-
Notifications
You must be signed in to change notification settings - Fork 2.3k
Expand file tree
/
Copy pathfork-join.md
More file actions
401 lines (292 loc) · 22.1 KB
/
fork-join.md
File metadata and controls
401 lines (292 loc) · 22.1 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
---
title: 深入理解Java并发编程之Fork/Join框架
shortTitle: Fork/Join
description: Fork/Join 框架是 Java 7 中引入的一个强大的并行执行任务框架,旨在利用多核处理器的能力。该框架是基于"分而治之"的原理:一个大任务通常可以分解为一些小任务,这些小任务可以进一步分解,直到它们变得足够小而可以并行执行。
category:
- Java核心
tag:
- Java并发编程
head:
- - meta
- name: keywords
content: Java,并发编程,多线程,Thread,ForkJoin,ForkJoinPool,ForkJoinTask
---
并发编程领域的任务可以分为三种:简单并行任务、聚合任务和批量并行任务,见下图。
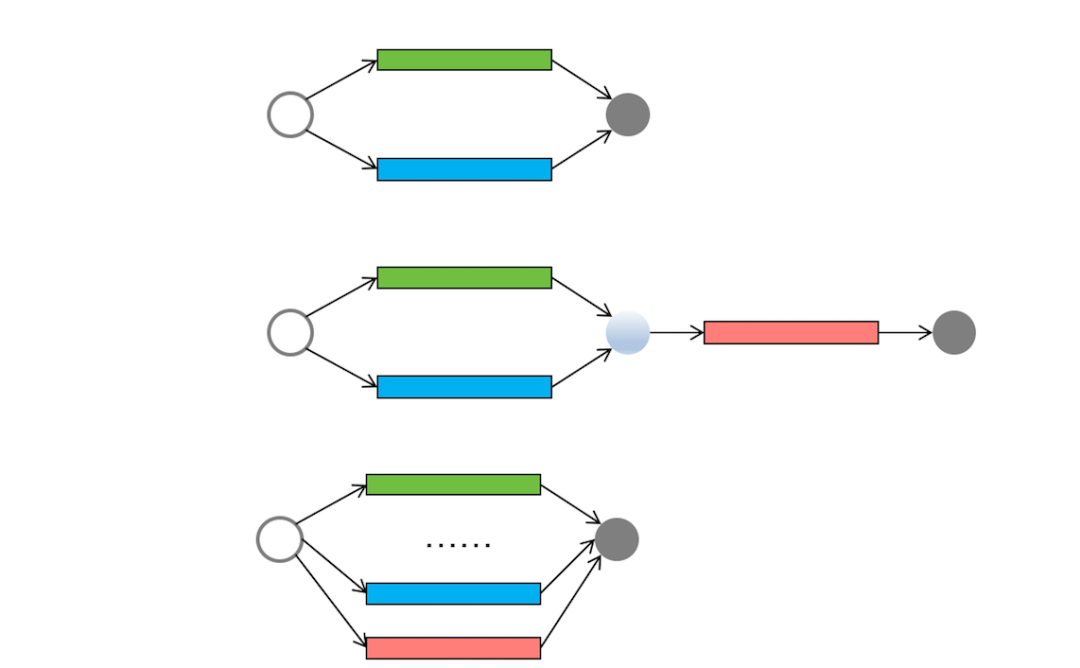
这些模型之外,还有一种任务模型被称为“分治”。分治是一种解决复杂问题的思维方法和模式;具体而言,它将一个复杂的问题分解成多个相似的子问题,然后再将这些子问题进一步分解成更小的子问题,直到每个子问题变得足够简单从而可以直接求解。
从理论上讲,每个问题都对应着一个任务,因此分治实际上就是对任务的划分和组织。分治思想在许多领域都有广泛的应用。例如,在算法领域,我们经常使用分治算法来解决问题(如归并排序和快速排序都属于分治算法,二分查找也是一种分治算法)。在大数据领域,MapReduce 计算框架背后的思想也是基于分治。
由于分治这种任务模型的普遍性,Java 并发包提供了一种名为 Fork/Join 的并行计算框架,专门用于支持分治任务模型的应用。
