-
Notifications
You must be signed in to change notification settings - Fork 2.3k
Expand file tree
/
Copy pathchar-byte.md
More file actions
252 lines (174 loc) · 14.8 KB
/
char-byte.md
File metadata and controls
252 lines (174 loc) · 14.8 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
---
title: Java 转换流:Java 字节流和字符流的桥梁
shortTitle: 转换流
category:
- Java核心
tag:
- Java IO
description: 本文详细介绍了 Java 转换流在 IO 操作中的重要作用,阐述了其如何有效地将字节流与字符流相互转换。同时,文章还提供了转换流的实际应用示例和常用方法。阅读本文,将帮助您更深入地了解 Java 转换流及其在 Java 编程中的关键地位,提高数据处理的灵活性和效率。
head:
- - meta
- name: keywords
content: Java,Java IO,转换流,InputStreamReader,OutputStreamWriter,乱码,编码,解码,java转换流
---
转换流可以将一个[字节流](https://javabetter.cn/io/stream.html)包装成[字符流](https://javabetter.cn/io/reader-writer.html),或者将一个字符流包装成字节流。这种转换通常用于处理文本数据,如读取文本文件或将数据从网络传输到应用程序。
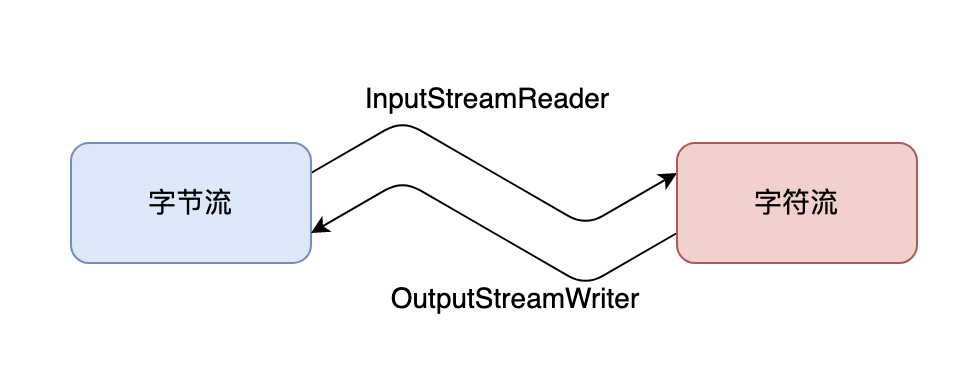
转换流主要有两种类型:InputStreamReader 和 OutputStreamWriter。
InputStreamReader 将一个字节输入流转换为一个字符输入流,而 OutputStreamWriter 将一个字节输出流转换为一个字符输出流。它们使用指定的字符集将字节流和字符流之间进行转换。常用的字符集包括 UTF-8、GBK、ISO-8859-1 等。
### 01、编码和解码
在计算机中,数据通常以二进制形式存储和传输。
- 编码就是将原始数据(比如说文本、图像、视频、音频等)转换为二进制形式。
- 解码就是将二进制数据转换为原始数据,是一个反向的过程。
常见的编码和解码方式有很多,举几个例子:
- ASCII 编码和解码:在计算机中,常常使用 ASCII 码来表示字符,如键盘上的字母、数字和符号等。例如,字母 A 对应的 ASCII 码是 65,字符 + 对应的 ASCII 码是 43。
- Unicode 编码和解码:Unicode 是一种字符集,支持多种语言和字符集。在计算机中,Unicode 可以使用 UTF-8、UTF-16 等编码方式将字符转换为二进制数据进行存储和传输。
- Base64 编码和解码:Base64 是一种将二进制数据转换为 ASCII 码的编码方式。它将 3 个字节的二进制数据转换为 4 个 ASCII 字符,以便在网络传输中使用。例如,将字符串 "Hello, world!" 进行 Base64 编码后,得到的结果是 "SGVsbG8sIHdvcmxkIQ=="。
- 图像编码和解码:在图像处理中,常常使用 JPEG、PNG、GIF 等编码方式将图像转换为二进制数据进行存储和传输。在解码时,可以将二进制数据转换为图像,以便显示或处理。
