diff --git a/docs.json b/docs.json
index b544c50d9..c73675ce5 100644
--- a/docs.json
+++ b/docs.json
@@ -213,7 +213,7 @@
"en/use-dify/workspace/subscription-management",
{
"group": "API Extension",
- "icon":"puzzle-piece-simple",
+ "icon": "puzzle-piece-simple",
"pages": [
"en/use-dify/workspace/api-extension/api-extension",
"en/use-dify/workspace/api-extension/external-data-tool-api-extension",
@@ -598,7 +598,7 @@
"zh/use-dify/workspace/subscription-management",
{
"group": "API 扩展",
- "icon":"puzzle-piece-simple",
+ "icon": "puzzle-piece-simple",
"pages": [
"zh/use-dify/workspace/api-extension/api-extension",
"zh/use-dify/workspace/api-extension/external-data-tool-api-extension",
@@ -983,7 +983,7 @@
"ja/use-dify/workspace/subscription-management",
{
"group": "API 拡張",
- "icon":"puzzle-piece-simple",
+ "icon": "puzzle-piece-simple",
"pages": [
"ja/use-dify/workspace/api-extension/api-extension",
"ja/use-dify/workspace/api-extension/external-data-tool-api-extension",
diff --git a/ja/use-dify/nodes/agent.mdx b/ja/use-dify/nodes/agent.mdx
index 7bdcfc3e1..97bf3824f 100644
--- a/ja/use-dify/nodes/agent.mdx
+++ b/ja/use-dify/nodes/agent.mdx
@@ -1,118 +1,36 @@
----
-title: "エージェント"
-description: "複雑なタスク実行のためにLLMにツールの自律制御を与える"
-icon: "robot"
----
-
+### フォームコンテンツ
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/agent)を参照してください。
+リクエストフォームに表示される内容をカスタマイズします:
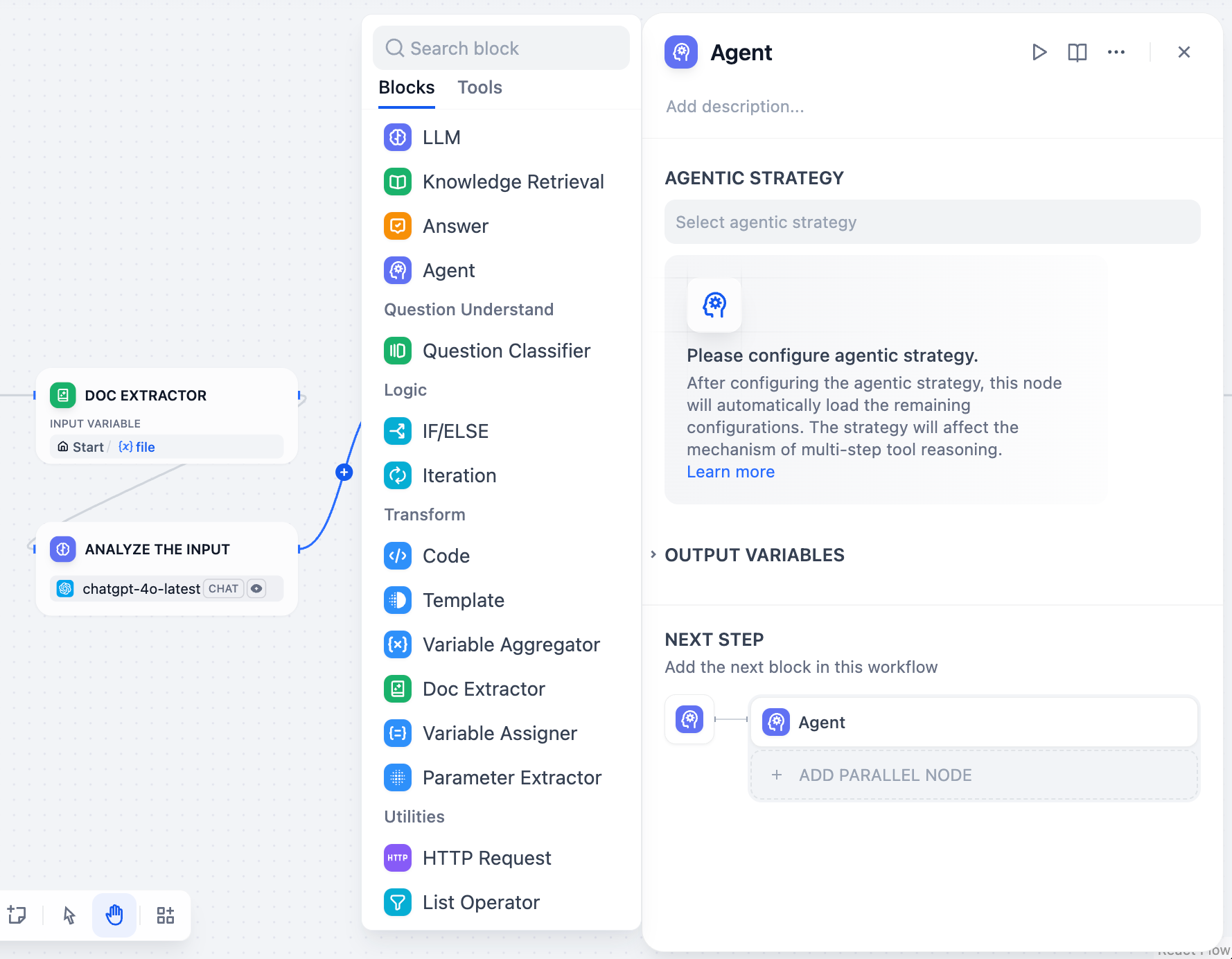
-エージェントノードは、LLMにツールの自律的な制御権を与え、どのツールをいつ使用するかを反復的に決定できるようにします。すべてのステップを事前に計画する代わりに、エージェントは問題を動的に推論し、複雑なタスクを完了するために必要に応じてツールを呼び出します。
-
-
-  -
+- **Markdownでフォーマットと構造を設定**
-## エージェント戦略
