-
Notifications
You must be signed in to change notification settings - Fork 2.3k
Expand file tree
/
Copy pathmap.md
More file actions
255 lines (162 loc) · 14.9 KB
/
map.md
File metadata and controls
255 lines (162 loc) · 14.9 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
---
title: 聊聊Java的并发集合容器ConcurrentHashMap、阻塞队列和 CopyOnWrite 容器
shortTitle: Java的并发容器
description: Java 的并发集合容器提供了在多线程环境中高效访问和操作的数据结构。这些容器通过内部的同步机制实现了线程安全,使得开发者无需显式同步代码就能在并发环境下安全使用。
category:
- Java核心
tag:
- Java并发编程
head:
- - meta
- name: keywords
content: Java,并发编程,多线程,Thread,并发集合容器
---
Java 的并发集合容器提供了在多线程环境中高效访问和操作的数据结构。这些容器通过内部的同步机制实现了线程安全,使得开发者无需显式同步代码就能在并发环境下安全使用,比如说:ConcurrentHashMap、阻塞队列和 CopyOnWrite 容器等。
java.util 包下提供了一些容器类([集合框架](https://javabetter.cn/collection/gailan.html)),其中 Vector 和 Hashtable 是线程安全的,但实现方式比较粗暴,通过在方法上加「[sychronized](https://javabetter.cn/thread/synchronized-1.html)」关键字实现。
但即便是 Vector 这样线程安全的类,在应对多线程的复合操作时也需要在客户端继续加锁以保证原子性。来看下面的例子:
```java
public class TestVector {
private Vector<String> vector;
//方法一
public Object getLast(Vector vector) {
int lastIndex = vector.size() - 1;
return vector.get(lastIndex);
}
//方法二
public void deleteLast(Vector vector) {
int lastIndex = vector.size() - 1;
vector.remove(lastIndex);
}
//方法三
public Object getLastSysnchronized(Vector vector) {
synchronized(vector){
int lastIndex = vector.size() - 1;
return vector.get(lastIndex);
}
}
//方法四
public void deleteLastSysnchronized(Vector vector) {
synchronized (vector){
int lastIndex = vector.size() - 1;
vector.remove(lastIndex);
}
}
}
```
如果方法一和方法二是一个组合的话,那么当方法一获取到了`vector`的 size 之后,方法二已经执行完毕,这样就会导致程序出现错误。
如果方法三与方法四组合的话,就还需在内部加锁来保证 `vector` 上的原子性操作。
于是并发容器就应用而生了,它们是线程安全的,可以在多线程环境下高效地访问和操作数据,而不需要额外的同步措施。
## 并发容器类
整体架构如下图所示:
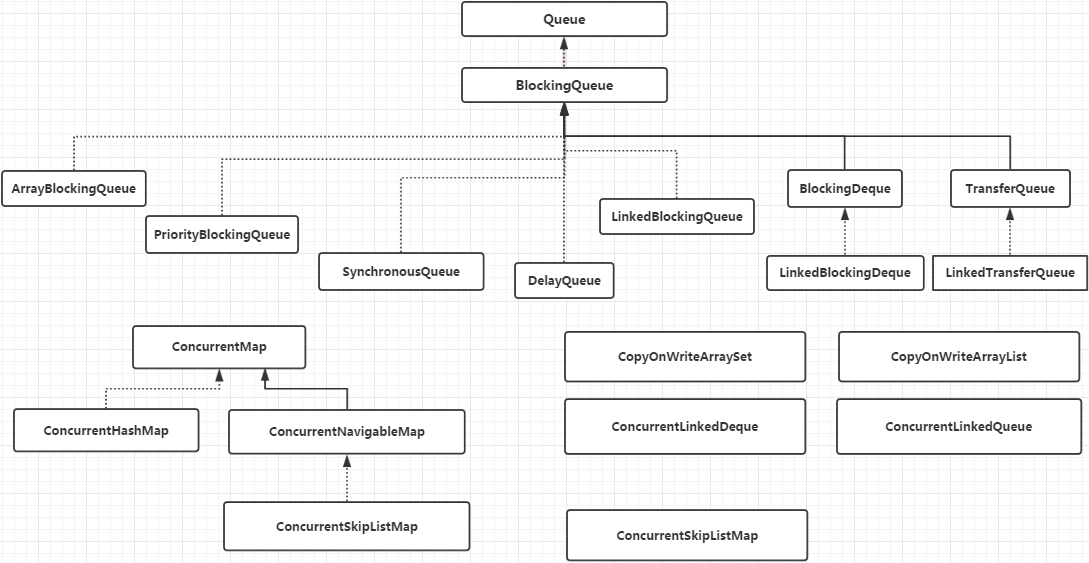
## 并发 Map
### ConcurrentMap 接口
ConcurrentMap 接口继承了 Map 接口,在 Map 接口的基础上又定义了四个方法:
```java
public interface ConcurrentMap<K, V> extends Map<K, V> {
//插入元素
V putIfAbsent(K key, V value);
//移除元素
boolean remove(Object key, Object value);
//替换元素
boolean replace(K key, V oldValue, V newValue);
//替换元素
V replace(K key, V value);
}
