diff --git a/ja/use-dify/nodes/doc-extractor.mdx b/ja/use-dify/nodes/doc-extractor.mdx
index 31fc3d887..aaea85b7c 100644
--- a/ja/use-dify/nodes/doc-extractor.mdx
+++ b/ja/use-dify/nodes/doc-extractor.mdx
@@ -1,15 +1,15 @@
---
-title: "ドキュメントエクストラクター"
+title: "ドキュメント抽出器"
description: "AI処理のためにアップロードされたドキュメントからテキストコンテンツを抽出"
---
⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/doc-extractor) を参照してください。
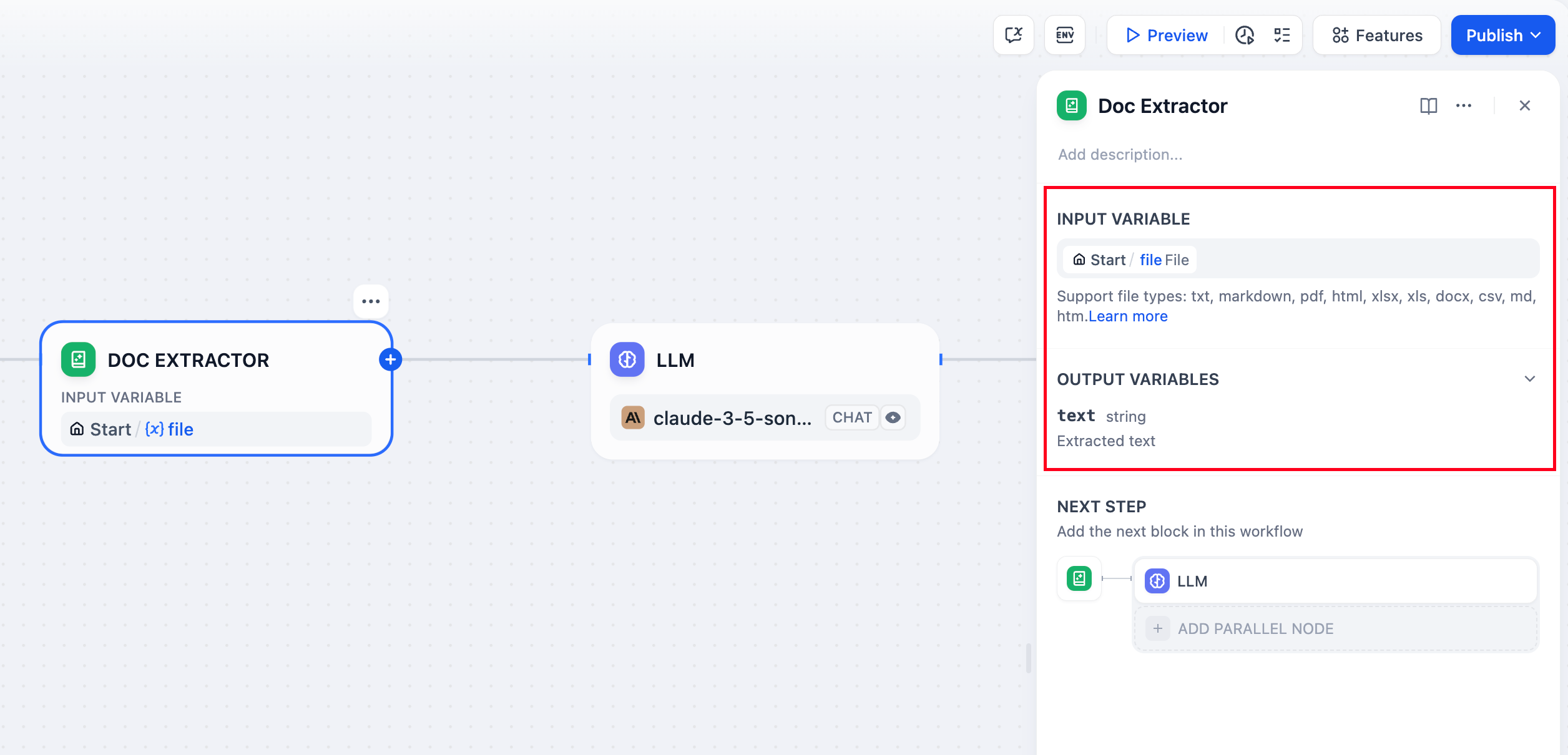
-ドキュメントエクストラクターノードは、アップロードされたファイルを大規模言語モデルが処理できるテキストに変換します。言語モデルはPDFやDOCXなどのドキュメント形式を直接読み取ることができないため、このノードはファイルアップロードとAI分析の間の重要な橋渡し役を果たします。
+ドキュメント抽出器ノードは、アップロードされたファイルを大規模言語モデルが処理できるテキストに変換します。言語モデルはPDFやDOCXなどのドキュメント形式を直接読み取ることができないため、このノードはファイルアップロードとAI分析の間の重要な橋渡し役を果たします。
-
- 
+
+ 
## サポートされているファイル形式
@@ -55,7 +55,7 @@ description: "AI処理のためにアップロードされたドキュメント
## 実装例
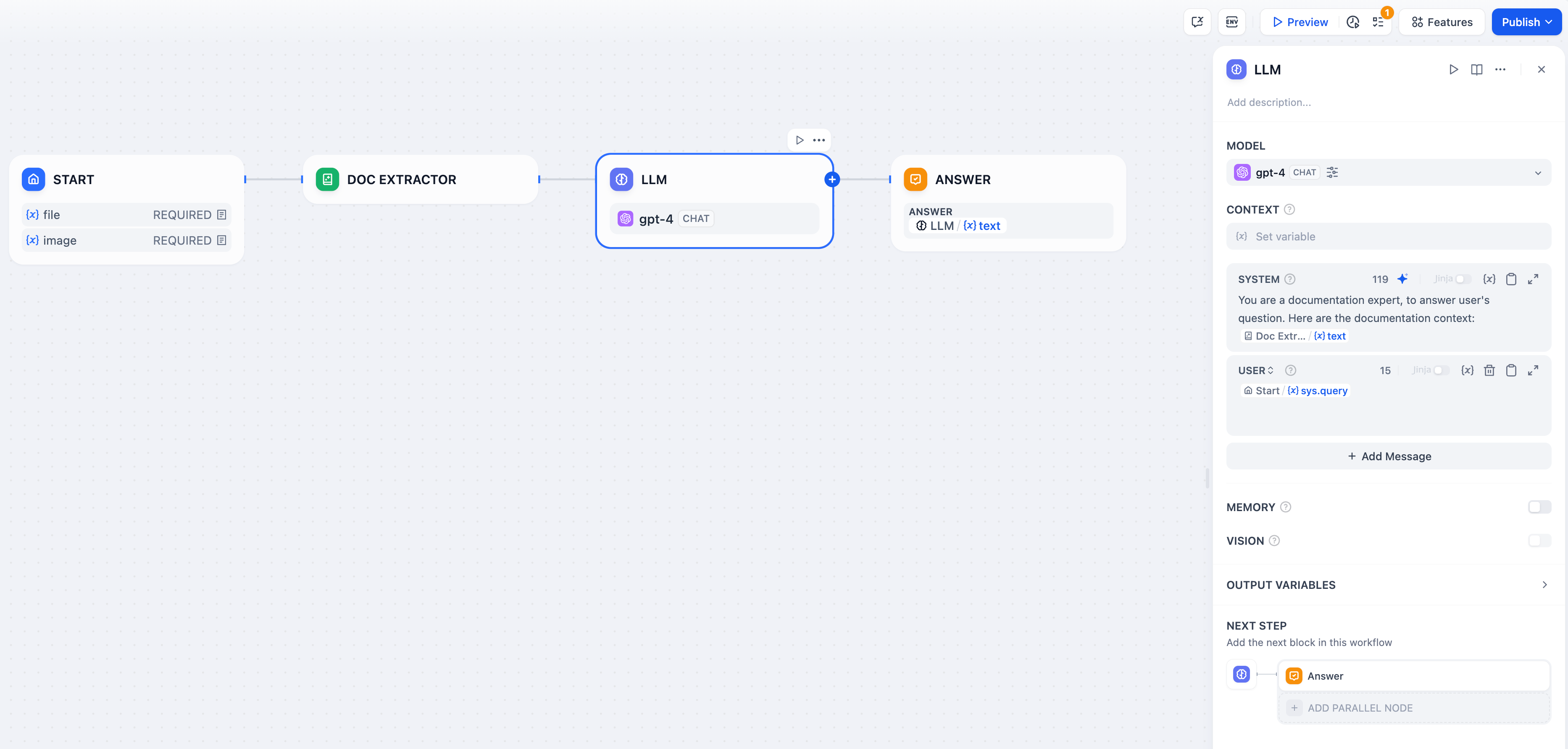
-ドキュメントエクストラクターを使用した完全なドキュメントQ&Aワークフローの例です:
+ドキュメント抽出器を使用した完全なドキュメントQ&Aワークフローの例です:
@@ -65,7 +65,7 @@ description: "AI処理のためにアップロードされたドキュメント
**ファイルアップロード設定** - ユーザーからのドキュメントアップロードを受け入れるために、Startノードでファイル入力を有効にします。
-**テキスト抽出** - ドキュメントエクストラクターを接続して、アップロードされたファイルを処理し、テキストコンテンツを抽出します。
+**テキスト抽出** - ドキュメント抽出器を接続して、アップロードされたファイルを処理し、テキストコンテンツを抽出します。
**AI処理** - 抽出されたテキストを大規模言語モデルのプロンプトで分析、要約、または質問応答に使用します。
@@ -89,7 +89,7 @@ description: "AI処理のためにアップロードされたドキュメント
## 処理の考慮事項
-ドキュメントエクストラクターは、異なるファイル形式に最適化された特殊な解析ライブラリを使用します。可能な限りテキスト構造と書式を保持し、抽出されたコンテンツを大規模言語モデル処理により有用にします。
+ドキュメント抽出器は、異なるファイル形式に最適化された特殊な解析ライブラリを使用します。可能な限りテキスト構造と書式を保持し、抽出されたコンテンツを大規模言語モデル処理により有用にします。
### ファイル形式処理
diff --git a/ja/use-dify/tutorials/article-reader.mdx b/ja/use-dify/tutorials/article-reader.mdx
index 22f11d8c4..5ade8a466 100644
--- a/ja/use-dify/tutorials/article-reader.mdx
+++ b/ja/use-dify/tutorials/article-reader.mdx
@@ -34,13 +34,13 @@ DifyでChatflowを作成し、モデルプロバイダーを追加して、十
ビジネスシーンに応じて、適切なファイルアップロード方法を選択してください。
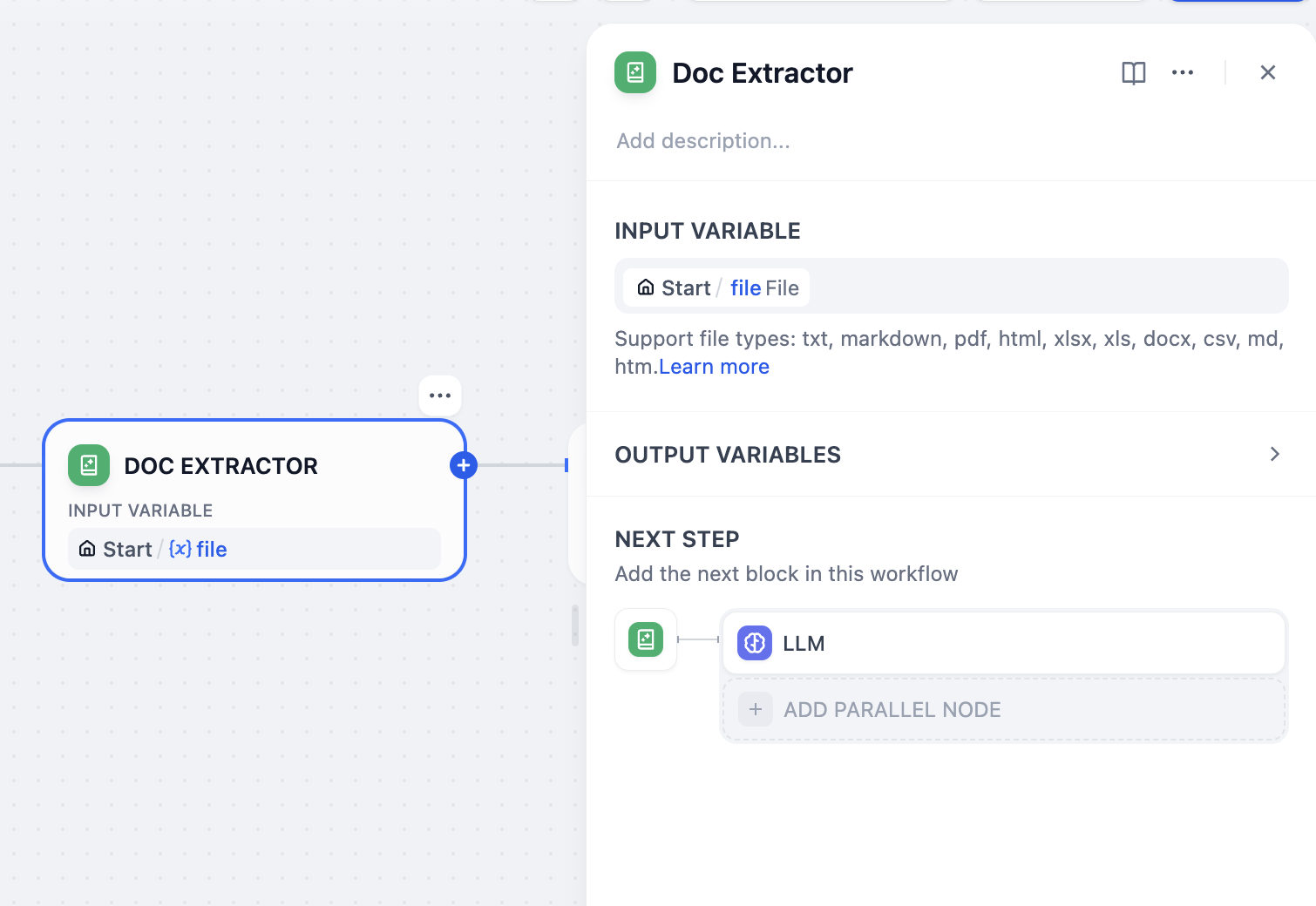
-### **テキスト抽出ツール**
+### **ドキュメント抽出器**
LLMはファイルを直接読み取ることができません。これは、多くのユーザーがファイルアップロード機能を初めて使用する際に抱く誤解であり、ファイルを変数としてLLMノードに適用すればよいと考えがちですが、実際にはLLMが読み取る内容は何もありません。