+ 見出し、リスト、太字、リンク、その他のMarkdown要素を使用して、情報をわかりやすく表示します。
-エージェント戦略は、エージェントの思考と行動を定義します。モデルの能力とタスク要件に最も適したアプローチを選択してください。
+- **変数で動的データを表示**
-
-
-
+- **Markdownでフォーマットと構造を設定**
-## エージェント戦略
+ 見出し、リスト、太字、リンク、その他のMarkdown要素を使用して、情報をわかりやすく表示します。
-エージェント戦略は、エージェントの思考と行動を定義します。モデルの能力とタスク要件に最も適したアプローチを選択してください。
+- **変数で動的データを表示**
-
-  -
+ ワークフロー変数を参照して、レビュー用のAI生成テキストや受信者の判断に役立つコンテキスト情報などの動的コンテンツを表示できます。
-
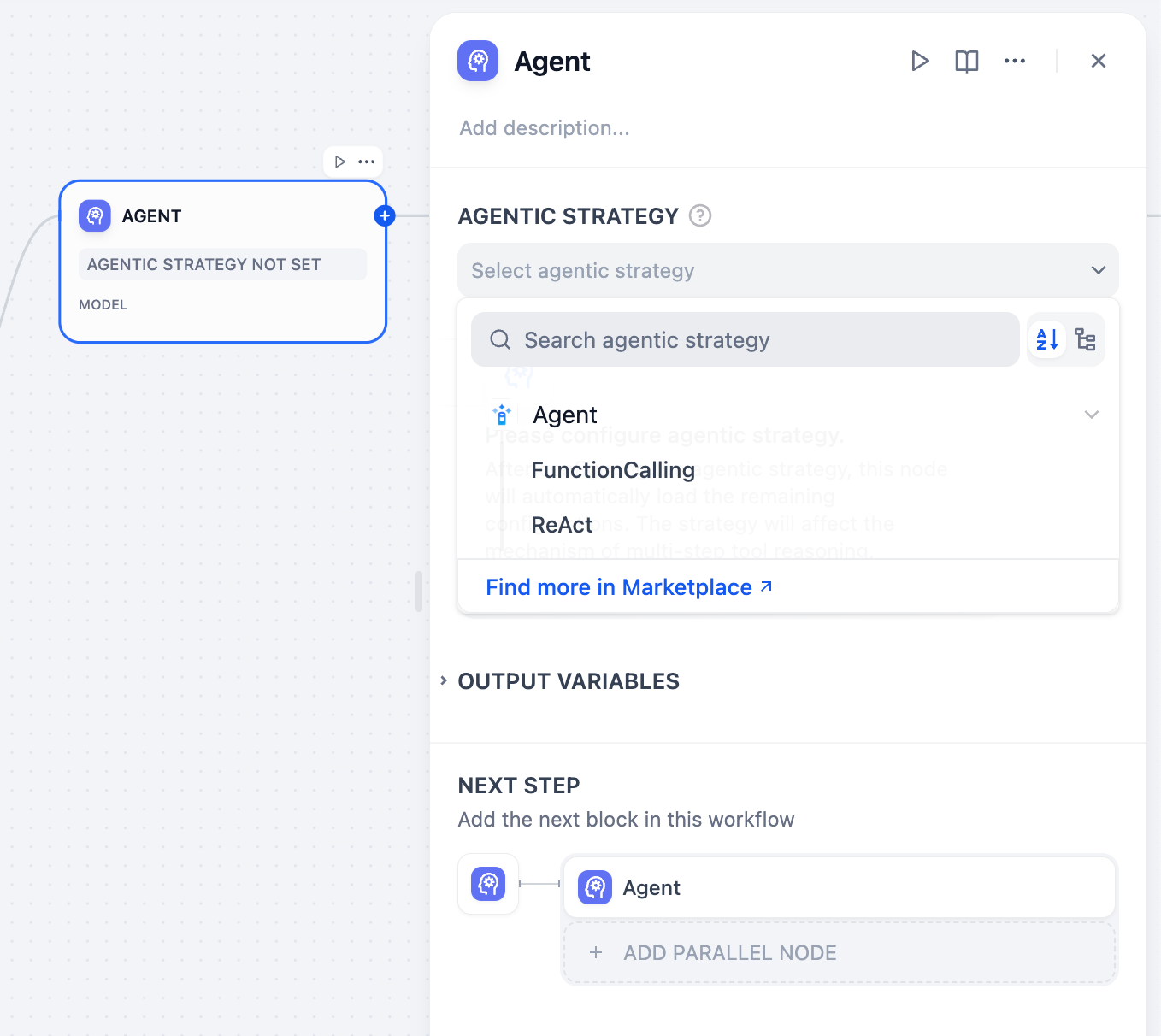
-
- 大規模言語モデルのネイティブな関数呼び出し機能を使用して、toolsパラメータを通じてツール定義を直接渡します。大規模言語モデルは、組み込まれたメカニズムを使用して、いつどのようにツールを呼び出すかを決定します。
-
- GPT-4、Claude 3.5、および関数呼び出しサポートが堅牢な他のモデルに最適です。
-
-
-
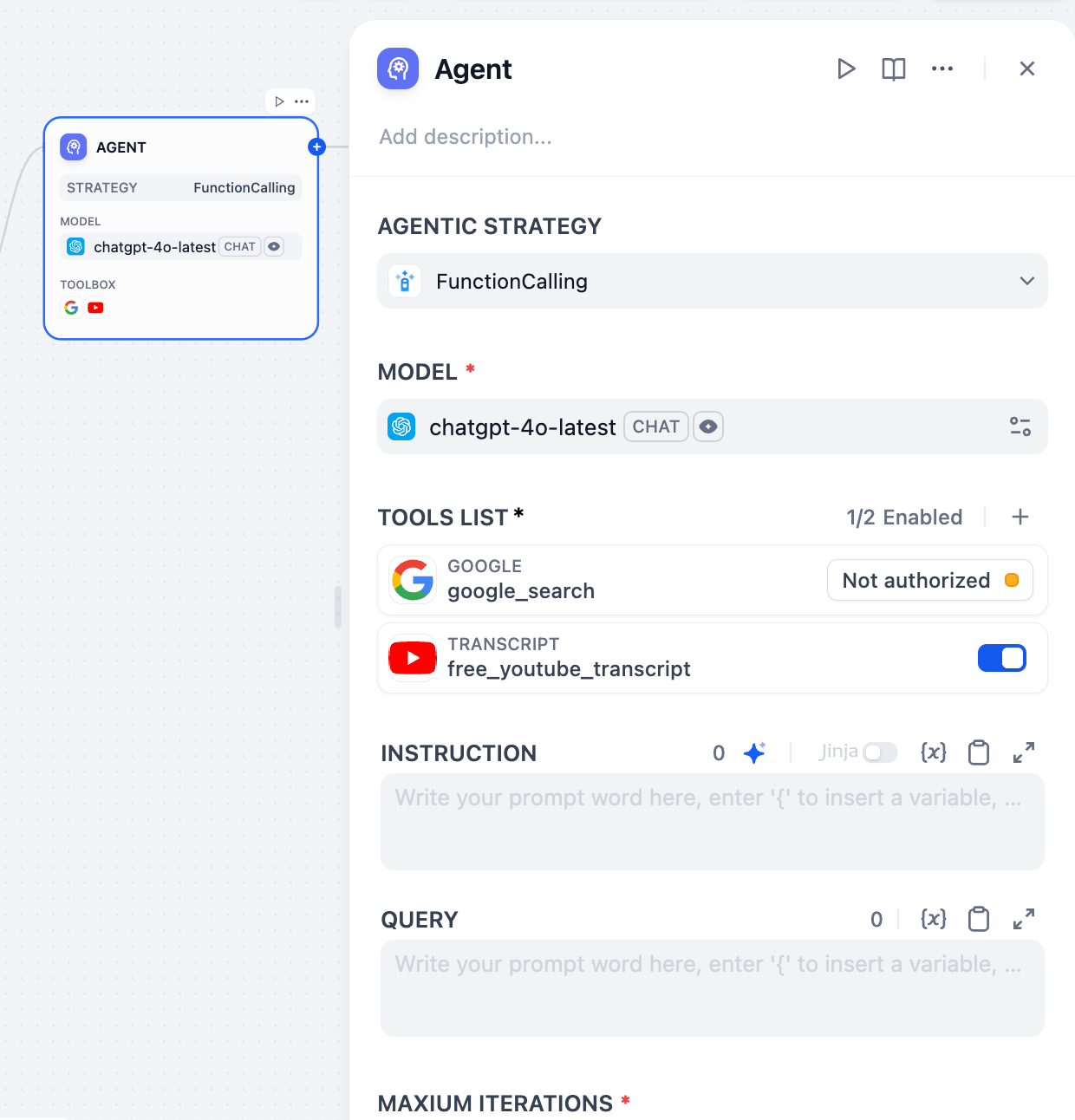
- 明示的な推論ステップを通じて大規模言語モデルを導く構造化されたプロンプトを使用します。透明な行動→観察**サイクルに従います。
+
+ 推論モデルの`text`出力変数を参照すると、フォームには最終回答とともにモデルの思考プロセスが表示されます。
- ネイティブな関数呼び出し機能を持たないモデルや、明示的な推論トレースが必要な場合によく機能します。
-
-
-
-
- **マーケットプレイス → エージェント戦略**から追加戦略をインストールするか、[コミュニティリポジトリ](https://github.com/langgenius/dify-plugins)にカスタム戦略を貢献してください。
-
-
-
-
-
+ ワークフロー変数を参照して、レビュー用のAI生成テキストや受信者の判断に役立つコンテキスト情報などの動的コンテンツを表示できます。
-
-
- 大規模言語モデルのネイティブな関数呼び出し機能を使用して、toolsパラメータを通じてツール定義を直接渡します。大規模言語モデルは、組み込まれたメカニズムを使用して、いつどのようにツールを呼び出すかを決定します。
-
- GPT-4、Claude 3.5、および関数呼び出しサポートが堅牢な他のモデルに最適です。
-
-
-
- 明示的な推論ステップを通じて大規模言語モデルを導く構造化されたプロンプトを使用します。透明な行動→観察**サイクルに従います。
+
+ 推論モデルの`text`出力変数を参照すると、フォームには最終回答とともにモデルの思考プロセスが表示されます。
- ネイティブな関数呼び出し機能を持たないモデルや、明示的な推論トレースが必要な場合によく機能します。
-
-
-
-
- **マーケットプレイス → エージェント戦略**から追加戦略をインストールするか、[コミュニティリポジトリ](https://github.com/langgenius/dify-plugins)にカスタム戦略を貢献してください。
-
-
-
-  -
-
-## 設定
-
-### モデル選択
-
-選択したエージェント戦略をサポートする大規模言語モデルを選択してください。より高性能なモデルは複雑な推論をより良く処理しますが、反復あたりのコストが高くなります。その戦略を使用する場合は、モデルが関数呼び出しをサポートしていることを確認してください。
