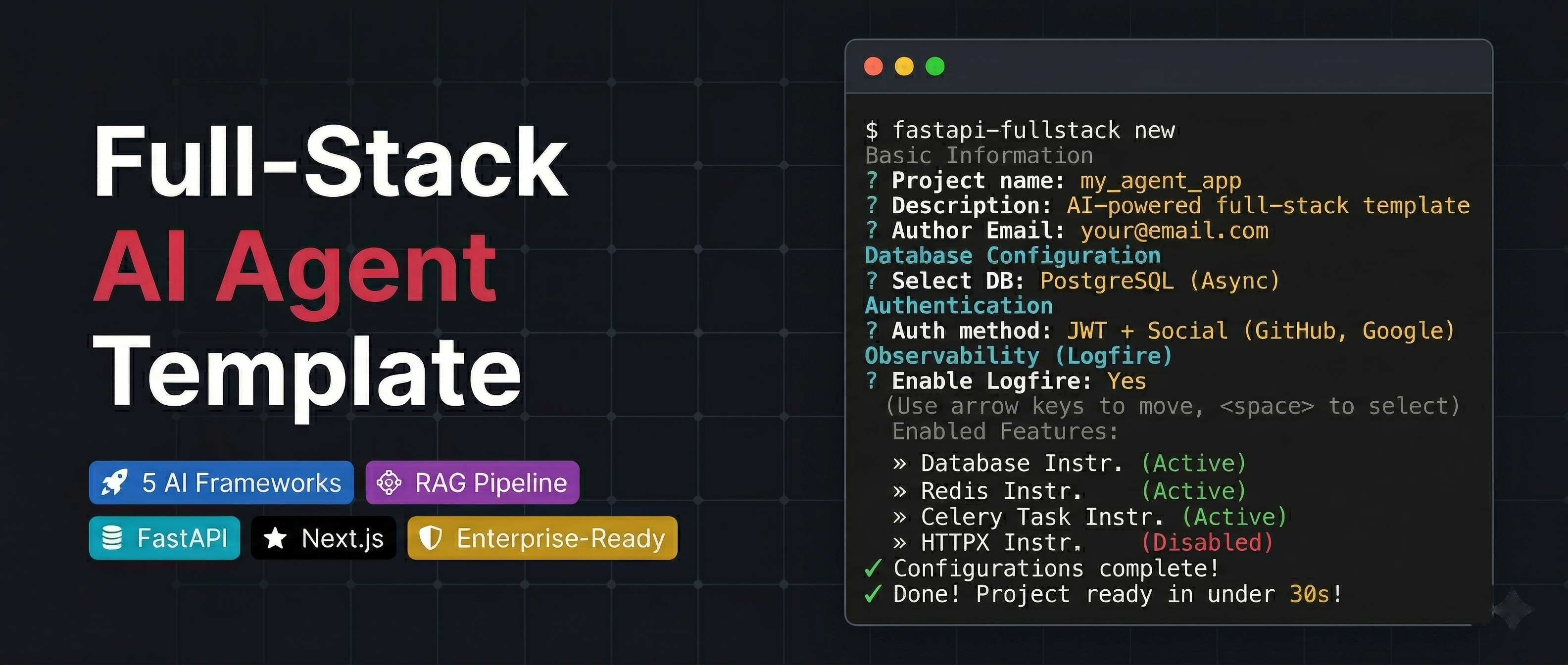
Production-ready FastAPI + Next.js project generator with AI agents, RAG, and 20+ enterprise integrations.
Quick Start • Features • Demo • Documentation • Configurator • PyPI



![]()
🤖 6 AI Agent Frameworks (PydanticAI, PydanticDeep, LangChain, LangGraph, CrewAI, DeepAgents)
📄 RAG Pipeline (Milvus, Qdrant, pgvector, ChromaDB)
⚡ FastAPI + Next.js 15 (WebSocket streaming, real-time chat UI)
🔗 Conversation Sharing (direct sharing, public links, admin browser)
🔒 Enterprise-Ready (JWT, OAuth, admin panel, Celery, Docker, K8s)
Table of Contents
This template is part of a broader open-source ecosystem for production AI agents:
| Project | Description | |
|---|---|---|
| pydantic-deepagents | The modular agent runtime for Python. Claude Code-style CLI with Docker sandbox, browser automation, multi-agent teams, and /improve. |  |
| pydantic-ai-shields | Drop-in guardrails for Pydantic AI agents. 5 infra + 5 content shields. |  |
| pydantic-ai-subagents | Declarative multi-agent orchestration with token tracking. |  |
| summarization-pydantic-ai | Smart context compression for long-running agents. |  |
| pydantic-ai-backend | Sandboxed execution for AI agents. Docker + Daytona. |  |
Want the runtime behind this template's AI agents? pydantic-deepagents powers the
deepagentsframework option — install it standalone withcurl -fsSL .../install.sh | bash.
Browse all projects at oss.vstorm.co
Tip
Prefer a visual configurator? Use the Web Configurator to configure your project in the browser and download a ZIP — no CLI installation needed.
# pip
pip install fastapi-fullstack
# uv (recommended)
uv tool install fastapi-fullstack
# pipx
pipx install fastapi-fullstack# Interactive wizard (recommended — runs by default)
fastapi-fullstack
# Quick mode with options
fastapi-fullstack create my_ai_app \
--database postgresql \
--frontend nextjs
# Use presets for common setups
fastapi-fullstack create my_ai_app --preset production # Full production setup
fastapi-fullstack create my_ai_app --preset ai-agent # AI agent with streaming
# Minimal project (no extras)
fastapi-fullstack create my_ai_app --minimalcd my_ai_app
make bootstrap # = make dev + make seedThat's it — backend, database, Redis, vector store (if RAG), Celery (if selected) come up, migrations are applied, and a default admin is seeded.
make dev # idempotent: build + up + migrate. Re-run anytime.make dev skips admin seeding (that's a one-shot in make seed) so it stays cheap to run after every code/config change.
Behind the scenes (make dev):
- Builds the backend Docker image (cached after first run)
- Starts services via
docker-compose.dev.yml(hot-reload bind mounts) - Polls Postgres until ready (
pg_isready— no fixed sleeps) - Applies pending Alembic migrations (no-op if already at head)
Then access:
| URL | ||
|---|---|---|
| Backend API | http://localhost:8000 | |
| Docs | http://localhost:8000/docs | OpenAPI / Swagger |