- 视频编码和解码:在视频处理中,常常使用 H.264、AVC、MPEG-4 等编码方式将视频转换为二进制数据进行存储和传输。在解码时,可以将二进制数据转换为视频,以便播放或处理。
简单一点说就是:
- 编码:字符(能看懂的)-->字节(看不懂的)
- 解码:字节(看不懂的)-->字符(能看懂的)
我用代码来表示一下:
```java
String str = "沉默王二";
String charsetName = "UTF-8";
// 编码
byte[] bytes = str.getBytes(Charset.forName(charsetName));
System.out.println("编码: " + bytes);
// 解码
String decodedStr = new String(bytes, Charset.forName(charsetName));
System.out.println("解码: " + decodedStr);
```
在这个示例中,首先定义了一个字符串变量 str 和一个字符集名称 charsetName。然后,使用 `Charset.forName()` 方法获取指定字符集的 Charset 对象。接着,使用字符串的 getBytes() 方法将字符串编码为指定字符集的字节数组。最后,使用 `new String()` 方法将字节数组解码为字符串。
需要注意的是,在编码和解码过程中,要保证使用相同的字符集,以便正确地转换数据。
### 02、字符集
Charset:字符集,是一组字符的集合,每个字符都有一个唯一的编码值,也称为码点。
常见的字符集包括 ASCII、Unicode 和 GBK,而 Unicode 字符集包含了多种编码方式,比如说 UTF-8、UTF-16。
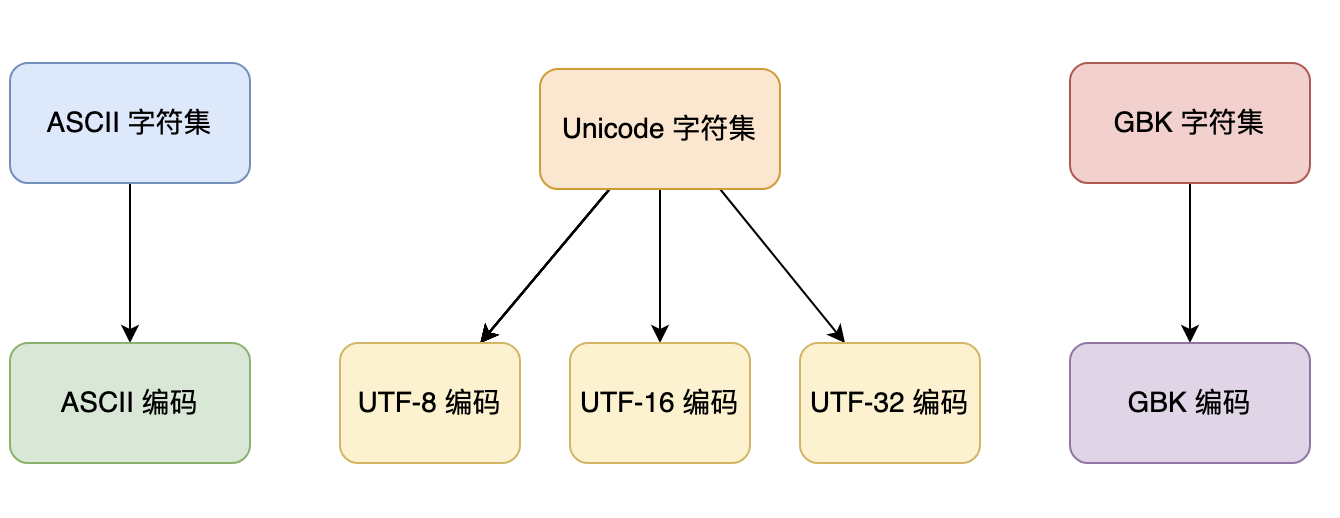
#### **ASCII 字符集**
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)字符集是一种最早的字符集,包含 128 个字符,其中包括控制字符、数字、英文字母以及一些标点符号。ASCII 字符集中的每个字符都有一个唯一的 7 位二进制编码(由 0 和 1 组成),可以表示为十进制数或十六进制数。
ASCII 编码方式是一种固定长度的编码方式,每个字符都使用 7 位二进制编码来表示。ASCII 编码只能表示英文字母、数字和少量的符号,不能表示其他语言的文字和符号,因此在全球范围内的应用受到了很大的限制。
#### Unicode 字符集
Unicode 包含了世界上几乎所有的字符,用于表示人类语言、符号和表情等各种信息。Unicode 字符集中的每个字符都有一个唯一的码点(code point),用于表示该字符在字符集中的位置,可以用十六进制数表示。
为了在计算机中存储和传输 Unicode 字符集中的字符,需要使用一种编码方式。UTF-8、UTF-16 和 UTF-32 都是 Unicode 字符集的编码方式,用于将 Unicode 字符集中的字符转换成字节序列,以便于存储和传输。它们的差别在于使用的字节长度不同。
- UTF-8 是一种可变长度的编码方式,对于 ASCII 字符(码点范围为 `0x00~0x7F`),使用一个字节表示,对于其他 Unicode 字符,使用两个、三个或四个字节表示。UTF-8 编码方式被广泛应用于互联网和计算机领域,因为它可以有效地压缩数据,适用于网络传输和存储。