-
-### ツール設定
-
-エージェントがアクセスできるツールを設定します。各ツールには以下が必要です:
-
-**認証** - ワークスペースで設定された外部サービス用のAPIキーと認証情報
-
-**説明** - ツールの機能と使用タイミングの明確な説明(これがエージェントの意思決定を導きます)
-
-**パラメータ** - 適切な検証を伴うツールが受け入れる必須およびオプションの入力
-
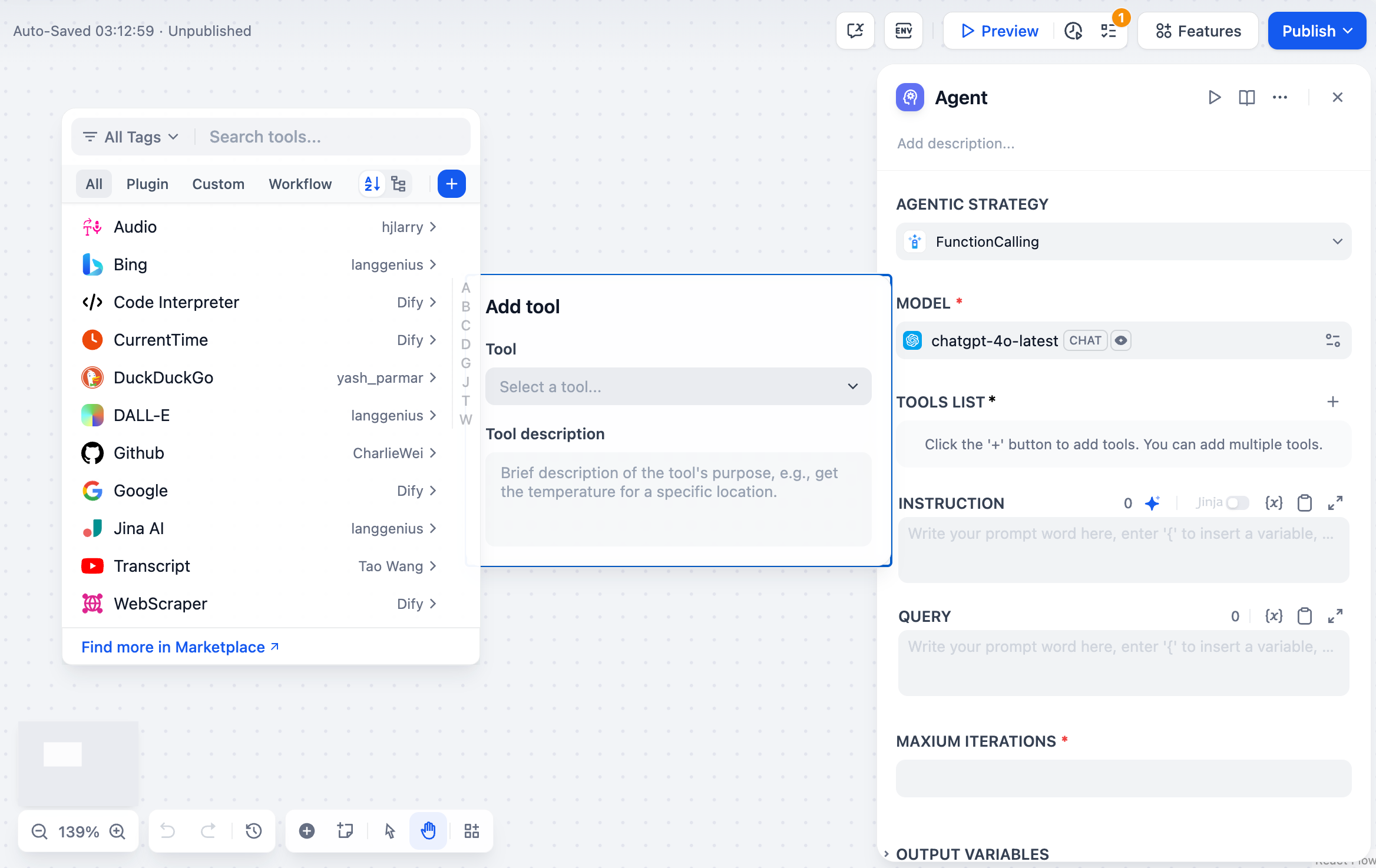
-### 指示とコンテキスト
-
-自然言語の指示を使用してエージェントの役割、目標、コンテキストを定義します。上流のワークフローノードから変数を参照するには、Jinja2構文を使用します。
-
-**クエリ**は、エージェントが作業すべきユーザー入力またはタスクを指定します。これは以前のワークフローノードからの動的コンテンツにすることができます。
-
-
-
-
-
-## 設定
-
-### モデル選択
-
-選択したエージェント戦略をサポートする大規模言語モデルを選択してください。より高性能なモデルは複雑な推論をより良く処理しますが、反復あたりのコストが高くなります。その戦略を使用する場合は、モデルが関数呼び出しをサポートしていることを確認してください。
-
-### ツール設定
-
-エージェントがアクセスできるツールを設定します。各ツールには以下が必要です:
-
-**認証** - ワークスペースで設定された外部サービス用のAPIキーと認証情報
-
-**説明** - ツールの機能と使用タイミングの明確な説明(これがエージェントの意思決定を導きます)
-
-**パラメータ** - 適切な検証を伴うツールが受け入れる必須およびオプションの入力
-
-### 指示とコンテキスト
-
-自然言語の指示を使用してエージェントの役割、目標、コンテキストを定義します。上流のワークフローノードから変数を参照するには、Jinja2構文を使用します。
-
-**クエリ**は、エージェントが作業すべきユーザー入力またはタスクを指定します。これは以前のワークフローノードからの動的コンテンツにすることができます。
-
-
-  -
-
-### 実行制御
+ 回答のみを表示するには、対応するLLMノードで**推論タグ分離を有効化**をオンにしてください。
+
-**最大反復数**は、無限ループを防ぐための安全制限を設定します。タスクの複雑さに基づいて設定してください - 単純なタスクには3-5回の反復が必要ですが、複雑な調査には10-15回必要な場合があります。
+- **入力フィールドで入力を収集**
-**メモリ**は、TokenBufferMemoryを使用してエージェントが記憶する過去のメッセージ数を制御します。より大きなメモリウィンドウはより多くのコンテキストを提供しますが、トークンコストが増加します。これにより、ユーザーが以前のアクションを参照できる会話の継続性が可能になります。
+ 入力フィールドは空のままにするか、変数(例:編集用のLLM出力)または静的テキスト(例:サンプルやデフォルト値)を事前入力して、受信者が編集できるようにすることができます。
-### ツールパラメータ自動生成
+ 各入力フィールドは下流で使用するための変数になります。例えば、編集されたコンテンツをさらなる処理に渡したり、フィードバックをLLMに送信して再生成したりできます。