## 什么是分治任务模型
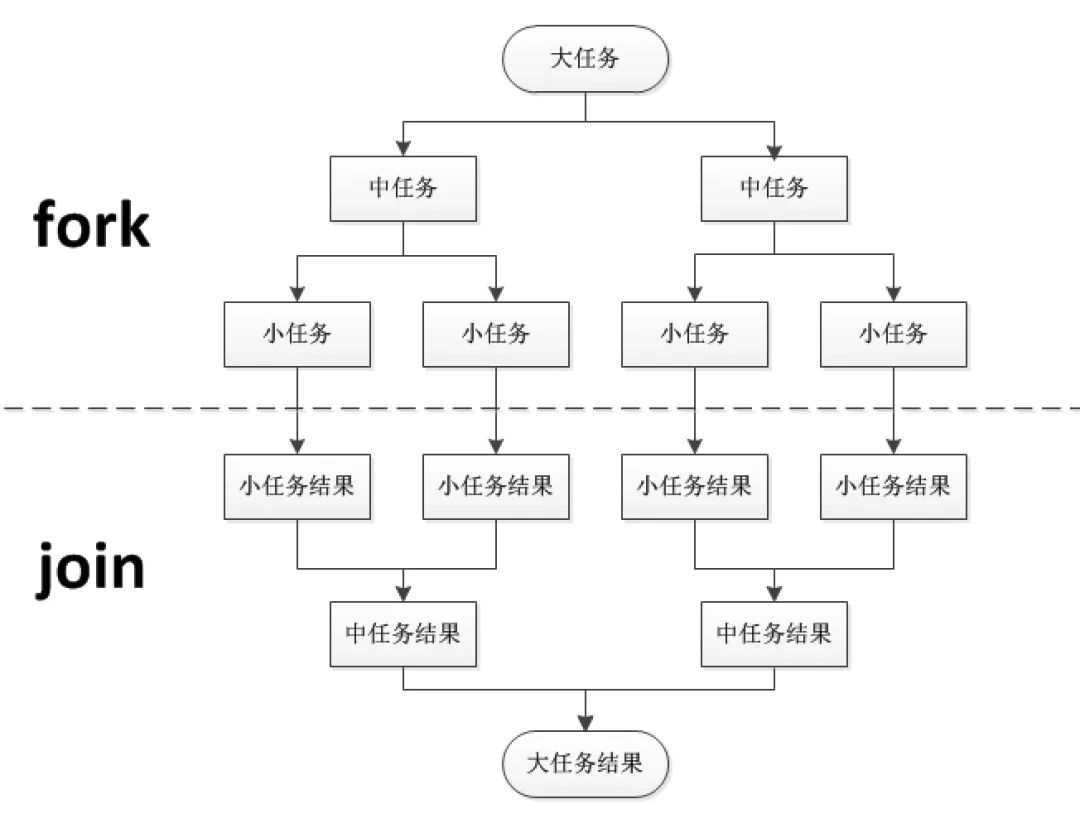
分治任务模型可分为两个阶段:一个阶段是 **任务分解**,就是迭代地将任务分解为子任务,直到子任务可以直接计算出结果;另一个阶段是 **结果合并**,即逐层合并子任务的执行结果,直到获得最终结果。下图是一个简化的分治任务模型图,你可以对照着理解。
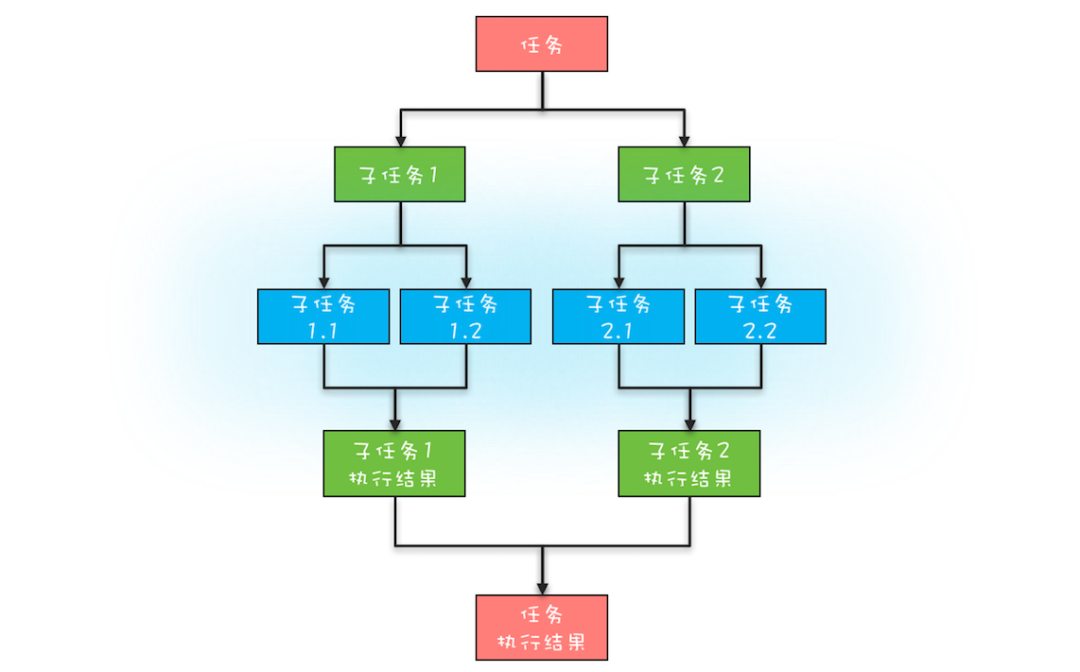
在这个分治任务模型里,任务和分解后的子任务具有相似性,这种相似性往往体现在任务和子任务的算法是相同的,但是计算的数据规模是不同的。具备这种相似性的问题,我们往往都采用递归算法。
## Fork/Join 的使用
Fork/Join 是一个并行计算框架,主要用于支持分治任务模型。在这个计算框架中,Fork 代表任务的分解,而 Join 代表结果的合并。
Fork/Join 计算框架主要由两部分组成:分治任务的线程池 ForkJoinPool 和分治任务 ForkJoinTask。
这两部分的关系类似于 [ThreadPoolExecutor](https://javabetter.cn/thread/pool.html) 和 [Runnable](https://javabetter.cn/thread/wangzhe-thread.html) 之间的关系,都是用于提交任务到线程池的,只不过分治任务有自己独特的类型 ForkJoinTask。
ForkJoinTask 是一个抽象类,其中有许多方法,其中最核心的是 `fork()`方法和 `join()`方法。fork 方法用于异步执行一个子任务,而 join 方法通过阻塞当前线程来等待子任务的执行结果。
ForkJoinTask 有两个子类:RecursiveAction 和 RecursiveTask。
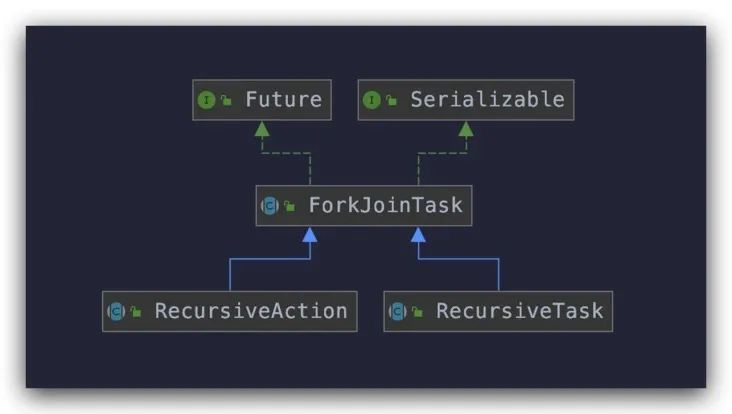
从它们的名字就可以看出,都是通过递归的方式来处理分治任务的。这两个子类都定义了一个抽象方法 `compute()`,不同之处在于 RecursiveAction 的 compute 方法没有返回值,而 RecursiveTask 的 compute 方法有返回值。这两个子类也都是抽象类,在使用时需要创建自定义的子类来扩展功能。