| Admin | http://localhost:8000/admin | admin@example.com / admin123 (after make seed) |
| Frontend | http://localhost:3000 | make dev-frontend (Docker) or cd frontend && bun install && bun dev (local) |
make dev # bootstrap or restart (no admin re-seed)
make seed # one-shot admin creation (no-op if admin exists)
make dev-down # stop everything
make dev-logs # tail container logs
make dev-rebuild # force-rebuild backend image (after pyproject.toml changes)
make dev-frontend # start the Next.js containermake target |
Compose file | When to use |
|---|---|---|
make dev |
docker-compose.dev.yml |
Local development with hot-reload + bind-mounted source. |
make stage |
docker-compose.yml |
Production-like build (no bind mounts) running on localhost. Sanity-check before deploy. |
make prod |
docker-compose.prod.yml |
Production. Requires .env.prod (copy from .env.prod.example) + external Nginx using nginx/nginx.conf. |
Each env has matching -down, -logs, -rebuild siblings.
Note
Windows users: make requires GNU Make. Install via Chocolatey (choco install make) or use WSL2 / Git Bash. The Docker workflow is identical across macOS, Linux, and WSL2.
Local backend (no Docker, for IDE breakpoints)
If you want to run the backend on the host while the database stays in Docker:
cd my_ai_app
make install # uv sync + pre-commit hooks
# Start only infrastructure containers
docker compose -f docker-compose.dev.yml up -d db redis # add 'milvus etcd minio' if RAG
make db-upgrade # apply migrations
make create-admin # interactive
make run # uvicorn --reloadProduction deploy
# On your server
git clone <your-repo>
cd my_ai_app
cp .env.prod.example .env.prod # fill in real secrets
# Configure your nginx host using nginx/nginx.conf as reference
make prod # builds + starts + migrates
make prod-logs # tail logsFor frontend deployment to Vercel:
cd frontend && npx vercel --prodIn the Vercel dashboard set BACKEND_URL, BACKEND_WS_URL, NEXT_PUBLIC_AUTH_ENABLED=true.
Each generated project has a CLI named after your project_slug. For example, if you created my_ai_app:
cd backend
# The CLI command is: uv run <project_slug> <command>
uv run my_ai_app server run --reload # Start dev server
uv run my_ai_app db migrate -m "message" # Create migration
uv run my_ai_app db upgrade # Apply migrations
uv run my_ai_app user create-admin # Create admin userUse make help to see all available Makefile shortcuts.
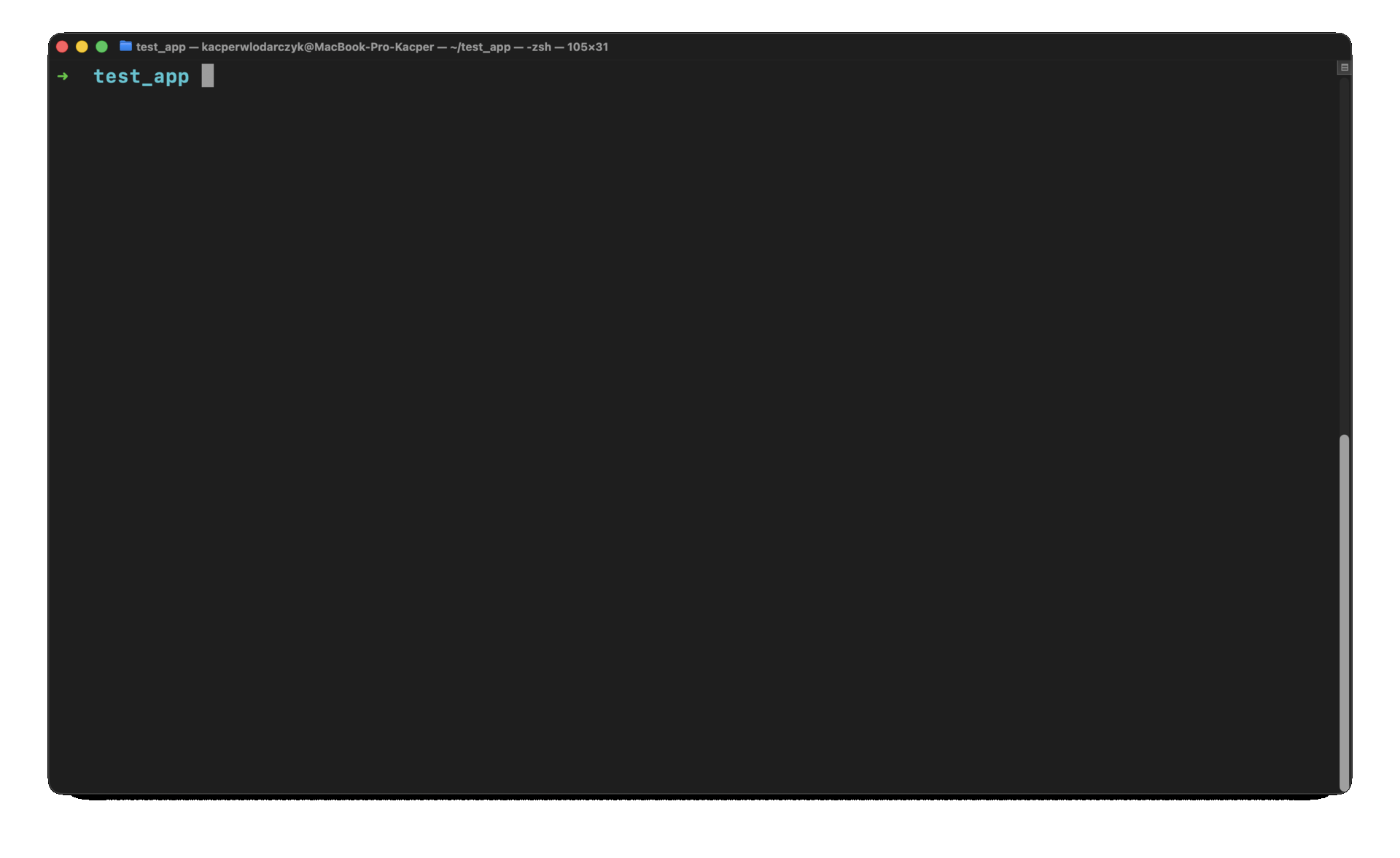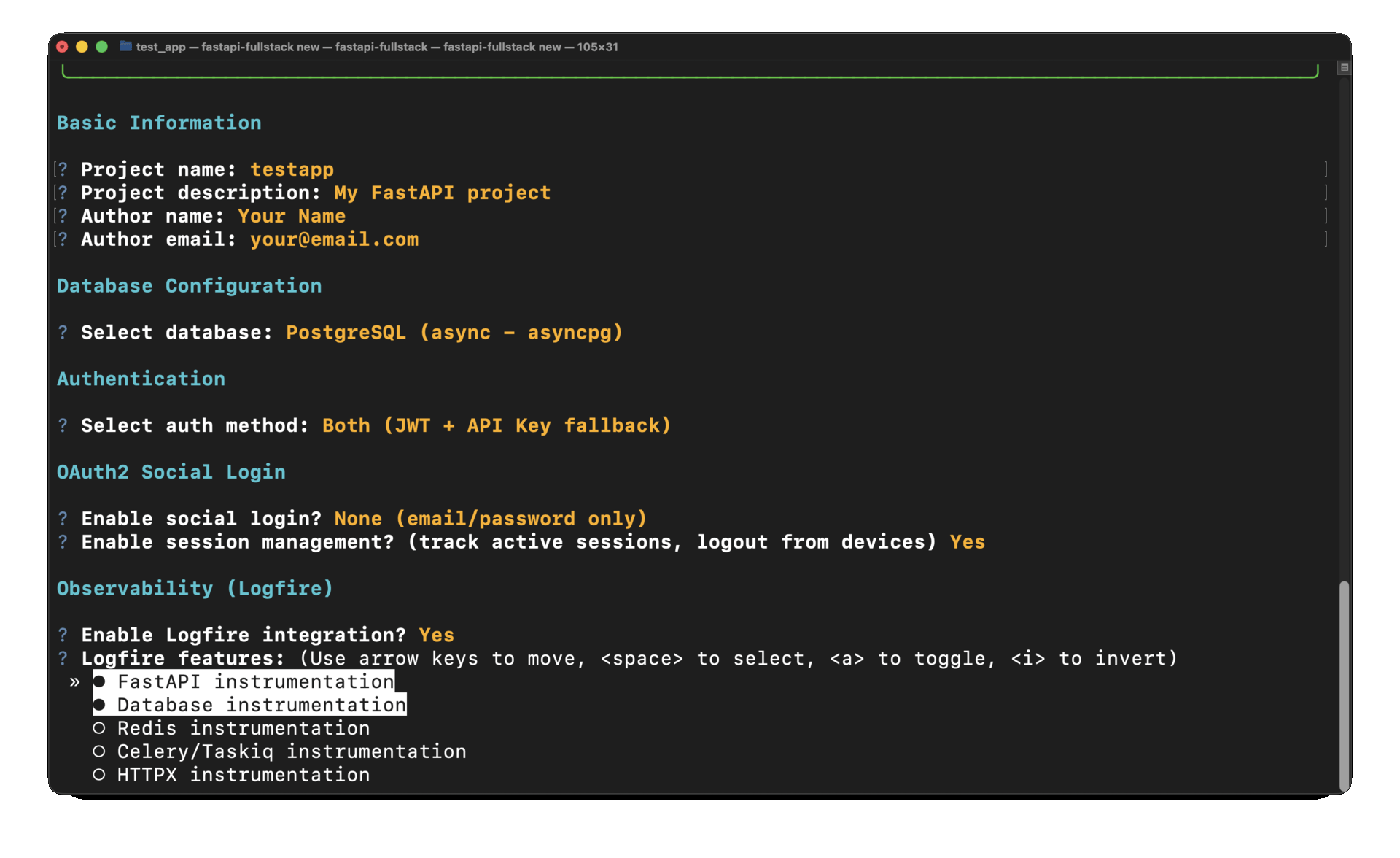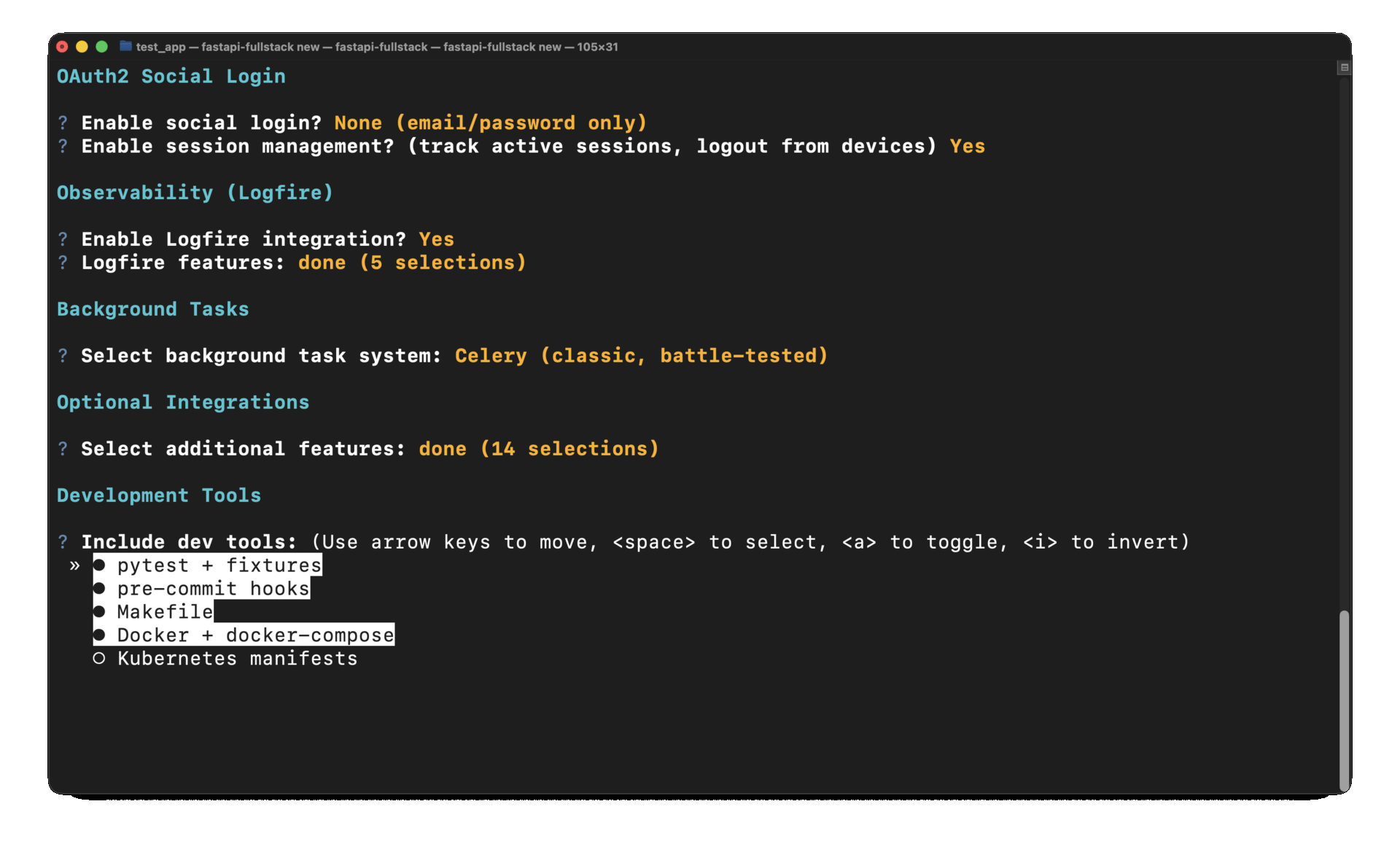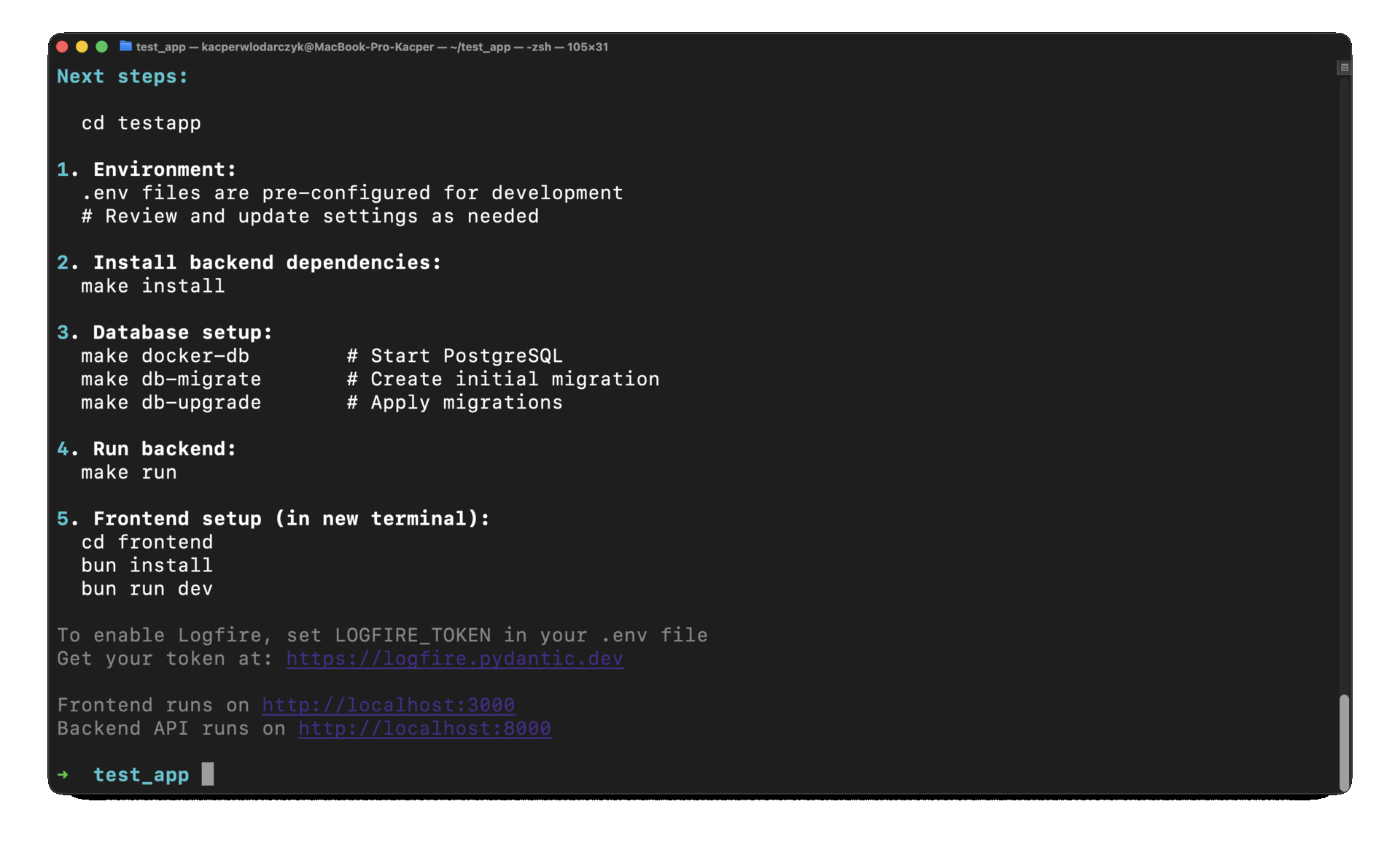
CLI generator:
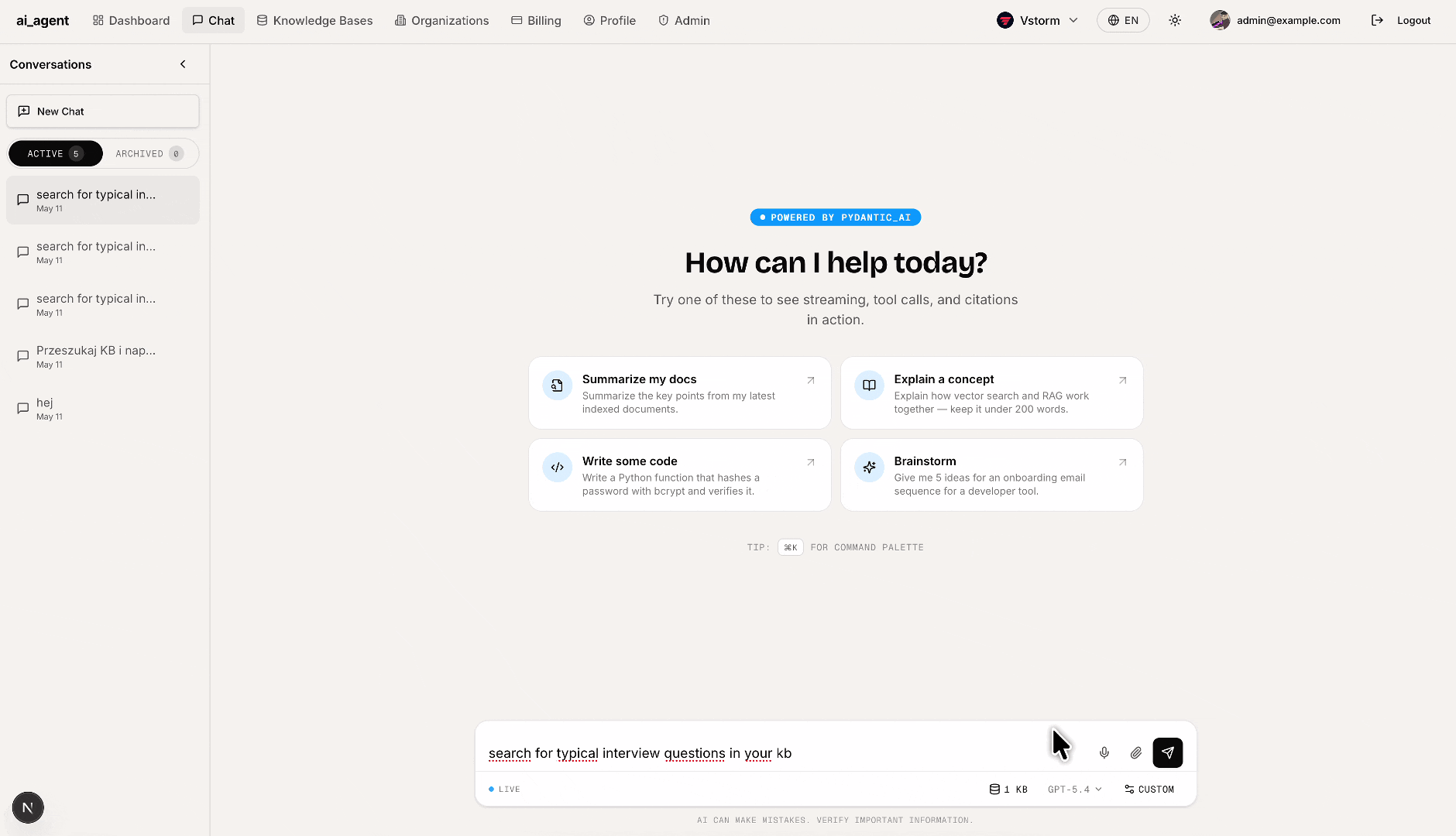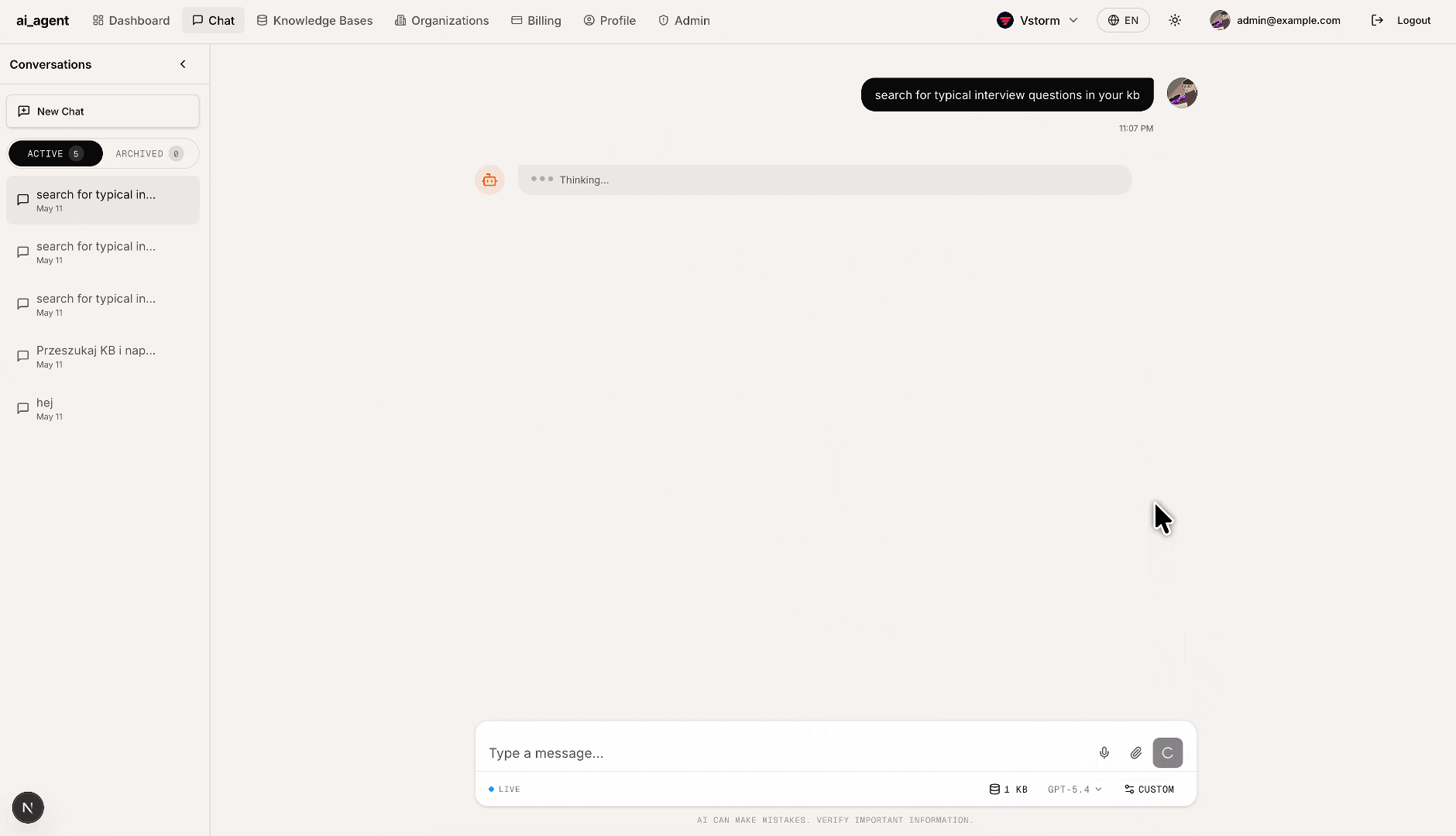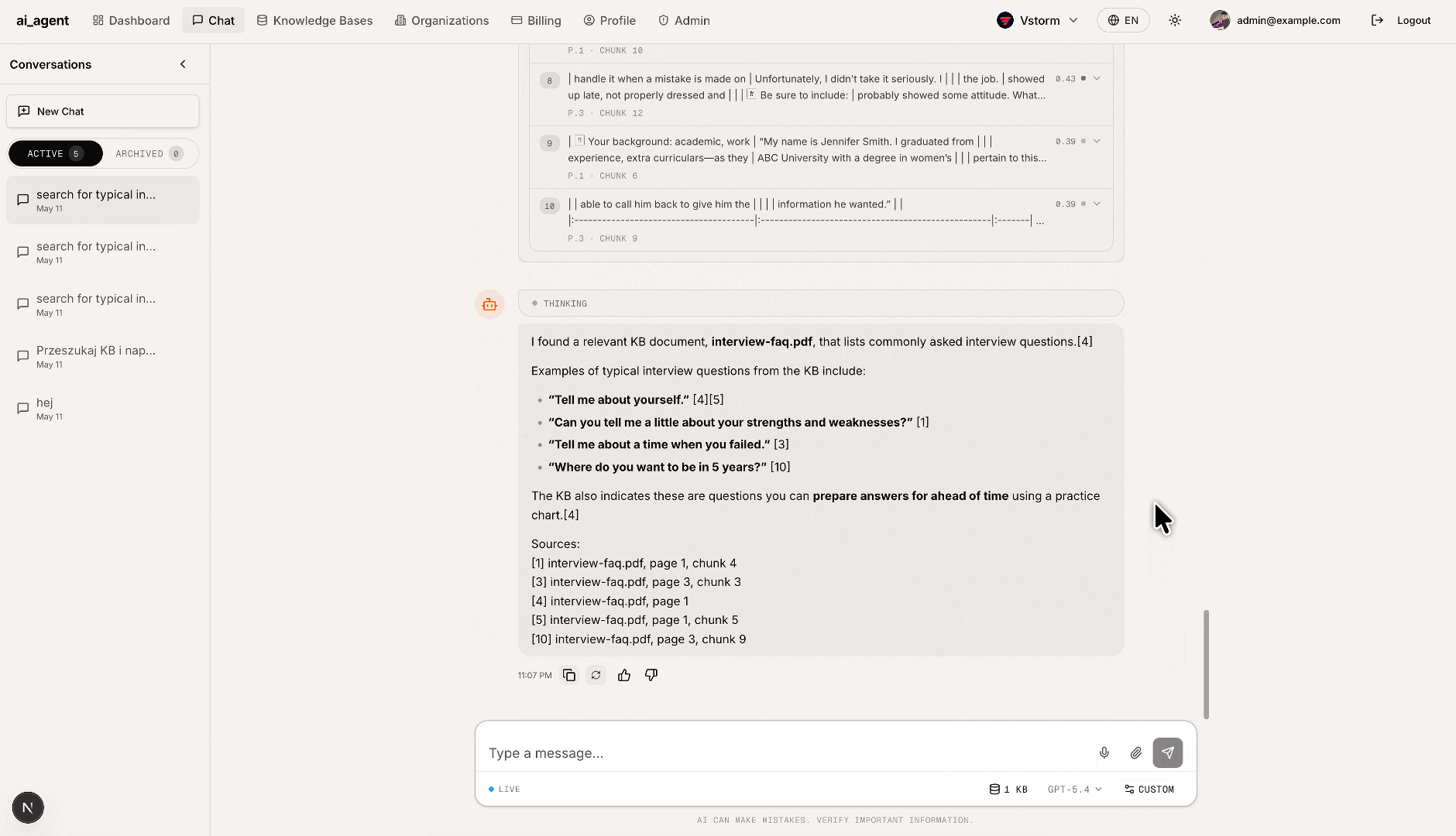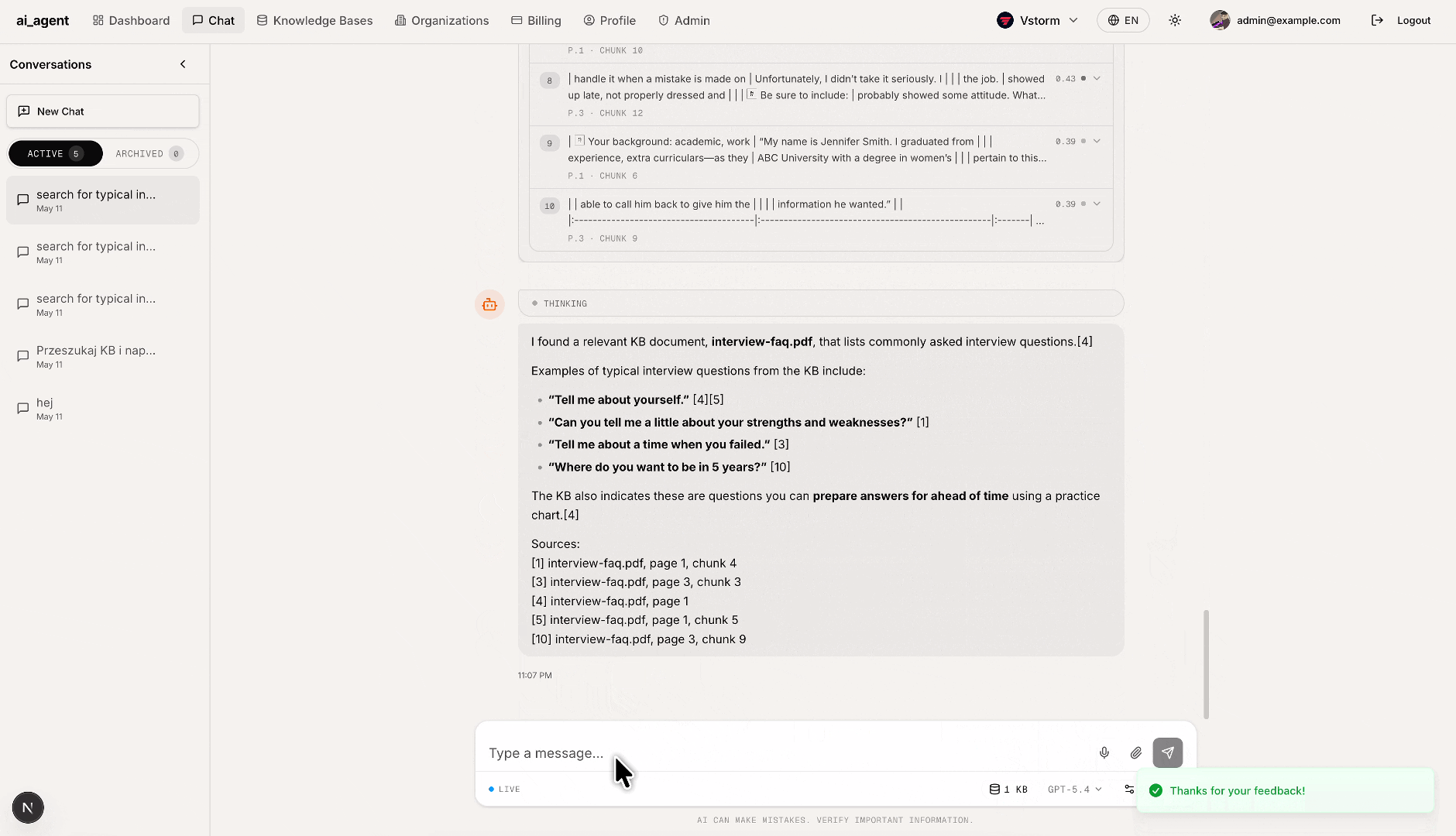
Live chat:
File upload & RAG ingestion:
Landing Page — Full-page marketing site with hero, features breakdown, testimonials, pricing preview, and FAQ. Generated with the enable_marketing_site option.