-そのため、Difyではテキスト抽出ツールを導入しており、このノードはファイル変数からテキストを抽出し、テキスト形式の変数を出力します。
+そのため、Difyではドキュメント抽出器を導入しており、このノードはファイル変数からテキストを抽出し、テキスト形式の変数を出力します。
-開始ノードのファイル変数を入力として、テキスト抽出ツールはドキュメント形式のファイルをテキスト形式の変数に変換します。
+開始ノードのファイル変数を入力として、ドキュメント抽出器はドキュメント形式のファイルをテキスト形式の変数に変換します。
diff --git a/versions/legacy/ja/user-guide/build-app/flow-app/additional-feature.mdx b/versions/legacy/ja/user-guide/build-app/flow-app/additional-feature.mdx
index b618a9230..93b9d7914 100644
--- a/versions/legacy/ja/user-guide/build-app/flow-app/additional-feature.mdx
+++ b/versions/legacy/ja/user-guide/build-app/flow-app/additional-feature.mdx
@@ -79,7 +79,7 @@ LLMは直接ドキュメントファイルを読み取る機能を持ってい
1. Features 機能を有効にし、ファイルタイプで "ドキュメント" のみを選択します。
2. [ドキュメント抽出](/ja-jp/guides/workflow/nodes/doc-extractor) ノードの入力変数で `sys.files` 変数を選択します。
-3. LLM ノードを追加し、システムプロンプトでドキュメント抽出ノードの出力変数を選択します。
+3. LLM ノードを追加し、システムプロンプトでドキュメント抽出器ノードの出力変数を選択します。
4. 最後に "回答" ノードを追加し、LLM ノードの出力変数を記入します。
この方法で構築された チャットフロー アプリは、アップロードされたファイルの内容を記憶しません。アプリの使用者は毎回チャットボックスでドキュメントファイルをアップロードする必要があります。アプリにアップロードされたファイルの内容を記憶させる場合は、[「ファイルアップロード:開始ノードに変数を追加」](/ja-jp/guides/workflow/file-upload)を参照してください。
@@ -100,10 +100,10 @@ LLMは直接ドキュメントファイルを読み取る機能を持ってい
1. Features 機能を有効にし、ファイルタイプで "画像" および "ドキュメントファイル" を選択します。
2. 二つのリスト操作ノードを追加し、"フィルタリング" 条件で画像とドキュメント変数を抽出します。
-3. ドキュメントファイル変数を抽出し、"ドキュメント抽出機" ノードに渡し、画像ファイル変数を抽出し、LLM ノードに渡します。
+3. ドキュメントファイル変数を抽出し、"ドキュメント抽出器" ノードに渡し、画像ファイル変数を抽出し、LLM ノードに渡します。
4. 最後に "回答" ノードを追加し、LLM ノードの出力変数を記入します。
-アプリ使用者が文書ファイルと画像を同時にアップロードした場合、文書ファイルは自動的に文書抽出機ノードに送られ、画像ファイルはLLMノードに送られて、ファイルを共同で処理することができます。
+アプリ使用者が文書ファイルと画像を同時にアップロードした場合、文書ファイルは自動的にドキュメント抽出器ノードに送られ、画像ファイルはLLMノードに送られて、ファイルを共同で処理することができます。
* **音声・動画ファイル**
diff --git a/versions/legacy/ja/user-guide/build-app/flow-app/file-upload.mdx b/versions/legacy/ja/user-guide/build-app/flow-app/file-upload.mdx
index f208c00cf..d6910bc48 100644
--- a/versions/legacy/ja/user-guide/build-app/flow-app/file-upload.mdx