```
**putIfAbsent:** 与原有 put 方法不同的是,putIfAbsent 如果插入的 key 相同,则不替换原有的 value 值;
**remove:** 与原有 remove 方法不同的是,新 remove 方法中增加了对 value 的判断,如果要删除的 key-value 不能与 Map 中原有的 key-value 对应上,则不会删除该元素;
**replace(K,V,V):** 增加了对 value 值的判断,如果 key-oldValue 能与 Map 中原有的 key-value 对应上,才进行替换操作;
**replace(K,V):** 与上面的 replace 不同的是,此 replace 不会对 Map 中原有的 key-value 进行比较,如果 key 存在则直接替换;
### ConcurrentHashMap
ConcurrentHashMap 同 [HashMap](https://javabetter.cn/collection/hashmap.html) 一样,也是基于散列表的 map,但是它提供了一种与 Hashtable 完全不同的加锁策略,提供了更高效的并发性和伸缩性。
后面我们会单独开一篇来详细介绍 [ConcurrentHashMap](https://javabetter.cn/thread/ConcurrentHashMap.html),戳链接直达。
### ConcurrentSkipListMap
ConcurrentNavigableMap 接口继承了 NavigableMap 接口,这个接口提供了针对给定搜索目标返回最接近匹配项的导航方法。
ConcurrentNavigableMap 接口的主要实现类是 ConcurrentSkipListMap 类。从名字上来看,它的底层使用的是跳表(SkipList)。跳表是一种”空间换时间“的数据结构,可以使用 [CAS](https://javabetter.cn/thread/cas.html) 来保证并发安全性。
与 ConcurrentHashMap 的读密集操作相比,ConcurrentSkipListMap 的读和写操作的性能相对较低。这是由其数据结构导致的,因为跳表的插入和删除需要更复杂的指针操作。然而,ConcurrentSkipListMap 提供了有序性,这是 ConcurrentHashMap 所没有的。
ConcurrentSkipListMap 适用于需要线程安全的同时又需要元素有序的场合。如果不需要有序,ConcurrentHashMap 可能是更好的选择,因为它通常具有更高的性能。
## 并发 Queue
JDK 并没有提供线程安全的 List 类,因为对 List 来说,**很难去开发一个通用并且没有并发瓶颈的线程安全的 List**。因为即使简单的读操作,比如 `contains()`,也需要再搜索的时候锁住整个 list。
所以退一步,JDK 提供了队列和双端队列的线程安全类:ConcurrentLinkedQueue 和 ConcurrentLinkedDeque。因为队列相对于 List 来说,有更多的限制。这两个类是使用 CAS 来实现线程安全的。
我们会在后面单独开一篇来详细介绍[ConcurrentLinkedQueue](https://javabetter.cn/thread/ConcurrentLinkedQueue.html),戳链接直达。
## 并发 Set
ConcurrentSkipListSet 是线程安全的有序集合。底层是使用 ConcurrentSkipListMap 来实现。
谷歌的 [Guava](https://javabetter.cn/common-tool/guava.html)实现了一个线程安全的 ConcurrentHashSet:
```java
Set<String> s = Sets.newConcurrentHashSet();
```
Set 日常开发中用的并不多,所以这里就不展开细讲了。
## 阻塞队列
我们假设一种场景,[生产者一直生产资源,消费者一直消费资源](https://javabetter.cn/thread/shengchanzhe-xiaofeizhe.html)(后面会细讲,戳链接直达),资源存储在一个缓冲池中,生产者将生产的资源存进缓冲池中,消费者从缓冲池中拿到资源进行消费,这就是大名鼎鼎的**生产者-消费者模式**。
该模式能够简化开发过程,一方面消除了生产者类与消费者类之间的代码依赖性,另一方面将生产数据的过程与使用数据的过程解耦简化负载。
我们自己 coding 实现这个模式的时候,因为需要让**多个线程操作共享变量**(即资源),所以很容易引发**线程安全问题**,造成**重复消费**和**死锁**,尤其是生产者和消费者存在多个的情况。另外,当缓冲池空了,我们需要阻塞消费者,唤醒生产者;当缓冲池满了,我们需要阻塞生产者,唤醒消费者,这些个**等待-唤醒**逻辑都需要自己实现。