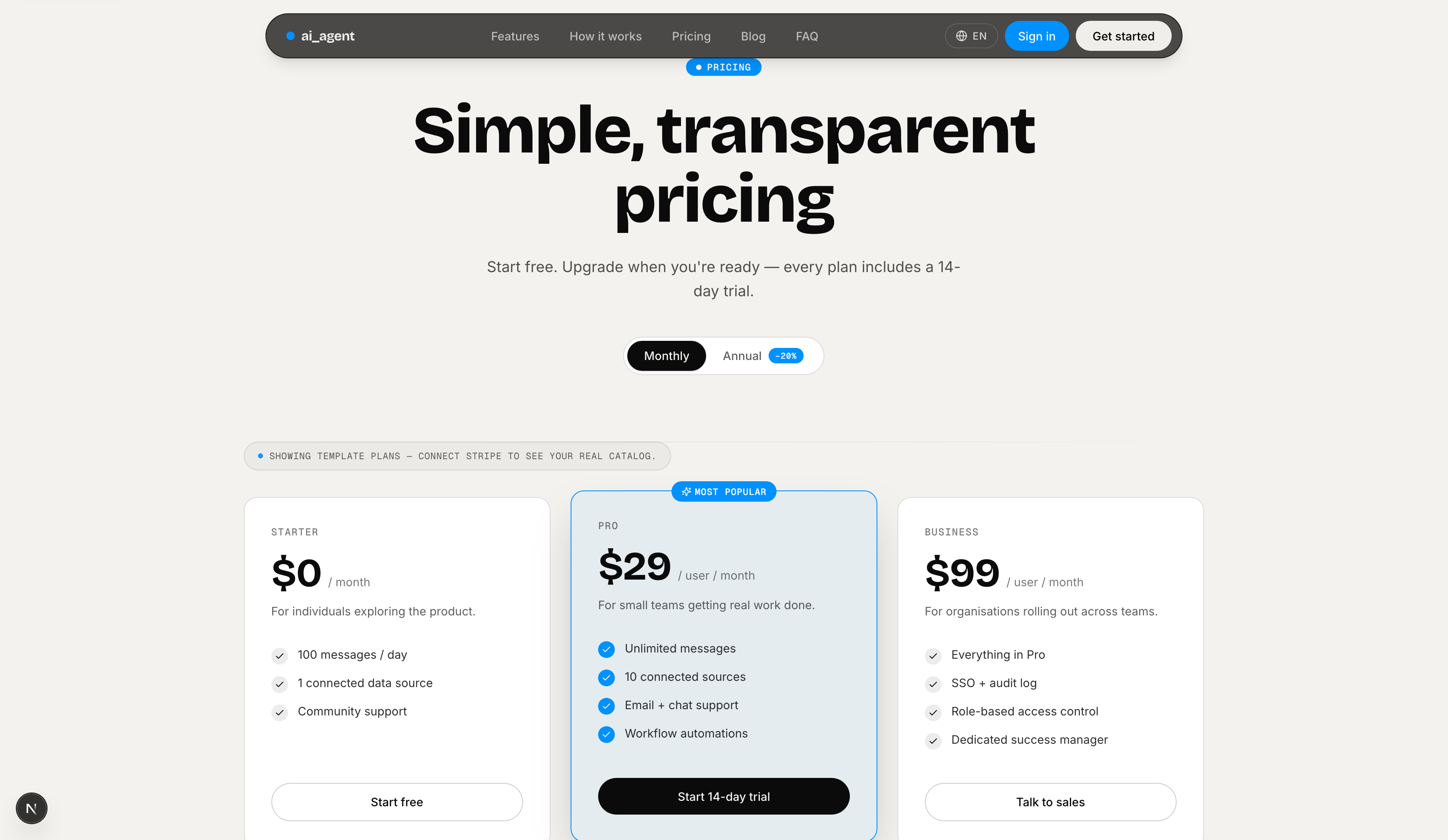
Pricing — Three-tier pricing page (Starter / Pro / Business) with monthly/annual toggle. Pulls live plan data from Stripe when connected; shows template plans otherwise.
Blog — Engineering blog included out of the box. Posts are MDX files in the repo — no CMS needed. Supports tags, featured posts, and author bylines.
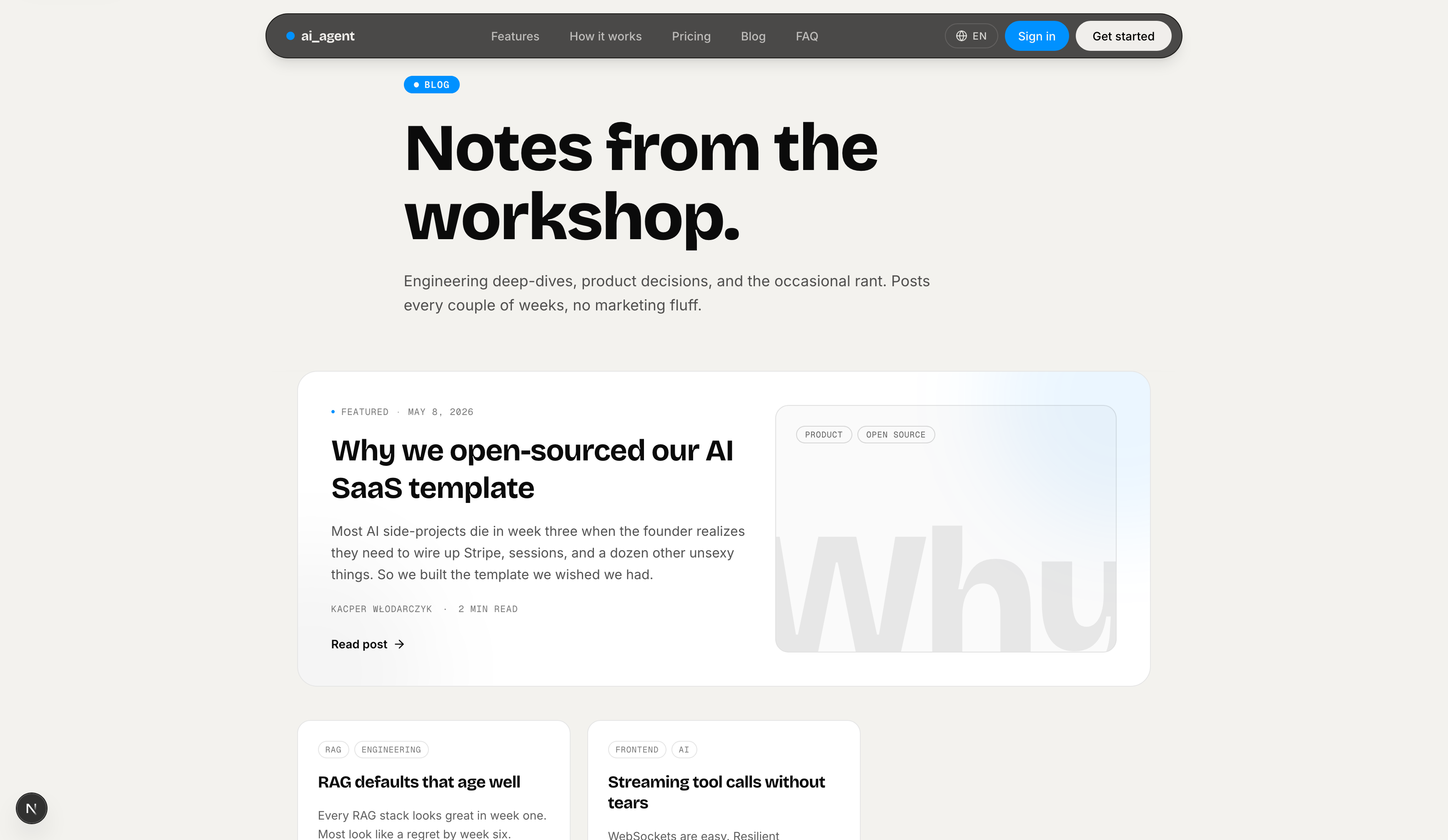
Blog Post — Individual post view with author card, reading time, and tag badges. Content is plain MDX — edit files and redeploy.
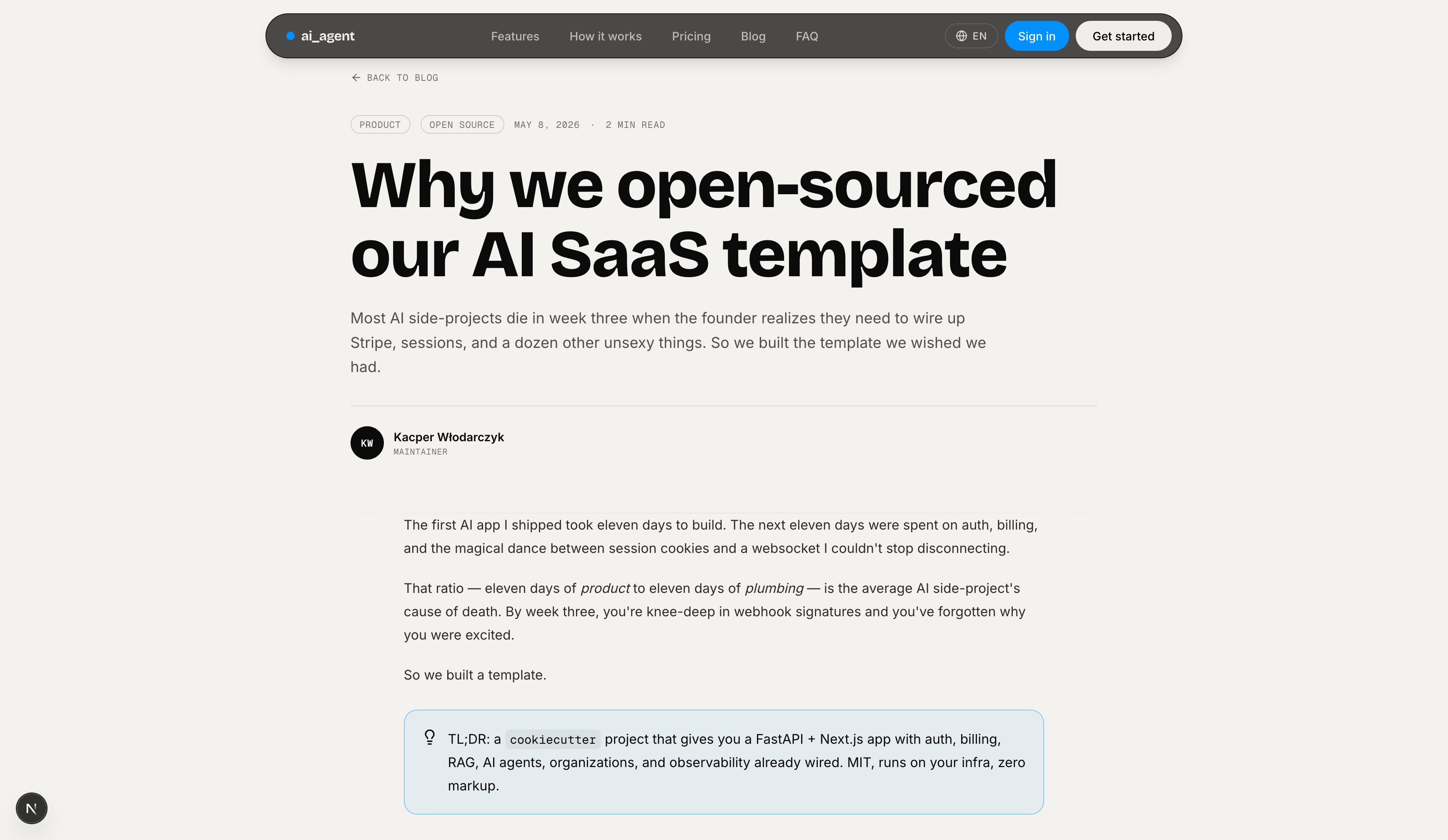
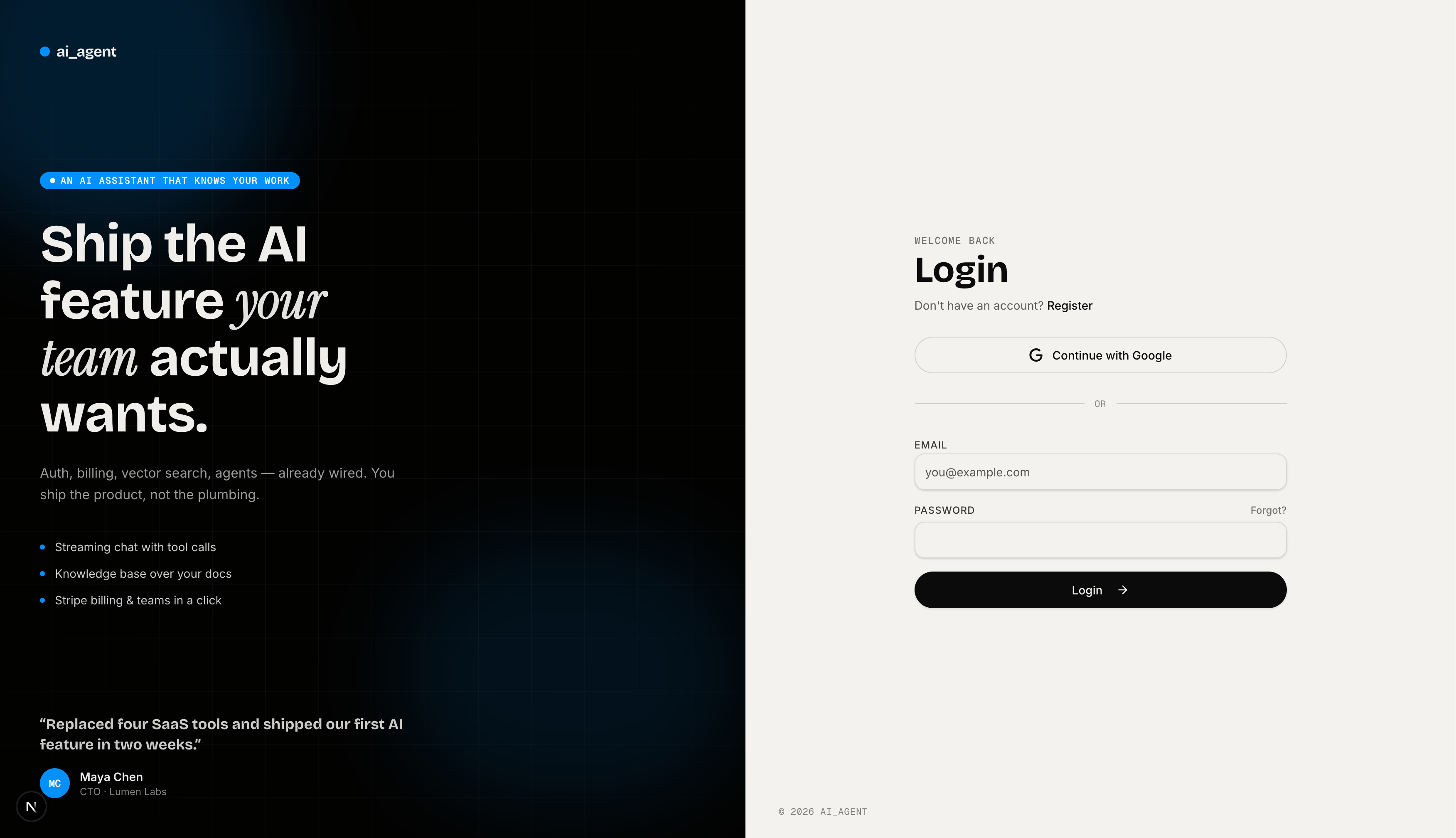
Login — Split-screen login with Google OAuth and email/password. Left panel shows a product pitch with a social proof quote. HTTP-only cookie session on submit.
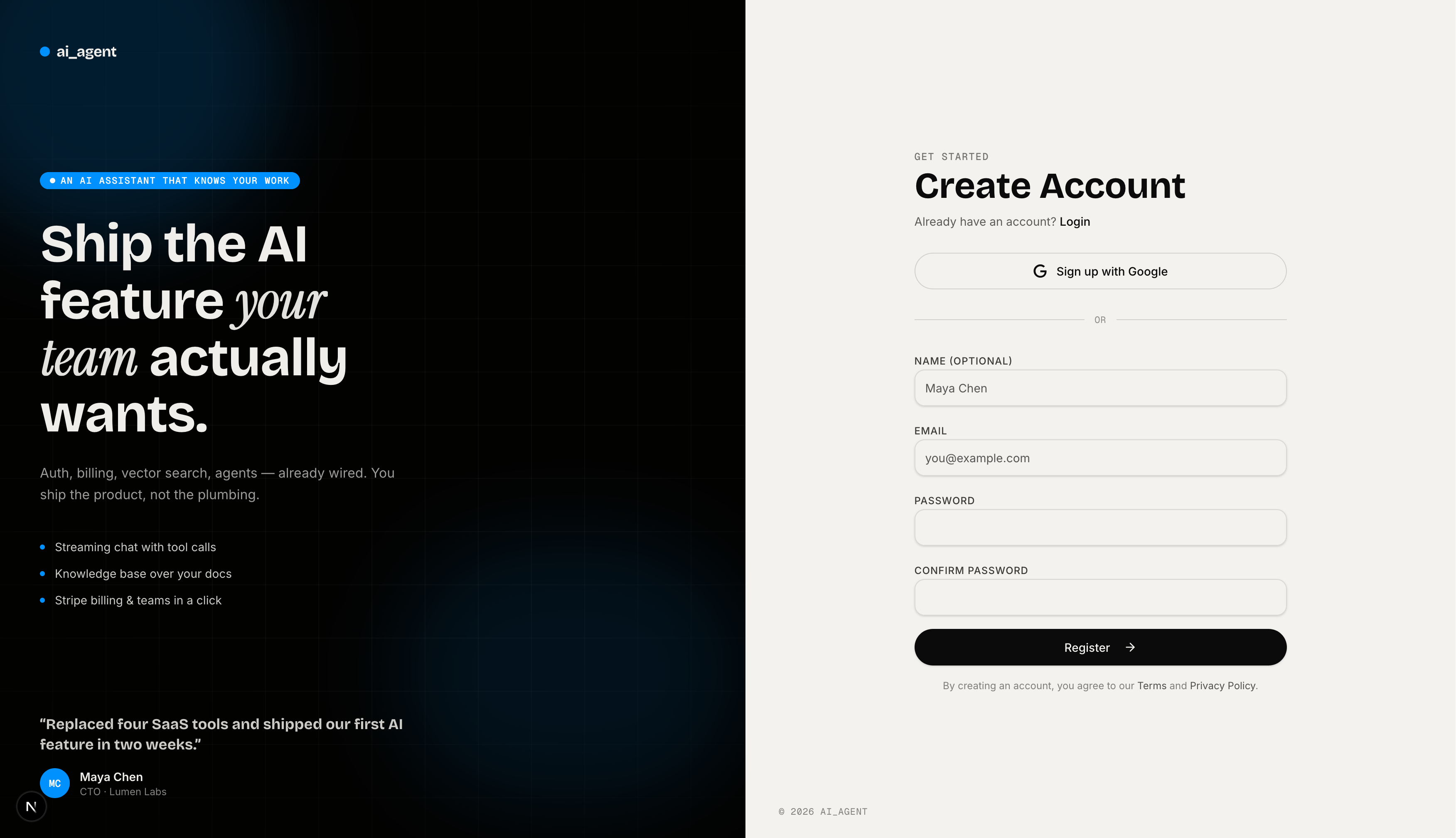
Register — Same split-screen layout as login. Google sign-up and email/password form with confirm-password field and terms acceptance.
Dashboard (light mode) — Workspace overview showing conversation count, knowledge base vector count, recent activity feed, agent tool call stats, active sessions, and team info. Onboarding banner guides new users through setup in under 2 minutes.