+++ b/versions/legacy/ja/user-guide/build-app/flow-app/file-upload.mdx
@@ -25,7 +25,7 @@ version: '日本語'
* ファイルのアップロード:柔軟性が高く、ユーザーは特定のニーズに応じて様々なタイプのファイルをアップロードできます。
* ナレッジベース:内容は比較的固定されていますが、複数のセッションで再利用が可能です。
3. **情報処理**:
- * ファイルのアップロード:ファイルの内容をLLMが理解できるテキストに変換するためには、ドキュメントエクストラクターなどのツールが必要です。このツールは、ファイルから必要な情報を抽出し、モデルが処理できる形式に整えます。
+ * ファイルのアップロード:ファイルの内容をLLMが理解できるテキストに変換するためには、ドキュメント抽出器などのツールが必要です。このツールは、ファイルから必要な情報を抽出し、モデルが処理できる形式に整えます。
* ナレッジベース:通常、前処理とインデックス作業が完了しているため、直接検索して情報を取得できます。
4. **アプリケーションシーン**:
* ファイルのアップロード:ユーザー固有の文書を処理する必要があるシーンで非常に有効です。例えば、文書分析やパーソナライズされた学習支援などが挙げられます。
@@ -96,13 +96,13 @@ Difyは、[チャットフロー](/ja-jp/guides/workflow/concepts) と [ワー
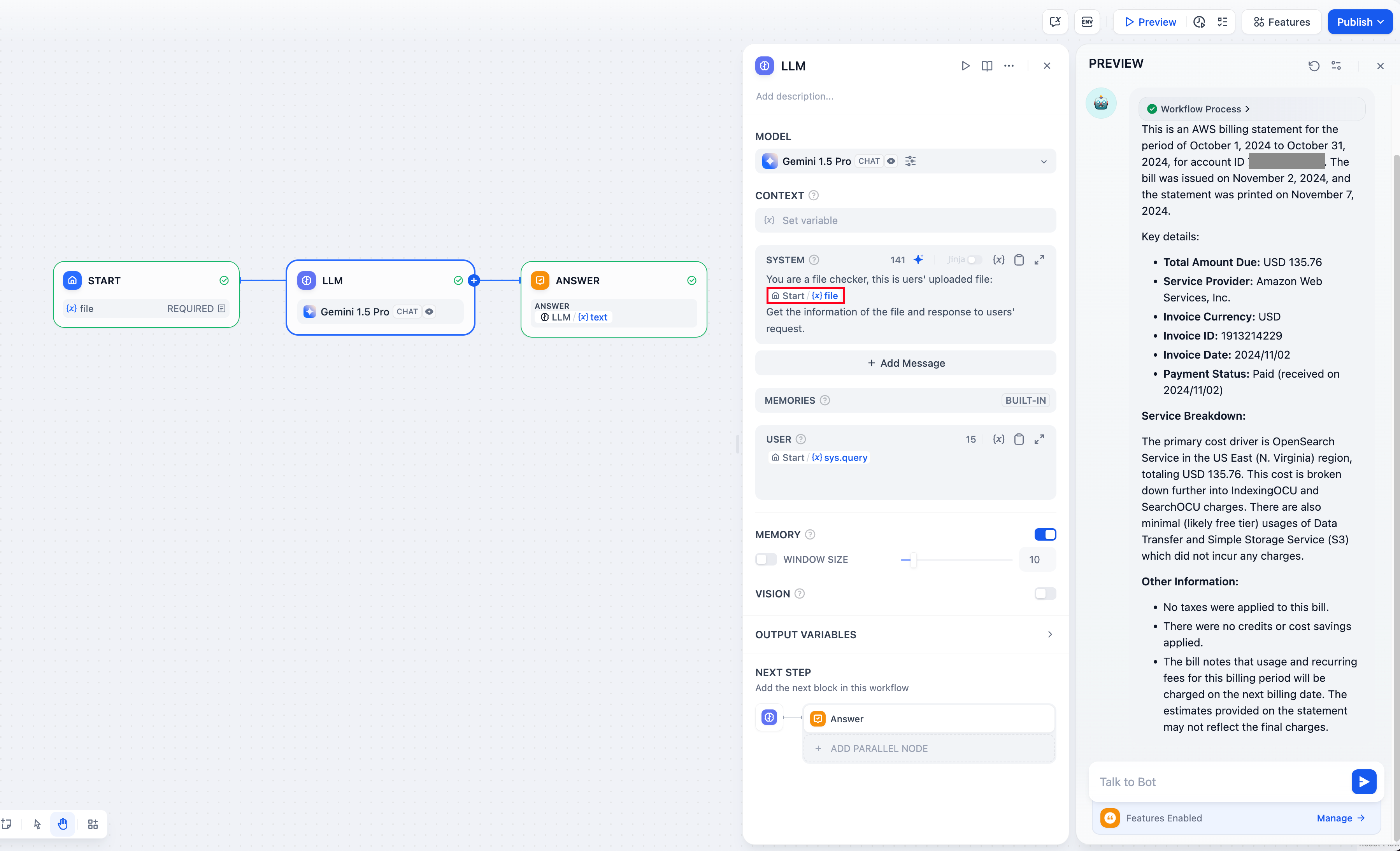 -機能を有効にしても、LLM(大規模言語モデル)がファイルを直接読み取ることはできません。ファイルをLLMが理解できるテキスト形式に変換するには、ドキュメント抽出ツールが必要です。
+機能を有効にしても、LLM(大規模言語モデル)がファイルを直接読み取ることはできません。ファイルをLLMが理解できるテキスト形式に変換するには、ドキュメント抽出器が必要です。
* 音声ファイルについては、`gpt-4o-audio-preview`などのマルチモーダル入力に対応したモデルを使用することで、音声を直接処理できます。この場合、追加のエクストラクタは必要ありません。
* 映像やその他のファイルタイプについては、対応するエクストラクタがまだ用意されておらず、外部ツールを統合するためには開発者が外部ツールにアクセスする必要があります。[外部ツール](/ja-jp/guides/workflow/nodes/iteration)を接続して処理する必要があります。
-2. [テキスト抽出ツール](/ja-jp/guides/workflow/nodes/doc-extractor)ノードを追加し、入力変数で `sys.files` 変数を選択します。
-3. LLMノードを追加し、システムプロンプトでテキスト抽出ツールノードの出力変数を選択します。
+2. [ドキュメント抽出器](/ja-jp/guides/workflow/nodes/doc-extractor)ノードを追加し、入力変数で `sys.files` 変数を選択します。
+3. LLMノードを追加し、システムプロンプトでドキュメント抽出器ノードの出力変数を選択します。
4. 最後に「直接応答」ノードを追加し、LLMノードの出力変数を入力します。
@@ -138,7 +138,7 @@ LLMが対話中にファイル内容を記憶する機能を追加したい場
ファイル変数の使用方法には主に2つのアプローチがあります:
1. ツールノードを利用してファイルの内容を変換する:
- * ドキュメント形式のファイルの場合、「ドキュメントエクストラクタ」ノードを使ってファイルの内容をテキスト形式に変換できます。
+ * ドキュメント形式のファイルの場合、「ドキュメント抽出器」ノードを使ってファイルの内容をテキスト形式に変換できます。
* この方法は、ファイルの内容をモデルが理解できる形式(例: string、array[string]など)に変換する必要がある場合に適しています。
2. LLMノード内でファイル変数を直接使用する:
* 特定の種類のファイル(例: 画像)の場合、LLMノード内でファイル変数を直接使用することができます。
@@ -146,17 +146,17 @@ LLMが対話中にファイル内容を記憶する機能を追加したい場
どちらの方法を選ぶかは、ファイルの種類と具体的な要件によります。以下で、これら2つの方法の具体的な手順について詳しく説明します。
-#### 2. テキスト抽出ツールノードの追加