-ツールには**自動生成**または**手動入力**として設定されたパラメータがあります。自動生成パラメータ(`auto: false`)はエージェントによって自動的に設定され、手動入力パラメータはツールの永続的な設定の一部となる明示的な値が必要です。
+### ユーザーアクション
-
+受信者がクリックできる決定ボタンを定義します。各ボタンは個別の実行ブランチに対応します。
-## 出力変数
+例えば、`Post`ブランチはコンテンツの公開をトリガーするノードにつながり、`Regenerate`ブランチはLLMノードにループバックしてコンテンツを修正することができます。
-エージェントノードは以下を含む包括的な出力を提供します:
-
-**最終回答** - クエリに対するエージェントの最終的な応答
-
-**ツール出力** - 実行中の各ツール呼び出しからの結果
-
-**推論トレース** - JSON出力で利用可能なステップバイステップの決定プロセス(特に推論と行動戦略で詳細)
-
-**反復回数** - 使用された推論サイクルの数
-
-**成功ステータス** - エージェントがタスクを正常に完了したかどうか
-
-**エージェントログ** - ツール呼び出しのデバッグと監視のためのメタデータを含む構造化されたログイベント
-
-## 使用例
-
-**調査と分析** - エージェントは複数のソースを自律的に検索し、情報を統合し、包括的。
-
-**トラブルシューティング** - エージェントが情報を収集し、仮説をテストし、発見に基づいてアプローチを適応させる必要がある診断タスク。
-
-**マルチステップデータ処理** - 次のアクションが中間結果に依存する複雑なワークフロー。
-
-**動的API統合** - API呼び出しの順序が事前に決定できない応答と条件に依存するシナリオ。
-
-## ベストプラクティス
-
-**明確なツール説明**は、エージェントが各ツールをいつどのように効果的に使用するかを理解するのに役立ちます。
-
-**適切な反復制限**は、複雑なタスクに対して十分な柔軟性を確保しながら、暴走コストを防ぎます。
-
-**詳細な指示**は、エージェントの役割、目標、制約や好みについてのコンテキストを提供します。
-
-**メモリ管理**は、使用例の要件に基づいて、コンテキスト保持とトークン効率のバランスを取ります。
+
+ プリセットのボタンスタイルを使用して、アクションを視覚的に区別します。
+
+ 例えば、`Approve`のような主要なアクションには目立つスタイルを使用し、副次的なオプションにはより控えめなスタイルを使用します。
+
\ No newline at end of file
diff --git a/zh/use-dify/nodes/agent.mdx b/zh/use-dify/nodes/agent.mdx
index 0bfc77c28..106d38a33 100644
--- a/zh/use-dify/nodes/agent.mdx
+++ b/zh/use-dify/nodes/agent.mdx
@@ -1,117 +1,36 @@
----
-title: "智能代理"
-icon: "robot"
----
-
+### 表单内容
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/agent)。
+自定义请求表单中显示的内容:
-智能代理节点让你的大型语言模型自主控制工具,使其能够迭代决定使用哪些工具以及何时使用它们。智能代理不是预先规划每一步,而是动态地推理问题,根据需要调用工具来完成复杂任务。
-
-
-
-
+- **使用 Markdown 格式化和组织内容**
-## 智能代理策略
+ 使用标题、列表、粗体文本、链接和其他 Markdown 元素来清晰地呈现信息。