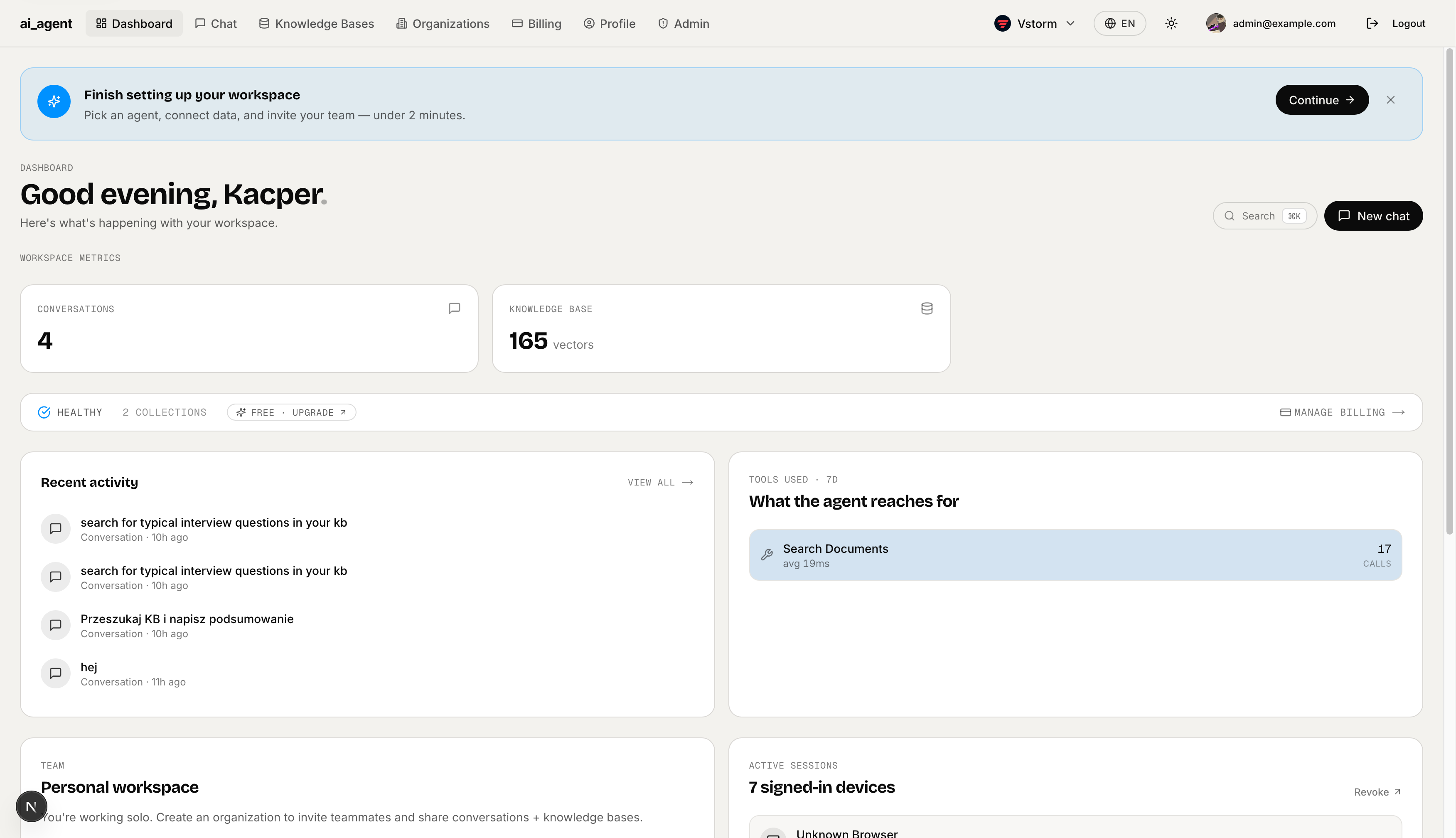
Dashboard (dark mode) — Same dashboard in dark theme. Theme is saved per-device and can be overridden per-workspace in appearance settings.
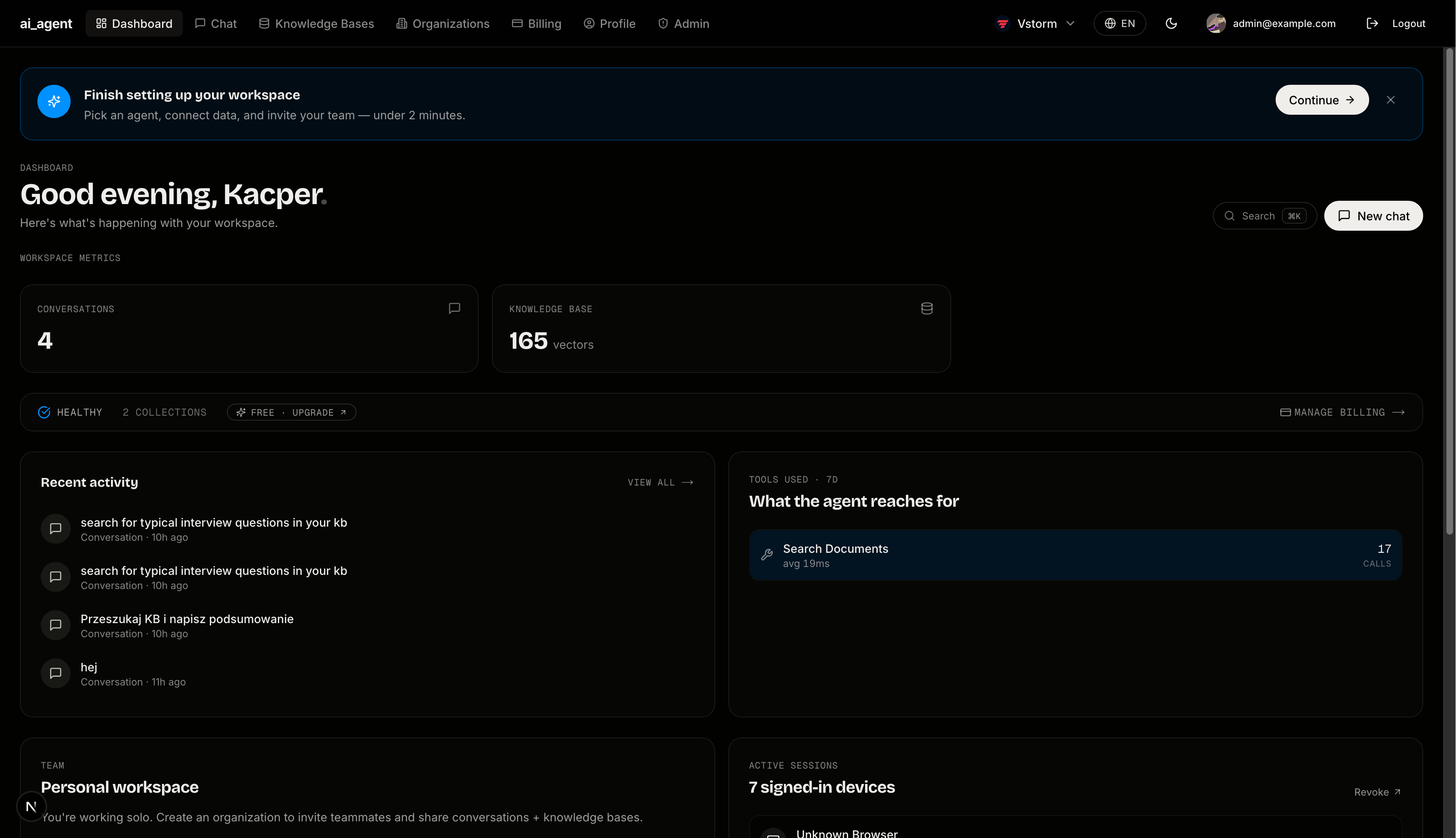
Workspaces — List of all organizations the user belongs to. Shows plan tier and role for each. Users can switch active workspace or create a new organization.
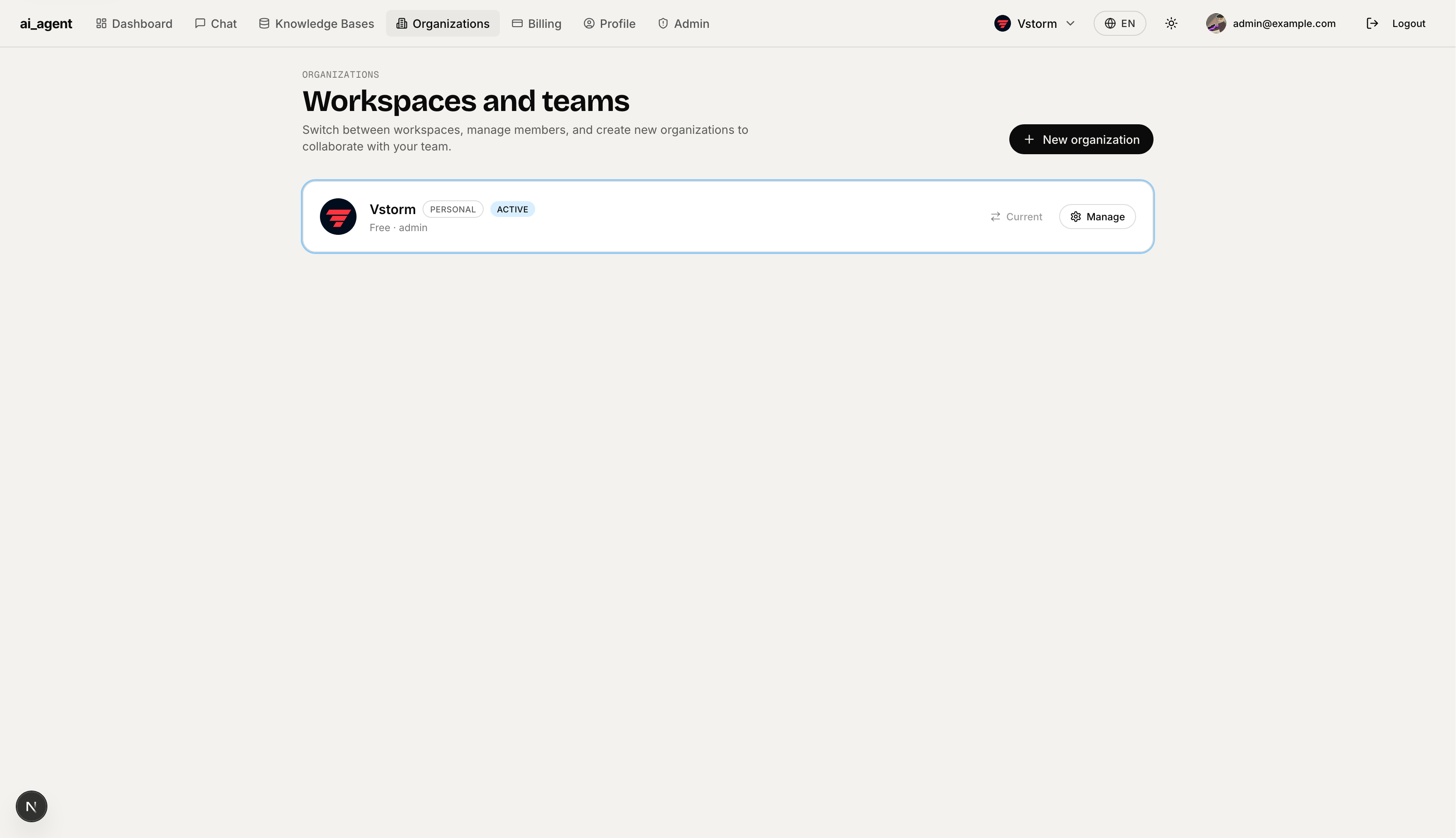
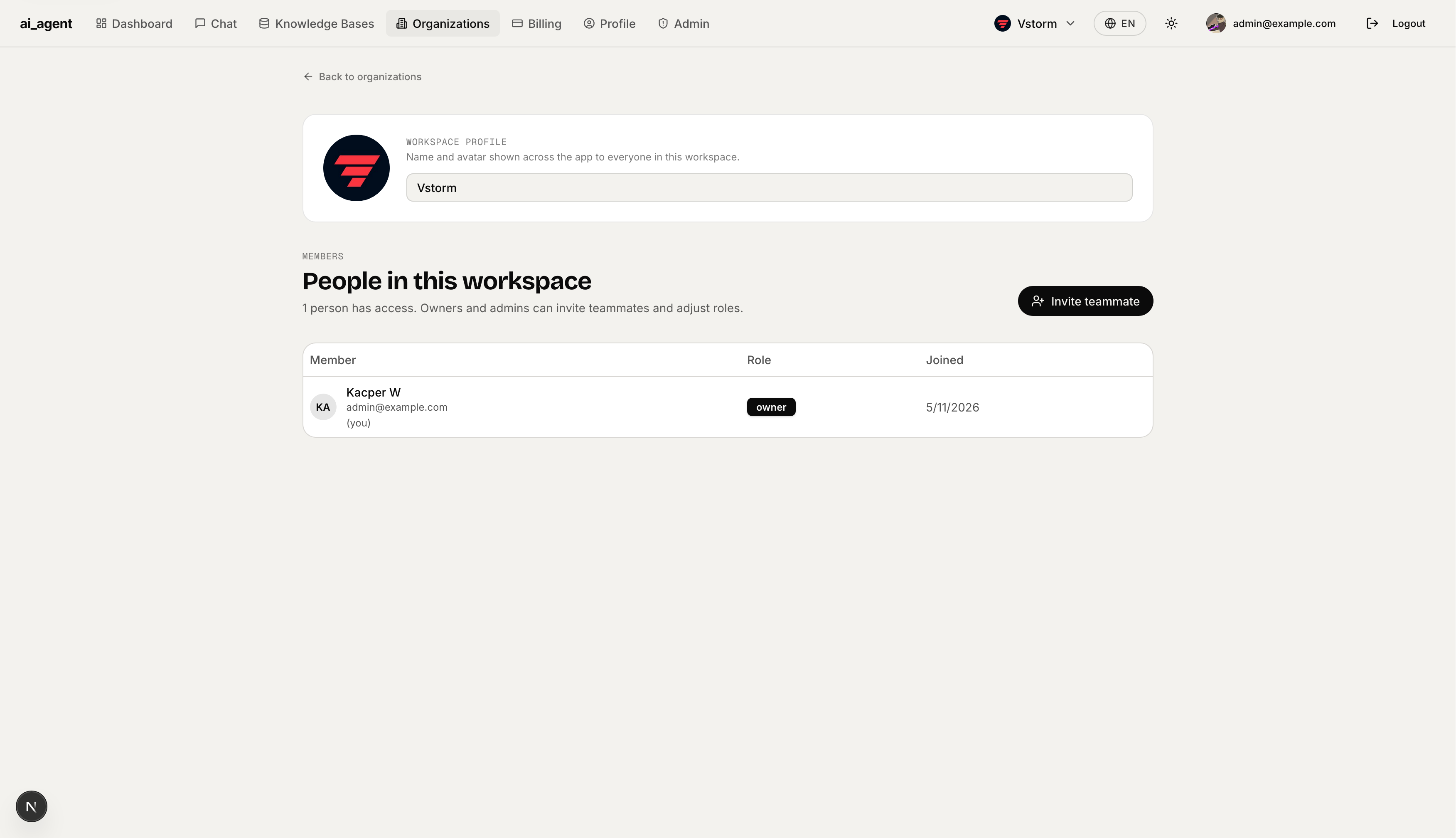
Team Management — Organization detail page with workspace profile (name + avatar), member list with roles, and an "Invite teammate" button. Owners and admins can adjust roles inline.
Knowledge Bases — List of RAG knowledge bases scoped to the current workspace. Each base shows its collection slug. Users can create new bases, toggle which ones are active in chat, and upload documents through the UI.
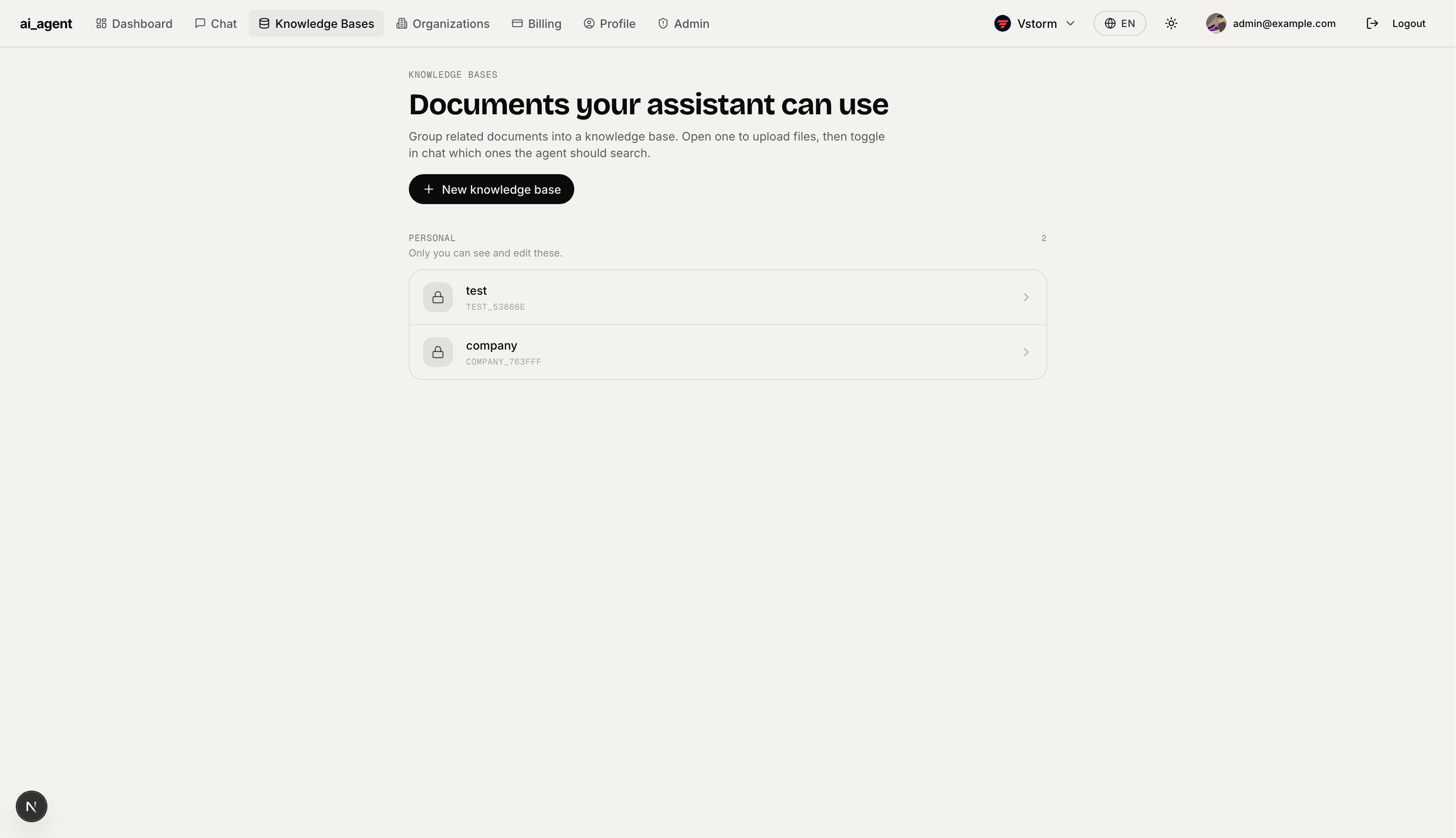
Billing — Workspace billing dashboard showing current plan, storage usage (chat attachments + indexed RAG documents), quick links to usage breakdown, invoices, payment methods, and subscription management. "Manage in Stripe" opens the Stripe customer portal.
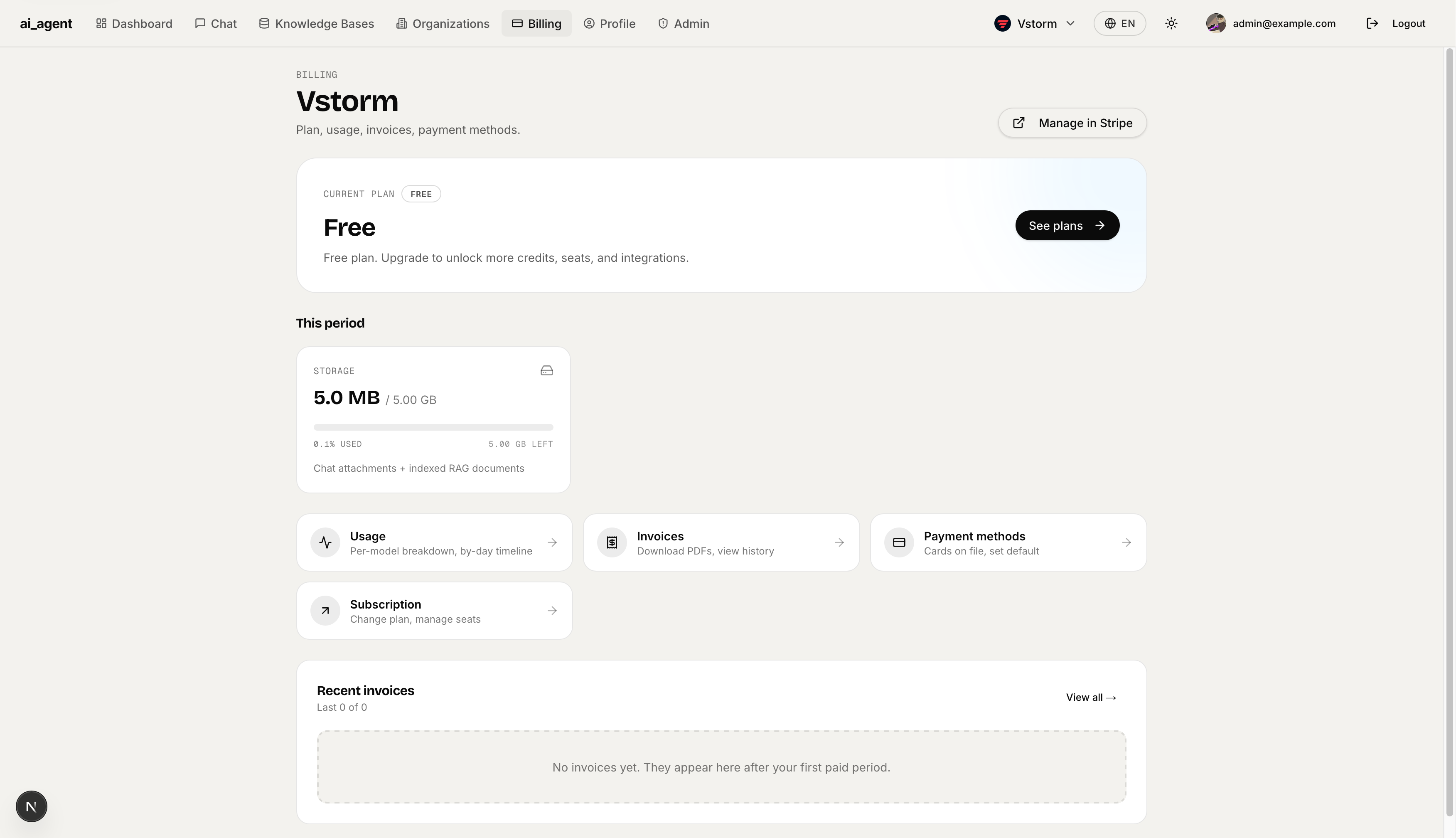
Profile — Personal info tab: avatar upload, display name, email, and active session list with per-device revoke buttons. Visibility note explains which fields are shown to teammates.