这么容易出错的事情,JDK 当然帮我们做啦,这就是阻塞队列(BlockingQueue),**你只管往里面存、取就行,而不用担心多线程环境下存、取共享变量的线程安全问题。**
> BlockingQueue 是 Java util.concurrent 包下重要的数据结构,区别于普通的队列,BlockingQueue 提供了**线程安全的队列访问方式**,并发包下很多高级同步类的实现都是基于 BlockingQueue 实现的。
BlockingQueue 一般用于生产者-消费者模式,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。**BlockingQueue 就是存放元素的容器**。
### BlockingQueue 的操作方法
阻塞队列提供了四组不同的方法用于插入、移除、检查元素:
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
| :-----------: | :-------: | :--------: | :--------: | :----------------: |
| 插入方法 | add(e) | offer(e) | **put(e)** | offer(e,time,unit) |
| 移除方法 | remove() | poll() | **take()** | poll(time,unit) |
| 检查方法 | element() | peek() | - | - |
- 抛出异常:如果操作无法立即执行,会抛异常。当阻塞队列满时候,再往队列里插入元素,会抛出 `IllegalStateException(“Queue full”)`异常。当队列为空时,从队列里获取元素时会抛出 NoSuchElementException 异常 。
- 返回特殊值:如果操作无法立即执行,会返回一个特殊值,通常是 true / false。
- 一直阻塞:如果操作无法立即执行,则一直阻塞或者响应中断。
- 超时退出:如果操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功,通常是 true / false。
**注意:**
- 不能往阻塞队列中插入 null,会抛出空指针异常。
- 可以访问阻塞队列中的任意元素,调用 `remove(o)`可以将队列之中的特定对象移除,但并不高效,尽量避免使用。
我们会在后面单独开一篇[BlockingQueue](https://javabetter.cn/thread/BlockingQueue.html)来细讲,戳链接直达。
### BlockingQueue 的实现类
#### ArrayBlockingQueue
由**数组**结构组成的**有界**阻塞队列。内部结构是数组,具有数组的特性。
```java
public ArrayBlockingQueue(int capacity, boolean fair){
//..省略代码
}
```
可以初始化队列大小,一旦初始化将不能改变。构造方法中的 fair 表示控制对象的内部锁是否采用公平锁,默认是**非公平锁**。
#### LinkedBlockingQueue
由**链表**结构组成的**有界**阻塞队列。内部结构是链表,具有链表的特性。默认队列的大小是`Integer.MAX_VALUE`,也可以指定大小。此队列按照**先进先出**的原则对元素进行排序。
#### DelayQueue
该队列中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。注入其中的元素必须实现 `java.util.concurrent.Delayed` 接口。
DelayQueue 是一个没有大小限制的队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
#### PriorityBlockingQueue
基于优先级的无界阻塞队列(优先级的判断通过构造函数传入的 Compator 对象来决定),内部控制线程同步的锁采用的是非公平锁。
> 网上大部分博客上**PriorityBlockingQueue**为公平锁,其实是不对的,查阅源码(感谢 github:**ambition0802**同学的指出):
```java
public PriorityBlockingQueue(int initialCapacity,
Comparator<? super E> comparator) {
this.lock = new ReentrantLock(); //默认构造方法-非公平锁
...//其余代码略
}