-智能代理策略定义了你的智能代理如何思考和行动。选择最适合你的模型能力和任务需求的方法。
+- **使用变量显示动态数据**
-
-
-
+ 引用工作流变量来显示动态内容,例如供审阅的 AI 生成文本或任何有助于接收者做出决策的上下文信息。
-
-
- 使用大型语言模型的原生函数调用能力,通过工具参数直接传递工具定义。大型语言模型使用其内置机制决定何时以及如何调用工具。
-
- 最适合像 GPT-4、Claude 3.5 和其他具有强大函数调用支持的模型。
-
-
-
- 使用结构化提示词来引导大型语言模型通过明确的推理步骤。遵循**思维 → 行动 → 观察**循环进行透明的决策制定。
+
+ 如果你引用推理模型的 `text` 输出变量,表单将显示模型的思考过程以及最终答案。
- 适用于可能没有原生函数调用能力的模型,或者当你需要明确推理轨迹时。
-
-
-
-
- 从**应用市场 → 智能代理策略**安装其他策略,或向[社区仓库](https://github.com/langgenius/dify-plugins)贡献自定义策略。
-
-
-
-
-
-
-## 配置
-
-### 模型选择
-
-选择支持你所选智能代理策略的大型语言模型。更强大的模型能更好地处理复杂推理,但每次迭代成本更高。如果使用函数调用策略,请确保你的模型支持函数调用。
-
-### 工具配置
-
-配置你的智能代理可以访问的工具。每个工具需要:
-
-**授权** - 在工作空间中配置的外部服务的 API 密钥和凭据
-
-**描述** - 清楚说明工具的作用以及何时使用它(这指导智能代理的决策制定)
-
-**参数** - 工具接受的必需和可选输入,带有适当的验证
-
-### 指令和上下文
-
-使用自然语言指令定义智能代理的角色、目标和上下文。使用 Jinja2 语法引用上游工作流节点的变量。
-
-**查询**指定智能代理应该处理的用户输入或任务。这可以是来自先前工作流节点的动态内容。
-
-
-
-
-
-### 执行控制
+ 如果只想显示答案,请为相应的 LLM 节点开启**启用推理标签分离**选项。
+
-**最大迭代次数**设置安全限制以防止无限循环。根据任务复杂性进行配置 - 简单任务需要 3-5 次迭代,而复杂研究可能需要 10-15 次。
+- **使用输入字段收集信息**
-**记忆**控制智能代理使用 TokenBufferMemory 记提供更多上下文,但会增加标记成本。这使得对话连续性成为可能,用户可以引用以前的行动。
+ 输入字段可以为空,或使用变量预填充(例如,供优化的 LLM 输出)或静态文本预填充(例如,示例或默认值),接收者可以编辑这些内容。
-### 工具参数自动生成
+ 每个输入字段都会成为一个变量,可供下游使用。例如,将编辑后的内容传递给后续处理,或将反馈发送给 LLM 进行重新生成。
-工具可以将参数配置为**自动生成**或**手动输入**。自动生成的参数(`auto: false`)由智能代理自动填充,而手动输入参数需要明确的值,这些值成为工具永久配置的一部分。
+### 用户操作
-
+定义接收者可以点击的决策按钮。每个按钮对应一个独立的执行分支。
-## 输出变量
+例如,`Post` 分支可能连接到触发内容发布的节点,而 `Regenerate` 分支可能循环回 LLM 节点来修改内容。
-智能代理节点提供全面的输出,包括:
-
-**最终答案** - 智能代理对查询的最终响应
-
-**工具输出** - 执行期间每次工具调用的结果
-
-**推理轨迹** - 逐步决策过程(推理与行动策略特别详细)在 JSON 输出中可用
-
-**迭代计数** - 使用的推理循环次数
-