+#### 2. ドキュメント抽出器ノードの追加
-ファイルをアップロードすると、そのファイルは「単一ファイル」変数に保存されます。しかし、LLMは変数内のファイルを直接読み込むことができないため、まず[**「テキスト抽出ツール」**](/ja-jp/guides/workflow/nodes/doc-extractor)ノードを追加する必要があります。
+ファイルをアップロードすると、そのファイルは「単一ファイル」変数に保存されます。しかし、LLMは変数内のファイルを直接読み込むことができないため、まず[**「ドキュメント抽出器」**](/ja-jp/guides/workflow/nodes/doc-extractor)ノードを追加する必要があります。
-「開始」ノード内のファイル変数を **「テキスト抽出ツール」** ノードの入力変数として使用します。
+「開始」ノード内のファイル変数を **「ドキュメント抽出器」** ノードの入力変数として使用します。
-機能を有効にしても、LLM(大規模言語モデル)がファイルを直接読み取ることはできません。ファイルをLLMが理解できるテキスト形式に変換するには、ドキュメント抽出ツールが必要です。
+機能を有効にしても、LLM(大規模言語モデル)がファイルを直接読み取ることはできません。ファイルをLLMが理解できるテキスト形式に変換するには、ドキュメント抽出器が必要です。
* 音声ファイルについては、`gpt-4o-audio-preview`などのマルチモーダル入力に対応したモデルを使用することで、音声を直接処理できます。この場合、追加のエクストラクタは必要ありません。
* 映像やその他のファイルタイプについては、対応するエクストラクタがまだ用意されておらず、外部ツールを統合するためには開発者が外部ツールにアクセスする必要があります。[外部ツール](/ja-jp/guides/workflow/nodes/iteration)を接続して処理する必要があります。
-2. [テキスト抽出ツール](/ja-jp/guides/workflow/nodes/doc-extractor)ノードを追加し、入力変数で `sys.files` 変数を選択します。
-3. LLMノードを追加し、システムプロンプトでテキスト抽出ツールノードの出力変数を選択します。
+2. [ドキュメント抽出器](/ja-jp/guides/workflow/nodes/doc-extractor)ノードを追加し、入力変数で `sys.files` 変数を選択します。
+3. LLMノードを追加し、システムプロンプトでドキュメント抽出器ノードの出力変数を選択します。
4. 最後に「直接応答」ノードを追加し、LLMノードの出力変数を入力します。
@@ -138,7 +138,7 @@ LLMが対話中にファイル内容を記憶する機能を追加したい場
ファイル変数の使用方法には主に2つのアプローチがあります:
1. ツールノードを利用してファイルの内容を変換する:
- * ドキュメント形式のファイルの場合、「ドキュメントエクストラクタ」ノードを使ってファイルの内容をテキスト形式に変換できます。
+ * ドキュメント形式のファイルの場合、「ドキュメント抽出器」ノードを使ってファイルの内容をテキスト形式に変換できます。
* この方法は、ファイルの内容をモデルが理解できる形式(例: string、array[string]など)に変換する必要がある場合に適しています。
2. LLMノード内でファイル変数を直接使用する:
* 特定の種類のファイル(例: 画像)の場合、LLMノード内でファイル変数を直接使用することができます。
@@ -146,17 +146,17 @@ LLMが対話中にファイル内容を記憶する機能を追加したい場
どちらの方法を選ぶかは、ファイルの種類と具体的な要件によります。以下で、これら2つの方法の具体的な手順について詳しく説明します。
-#### 2. テキスト抽出ツールノードの追加
+#### 2. ドキュメント抽出器ノードの追加
-ファイルをアップロードすると、そのファイルは「単一ファイル」変数に保存されます。しかし、LLMは変数内のファイルを直接読み込むことができないため、まず[**「テキスト抽出ツール」**](/ja-jp/guides/workflow/nodes/doc-extractor)ノードを追加する必要があります。
+ファイルをアップロードすると、そのファイルは「単一ファイル」変数に保存されます。しかし、LLMは変数内のファイルを直接読み込むことができないため、まず[**「ドキュメント抽出器」**](/ja-jp/guides/workflow/nodes/doc-extractor)ノードを追加する必要があります。