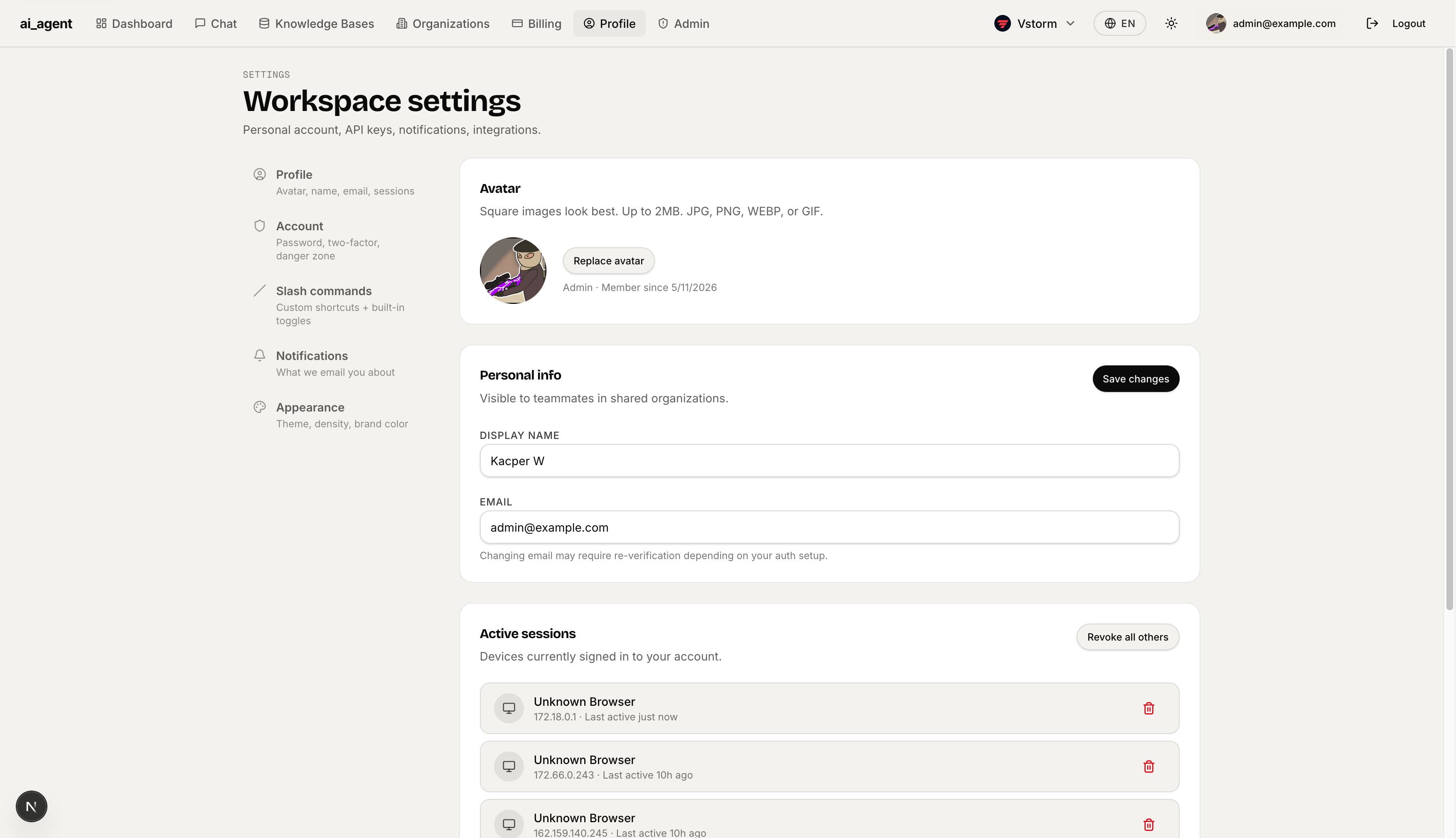
Account & Security — Change password form with strength guidance, "Sign out everywhere" button, and danger zone for permanent account deletion.
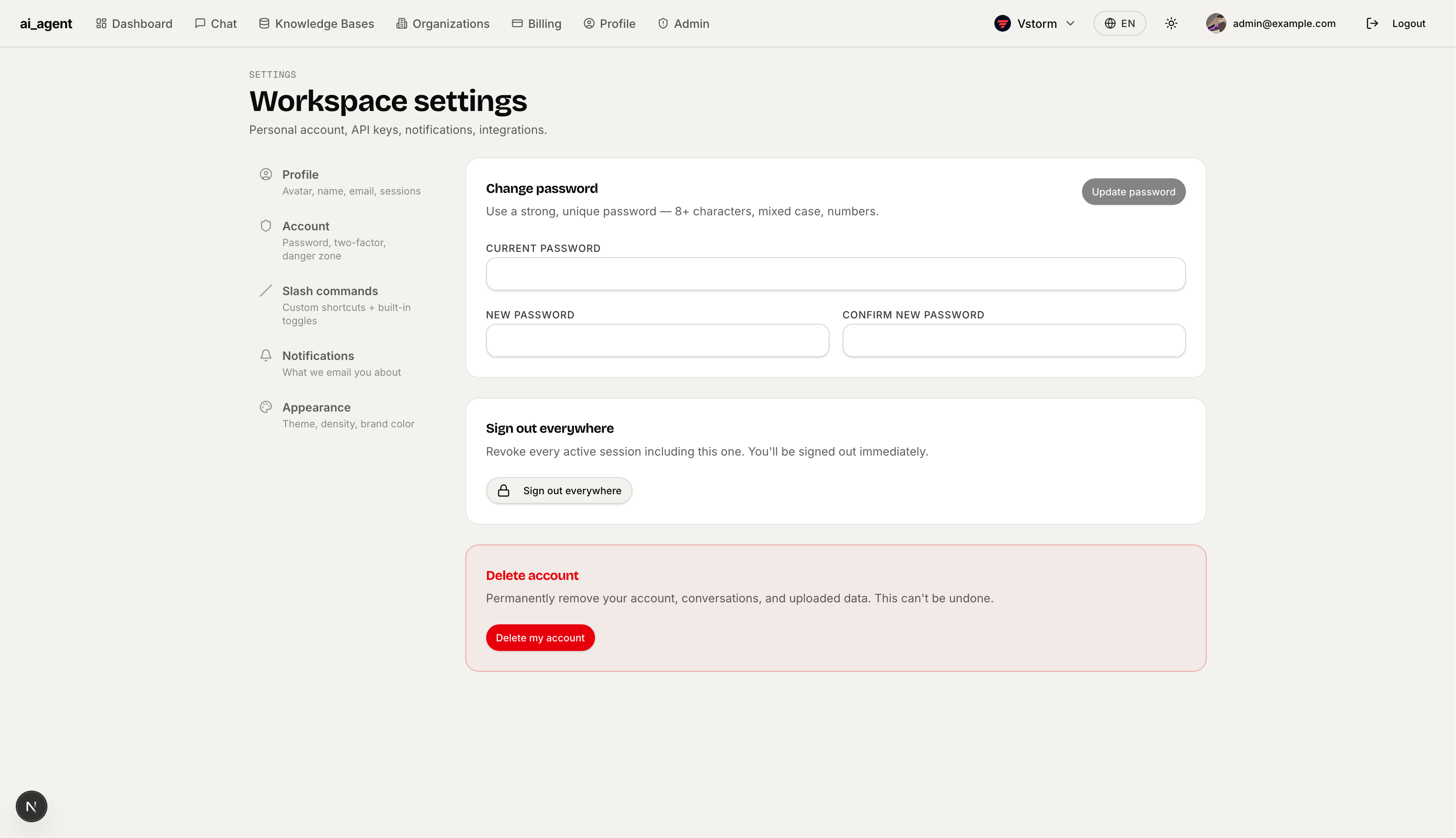
Slash Commands — Customize the /command palette in chat. Toggle built-in commands (/clear, /regen, /settings, /summarize, /explain) and create custom shortcuts that send a stored prompt with a few keystrokes.
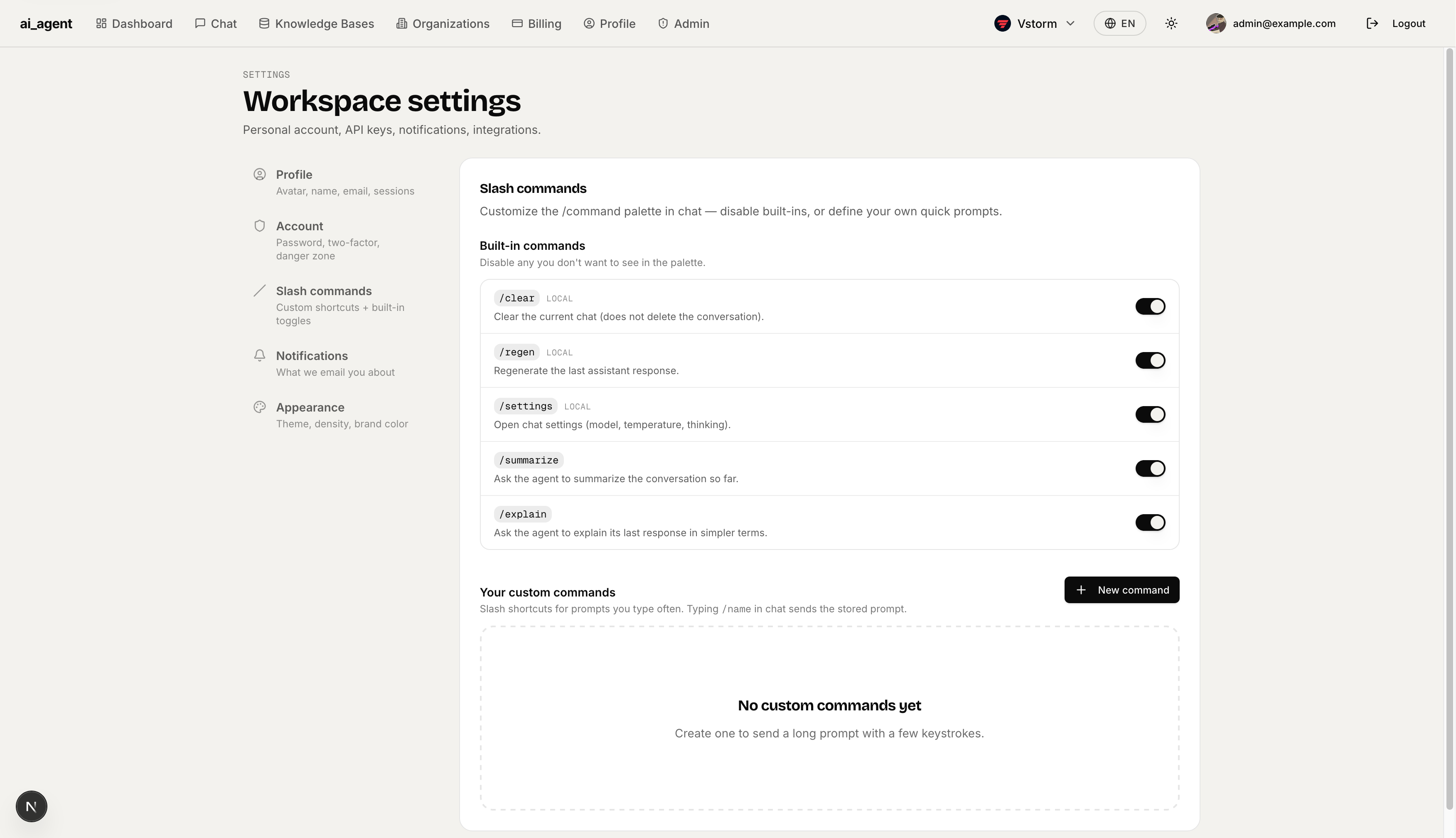
Appearance — Theme switcher (light / dark / system) and brand color picker with four presets: Blue (Stripe/Vercel), Green (healthtech), Red (energetic), Orange (B2C), Violet (Anthropic-style). Brand color updates CSS variables across the entire workspace and is saved per-device.
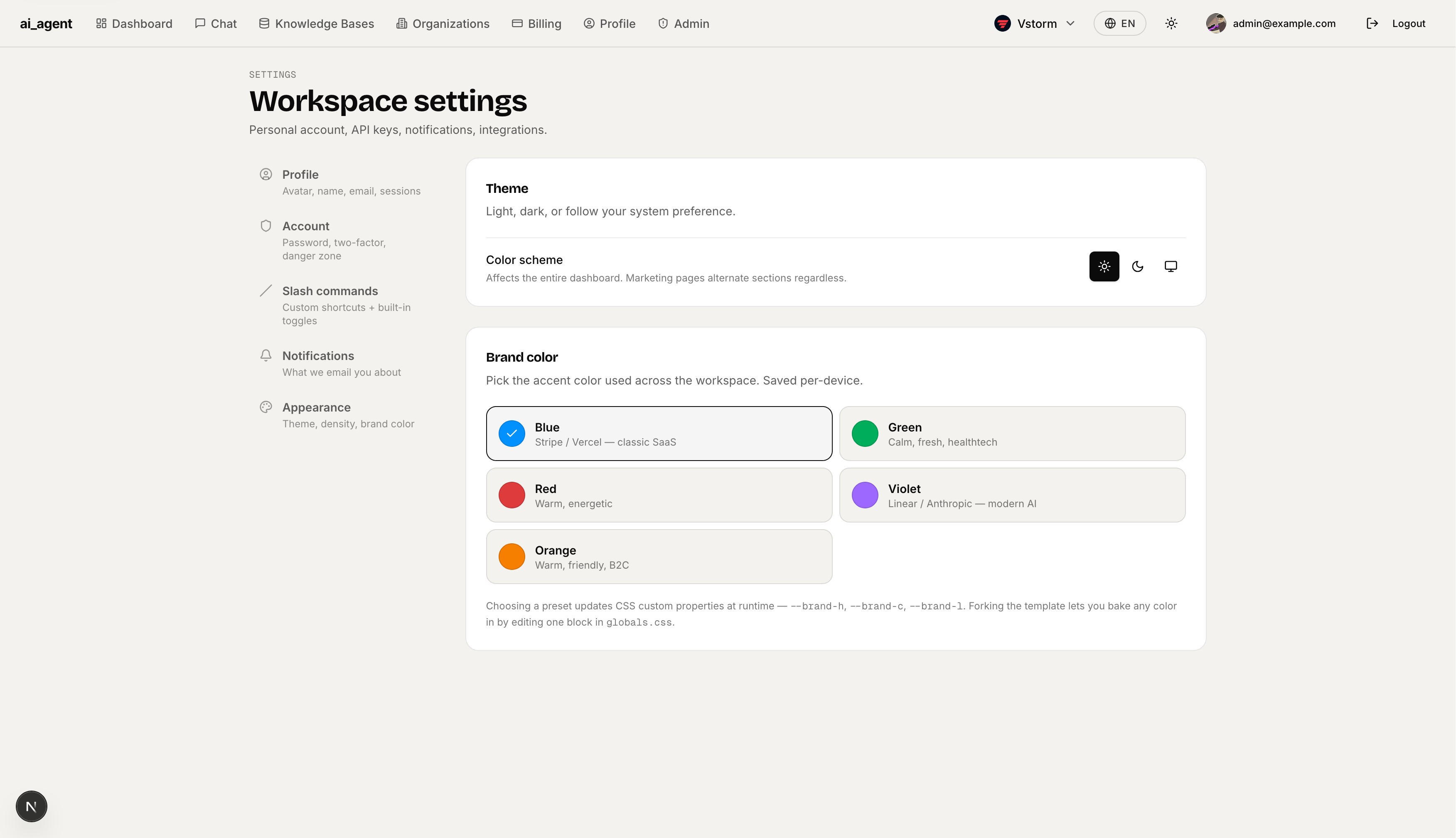
Notification Preferences — Per-category notification controls with separate toggles for email and in-app delivery. Categories: Billing, Team activity, Security alerts, and Product updates. Preferences stored locally and synced to the backend via /users/me/notifications.
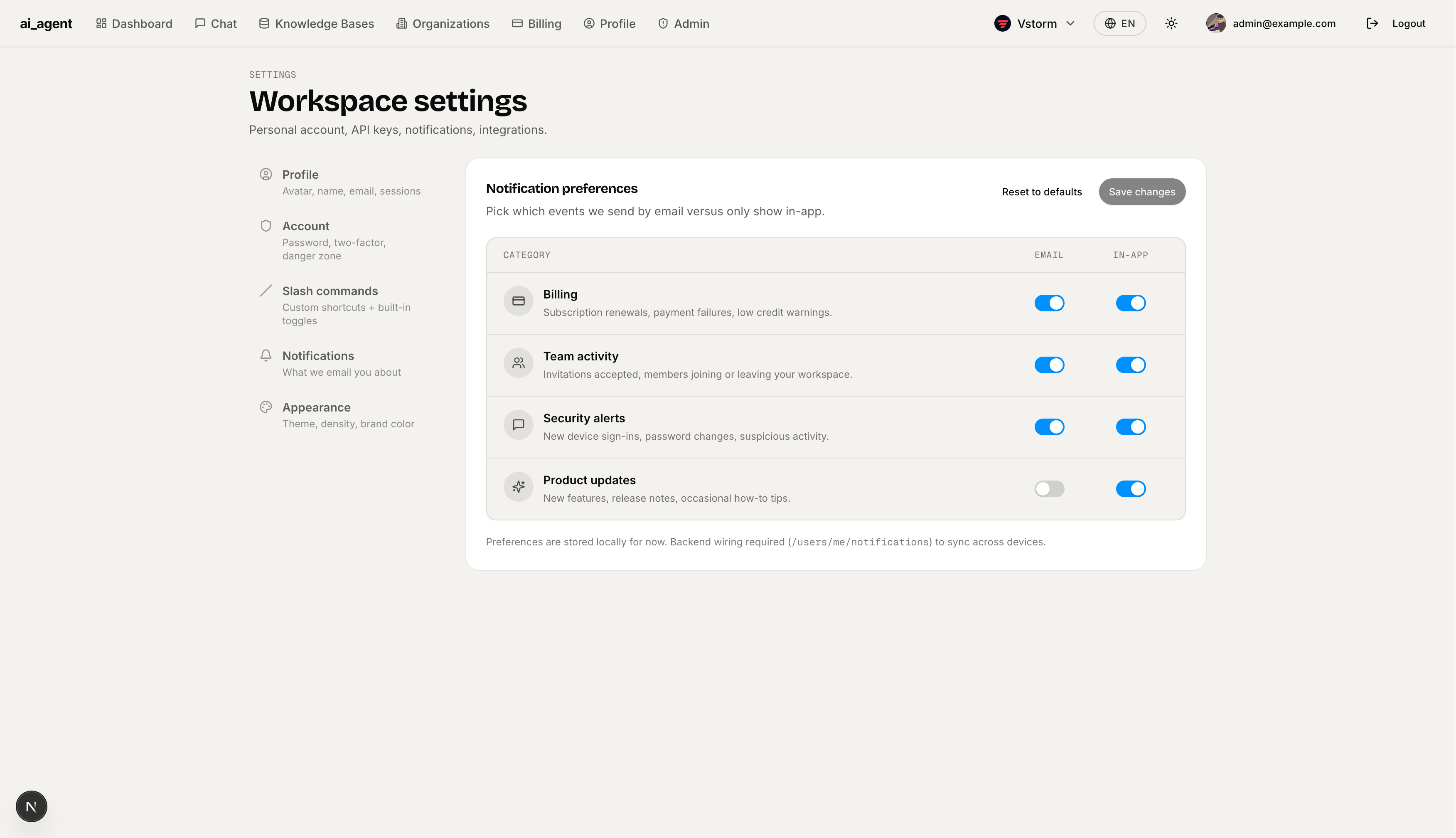
Admin Overview — Workspace-wide metrics (total users, active sessions last 24h, conversation count, MRR) plus a recent activity feed showing all conversations across all users. Requires the admin role.