接下来,让我们使用 Fork/Join 并行计算框架来计算斐波那契数列(下面的代码示例源自 Java 官方示例)。
首先,我们需要创建一个 ForkJoinPool 线程池以及一个用于计算斐波那契数列的 Fibonacci 分治任务。然后,通过调用 ForkJoinPool 线程池的 `invoke()`方法来启动分治任务。
由于计算斐波那契数列需要返回结果,所以我们的 Fibonacci 类继承自 RecursiveTask。Fibonacci 分治任务需要实现 compute 方法,在这个方法中,逻辑与普通计算斐波那契数列的方法非常相似,只是在计算 `Fibonacci(n - 1)`时使用了异步子任务,这是通过 `f1.fork()`语句来实现。
```java
@Slf4j
public class ForkJoinDemo {
// 1. 运行入口
public static void main(String[] args) {
int n = 20;
// 为了追踪子线程名称,需要重写 ForkJoinWorkerThreadFactory 的方法
final ForkJoinPool.ForkJoinWorkerThreadFactory factory = pool -> {
final ForkJoinWorkerThread worker = ForkJoinPool.defaultForkJoinWorkerThreadFactory.newThread(pool);
worker.setName("my-thread" + worker.getPoolIndex());
return worker;
};
//创建分治任务线程池,可以追踪到线程名称
ForkJoinPool forkJoinPool = new ForkJoinPool(4, factory, null, false);
// 快速创建 ForkJoinPool 方法
// ForkJoinPool forkJoinPool = new ForkJoinPool(4);
//创建分治任务
Fibonacci fibonacci = new Fibonacci(n);