-「開始」ノード内のファイル変数を **「テキスト抽出ツール」** ノードの入力変数として使用します。
+「開始」ノード内のファイル変数を **「ドキュメント抽出器」** ノードの入力変数として使用します。
 -「テキスト抽出ツール」ノードの出力変数をLLMノードのシステムプロンプトに貼り付けます。
+「ドキュメント抽出器」ノードの出力変数をLLMノードのシステムプロンプトに貼り付けます。
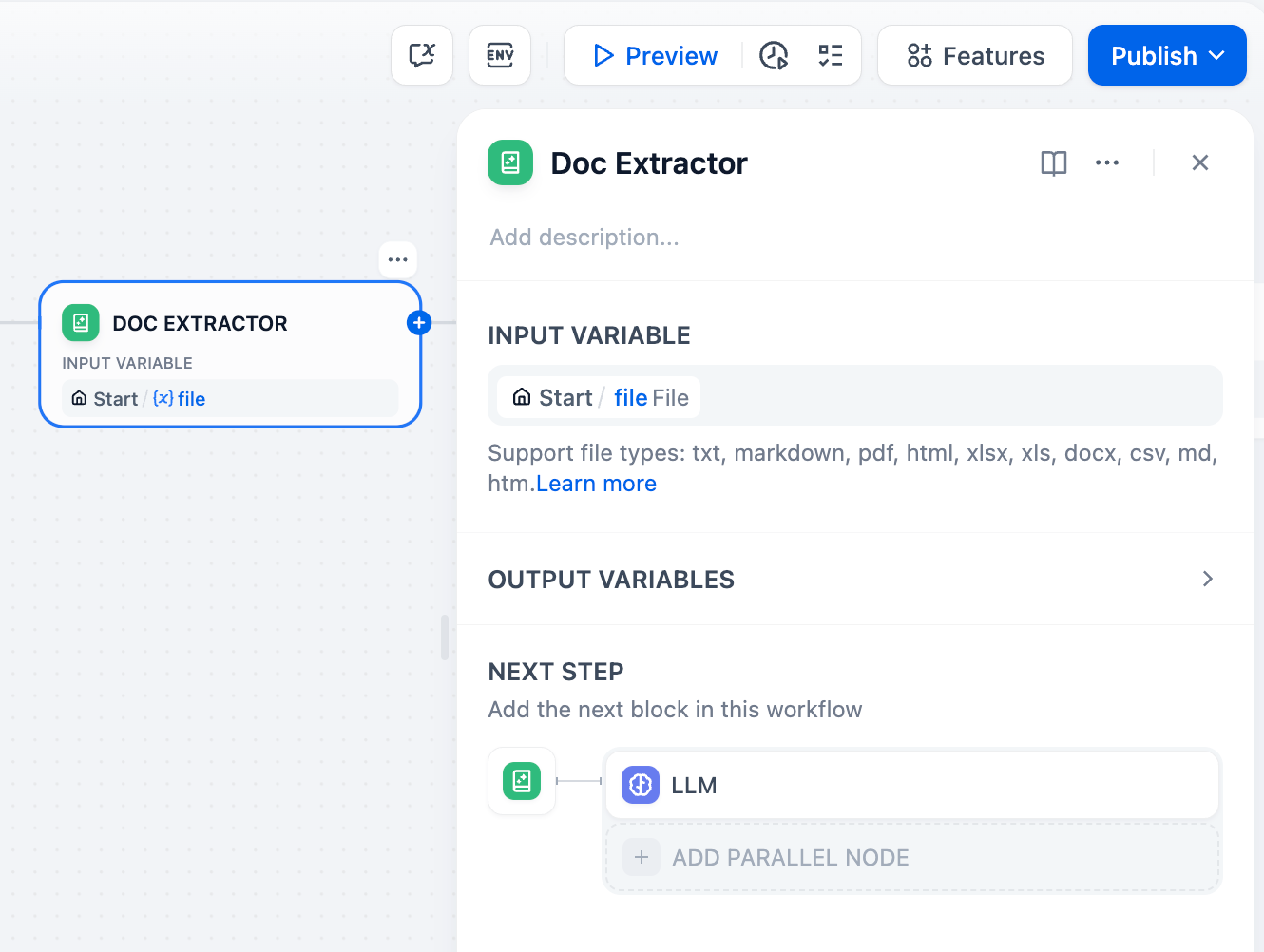
-「テキスト抽出ツール」ノードの出力変数をLLMノードのシステムプロンプトに貼り付けます。
+「ドキュメント抽出器」ノードの出力変数をLLMノードのシステムプロンプトに貼り付けます。
 diff --git a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/doc-extractor.mdx b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/doc-extractor.mdx
index 6199e825c..1ffc149ef 100644
--- a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/doc-extractor.mdx
+++ b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/doc-extractor.mdx
@@ -1,11 +1,11 @@
---
-title: テキスト抽出ツール
+title: ドキュメント抽出器
version: '日本語'
---
### 定義
-LLM(大規模言語モデル)は文書の内容を直接読み取ることができません。そのため、ユーザーがアップロードした文書を”テキスト抽出ツールノード”を介して解析し、文書ファイルの情報を読み取り、テキストに変換して内容をLLMに送信する必要があります。
+LLM(大規模言語モデル)は文書の内容を直接読み取ることができません。そのため、ユーザーがアップロードした文書を”ドキュメント抽出器ノード”を介して解析し、文書ファイルの情報を読み取り、テキストに変換して内容をLLMに送信する必要があります。
### 適用シナリオ
@@ -14,20 +14,20 @@ LLM(大規模言語モデル)は文書の内容を直接読み取ること
### ノードの機能
-テキスト抽出ツールノードは、情報を処理する中心的な役割を果たします。入力変数内のファイルを識別して読み取り、情報を抽出し、string型の出力変数に変換して、後続のノードが呼び出すために提供します。
+ドキュメント抽出器ノードは、情報を処理する中心的な役割を果たします。入力変数内のファイルを識別して読み取り、情報を抽出し、string型の出力変数に変換して、後続のノードが呼び出すために提供します。

-テキスト抽出ツールノードは、入力変数と出力変数に分かれています。
+ドキュメント抽出器ノードは、入力変数と出力変数に分かれています。
#### 入力変数
-テキスト抽出ツールは以下のデータ構造の変数のみを受け入れます:
+ドキュメント抽出器は以下のデータ構造の変数のみを受け入れます:
* `File`,1つのファイル
* `Array[File]`,複数のファイル
-テキスト抽出ツールは、テキスト、Markdown、PDF、HTML、DOCX形式のファイルなどの文書タイプから情報を抽出できますが、画像、音声、映像などの形式のファイルは処理できません。
+ドキュメント抽出器は、テキスト、Markdown、PDF、HTML、DOCX形式のファイルなどの文書タイプから情報を抽出できますが、画像、音声、映像などの形式のファイルは処理できません。
#### 出力変数
@@ -40,17 +40,17 @@ LLM(大規模言語モデル)は文書の内容を直接読み取ること
### 設定例
-典型的なファイルインタラクションの質疑応答シナリオでは、テキスト抽出ツールはLLMノードの前段階として機能し、アプリのファイル情報を抽出し、LLMノードに渡してユーザーのファイルに関する質問に回答します。
+典型的なファイルインタラクションの質疑応答シナリオでは、ドキュメント抽出器はLLMノードの前段階として機能し、アプリのファイル情報を抽出し、LLMノードに渡してユーザーのファイルに関する質問に回答します。