- UTF-16 是一种固定长度的编码方式,对于基本多语言平面(Basic Multilingual Plane,Unicode 字符集中的一个码位范围,包含了世界上大部分常用的字符,总共包含了超过 65,000 个码位)中的字符(码点范围为 `0x0000~0xFFFF`),使用两个字节表示,对于其他 Unicode 字符,使用四个字节表示。
- UTF-32 是一种固定长度的编码方式,对于所有 Unicode 字符,使用四个字节表示。
#### GBK 字符集
GBK 包含了 GB2312 字符集中的字符,同时还扩展了许多其他汉字字符和符号,共收录了 21,913 个字符。GBK 采用双字节编码方式,每个汉字占用 2 个字节,其中高字节和低字节都使用了 8 位,因此 GBK 编码共有 `2^16=65536` 种可能的编码,其中大部分被用于表示汉字字符。
GBK 编码是一种变长的编码方式,对于 ASCII 字符(码位范围为 0x00 到 0x7F),使用一个字节表示,对于其他字符,使用两个字节表示。GBK 编码中的每个字节都可以采用 0x81 到 0xFE 之间的任意一个值,因此可以表示 `2^15=32768` 个字符。为了避免与 ASCII 码冲突,GBK 编码的第一个字节采用了 0x81 到 0xFE 之间除了 0x7F 的所有值,第二个字节采用了 0x40 到 0x7E 和 0x80 到 0xFE 之间的所有值,共 94 个值。
GB2312 的全名是《信息交换用汉字编码字符集基本集》,也被称为“国标码”。采用了双字节编码方式,每个汉字占用 2 个字节,其中高字节和低字节都使用了 8 位,因此 GB2312 编码共有 `2^16=65536` 种可能的编码,其中大部分被用于表示汉字字符。GB2312 编码中的每个字节都可以采用 0xA1 到 0xF7 之间的任意一个值,因此可以表示 126 个字符。
GB2312 是一个较为简单的字符集,只包含了常用的汉字和符号,因此对于一些较为罕见的汉字和生僻字,GB2312 不能满足需求,现在已经逐渐被 GBK、GB18030 等字符集所取代。
GB18030 是最新的中文码表。收录汉字 70244 个,采用多字节编码,每个字可以由 1 个、2 个或 4 个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
### 03、乱码
当使用不同的编码方式读取或者写入文件时,就会出现乱码问题,来看示例。
```java
String s = "沉默王二!";
try {
// 将字符串按GBK编码方式保存到文件中
OutputStreamWriter out = new OutputStreamWriter(
new FileOutputStream("logs/test_utf8.txt"), "GBK");
out.write(s);
out.close();
FileReader fileReader = new FileReader("logs/test_utf8.txt");
int read;
while ((read = fileReader.read()) != -1) {
System.out.print((char)read);
}
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
```
在上面的示例代码中,首先定义了一个包含中文字符的字符串,然后将该字符串按 GBK 编码方式保存到文件中,接着将文件按默认编码方式(UTF-8)读取,并显示内容。此时就会出现乱码问题,显示为“��Ĭ������”。
这是因为文件中的 GBK 编码的字符在使用 UTF-8 编码方式解析时无法正确解析,从而导致出现乱码问题。
那如何才能解决乱码问题呢?
