudentComparator implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
// 比较总成绩
return Integer.compare(s2.getChineseScore() + s2.getMathScore(),
s1.getChineseScore() + s1.getMathScore());
}
}
public class PriorityQueueComparatorExample {
public static void main(String[] args) {
// 创建一个按照总成绩排序的优先级队列
PriorityQueue<Student> queue = new PriorityQueue<>(new StudentComparator());
// 添加元素
queue.offer(new Student("王二", 80, 90));
System.out.println(queue);
queue.offer(new Student("陈清扬", 95, 95));
System.out.println(queue);
queue.offer(new Student("小驼铃", 90, 95));
System.out.println(queue);
queue.offer(new Student("沉默", 90, 80));
while (!queue.isEmpty()) {
System.out.print(queue.poll() + " ");
}
}
}
```
Student 是一个学生对象,包含姓名、语文成绩和数学成绩。
StudentComparator 实现了 Comparator 接口,对总成绩做了一个排序。
PriorityQueue 是一个优先级队列,参数为 StudentComparator,然后我们添加了 4 个学生对象进去。
来看一下输出结果:
```
[Student{name='王二', 总成绩=170}]
[Student{name='陈清扬', 总成绩=190}, Student{name='王二', 总成绩=170}]
[Student{name='陈清扬', 总成绩=190}, Student{name='王二', 总成绩=170}, Student{name='小驼铃', 总成绩=185}]
Student{name='陈清扬', 总成绩=190} Student{name='小驼铃', 总成绩=185} Student{name='沉默', 总成绩=170} Student{name='王二', 总成绩=170}
```
我们使用 offer 方法添加元素,最后用 while 循环遍历元素(通过 poll 方法取出元素),从结果可以看得出,[PriorityQueue](https://javabetter.cn/collection/PriorityQueue.html)按照学生的总成绩由高到低进行了排序。
### 04、Map
Map 保存的是键值对,键要求保持唯一性,值可以重复。
#### 1)HashMap
HashMap 实现了 Map 接口,可以根据键快速地查找对应的值——通过哈希函数将键映射到哈希表中的一个索引位置,从而实现快速访问。[后面会详细聊到](https://javabetter.cn/collection/hashmap.html)。
这里先大致了解一下 HashMap 的特点:
- HashMap 中的键和值都可以为 null。如果键为 null,则将该键映射到哈希表的第一个位置。
- 可以使用迭代器或者 forEach 方法遍历 HashMap 中的键值对。
- HashMap 有一个初始容量和一个负载因子。初始容量是指哈希表的初始大小,负载因子是指哈希表在扩容之前可以存储的键值对数量与哈希表大小的比率。默认的初始容量是 16,负载因子是 0.75。
来个简单的增删改查吧。
```java
// 创建一个 HashMap 对象
HashMap<String, String> hashMap = new HashMap<>();
// 添加键值对
hashMap.put("沉默", "cenzhong");
hashMap.put("王二", "wanger");
hashMap.put("陈清扬", "chenqingyang");
// 获取指定键的值
String value1 = hashMap.get("沉默");
System.out.println("沉默对应的值为:" + value1);
// 修改键对应的值
hashMap.put("沉默", "chenmo");
String value2 = hashMap.get("沉默");
System.out.println("修改后沉默对应的值为:" + value2);
// 删除指定键的键值对
hashMap.remove("王二");
// 遍历 HashMap
for (String key : hashMap.keySet()) {
String value = hashMap.get(key);
System.out.println(key + " 对应的值为:" + value);
}
```
#### 2)LinkedHashMap
HashMap 已经非常强大了,但它是无序的。如果我们需要一个有序的 Map,就要用到 [LinkedHashMap](https://javabetter.cn/collection/linkedhashmap.html)。LinkedHashMap 是 HashMap 的子类,它使用链表来记录插入/访问元素的顺序。
LinkedHashMap 可以看作是 HashMap + LinkedList 的合体,它使用了哈希表来存储数据,又用了双向链表来维持顺序。
来一个简单的例子。
```java
// 创建一个 LinkedHashMap,插入的键值对为 沉默 王二 陈清扬
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("沉默", "cenzhong");