//调用 invoke 方法启动分治任务
Integer result = forkJoinPool.invoke(fibonacci);
log.info("Fibonacci {} 的结果是 {}", n, result);
}
}
// 2. 定义拆分任务,写好拆分逻辑
@Slf4j
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
@Override
public Integer compute() {
//和递归类似,定义可计算的最小单元
if (n <= 1) {
return n;
}
// 想查看子线程名称输出的可以打开下面注释
//log.info(Thread.currentThread().getName());
Fibonacci f1 = new Fibonacci(n - 1);
// 拆分成子任务
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
// f1.join 等待子任务执行结果
return f2.compute() + f1.join();
}
}
```
运行程序,我们会得到如下的结果:
```
17:29:10.336 [main] INFO tech.shuyi.javacodechip.forkjoinpool.ForkJoinDemo - Fibonacci 20 的结果是 6765
```
## ForkJoinPool
Fork/Join 并行计算的核心组件是 ForkJoinPool。下面简单介绍一下 ForkJoinPool 的工作原理。
当我们通过 ForkJoinPool 的 invoke 或 submit 方法提交任务时,ForkJoinPool 会根据一定的路由规则将任务分配到一个任务队列中。如果任务执行过程中创建了子任务,那么子任务会被提交到对应工作线程的任务队列中。
ForkJoinPool 中有一个数组形式的成员变量 `workQueue[]`,其对应一个队列数组,每个队列对应一个消费线程。丢入线程池的任务,根据特定规则进行转发。
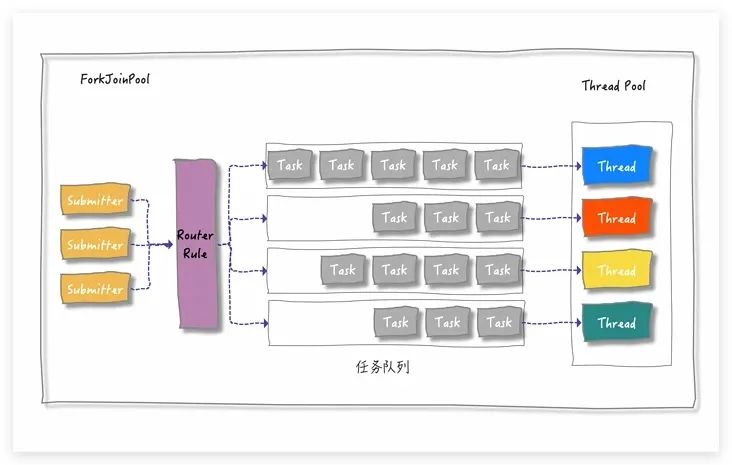
当工作线程的任务队列为空时,它是否无事可做呢?