-このセクションでは、典型的なChatPDFサンプルワークフローテンプレートを用いて、テキスト抽出ツールノードの使用方法を説明します。
+このセクションでは、典型的なChatPDFサンプルワークフローテンプレートを用いて、ドキュメント抽出器ノードの使用方法を説明します。

**設定手順:**
1. アプリでファイルアップロード機能を有効にします。 [“スタート”](./start) ノードで**単一ファイル変数**を追加し、`pdf`と名付けます。
-2. テキスト抽出ツールノードを追加し、入力変数で`pdf`変数を選択します。
-3. LLMノードを追加し、システムプロンプトでテキスト抽出ツールノードの出力変数を選択します。LLMはこの出力変数を使用してファイルの内容を読み取ることができます。
+2. ドキュメント抽出器ノードを追加し、入力変数で`pdf`変数を選択します。
+3. LLMノードを追加し、システムプロンプトでドキュメント抽出器ノードの出力変数を選択します。LLMはこの出力変数を使用してファイルの内容を読み取ることができます。

@@ -59,7 +59,7 @@ LLM(大規模言語モデル)は文書の内容を直接読み取ること
設定が完了すると、アプリケーションはファイルアップロード機能を持ち、ユーザーはPDFファイルをアップロードして対話を展開できるようになります。
-
diff --git a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/doc-extractor.mdx b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/doc-extractor.mdx
index 6199e825c..1ffc149ef 100644
--- a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/doc-extractor.mdx
+++ b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/doc-extractor.mdx
@@ -1,11 +1,11 @@
---
-title: テキスト抽出ツール
+title: ドキュメント抽出器
version: '日本語'
---
### 定義
-LLM(大規模言語モデル)は文書の内容を直接読み取ることができません。そのため、ユーザーがアップロードした文書を”テキスト抽出ツールノード”を介して解析し、文書ファイルの情報を読み取り、テキストに変換して内容をLLMに送信する必要があります。
+LLM(大規模言語モデル)は文書の内容を直接読み取ることができません。そのため、ユーザーがアップロードした文書を”ドキュメント抽出器ノード”を介して解析し、文書ファイルの情報を読み取り、テキストに変換して内容をLLMに送信する必要があります。
### 適用シナリオ
@@ -14,20 +14,20 @@ LLM(大規模言語モデル)は文書の内容を直接読み取ること
### ノードの機能
-テキスト抽出ツールノードは、情報を処理する中心的な役割を果たします。入力変数内のファイルを識別して読み取り、情報を抽出し、string型の出力変数に変換して、後続のノードが呼び出すために提供します。
+ドキュメント抽出器ノードは、情報を処理する中心的な役割を果たします。入力変数内のファイルを識別して読み取り、情報を抽出し、string型の出力変数に変換して、後続のノードが呼び出すために提供します。

-テキスト抽出ツールノードは、入力変数と出力変数に分かれています。
+ドキュメント抽出器ノードは、入力変数と出力変数に分かれています。
#### 入力変数
-テキスト抽出ツールは以下のデータ構造の変数のみを受け入れます:
+ドキュメント抽出器は以下のデータ構造の変数のみを受け入れます:
* `File`,1つのファイル
* `Array[File]`,複数のファイル
-テキスト抽出ツールは、テキスト、Markdown、PDF、HTML、DOCX形式のファイルなどの文書タイプから情報を抽出できますが、画像、音声、映像などの形式のファイルは処理できません。
+ドキュメント抽出器は、テキスト、Markdown、PDF、HTML、DOCX形式のファイルなどの文書タイプから情報を抽出できますが、画像、音声、映像などの形式のファイルは処理できません。
#### 出力変数
@@ -40,17 +40,17 @@ LLM(大規模言語モデル)は文書の内容を直接読み取ること