linkedHashMap.put("王二", "wanger");
linkedHashMap.put("陈清扬", "chenqingyang");
// 遍历 LinkedHashMap
for (String key : linkedHashMap.keySet()) {
String value = linkedHashMap.get(key);
System.out.println(key + " 对应的值为:" + value);
}
```
来看输出结果:
```
沉默 对应的值为:cenzhong
王二 对应的值为:wanger
陈清扬 对应的值为:chenqingyang
```
从结果中可以看得出来,LinkedHashMap 维持了键值对的插入顺序,对吧?为了和 LinkedHashMap 做对比,我们用同样的数据试验一下 HashMap。
```java
// 创建一个HashMap,插入的键值对为 沉默 王二 陈清扬
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("沉默", "cenzhong");
hashMap.put("王二", "wanger");
hashMap.put("陈清扬", "chenqingyang");
// 遍历 HashMap
for (String key : hashMap.keySet()) {
String value = hashMap.get(key);
System.out.println(key + " 对应的值为:" + value);
}
```
来看输出结果:
```
沉默 对应的值为:cenzhong
陈清扬 对应的值为:chenqingyang
王二 对应的值为:wanger
```
HashMap 没有维持键值对的插入顺序,对吧?
#### 3)TreeMap
[TreeMap](https://javabetter.cn/collection/treemap.html) 实现了 SortedMap 接口,可以自动将键按照自然顺序或指定的比较器顺序排序,并保证其元素的顺序。内部使用红黑树来实现键的排序和查找。
同样来一个增删改查的 demo:
```java
// 创建一个 TreeMap 对象
Map<String, String> treeMap = new TreeMap<>();
// 向 TreeMap 中添加键值对
treeMap.put("沉默", "cenzhong");
treeMap.put("王二", "wanger");
treeMap.put("陈清扬", "chenqingyang");
// 查找键值对
String name = "沉默";
if (treeMap.containsKey(name)) {
System.out.println("找到了 " + name + ": " + treeMap.get(name));
} else {
System.out.println("没有找到 " + name);
}
// 修改键值对
name = "王二";
if (treeMap.containsKey(name)) {
System.out.println("修改前的 " + name + ": " + treeMap.get(name));
treeMap.put(name, "newWanger");
System.out.println("修改后的 " + name + ": " + treeMap.get(name));
} else {
System.out.println("没有找到 " + name);
}
// 删除键值对
name = "陈清扬";
if (treeMap.containsKey(name)) {
System.out.println("删除前的 " + name + ": " + treeMap.get(name));
treeMap.remove(name);
System.out.println("删除后的 " + name + ": " + treeMap.get(name));
} else {
System.out.println("没有找到 " + name);
}
// 遍历 TreeMap
for (Map.Entry<String, String> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
```
与 HashMap 不同的是,TreeMap 会按照键的顺序来进行排序。
```java
// 创建一个 TreeMap 对象
Map<String, String> treeMap = new TreeMap<>();
// 向 TreeMap 中添加键值对
treeMap.put("c", "cat");
treeMap.put("a", "apple");
treeMap.put("b", "banana");
// 遍历 TreeMap
for (Map.Entry<String, String> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
```
来看输出结果:
```
a: apple
b: banana
c: cat
```
默认情况下,已经按照键的自然顺序排过了。
“好了,三妹,关于集合框架,我们就先聊到这,随后我们会针对常用的容器进行详细地讲解,比如说 ArrayList、LinkedList、HashMap 等。”
“哇,二哥,这篇讲的东西可真不少,虽然都是比较基础的,但对于我一个小白来说,还是需要花点时间去消化的。”三妹嘟嘟嘴说到。
---
GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括 Java 基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM 等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