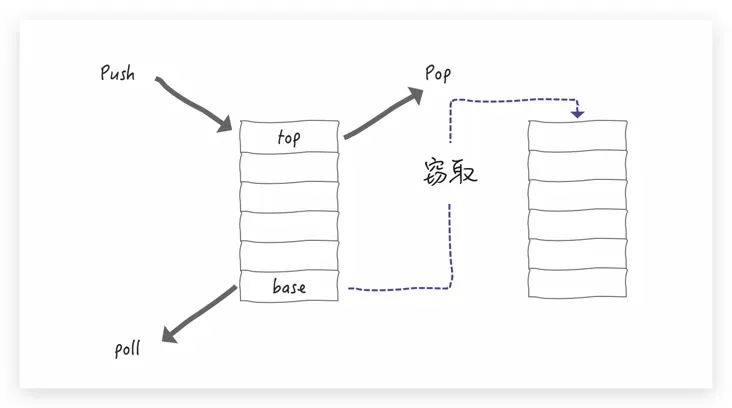
不是的。ForkJoinPool 引入了一种称为"任务窃取"的机制。当工作线程空闲时,它可以从其他工作线程的任务队列中"窃取"任务。
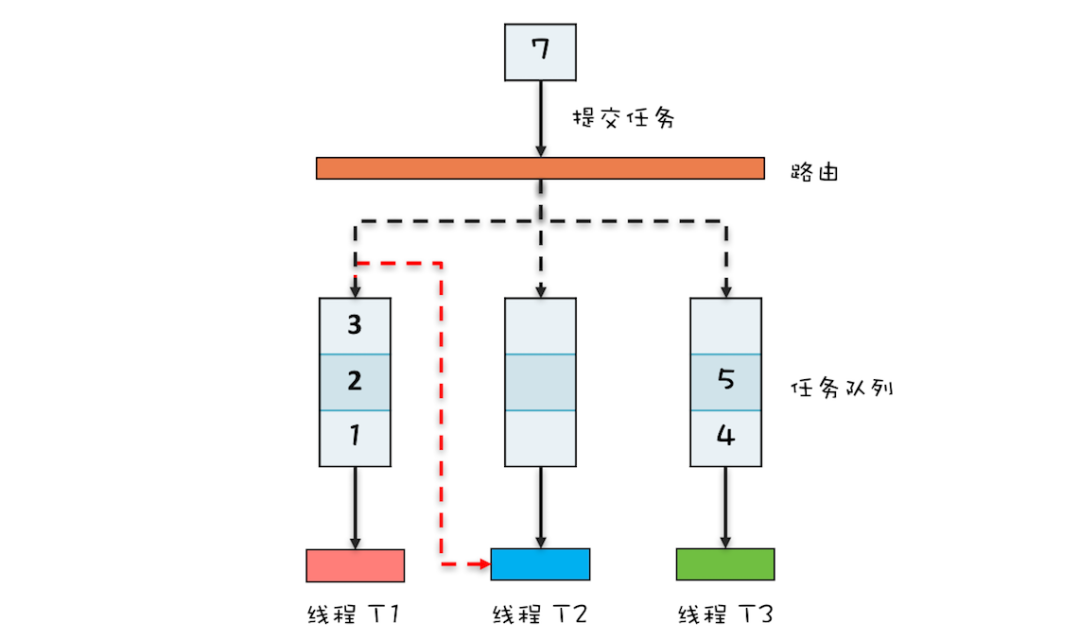
例如,下图中线程 T2 的任务队列已经为空,它可以窃取线程 T1 任务队列中的任务。这样,所有的工作线程都能保持忙碌的状态。
ForkJoinPool 中的任务队列采用双端队列的形式。工作线程从任务队列的一个端获取任务,而"窃取任务"从另一端进行消费。这种设计能够避免许多不必要的数据竞争。
## 与ThreadPoolExecutor的比较
ForkJoinPool 与 ThreadPoolExecutor 有很多相似之处,例如都是线程池,都是用于执行任务的。但是,它们之间也有很多不同之处。
首先,ForkJoinPool 采用的是"工作窃取"的机制,而 ThreadPoolExecutor 采用的是"工作复用"的机制。这两种机制各有优劣,ForkJoinPool 的优势在于能够充分利用 CPU 的多核能力,而 ThreadPoolExecutor 的优势在于能够避免线程间的上下文切换。
其次,ForkJoinPool 采用的是分治任务模型,而 ThreadPoolExecutor 采用的是简单并行任务模型。这两种任务模型各有优劣,ForkJoinPool 的优势在于能够处理分治任务,而 ThreadPoolExecutor 的优势在于能够处理简单并行任务。
最后,ForkJoinPool 采用的是 LIFO 的任务队列,而 ThreadPoolExecutor 采用的是 FIFO 的任务队列。这两种任务队列各有优劣,ForkJoinPool 的优势在于能够避免数据竞争,而 ThreadPoolExecutor 的优势在于能够保证任务的顺序性。
假设:我们要计算 1 到 1 亿的和,为了加快计算的速度,我们自然想到算法中的分治原理,将 1 亿个数字分成 1 万个任务,每个任务计算 1 万个数值的综合,利用 CPU 的并发计算性能缩短计算时间。
由于 ThreadPoolExecutor 可以通过 [Future](https://javabetter.cn/thread/callable-future-futuretask.html) 获取到执行结果,因此利用 ThreadPoolExecutor 也是可行的。
当然 ForkJoinPool 实现也是可以的。下面我们将这两种方式都实现一下,看看这两种实现方式有什么不同。
无论哪种实现方式,其大致思路都是:
1. 按照线程池里线程个数 N,将 1 亿个数划分成 N 等份,随后丢入线程池进行计算。
2. 每个计算任务使用 Future 接口获取计算结果,最后积加即可。
我们先使用 ThreadPoolExecutor 实现。
首先,定义一个 Calculator 接口,表示计算数字总和这个动作,如下所示。
```java
public interface Calculator {
/**
* 把传进来的所有numbers 做求和处理
*
* @param numbers
* @return 总和
*/
long sumUp(long[] numbers);
}
```
接着,我们定义一个使用 ThreadPoolExecutor 线程池实现的类,如下所示。
```java
public class ExecutorServiceCalculator implements Calculator {
private int parallism;
private ExecutorService pool;
public ExecutorServiceCalculator() {