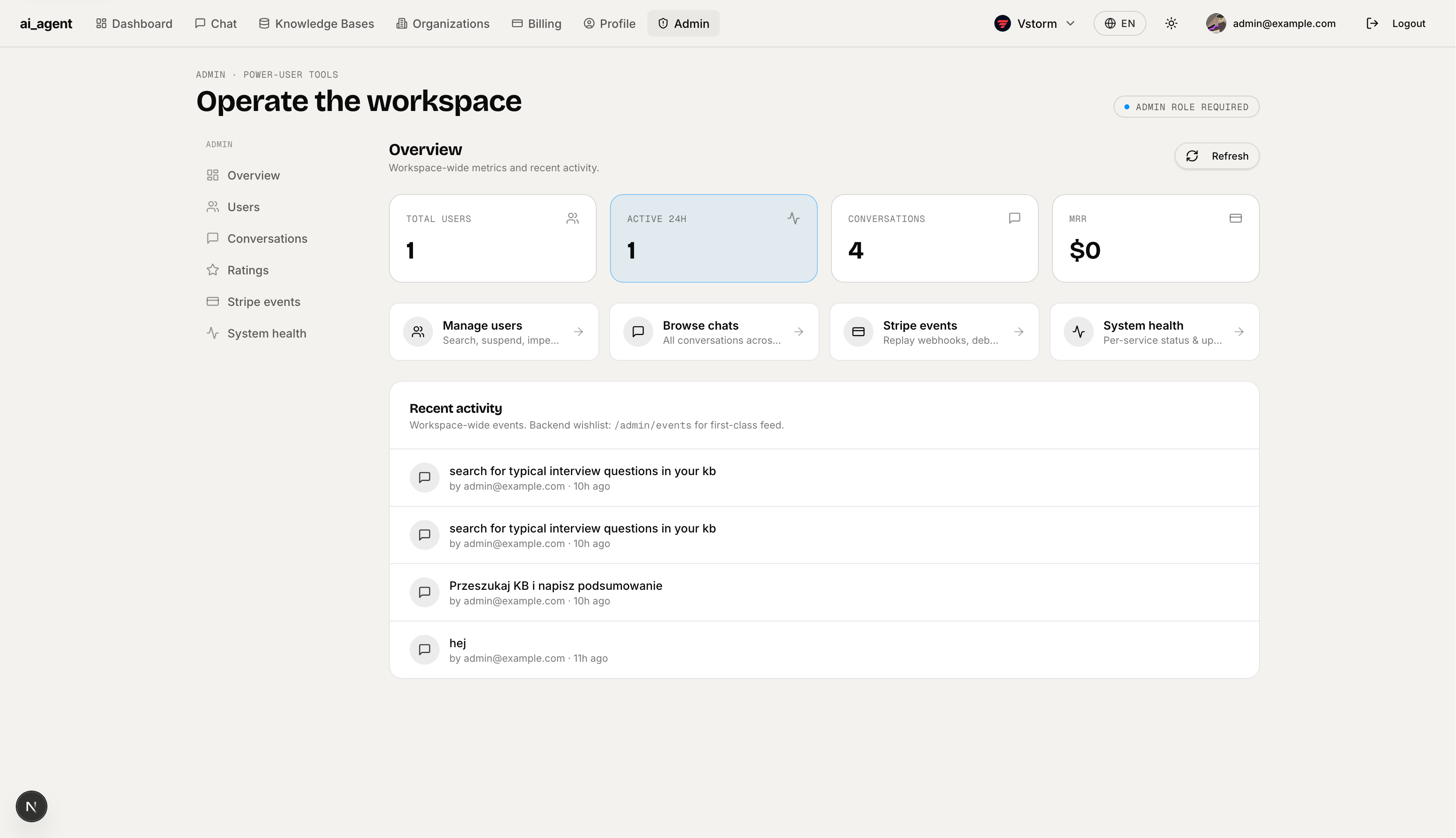
User Management — Full user list with search by email or name. Shows role, status, join date, and an "Inspect" action to impersonate or suspend any user. Pagination built in.
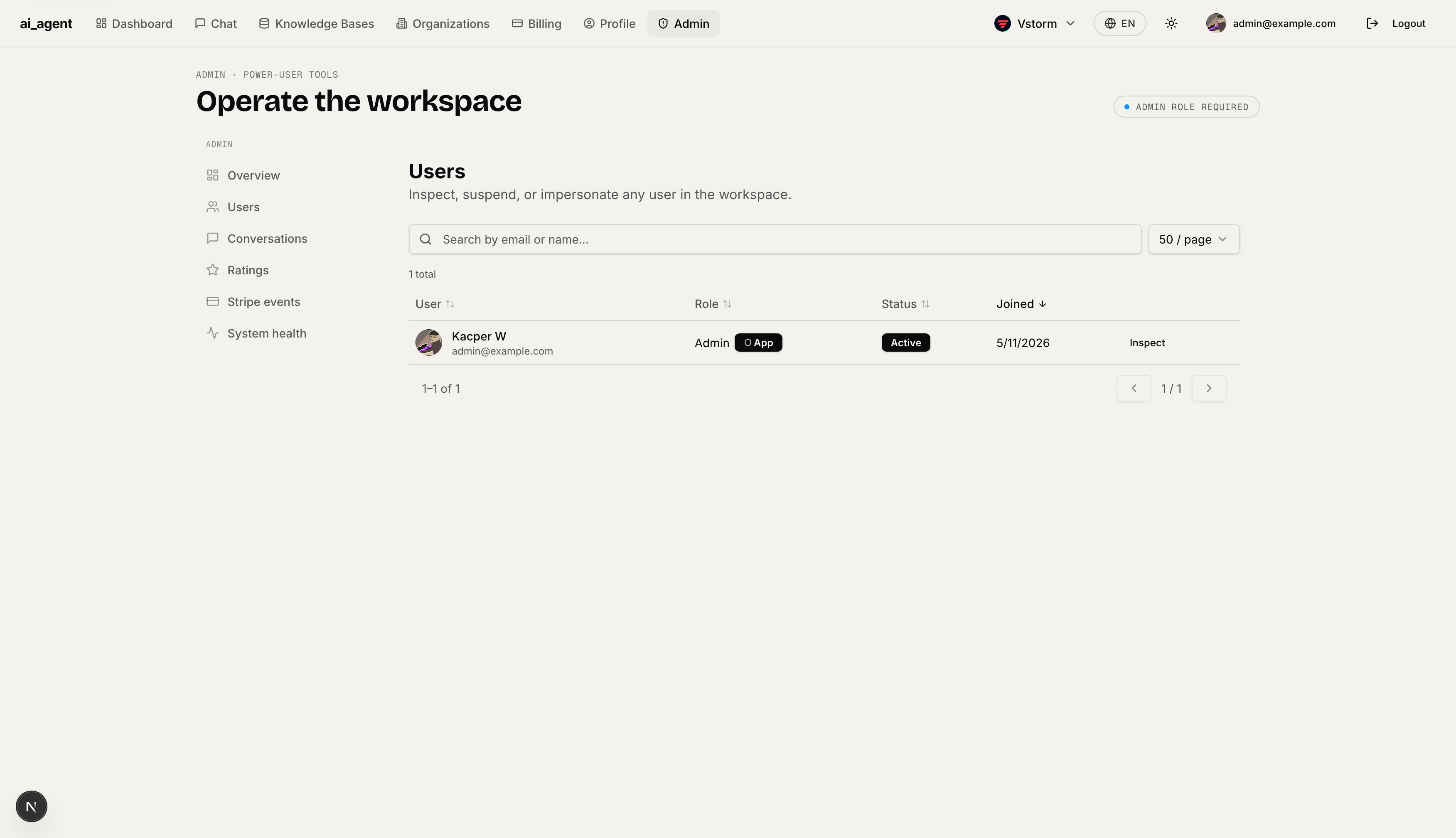
Conversation Browser — Browse all conversations across the workspace. Filter by status and owner, sort by any column, open any conversation in a read-only view. Useful for support and quality review.
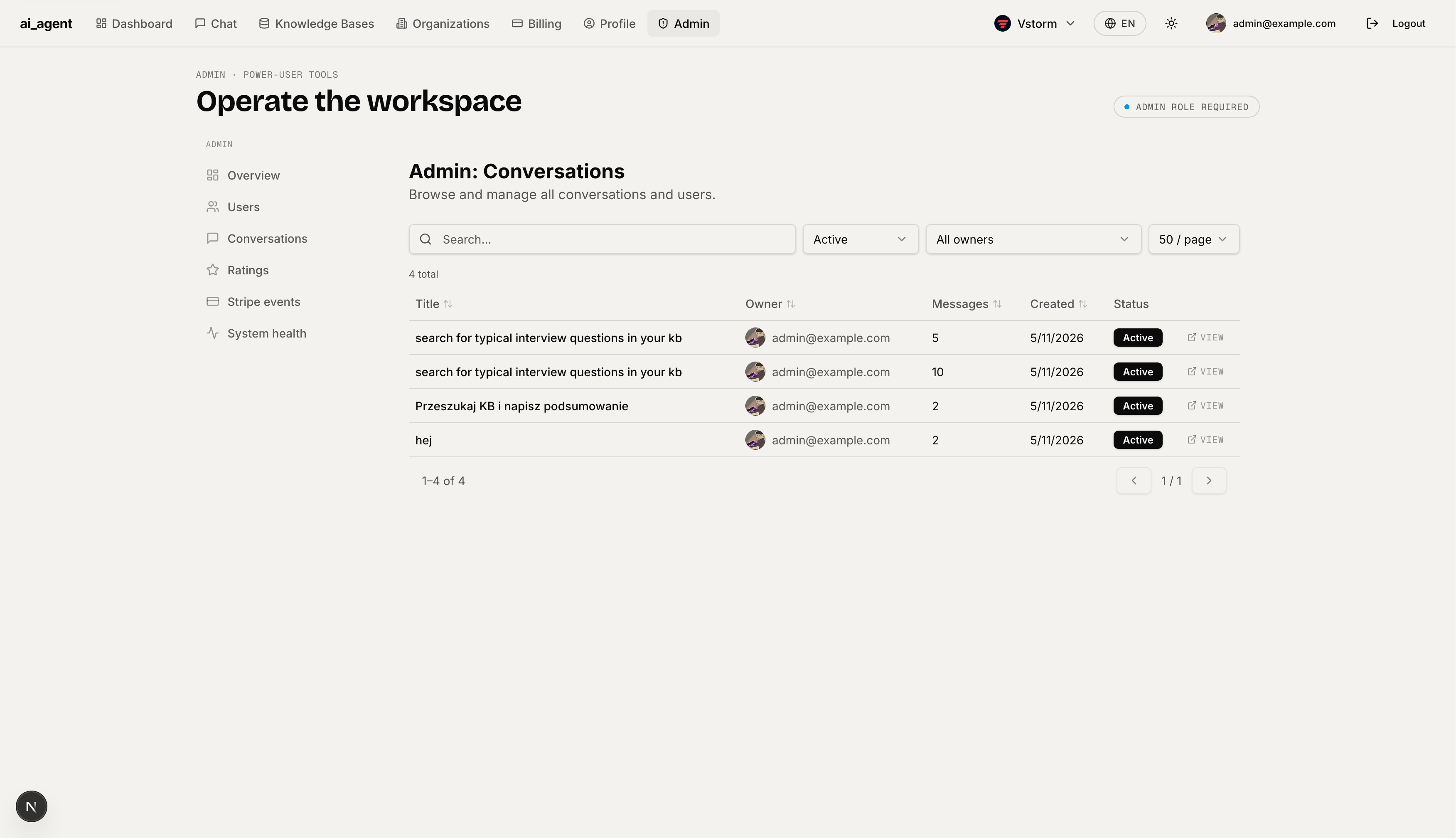
Message Quality & Ratings — Aggregated like/dislike feedback on AI responses over the last 30 days. Shows approval rate, daily chart, and a filterable table of individual ratings with optional user comments. Export to CSV.
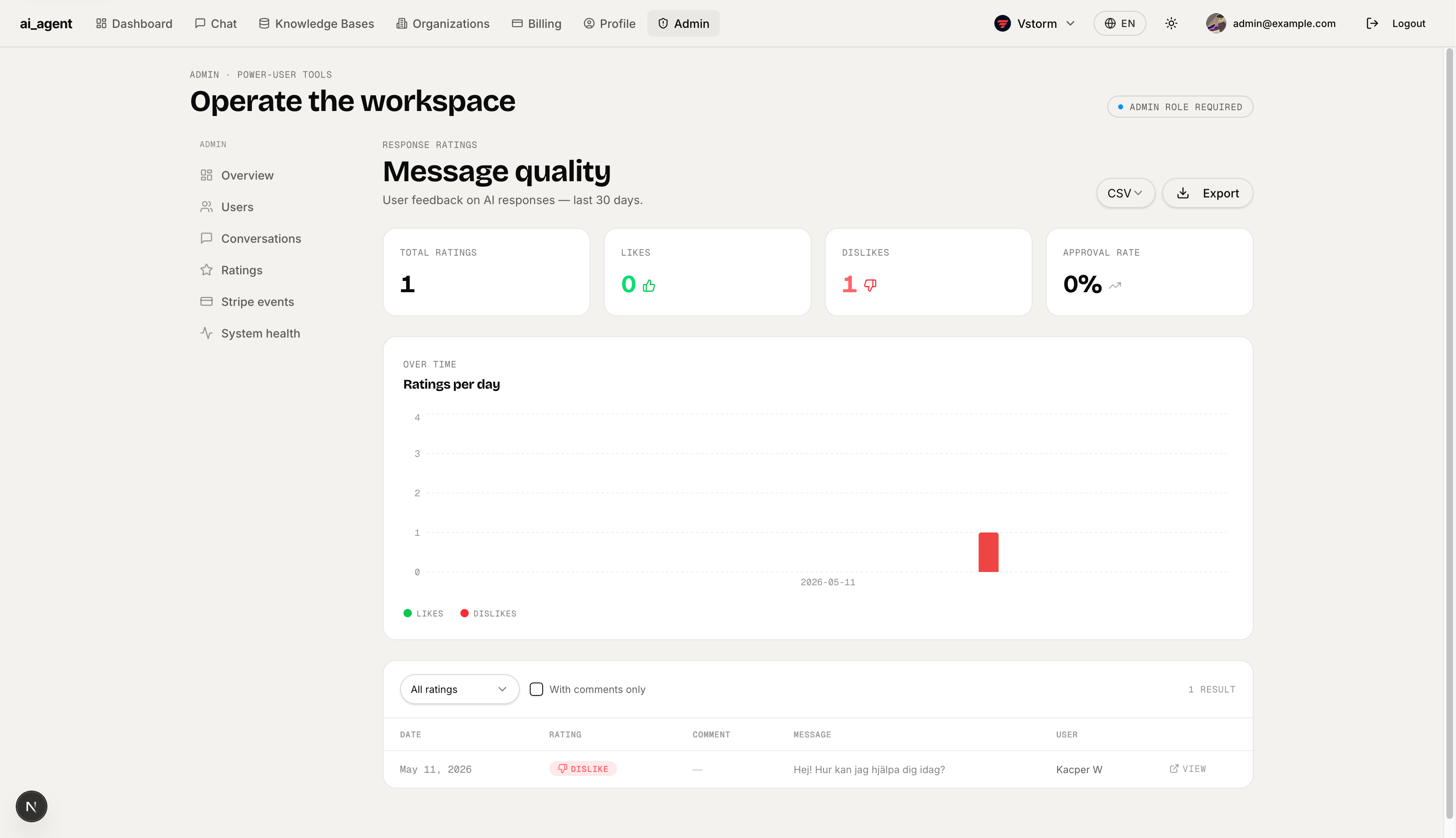
Stripe Events Log — Webhook event browser for debugging Stripe billing flows. Lists all received events (type, customer, amount, status, timestamp) and lets admins manually replay any event via the backend /admin/stripe-events/{id}/replay endpoint.
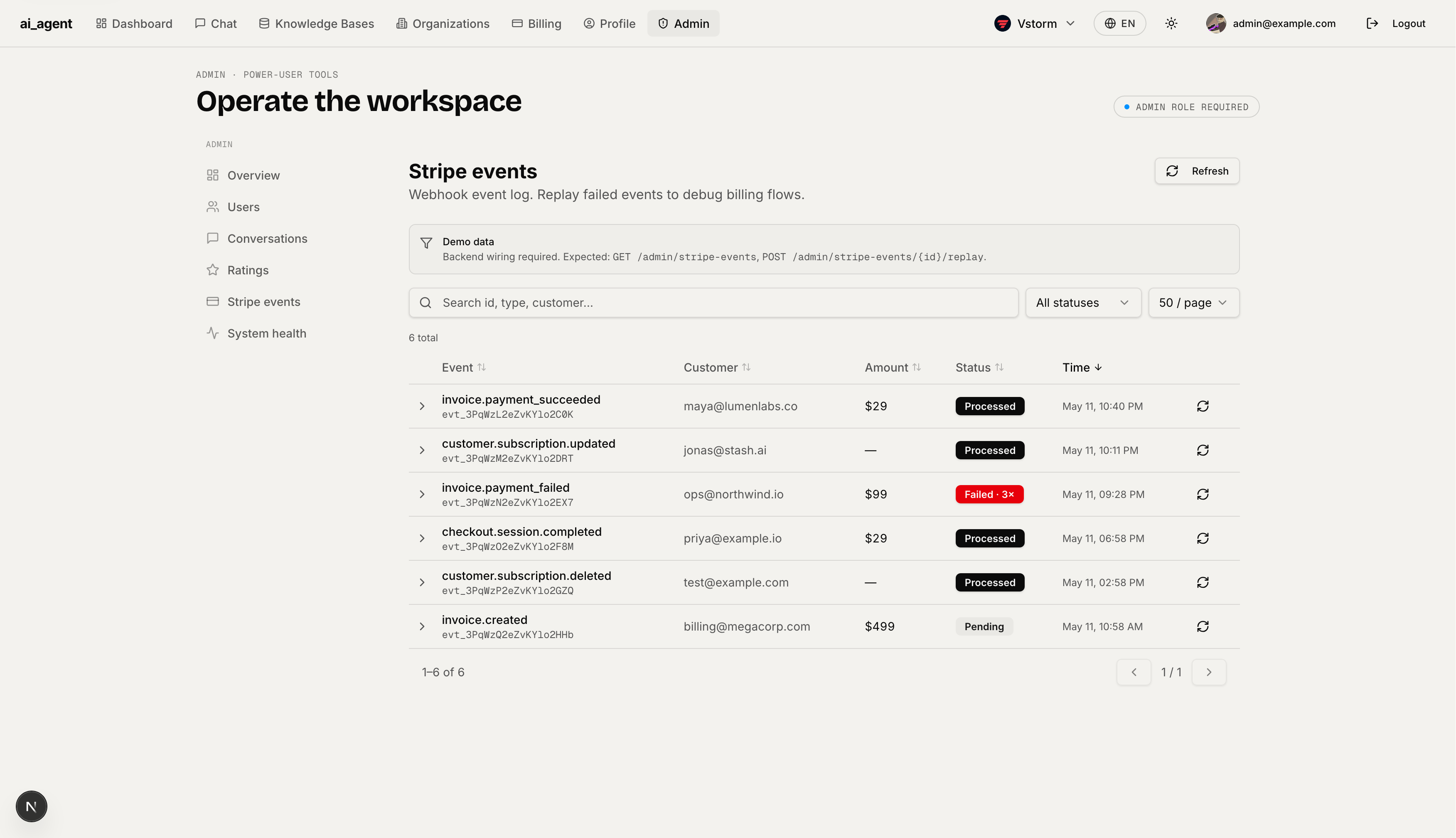
System Health — Live readiness dashboard auto-refreshing every 30 seconds. Checks API, Database (PostgreSQL primary), Redis, Vector store, LLM provider, Background worker, and Stripe API. Shows uptime percentage per service.