```
#### SynchronousQueue
这个队列比较特殊,**没有任何内部容量**,甚至连一个队列的容量都没有。并且每个 put 必须等待一个 take,反之亦然。
需要区别容量为 1 的 ArrayBlockingQueue、LinkedBlockingQueue。
以下方法的返回值,可以帮助理解这个队列:
- `iterator()` 永远返回空,因为里面没有东西
- `peek()` 永远返回 null
- `put()` 往 queue 放进去一个 element 以后就一直 wait 直到有其他 thread 进来把这个 element 取走。
- `offer()` 往 queue 里放一个 element 后立即返回,如果碰巧这个 element 被另一个 thread 取走了,offer 方法返回 true,认为 offer 成功;否则返回 false。
- `take()` 取出并且 remove 掉 queue 里的 element,取不到东西他会一直等。
- `poll()` 取出并且 remove 掉 queue 里的 element,只有到碰巧另外一个线程正在往 queue 里 offer 数据或者 put 数据的时候,该方法才会取到东西。否则立即返回 null。
- `isEmpty()` 永远返回 true
- `remove()&removeAll()` 永远返回 false
**注意**
**PriorityBlockingQueue**不会阻塞数据生产者(因为队列是无界的),而只会在没有可消费的数据时阻塞数据的消费者。因此使用的时候要特别注意,**生产者生产数据的速度绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。**对于使用默认大小的**LinkedBlockingQueue**也是一样的。
## CopyOnWrite 容器
在聊 CopyOnWrite 容器之前我们先来谈谈什么是 CopyOnWrite 机制,CopyOnWrite 是计算机设计领域的一种优化策略,也是一种在并发场景下常用的设计思想——写入时复制。
什么是写入时复制呢?
就是当有多个调用者同时去请求一个资源数据的时候,有一个调用者出于某些原因需要对当前的数据源进行修改,这个时候系统将会复制一个当前数据源的副本给调用者修改。
CopyOnWrite 容器即**写时复制的容器**,当我们往一个容器中添加元素的时候,不直接往容器中添加,而是将当前容器进行 copy,复制出来一个新的容器,然后向新容器中添加我们需要的元素,最后将原容器的引用指向新容器。
这样做的好处在于,我们可以在并发的场景下对容器进行"读操作"而不需要"加锁",从而达到读写分离的目的。从 JDK 1.5 开始 Java 并发包里提供了两个使用 CopyOnWrite 机制实现的并发容器,分别是 [CopyOnWriteArrayList](https://javabetter.cn/thread/CopyOnWriteArrayList.html)(后面会细讲,戳链接直达) 和 CopyOnWriteArraySet(不常用)。
## 小结
本文主要介绍了并发包中的三个重要的容器类,Map、阻塞队列和 CopyOnWrite 容器,Map 用于存储键值对,阻塞队列用于生产者-消费者模型,而 CopyOnWrite 容器用于“读多写少”的并发场景。
> 编辑:沉默王二,部分内容来源于朋友小七萤火虫开源的这个仓库:[深入浅出 Java 多线程](http://concurrent.redspider.group/),推荐阅读:[時光以北这篇 ConcurrentSkipListMap 讲的很不错](https://juejin.cn/post/6844903958499033095),可以学习。
---
GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第二份 PDF 《[并发编程小册](https://javabetter.cn/thread/)》终于来了!包括线程的基本概念和使用方法、Java的内存模型、sychronized、volatile、CAS、AQS、ReentrantLock、线程池、并发容器、ThreadLocal、生产者消费者模型等面试和开发必须掌握的内容,共计 15 万余字,200+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,二哥的并发编程进阶之路.pdf](https://javabetter.cn/thread/)
[加入二哥的编程星球](https://javabetter.cn/thread/),在星球的第二个置顶帖「[知识图谱](https://javabetter.cn/thread/)」里就可以获取 PDF 版本。