### 設定例
-典型的なファイルインタラクションの質疑応答シナリオでは、テキスト抽出ツールはLLMノードの前段階として機能し、アプリのファイル情報を抽出し、LLMノードに渡してユーザーのファイルに関する質問に回答します。
+典型的なファイルインタラクションの質疑応答シナリオでは、ドキュメント抽出器はLLMノードの前段階として機能し、アプリのファイル情報を抽出し、LLMノードに渡してユーザーのファイルに関する質問に回答します。
-このセクションでは、典型的なChatPDFサンプルワークフローテンプレートを用いて、テキスト抽出ツールノードの使用方法を説明します。
+このセクションでは、典型的なChatPDFサンプルワークフローテンプレートを用いて、ドキュメント抽出器ノードの使用方法を説明します。

**設定手順:**
1. アプリでファイルアップロード機能を有効にします。 [“スタート”](./start) ノードで**単一ファイル変数**を追加し、`pdf`と名付けます。
-2. テキスト抽出ツールノードを追加し、入力変数で`pdf`変数を選択します。
-3. LLMノードを追加し、システムプロンプトでテキスト抽出ツールノードの出力変数を選択します。LLMはこの出力変数を使用してファイルの内容を読み取ることができます。
+2. ドキュメント抽出器ノードを追加し、入力変数で`pdf`変数を選択します。
+3. LLMノードを追加し、システムプロンプトでドキュメント抽出器ノードの出力変数を選択します。LLMはこの出力変数を使用してファイルの内容を読み取ることができます。

@@ -59,7 +59,7 @@ LLM(大規模言語モデル)は文書の内容を直接読み取ること
設定が完了すると、アプリケーションはファイルアップロード機能を持ち、ユーザーはPDFファイルをアップロードして対話を展開できるようになります。
-  +
diff --git a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/list-operator.mdx b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/list-operator.mdx
index 7bd147d89..3d95ed516 100644
--- a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/list-operator.mdx
+++ b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/list-operator.mdx
@@ -85,9 +85,9 @@ title: リスト処理
1. [機能](/ja-jp/guides/workflow/additional-features)を有効にし、ファイルタイプで「画像」および「文章」を選択します。
2. フィルタ条件で、画像変数とドキュメント変数をそれぞれ抽出するための2つのリスト操作ノードを追加します。
-3. 文章変数を抽出し、「ドキュメントエクストラクタ」ノードに渡し、画像ファイル変数を抽出してLLMノードに渡します。
+3. 文章変数を抽出し、「ドキュメント抽出器」ノードに渡し、画像ファイル変数を抽出してLLMノードに渡します。
4. 最後に「直接返信」ノードを追加し、LLMノードの出力変数を記入します。

-アプリのユーザーが文章と画像ファイルを同時にアップロードした場合、文章は自動的にドキュメントエクストラクタノードに、画像ファイルは自動的にLLMノードに分流され、それぞれのファイルの共通処理が実現されます。
+アプリのユーザーが文章と画像ファイルを同時にアップロードした場合、文章は自動的にドキュメント抽出器ノードに、画像ファイルは自動的にLLMノードに分流され、それぞれのファイルの共通処理が実現されます。
diff --git a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/llm.mdx b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/llm.mdx
index d608d91e0..9271aa99b 100644
--- a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/llm.mdx
+++ b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/llm.mdx