-**成功状态** - 智能代理是否成功完成任务
-
-**智能代理日志** - 带有元数据的结构化日志事件,用于调试和监控工具调用
-
-## 用例
-
-**研究与分析** - 智能代理可以自主搜索多个来源,综合信息,并提供全面的答案。
-
-**故障排除** - 诊断任务,智能代理需要收集信息、测试假设,并根据发现调整其方法。
-
-**多步数据处理** - 复杂的工作流,其中下一个行动取决于中间结果。
-
-**动态 API 集成** - API 调用序列取决于无法预先确定的响应和条件的场景。
-
-## 最佳实践
-
-**清晰的工具描述**帮助智能代理了解何时以及如何有效使用每个工具。
-
-**适当的迭代限制**防止失控成本,同时为复杂任务提供足够的灵活性。
-
-**详细的指令**提供关于智能代理角色、目标以及任何约束或偏好的上下文。
-
-**记忆管理**根据你的用例要求平衡上下文保留与标记效率。
+
+ 使用预设的按钮样式来直观地区分不同操作。
+
+ 例如,对于 `Approve` 等关键操作使用醒目样式,对于次要选项使用较为低调的样式。
+
\ No newline at end of file
-
-
-### 実行制御
+ 回答のみを表示するには、対応するLLMノードで**推論タグ分離を有効化**をオンにしてください。
+
-**最大反復数**は、無限ループを防ぐための安全制限を設定します。タスクの複雑さに基づいて設定してください - 単純なタスクには3-5回の反復が必要ですが、複雑な調査には10-15回必要な場合があります。
+- **入力フィールドで入力を収集**
-**メモリ**は、TokenBufferMemoryを使用してエージェントが記憶する過去のメッセージ数を制御します。より大きなメモリウィンドウはより多くのコンテキストを提供しますが、トークンコストが増加します。これにより、ユーザーが以前のアクションを参照できる会話の継続性が可能になります。
+ 入力フィールドは空のままにするか、変数(例:編集用のLLM出力)または静的テキスト(例:サンプルやデフォルト値)を事前入力して、受信者が編集できるようにすることができます。
-### ツールパラメータ自動生成
+ 各入力フィールドは下流で使用するための変数になります。例えば、編集されたコンテンツをさらなる処理に渡したり、フィードバックをLLMに送信して再生成したりできます。
-ツールには**自動生成**または**手動入力**として設定されたパラメータがあります。自動生成パラメータ(`auto: false`)はエージェントによって自動的に設定され、手動入力パラメータはツールの永続的な設定の一部となる明示的な値が必要です。
+### ユーザーアクション
-
+受信者がクリックできる決定ボタンを定義します。各ボタンは個別の実行ブランチに対応します。
-## 出力変数
+例えば、`Post`ブランチはコンテンツの公開をトリガーするノードにつながり、`Regenerate`ブランチはLLMノードにループバックしてコンテンツを修正することができます。
-エージェントノードは以下を含む包括的な出力を提供します:
-
-**最終回答** - クエリに対するエージェントの最終的な応答
-
-**ツール出力** - 実行中の各ツール呼び出しからの結果
-
-**推論トレース** - JSON出力で利用可能なステップバイステップの決定プロセス(特に推論と行動戦略で詳細)
-
-**反復回数** - 使用された推論サイクルの数
-
-**成功ステータス** - エージェントがタスクを正常に完了したかどうか
-
-**エージェントログ** - ツール呼び出しのデバッグと監視のためのメタデータを含む構造化されたログイベント