// CPU的核心数 默认就用cpu核心数了
parallism = Runtime.getRuntime().availableProcessors();
pool = Executors.newFixedThreadPool(parallism);
}
// 1. 处理计算任务的线程
private static class SumTask implements Callable<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
public Long call() {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
}
}
// 2. 核心业务逻辑实现
@Override
public long sumUp(long[] numbers) {
List<Future<Long>> results = new ArrayList<>();
// 2.1 数字拆分
// 把任务分解为 n 份,交给 n 个线程处理 4核心 就等分成4份呗
// 然后把每一份都扔个一个SumTask线程 进行处理
int part = numbers.length / parallism;
for (int i = 0; i < parallism; i++) {
int from = i * part; //开始位置
int to = (i == parallism - 1) ? numbers.length - 1 : (i + 1) * part - 1; //结束位置
//扔给线程池计算
results.add(pool.submit(new SumTask(numbers, from, to)));
}
// 2.2 阻塞等待结果
// 把每个线程的结果相加,得到最终结果 get()方法 是阻塞的
// 优化方案:可以采用CompletableFuture来优化 JDK1.8的新特性
long total = 0L;
for (Future<Long> f : results) {
try {
total += f.get();
} catch (Exception ignore) {
}
}
return total;
}
}
```
如上面代码所示,我们实现了一个计算单个任务的类 SumTask,在该类中对数值进行累加。其次,我们在 `sumUp ()` 方法中,对 1 亿的数字进行拆分,接着扔给线程池计算,最后阻塞等待计算结果,最终累加起来。
我们运行上面的代码,可以得到顺利得到最终结果,如下所示。
```
耗时:10ms
结果为:50000005000000
```
接着我们使用 ForkJoinPool 来实现。
我们首先实现 SumTask 继承 RecursiveTask 抽象类,并在 compute 方法中定义拆分逻辑及计算。最后在 sumUp 方法中调用 pool 方法进行计算,代码如下所示。
```java
public class ForkJoinCalculator implements Calculator {
private ForkJoinPool pool;
// 1. 定义计算逻辑
private static class SumTask extends RecursiveTask<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
//此方法为ForkJoin的核心方法:对任务进行拆分 拆分的好坏决定了效率的高低
@Override
protected Long compute() {
// 当需要计算的数字个数小于6时,直接采用for loop方式计算结果