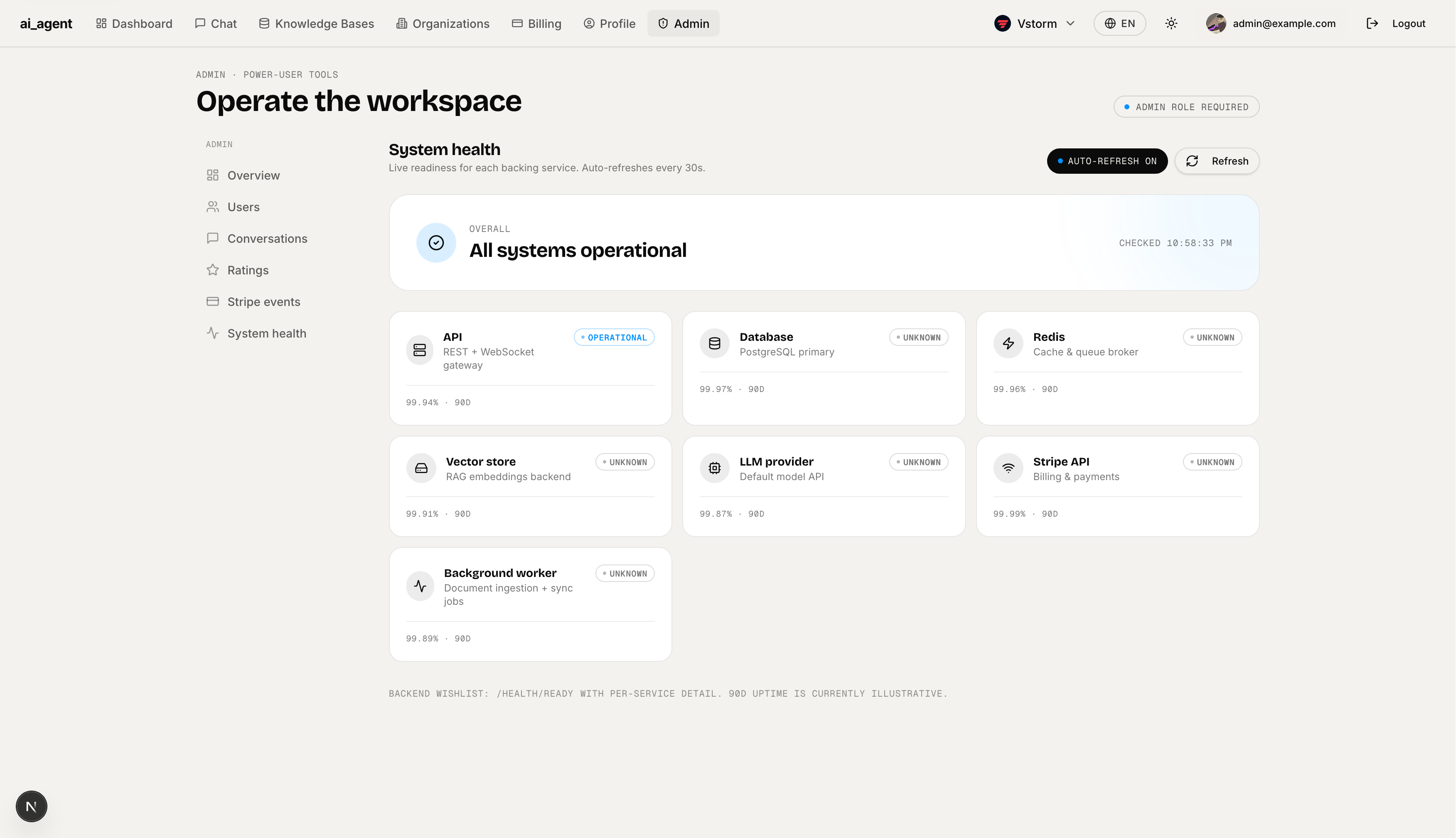
Logfire (PydanticAI) — Full distributed tracing for PydanticAI agent runs, FastAPI requests, database queries, Redis, Celery tasks, and HTTPX calls — all in one timeline.
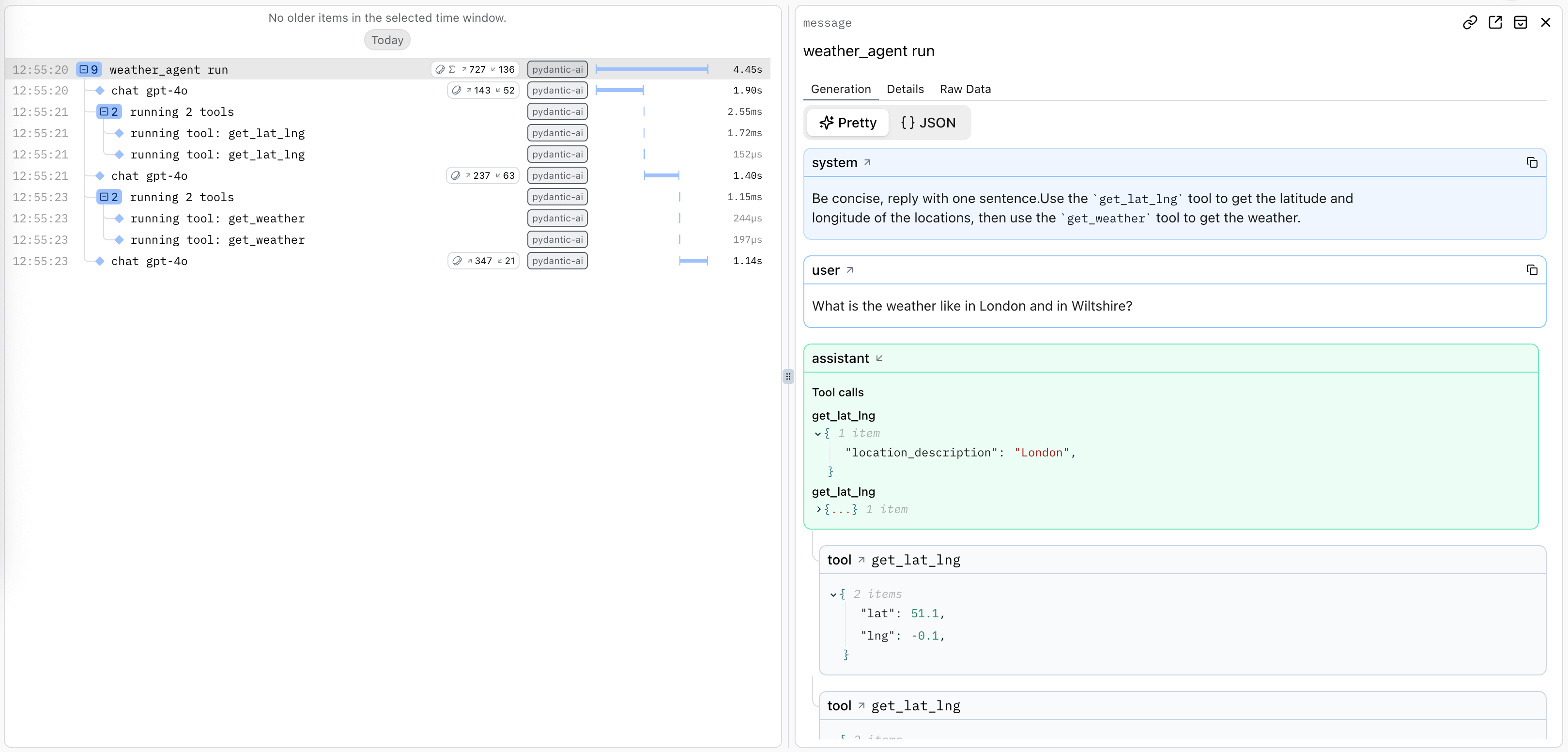
LangSmith (LangChain / LangGraph) — Trace viewer for LangChain agent runs with step-by-step chain inspection, token usage, and feedback collection.
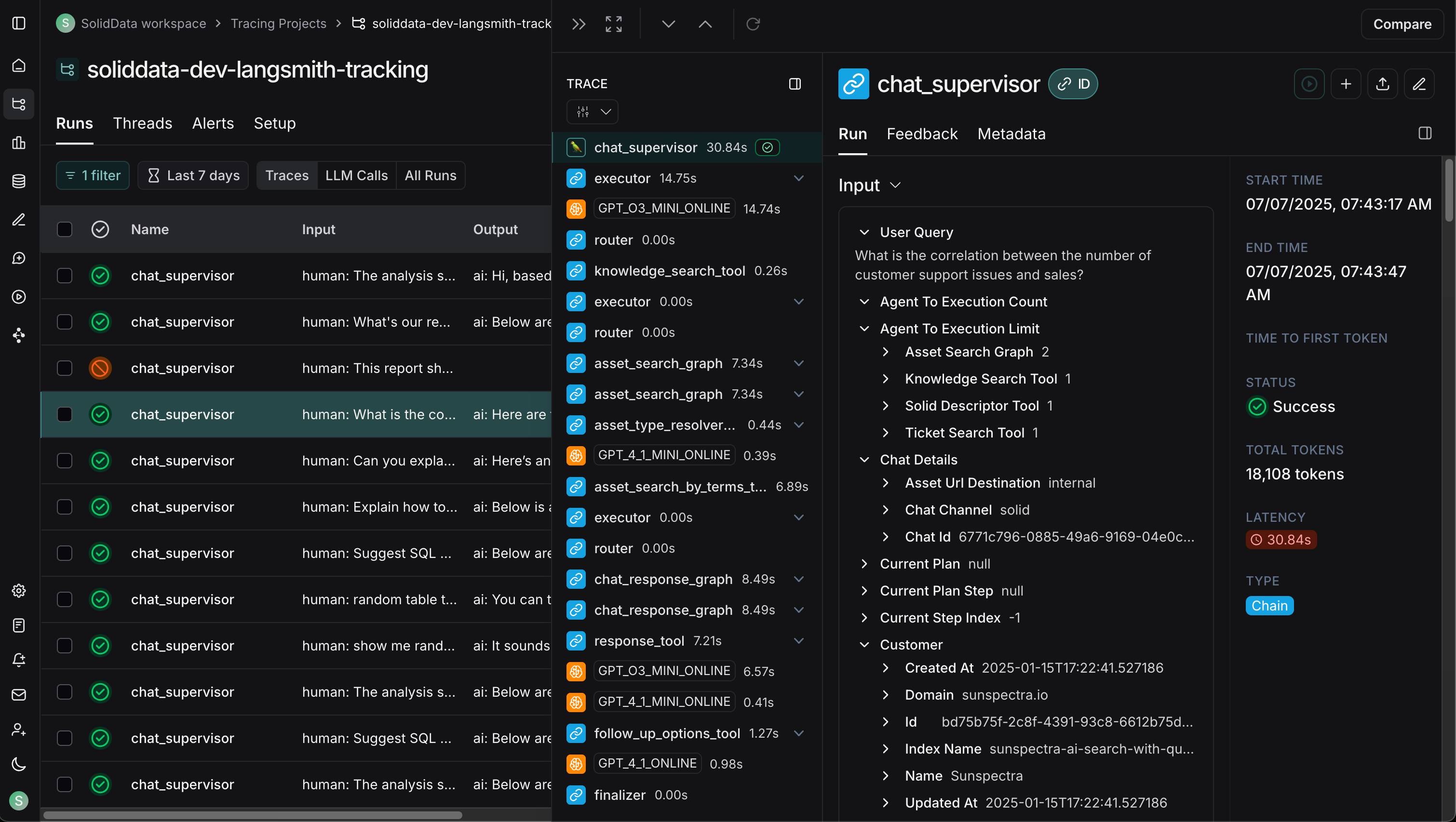
Telegram Bot — Multi-bot integration with both polling and webhook modes. Each bot gets its own session, supports group concurrency control, and routes messages through the same agent pipeline as the web UI.
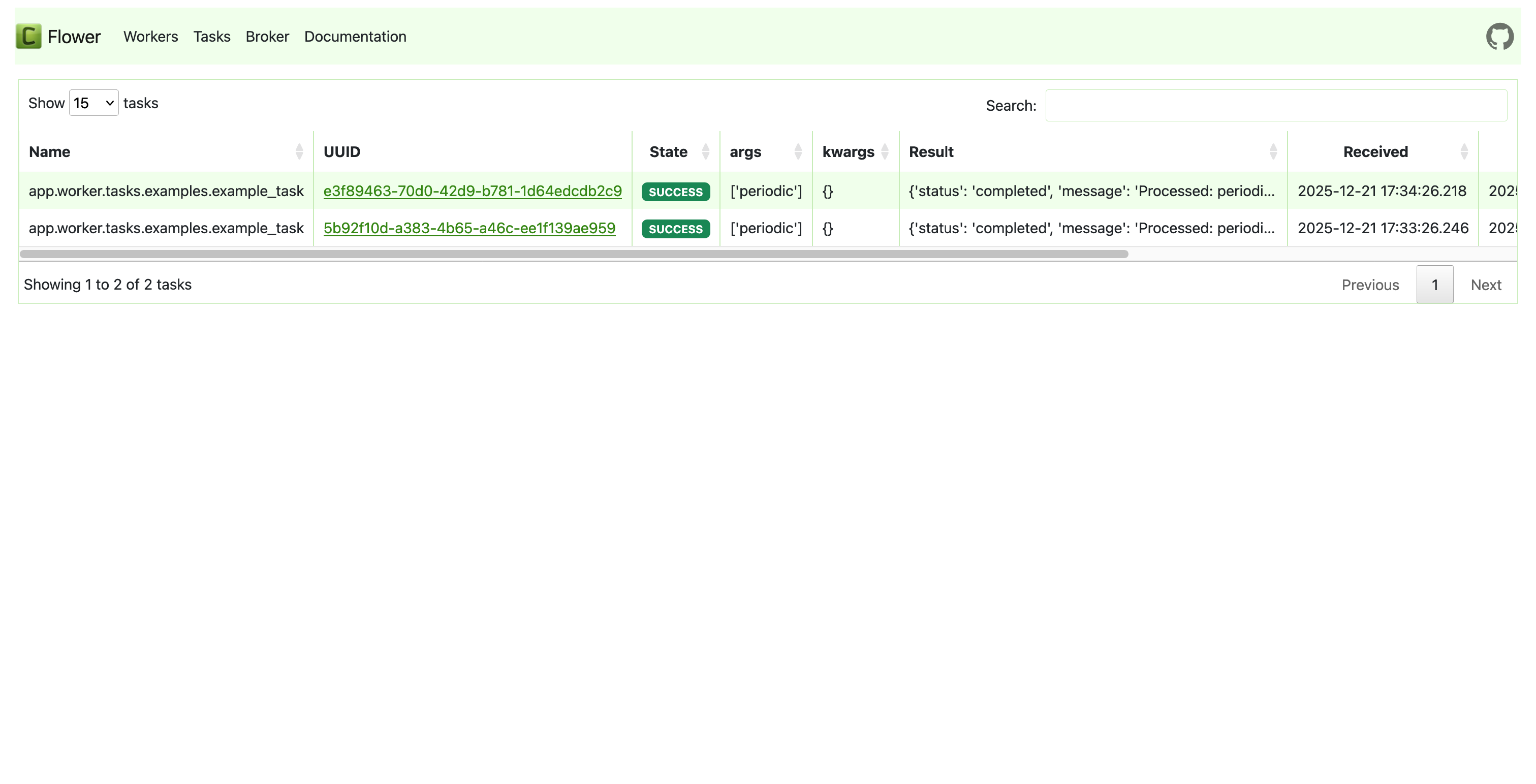
Celery Flower — Real-time task queue monitor. Track worker status, task throughput, and failure rates for background jobs (document ingestion, email, webhooks).
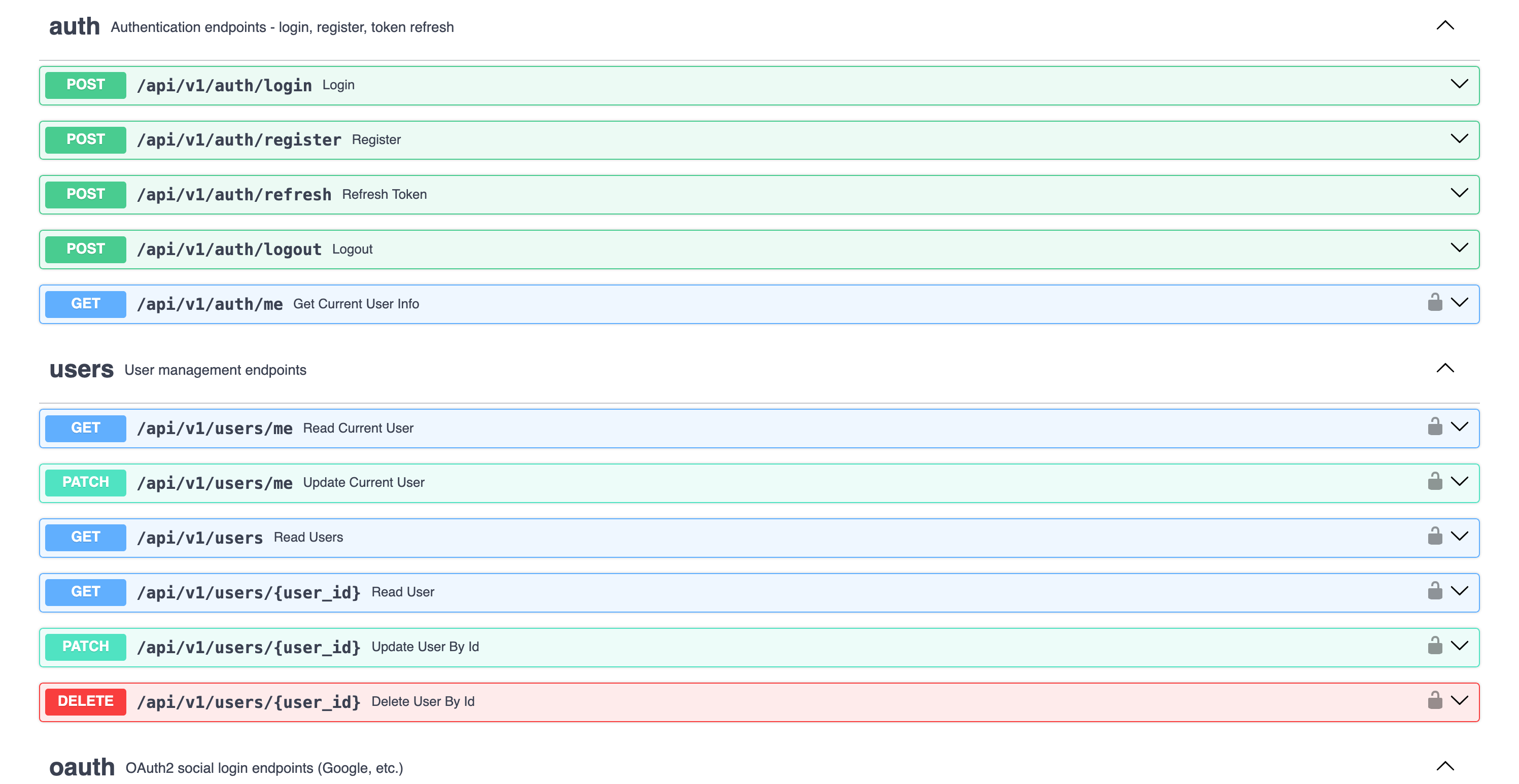
API Documentation — Auto-generated OpenAPI / Swagger UI at /docs. All endpoints documented with request/response schemas, auth requirements, and example payloads.