-
-## 使用例
-
-**調査と分析** - エージェントは複数のソースを自律的に検索し、情報を統合し、包括的。
-
-**トラブルシューティング** - エージェントが情報を収集し、仮説をテストし、発見に基づいてアプローチを適応させる必要がある診断タスク。
-
-**マルチステップデータ処理** - 次のアクションが中間結果に依存する複雑なワークフロー。
-
-**動的API統合** - API呼び出しの順序が事前に決定できない応答と条件に依存するシナリオ。
-
-## ベストプラクティス
-
-**明確なツール説明**は、エージェントが各ツールをいつどのように効果的に使用するかを理解するのに役立ちます。
-
-**適切な反復制限**は、複雑なタスクに対して十分な柔軟性を確保しながら、暴走コストを防ぎます。
-
-**詳細な指示**は、エージェントの役割、目標、制約や好みについてのコンテキストを提供します。
-
-**メモリ管理**は、使用例の要件に基づいて、コンテキスト保持とトークン効率のバランスを取ります。
+
+ プリセットのボタンスタイルを使用して、アクションを視覚的に区別します。
+
+ 例えば、`Approve`のような主要なアクションには目立つスタイルを使用し、副次的なオプションにはより控えめなスタイルを使用します。
+
\ No newline at end of file
diff --git a/zh/use-dify/nodes/agent.mdx b/zh/use-dify/nodes/agent.mdx
index 0bfc77c28..106d38a33 100644
--- a/zh/use-dify/nodes/agent.mdx
+++ b/zh/use-dify/nodes/agent.mdx
@@ -1,117 +1,36 @@
----
-title: "智能代理"
-icon: "robot"
----
-
+### 表单内容
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/agent)。
+自定义请求表单中显示的内容:
-智能代理节点让你的大型语言模型自主控制工具,使其能够迭代决定使用哪些工具以及何时使用它们。智能代理不是预先规划每一步,而是动态地推理问题,根据需要调用工具来完成复杂任务。
-
-
-
-
+- **使用 Markdown 格式化和组织内容**
-## 智能代理策略
+ 使用标题、列表、粗体文本、链接和其他 Markdown 元素来清晰地呈现信息。
-智能代理策略定义了你的智能代理如何思考和行动。选择最适合你的模型能力和任务需求的方法。
+- **使用变量显示动态数据**
-
-
-
+ 引用工作流变量来显示动态内容,例如供审阅的 AI 生成文本或任何有助于接收者做出决策的上下文信息。
-
-
- 使用大型语言模型的原生函数调用能力,通过工具参数直接传递工具定义。大型语言模型使用其内置机制决定何时以及如何调用工具。
-
- 最适合像 GPT-4、Claude 3.5 和其他具有强大函数调用支持的模型。
-
-
-
- 使用结构化提示词来引导大型语言模型通过明确的推理步骤。遵循**思维 → 行动 → 观察**循环进行透明的决策制定。
+
+ 如果你引用推理模型的 `text` 输出变量,表单将显示模型的思考过程以及最终答案。
- 适用于可能没有原生函数调用能力的模型,或者当你需要明确推理轨迹时。
-
-
-
-
- 从**应用市场 → 智能代理策略**安装其他策略,或向[社区仓库](https://github.com/langgenius/dify-plugins)贡献自定义策略。
-
-
-
-
-
-
-## 配置