@@ -355,8 +355,8 @@ LLMノードの出力変数をクリックし、構造化スイッチの設定
ワークフローアプリケーションでドキュメントの内容を取り込むことを可能にする場合、例えばChatPDFアプリケーションを開発する際には、以下の手順を踏んでください:
* 「スタート」ノードへファイル変数を設定する;
-* LLMノードの前段階にドキュメント抽出ノードを設置し、ファイル変数を入力として利用する;
-* 抽出ノードからの**出力変数** `text` をLLMノードへの入力プロンプトとして設定する。
+* LLMノードの前段階にドキュメント抽出器ノードを設置し、ファイル変数を入力として利用する;
+* ドキュメント抽出器ノードからの**出力変数** `text` をLLMノードへの入力プロンプトとして設定する。
さらなる情報は、[ファイルアップロード](../file-upload)を参照してください。
+
diff --git a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/list-operator.mdx b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/list-operator.mdx
index 7bd147d89..3d95ed516 100644
--- a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/list-operator.mdx
+++ b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/list-operator.mdx
@@ -85,9 +85,9 @@ title: リスト処理
1. [機能](/ja-jp/guides/workflow/additional-features)を有効にし、ファイルタイプで「画像」および「文章」を選択します。
2. フィルタ条件で、画像変数とドキュメント変数をそれぞれ抽出するための2つのリスト操作ノードを追加します。
-3. 文章変数を抽出し、「ドキュメントエクストラクタ」ノードに渡し、画像ファイル変数を抽出してLLMノードに渡します。
+3. 文章変数を抽出し、「ドキュメント抽出器」ノードに渡し、画像ファイル変数を抽出してLLMノードに渡します。
4. 最後に「直接返信」ノードを追加し、LLMノードの出力変数を記入します。

-アプリのユーザーが文章と画像ファイルを同時にアップロードした場合、文章は自動的にドキュメントエクストラクタノードに、画像ファイルは自動的にLLMノードに分流され、それぞれのファイルの共通処理が実現されます。
+アプリのユーザーが文章と画像ファイルを同時にアップロードした場合、文章は自動的にドキュメント抽出器ノードに、画像ファイルは自動的にLLMノードに分流され、それぞれのファイルの共通処理が実現されます。
diff --git a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/llm.mdx b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/llm.mdx
index d608d91e0..9271aa99b 100644
--- a/versions/legacy/ja/user-guide/build-app/flow-app/nodes/llm.mdx
+++ b/versions/legacy/ja/user-guide/build-app/flow-app/nodes/llm.mdx
@@ -355,8 +355,8 @@ LLMノードの出力変数をクリックし、構造化スイッチの設定
ワークフローアプリケーションでドキュメントの内容を取り込むことを可能にする場合、例えばChatPDFアプリケーションを開発する際には、以下の手順を踏んでください:
* 「スタート」ノードへファイル変数を設定する;
-* LLMノードの前段階にドキュメント抽出ノードを設置し、ファイル変数を入力として利用する;
-* 抽出ノードからの**出力変数** `text` をLLMノードへの入力プロンプトとして設定する。
+* LLMノードの前段階にドキュメント抽出器ノードを設置し、ファイル変数を入力として利用する;
+* ドキュメント抽出器ノードからの**出力変数** `text` をLLMノードへの入力プロンプトとして設定する。
さらなる情報は、[ファイルアップロード](../file-upload)を参照してください。