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
} else {
// 否则,把任务一分为二,递归拆分(注意此处有递归)到底拆分成多少分 需要根据具体情况而定
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
public ForkJoinCalculator() {
// 也可以使用公用的线程池 ForkJoinPool.commonPool():
// pool = ForkJoinPool.commonPool()
pool = new ForkJoinPool();
}
@Override
public long sumUp(long[] numbers) {
Long result = pool.invoke(new SumTask(numbers, 0, numbers.length - 1));
pool.shutdown();
return result;
}
}
```
运行上面的代码,结果为:
```
耗时:860ms
结果为:50000005000000
```
对比 ThreadPoolExecutor 和 ForkJoinPool 这两者的实现,可以发现它们都有任务拆分的逻辑,以及最终合并数值的逻辑。但 ForkJoinPool 相比 ThreadPoolExecutor 来说,做了一些实现上的封装,例如:
* 不用手动去获取子任务的结果,而是使用 join 方法直接获取结果。
* 将任务拆分的逻辑,封装到 RecursiveTask 实现类中,而不是裸露在外。
因此对于没有父子任务依赖,但是希望获取到子任务执行结果的并行计算任务,就可以使用 ForkJoinPool 来实现。**在这种情况下,使用 ForkJoinPool 实现更多是代码实现方便,封装做得更加好。**
## 模拟 MapReduce 统计单词数量
MapReduce 是一个编程模型,同时也是一个处理和生成大数据集的处理框架。它源于 Google,用于支持在大型数据集上的分布式计算。这个框架主要由两个步骤组成:Map 步骤和 Reduce 步骤,这也是它名字的由来。
Fork/Join 并行计算框架通常被用来实现学习 MapReduce 的入门程序,该程序用于统计文件中每个单词的数量。
首先,我们可以使用二分法递归地将文件拆分为更小的部分,直到每个部分只有一行数据。然后,在每个部分中统计单词的数量,并逐级汇总结果。你可以参考之前提到的简化版分治任务模型图来理解该过程。
现在,让我们开始实现。下面的代码使用了字符串数组`String[] fc`来模拟文件内容,其中每个元素与文件中的行数据一一对应。关键代码位于`compute()`方法中,这是一个递归方法。它将前半部分数据 fork 一个递归任务进行处理(关键代码:`mr1.fork()`),而后半部分数据在当前任务中递归处理(`mr2.compute()`)。
```java
import java.util.concurrent.RecursiveTask;
public class WordCountTask extends RecursiveTask<Integer> {
private final String[] fc;
private final int start, end;
public WordCountTask(String[] fc, int start, int end) {
this.fc = fc;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start <= 1) {
// 对单行数据进行统计
return countWords(fc[start]);