-
-### 模型选择
-
-选择支持你所选智能代理策略的大型语言模型。更强大的模型能更好地处理复杂推理,但每次迭代成本更高。如果使用函数调用策略,请确保你的模型支持函数调用。
-
-### 工具配置
-
-配置你的智能代理可以访问的工具。每个工具需要:
-
-**授权** - 在工作空间中配置的外部服务的 API 密钥和凭据
-
-**描述** - 清楚说明工具的作用以及何时使用它(这指导智能代理的决策制定)
-
-**参数** - 工具接受的必需和可选输入,带有适当的验证
-
-### 指令和上下文
-
-使用自然语言指令定义智能代理的角色、目标和上下文。使用 Jinja2 语法引用上游工作流节点的变量。
-
-**查询**指定智能代理应该处理的用户输入或任务。这可以是来自先前工作流节点的动态内容。
-
-
-
-
-
-### 执行控制
+ 如果只想显示答案,请为相应的 LLM 节点开启**启用推理标签分离**选项。
+
-**最大迭代次数**设置安全限制以防止无限循环。根据任务复杂性进行配置 - 简单任务需要 3-5 次迭代,而复杂研究可能需要 10-15 次。
+- **使用输入字段收集信息**
-**记忆**控制智能代理使用 TokenBufferMemory 记提供更多上下文,但会增加标记成本。这使得对话连续性成为可能,用户可以引用以前的行动。
+ 输入字段可以为空,或使用变量预填充(例如,供优化的 LLM 输出)或静态文本预填充(例如,示例或默认值),接收者可以编辑这些内容。
-### 工具参数自动生成
+ 每个输入字段都会成为一个变量,可供下游使用。例如,将编辑后的内容传递给后续处理,或将反馈发送给 LLM 进行重新生成。
-工具可以将参数配置为**自动生成**或**手动输入**。自动生成的参数(`auto: false`)由智能代理自动填充,而手动输入参数需要明确的值,这些值成为工具永久配置的一部分。
+### 用户操作
-
+定义接收者可以点击的决策按钮。每个按钮对应一个独立的执行分支。
-## 输出变量
+例如,`Post` 分支可能连接到触发内容发布的节点,而 `Regenerate` 分支可能循环回 LLM 节点来修改内容。
-智能代理节点提供全面的输出,包括:
-
-**最终答案** - 智能代理对查询的最终响应
-
-**工具输出** - 执行期间每次工具调用的结果
-
-**推理轨迹** - 逐步决策过程(推理与行动策略特别详细)在 JSON 输出中可用
-
-**迭代计数** - 使用的推理循环次数
-
-**成功状态** - 智能代理是否成功完成任务
-
-**智能代理日志** - 带有元数据的结构化日志事件,用于调试和监控工具调用
-
-## 用例
-
-**研究与分析** - 智能代理可以自主搜索多个来源,综合信息,并提供全面的答案。
-
-**故障排除** - 诊断任务,智能代理需要收集信息、测试假设,并根据发现调整其方法。
-
-**多步数据处理** - 复杂的工作流,其中下一个行动取决于中间结果。
-
-**动态 API 集成** - API 调用序列取决于无法预先确定的响应和条件的场景。
-
-## 最佳实践
-
-**清晰的工具描述**帮助智能代理了解何时以及如何有效使用每个工具。
-
-**适当的迭代限制**防止失控成本,同时为复杂任务提供足够的灵活性。
-
-**详细的指令**提供关于智能代理角色、目标以及任何约束或偏好的上下文。
-
-**记忆管理**根据你的用例要求平衡上下文保留与标记效率。
+
+ 使用预设的按钮样式来直观地区分不同操作。
+
+ 例如,对于 `Approve` 等关键操作使用醒目样式,对于次要选项使用较为低调的样式。
+
\ No newline at end of file