这就引出我们今天的主角了——转换流。
### 04、InputStreamReader
`java.io.InputStreamReader` 是 Reader 类的子类。它的作用是将字节流(InputStream)转换为字符流(Reader),同时支持指定的字符集编码方式,从而实现字符流与字节流之间的转换。
#### 1)构造方法
- `InputStreamReader(InputStream in)`: 创建一个使用默认字符集的字符流。
- `InputStreamReader(InputStream in, String charsetName)`: 创建一个指定字符集的字符流。
代码示例如下:
```java
InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");
```
#### 2)解决编码问题
下面是一个使用 InputStreamReader 解决乱码问题的示例代码:
```java
String s = "沉默王二!";
try {
// 将字符串按GBK编码方式保存到文件中
OutputStreamWriter outUtf8 = new OutputStreamWriter(
new FileOutputStream("logs/test_utf8.txt"), "GBK");
outUtf8.write(s);
outUtf8.close();
// 将字节流转换为字符流,使用GBK编码方式
InputStreamReader isr = new InputStreamReader(new FileInputStream("logs/test_utf8.txt"), "GBK");
// 读取字符流
int c;
while ((c = isr.read()) != -1) {
System.out.print((char) c);
}
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
```
由于使用了 InputStreamReader 对字节流进行了编码方式的转换,因此在读取字符流时就可以正确地解析出中文字符,避免了乱码问题。
### 05、OutputStreamWriter
`java.io.OutputStreamWriter` 是 Writer 的子类,字面看容易误以为是转为字符流,其实是将字符流转换为字节流,是字符流到字节流的桥梁。
- `OutputStreamWriter(OutputStream in)`: 创建一个使用默认字符集的字符流。
- `OutputStreamWriter(OutputStream in, String charsetName)`:创建一个指定字符集的字符流。
代码示例如下:
```java
OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("a.txt"));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("b.txt") , "GBK");
```
通常为了提高读写效率,我们会在转换流上再加一层[缓冲流](https://javabetter.cn/io/buffer.html),来看代码示例:
```java
try {
// 从文件读取字节流,使用UTF-8编码方式
FileInputStream fis = new FileInputStream("test.txt");
// 将字节流转换为字符流,使用UTF-8编码方式
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
// 使用缓冲流包装字符流,提高读取效率
BufferedReader br = new BufferedReader(isr);
// 创建输出流,使用UTF-8编码方式
FileOutputStream fos = new FileOutputStream("output.txt");
// 将输出流包装为转换流,使用UTF-8编码方式
OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");
// 使用缓冲流包装转换流,提高写入效率
BufferedWriter bw = new BufferedWriter(osw);
// 读取输入文件的每一行,写入到输出文件中
String line;
while ((line = br.readLine()) != null) {
bw.write(line);
bw.newLine(); // 每行结束后写入一个换行符
}
// 关闭流
br.close();
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
```
在上面的示例代码中,首先使用 FileInputStream 从文件中读取字节流,使用 UTF-8 编码方式进行读取。然后,使用 InputStreamReader 将字节流转换为字符流,使用 UTF-8 编码方式进行转换。接着,使用 BufferedReader 包装字符流,提高读取效率。然后,创建 FileOutputStream 用于输出文件,使用 UTF-8 编码方式进行创建。接着,使用 OutputStreamWriter 将输出流转换为字符流,使用 UTF-8 编码方式进行转换。最后,使用 BufferedWriter 包装转换流,提高写入效率。
### 06、小结
InputStreamReader 和 OutputStreamWriter 是将字节流转换为字符流或者将字符流转换为字节流。通常用于解决字节流和字符流之间的转换问题,可以将字节流以指定的字符集编码方式转换为字符流,或者将字符流以指定的字符集编码方式转换为字节流。
InputStreamReader 类的常用方法包括:
- `read()`:从输入流中读取一个字符的数据。
- `read(char[] cbuf, int off, int len)`:从输入流中读取 len 个字符的数据到指定的字符数组 cbuf 中,从 off 位置开始存放。
- `ready()`:返回此流是否已准备好读取。
- `close()`:关闭输入流。
OutputStreamWriter 类的常用方法包括:
- `write(int c)`:向输出流中写入一个字符的数据。
- `write(char[] cbuf, int off, int len)`:向输出流中写入指定字符数组 cbuf 中的 len 个字符,从 off 位置开始。
- `flush()`:将缓冲区的数据写入输出流中。
- `close()`:关闭输出流。
在使用转换流时,需要指定正确的字符集编码方式,否则可能会导致数据读取或写入出现乱码。
---
GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