} else {
int mid = (start + end) / 2;
WordCountTask mr1 = new WordCountTask(fc, start, mid);
mr1.fork();
WordCountTask mr2 = new WordCountTask(fc, mid, end);
int result2 = mr2.compute();
int result1 = mr1.join();
// 汇总结果
return result1 + result2;
}
}
private int countWords(String line) {
String[] words = line.split(" ");
return words.length;
}
}
```
这个示例程序是对 Fork/Join 模型的简化,实际上在真正的 MapReduce 框架中,还涉及到数据划分、映射阶段、归约阶段等更多的步骤。但是通过此示例,大家可以初步了解如何使用 Fork/Join 并行计算框架来处理类似的任务。
## 小结
Fork/Join 并行计算框架主要解决的是分治任务。分治的核心思想是“分而治之”:将一个大的任务拆分成小的子任务去解决,然后再把子任务的结果聚合起来从而得到最终结果。这个过程非常类似于大数据处理中的 MapReduce,所以你可以把 Fork/Join 看作单机版的 MapReduce。
Fork/Join 并行计算框架的核心组件是 ForkJoinPool。ForkJoinPool 支持任务窃取机制,能够让所有线程的工作量基本均衡,不会出现有的线程很忙,而有的线程很闲的状况,所以性能很好。
Java 1.8 提供的 Stream API 里面并行流也是以 ForkJoinPool 为基础的。不过需要注意的是,默认情况下所有的并行流计算都共享一个 ForkJoinPool,这个共享的 ForkJoinPool 默认的线程数是 CPU 的核数;如果所有的并行流计算都是 CPU 密集型计算的话,完全没有问题,但是如果存在 I/O 密集型的并行流计算,那么很可能会因为一个很慢的 I/O 计算而拖慢整个系统的性能。
所以 **建议用不同的 ForkJoinPool 执行不同类型的计算任务**。
>编辑:沉默王二,部分内容来源于这篇文章:[分而治之思想Forkjoin](https://mp.weixin.qq.com/s/baP7S6tA9i_Hgu6RhKcvew),还有一部分内容来源于朋友[陈树义的这篇文章](https://mp.weixin.qq.com/s/0jCBRPJBPYlgQ0iPByXDtw),内容很顶,强烈推荐。还有一部分图片来自于朋友「日拱一兵」的文章。
---
GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第二份 PDF 《[并发编程小册](https://javabetter.cn/thread/)》终于来了!包括线程的基本概念和使用方法、Java的内存模型、sychronized、volatile、CAS、AQS、ReentrantLock、线程池、并发容器、ThreadLocal、生产者消费者模型等面试和开发必须掌握的内容,共计 15 万余字,200+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,二哥的并发编程进阶之路.pdf](https://javabetter.cn/thread/)
[加入二哥的编程星球](https://javabetter.cn/thread/),在星球的第二个置顶帖「[知识图谱](https://javabetter.cn/thread/)」里就可以获取 PDF 版本。