Building AI/LLM applications requires more than just an API wrapper. You need:
- Type-safe AI agents with tool/function calling
- Real-time streaming responses via WebSocket
- Conversation persistence and history management
- Production infrastructure - auth, rate limiting, observability
- Enterprise integrations - background tasks, webhooks, admin panels
This template gives you all of that out of the box, with 20+ configurable integrations so you can focus on building your AI product, not boilerplate.
- 🤖 AI Chatbots & Assistants - PydanticAI or LangChain agents with streaming responses
- 📊 ML Applications - Background task processing with Celery/Taskiq
- 🏢 Enterprise SaaS - Full auth, admin panel, webhooks, and more
- 🚀 Startups - Ship fast with production-ready infrastructure
Generated projects include CLAUDE.md and AGENTS.md files optimized for AI coding assistants (Claude Code, Codex, Copilot, Cursor, Zed). Following progressive disclosure best practices - concise project overview with pointers to detailed docs when needed.
- 6 AI Frameworks - PydanticAI, PydanticDeep, LangChain, LangGraph, CrewAI, DeepAgents
- 4 LLM Providers - OpenAI, Anthropic, Google Gemini, OpenRouter
- RAG - Document ingestion, vector search, reranking (Milvus, Qdrant, ChromaDB, pgvector)
- WebSocket Streaming - Real-time responses with full event access
- Messaging Channels - Telegram and Slack multi-bot integration with polling, webhooks, per-thread sessions, group concurrency control
- Conversation Sharing - Share conversations with users or via public links, admin conversation browser
- Conversation Persistence - Save chat history to database
- Message Ratings - Like/dislike responses with feedback, admin analytics
- Image Description - Extract images from documents, describe via LLM vision
- Multimodal Embeddings - Google Gemini embedding model (text + images)
- Document Sources - Local files, API upload, Google Drive, S3/MinIO
- Sync Sources - Configurable connectors (Google Drive, S3) with scheduled sync
- Observability - Logfire for PydanticAI, LangSmith for LangChain/LangGraph/DeepAgents
- FastAPI + Pydantic v2 - High-performance async API
- Multiple Databases - PostgreSQL (async), MongoDB (async), SQLite
- Authentication - JWT + Refresh tokens, API Keys, OAuth2 (Google)
- Background Tasks - Celery, Taskiq, or ARQ
- Django-style CLI - Custom management commands with auto-discovery
- React 19 + TypeScript + Tailwind CSS v4
- AI Chat Interface - WebSocket streaming, tool call visualization
- Authentication - HTTP-only cookies, auto-refresh, password reset, magic link
- Marketing Site - hero, pricing, FAQ, blog, contact form, legal pages (PL + EN)
- User Settings - profile, API keys CRUD (
sk_*tokens), onboarding tracking - Admin Panel - workspace stats, Stripe events browser
- SEO - per-page metadata, OG image, sitemap, robots, manifest, favicons
- Dark Mode + i18n (PL/EN via next-intl, locale-prefixed routes)
| Category | Integrations |
|---|---|
| AI Frameworks | PydanticAI, PydanticDeep, LangChain, LangGraph, CrewAI, DeepAgents |
| LLM Providers | OpenAI, Anthropic, Google Gemini, OpenRouter |
| RAG / Vector Stores | Milvus, Qdrant, ChromaDB, pgvector |
| RAG Sources | Local files, API upload, Google Drive, S3/MinIO, Sync Sources (configurable, scheduled) |
| Embeddings | OpenAI, Voyage, Gemini (multimodal), SentenceTransformers |
| Caching & State | Redis, fastapi-cache2 |
| Security | Rate limiting, CORS, CSRF protection |
| Observability | Logfire, LangSmith, Sentry, Prometheus |
| Admin | SQLAdmin panel with auth |
| Collaboration | Conversation sharing (direct + link), admin conversation browser |
| Messaging | Telegram multi-bot (polling + webhook), Slack multi-bot (Events API + Socket Mode) |
| Events | Webhooks, WebSockets |
| DevOps | Docker, GitHub Actions, GitLab CI, Kubernetes |
┌──────────────────────────────────────────────────────────────────────────┐
│ FRONTEND (Next.js 15) │
│ Chat UI · Knowledge Base · Dashboard · Settings · Dark Mode · i18n │
└──────────────┬───────────────────────────────────────────┬───────────────┘
│ REST / WebSocket │ Vercel
▼ ▼
┌──────────────────────────────────────────────────────────────────────────┐
│ BACKEND (FastAPI) │
│ │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ AI AGENTS │ │
│ │ PydanticAI · LangChain · LangGraph · CrewAI · DeepAgents │ │
│ │ ──────────────────────────────────────────────────────────── │ │
│ │ Tools: datetime · web_search (Tavily) · search_knowledge_base │ │
│ │ Providers: OpenAI · Anthropic · Gemini · OpenRouter │ │
│ └─────────────────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ RAG PIPELINE │ │
│ │ │ │
│ │ Sources Parse Chunk Embed │ │
│ │ ───────── ────────── ────────── ────────────── │ │
│ │ Local files PyMuPDF recursive OpenAI │ │
│ │ API upload LiteParse markdown Voyage │ │
│ │ Google Drive LlamaParse fixed Gemini (multi) │ │
│ │ S3/MinIO python-docx SentenceTransf. │ │
│ │ Sync Sources │ │
│ │ │ │
│ │ Store Search Rank │ │
│ │ ────────────── ────────────── ────────────── │ │
│ │ Milvus Vector similarity Cohere reranker │ │
│ │ Qdrant BM25 + vector RRF CrossEncoder │ │
│ │ ChromaDB Multi-collection │ │
│ │ pgvector │ │
│ └─────────────────────────────────────────────────────────────────┘ │
│ │
│ Auth (JWT/API Key/OAuth) · Rate Limiting · Webhooks · Admin Panel │
│ Background Tasks (Celery/Taskiq/ARQ) · Django-style CLI │
│ Observability (Logfire/LangSmith/Sentry/Prometheus) │
└───────┬──────────────┬──────────────┬──────────────┬─────────────────────┘
│ │ │ │
▼ ▼ ▼ ▼
PostgreSQL Redis Vector DB LLM APIs
MongoDB (Milvus/ (OpenAI/
SQLite Qdrant/ Anthropic/
ChromaDB/ Gemini)
pgvector)
graph TB
subgraph Frontend["Frontend (Next.js 15)"]
UI[React Components]
WS[WebSocket Client]
Store[Zustand Stores]
end
subgraph Backend["Backend (FastAPI)"]
API[API Routes]
Services[Services Layer]
Repos[Repositories]
Agent[AI Agent]
end
subgraph Infrastructure
DB[(PostgreSQL/MongoDB)]
Redis[(Redis)]
Queue[Celery/Taskiq]
end
subgraph External
LLM[OpenAI/Anthropic]
Webhook[Webhook Endpoints]
end
UI --> API
WS <--> Agent
API --> Services
Services --> Repos
Services --> Agent
Repos --> DB
Agent --> LLM
Services --> Redis
Services --> Queue
Services --> Webhook
The backend follows a clean Repository + Service pattern:
graph LR
A[API Routes] --> B[Services]
B --> C[Repositories]
C --> D[(Database)]
B --> E[External APIs]
B --> F[AI Agents]
| Layer | Responsibility |
|---|---|
| Routes | HTTP handling, validation, auth |
| Services | Business logic, orchestration |
| Repositories | Data access, queries |
See Architecture Documentation for details.
Choose from 6 AI frameworks and 4 LLM providers when generating your project:
# PydanticAI with OpenAI (default)
fastapi-fullstack create my_app --ai-framework pydantic_ai
# LangGraph with Anthropic
fastapi-fullstack create my_app --ai-framework langgraph --llm-provider anthropic
# CrewAI with Google Gemini
fastapi-fullstack create my_app --ai-framework crewai --llm-provider google
# DeepAgents with OpenAI
fastapi-fullstack create my_app --ai-framework deepagents
# With RAG enabled
fastapi-fullstack create my_app --rag --database postgresql --task-queue celery| Framework | OpenAI | Anthropic | Gemini | OpenRouter |
|---|---|---|---|---|
| PydanticAI | ✓ | ✓ | ✓ | ✓ |
| PydanticDeep | ✓ | ✓ | ✓ | - |
| LangChain | ✓ | ✓ | ✓ | - |
| LangGraph | ✓ | ✓ | ✓ | - |
| CrewAI | ✓ | ✓ | ✓ | - |
| DeepAgents | ✓ | ✓ | ✓ | - |
Type-safe agents with full dependency injection:
# app/agents/assistant.py
from pydantic_ai import Agent, RunContext
@dataclass
class Deps:
user_id: str | None = None
db: AsyncSession | None = None
agent = Agent[Deps, str](
model="openai:gpt-4o-mini",
system_prompt="You are a helpful assistant.",
)
@agent.tool
async def search_database(ctx: RunContext[Deps], query: str) -> list[dict]:
"""Search the database for relevant information."""
# Access user context and database via ctx.deps
...Flexible agents with LangGraph:
# app/agents/langchain_assistant.py
from langchain.tools import tool
from langgraph.prebuilt import create_react_agent
@tool
def search_database(query: str) -> list[dict]:
"""Search the database for relevant information."""
...
agent = create_react_agent(
model=ChatOpenAI(model="gpt-4o-mini"),
tools=[search_database],
prompt="You are a helpful assistant.",
)Both frameworks use the same WebSocket endpoint with real-time streaming:
@router.websocket("/ws")
async def agent_ws(websocket: WebSocket):
await websocket.accept()
# Works with both PydanticAI and LangChain
async for event in agent.stream(user_input):
await websocket.send_json({
"type": "text_delta",
"content": event.content
})Each framework has its own observability solution:
| Framework | Observability | Dashboard |
|---|---|---|
| PydanticAI | Logfire | Agent runs, tool calls, token usage |
| LangChain | LangSmith | Traces, feedback, datasets |
See AI Agent Documentation for more.
Enable RAG to give your AI agents access to a knowledge base built from your documents.
| Backend | Type | Docker Required | Best For |
|---|---|---|---|
| Milvus | Dedicated vector DB | Yes (3 services) | Production, large scale |
| Qdrant | Dedicated vector DB | Yes (1 service) | Production, simple setup |
| ChromaDB | Embedded / HTTP | No | Development, prototyping |
| pgvector | PostgreSQL extension | No (uses existing PG) | Already have PostgreSQL |
# Local files
uv run my_app rag-ingest /path/to/document.pdf --collection docs
uv run my_app rag-ingest /path/to/folder/ --recursive
# Google Drive (service account)
uv run my_app rag-sync-gdrive --collection docs --folder-id <drive_folder_id>
# S3/MinIO
uv run my_app rag-sync-s3 --collection docs --prefix reports/ --bucket my-bucket| Provider | Model | Dimensions | Multimodal |
|---|---|---|---|
| OpenAI | text-embedding-3-small | 1536 | - |
| Voyage | voyage-3 | 1024 | - |
| Gemini | gemini-embedding-exp-03-07 | 3072 | Text + Images |
| SentenceTransformers | all-MiniLM-L6-v2 | 384 | - |
- Document parsing - PDF (PyMuPDF with tables, headers/footers, OCR), DOCX, TXT, MD + 130+ formats via LlamaParse
- Image description - Extract images from documents, describe via LLM vision API (opt-in)
- Chunking - RecursiveCharacterTextSplitter with configurable size/overlap
- Reranking - Cohere API or local CrossEncoder for improved search quality
- Agent integration - All 6 AI frameworks get a
search_knowledge_basetool automatically
Logfire provides complete observability for your application - from AI agents to database queries. Built by the Pydantic team, it offers first-class support for the entire Python ecosystem.
graph LR
subgraph Your App
API[FastAPI]
Agent[PydanticAI]
DB[(Database)]
Cache[(Redis)]
Queue[Celery/Taskiq]
HTTP[HTTPX]
end
subgraph Logfire
Traces[Traces]
Metrics[Metrics]
Logs[Logs]
end
API --> Traces
Agent --> Traces
DB --> Traces
Cache --> Traces
Queue --> Traces
HTTP --> Traces
| Component | What You See |
|---|---|
| PydanticAI | Agent runs, tool calls, LLM requests, token usage, streaming events |
| FastAPI | Request/response traces, latency, status codes, route performance |
| PostgreSQL/MongoDB | Query execution time, slow queries, connection pool stats |
| Redis | Cache hits/misses, command latency, key patterns |
| Celery/Taskiq | Task execution, queue depth, worker performance |
| HTTPX | External API calls, response times, error rates |
LangSmith provides observability specifically designed for LangChain applications:
| Feature | Description |
|---|---|
| Traces | Full execution traces for agent runs and chains |
| Feedback | Collect user feedback on agent responses |
| Datasets | Build evaluation datasets from production data |
| Monitoring | Track latency, errors, and token usage |
LangSmith is automatically configured when you choose LangChain:
# .env
LANGCHAIN_TRACING_V2=true
LANGCHAIN_API_KEY=your-api-key
LANGCHAIN_PROJECT=my_projectEnable Logfire and select which components to instrument:
fastapi-fullstack new
# ✓ Enable Logfire observability
# ✓ Instrument FastAPI
# ✓ Instrument Database
# ✓ Instrument Redis
# ✓ Instrument Celery
# ✓ Instrument HTTPX# Automatic instrumentation in app/main.py
import logfire
logfire.configure()
logfire.instrument_fastapi(app)
logfire.instrument_asyncpg()
logfire.instrument_redis()
logfire.instrument_httpx()# Manual spans for custom logic
with logfire.span("process_order", order_id=order.id):
await validate_order(order)
await charge_payment(order)
await send_confirmation(order)For more details, see Logfire Documentation.
Each generated project includes a powerful CLI inspired by Django's management commands:
# Server
my_app server run --reload
my_app server routes
# Database (Alembic wrapper)
my_app db init
my_app db migrate -m "Add users"
my_app db upgrade
# Users
my_app user create --email admin@example.com --superuser
my_app user listCreate your own commands with auto-discovery:
# app/commands/seed.py
from app.commands import command, success, error
import click
@command("seed", help="Seed database with test data")
@click.option("--count", "-c", default=10, type=int)
@click.option("--dry-run", is_flag=True)
def seed_database(count: int, dry_run: bool):
"""Seed the database with sample data."""
if dry_run:
info(f"[DRY RUN] Would create {count} records")
return
# Your logic here
success(f"Created {count} records!")Commands are automatically discovered from app/commands/ - just create a file and use the @command decorator.
my_app cmd seed --count 100
my_app cmd seed --dry-runmy_project/
├── backend/
│ ├── app/
│ │ ├── main.py # FastAPI app with lifespan
│ │ ├── api/
│ │ │ ├── routes/v1/ # Versioned API endpoints
│ │ │ ├── deps.py # Dependency injection
│ │ │ └── router.py # Route aggregation
│ │ ├── core/ # Config, security, middleware
│ │ ├── db/models/ # SQLAlchemy/MongoDB models
│ │ ├── schemas/ # Pydantic schemas
│ │ ├── repositories/ # Data access layer
│ │ ├── services/ # Business logic
│ │ ├── agents/ # AI agents with centralized prompts
│ │ ├── rag/ # RAG module (vector store, embeddings, ingestion)
│ │ ├── commands/ # Django-style CLI commands
│ │ └── worker/ # Background tasks
│ ├── cli/ # Project CLI
│ ├── tests/ # pytest test suite
│ └── alembic/ # Database migrations
├── frontend/
│ ├── src/
│ │ ├── app/ # Next.js App Router
│ │ ├── components/ # React components
│ │ ├── hooks/ # useChat, useWebSocket, etc.
│ │ └── stores/ # Zustand state management
│ └── e2e/ # Playwright tests
├── docker-compose.yml
├── Makefile
└── README.md
Generated projects include version metadata in pyproject.toml for tracking:
[tool.fastapi-fullstack]
generator_version = "0.1.5"
generated_at = "2024-12-21T10:30:00+00:00"| Option | Values | Description |
|---|---|---|
| Database | postgresql, mongodb, sqlite, none |
Async by default |
| ORM | sqlalchemy, sqlmodel |
SQLModel for simplified syntax |
| Auth | jwt, api_key, both, none |
JWT includes user management |
| OAuth | none, google |
Social login |
| AI Framework | pydantic_ai, langchain, langgraph, crewai, deepagents |
Choose your AI agent framework |
| LLM Provider | openai, anthropic, google, openrouter |
OpenRouter only with PydanticAI |
| RAG | --rag |
Enable RAG with vector database |
| Vector Store | milvus, qdrant, chromadb, pgvector |
pgvector uses existing PostgreSQL |
| Background Tasks | none, celery, taskiq, arq |
Distributed queues |
| Frontend | none, nextjs |
Next.js 15 + React 19 |
| Preset | Description |
|---|---|
--preset production |
Full production setup with Redis, Sentry, Kubernetes, Prometheus |
--preset ai-agent |
AI agent with WebSocket streaming and conversation persistence |
--minimal |
Minimal project with no extras |
Select what you need:
fastapi-fullstack new
# ✓ Redis (caching/sessions)
# ✓ Rate limiting (slowapi)
# ✓ Pagination (fastapi-pagination)
# ✓ Admin Panel (SQLAdmin)
# ✓ AI Agent (PydanticAI or LangChain)
# ✓ Webhooks
# ✓ Sentry
# ✓ Logfire / LangSmith
# ✓ Prometheus
# ... and moreSetting up a production AI agent stack manually means wiring together 10+ tools yourself:
# Without this template, you'd need to manually:
# 1. Set up FastAPI project structure
# 2. Configure SQLAlchemy + Alembic migrations
# 3. Implement JWT auth with refresh tokens
# 4. Build WebSocket streaming for AI responses
# 5. Integrate PydanticAI/LangChain with tool calling
# 6. Set up RAG pipeline (parsing, chunking, embedding, vector store)
# 7. Configure Celery + Redis for background tasks
# 8. Build Next.js frontend with auth and chat UI
# 9. Write Docker Compose for all services
# 10. Add observability, rate limiting, admin panel...
# With this template:
pip install fastapi-fullstack
fastapi-fullstack
# Done. All of the above, configured and working.| Feature | This Template | full-stack-fastapi-template | create-t3-app |
|---|---|---|---|
| AI Agents (5 frameworks) | ✅ | ❌ | ❌ |
| RAG Pipeline (4 vector stores) | ✅ | ❌ | ❌ |
| WebSocket Streaming | ✅ | ❌ | ❌ |
| Conversation Persistence | ✅ | ❌ | ❌ |
| LLM Observability (Logfire/LangSmith) | ✅ | ❌ | ❌ |
| FastAPI Backend | ✅ | ✅ | ❌ |
| Next.js Frontend | ✅ (v15) | ❌ | ✅ |
| JWT + OAuth Authentication | ✅ | ✅ | ✅ (NextAuth) |
| Background Tasks (Celery/Taskiq/ARQ) | ✅ | ✅ (Celery) | ❌ |
| Admin Panel | ✅ (SQLAdmin) | ❌ | ❌ |
| Multiple Databases (PG/Mongo/SQLite) | ✅ | PostgreSQL only | Prisma |
| Docker + K8s | ✅ | ✅ | ❌ |
| Interactive CLI Wizard | ✅ | ❌ | ✅ |
| Django-style Commands | ✅ | ❌ | ❌ |
| Document Sources (GDrive, S3, API) | ✅ | ❌ | ❌ |
| AI-Agent Friendly (CLAUDE.md) | ✅ | ❌ | ❌ |
How is this different from full-stack-fastapi-template?
full-stack-fastapi-template by @tiangolo is a great starting point for FastAPI projects, but it focuses on traditional web apps. This template is purpose-built for AI/LLM applications — it adds AI agents (5 frameworks), RAG with 4 vector stores, WebSocket streaming, conversation persistence, LLM observability, and a Next.js chat UI out of the box.
Can I use this without AI/LLM features?
Yes. The AI agent and RAG modules are optional. You can use this as a pure FastAPI + Next.js template with auth, admin panel, background tasks, and all other infrastructure — just skip the AI framework selection during setup.
What Python and Node.js versions are required?
Python 3.11+ and Node.js 18+ (for the Next.js frontend). We recommend using uv for Python and bun for the frontend.
Can I add integrations after project generation?
The generated project is plain code — no lock-in or runtime dependency on the generator. You can add, remove, or modify any integration manually. The template just gives you a well-structured starting point.
Can I use a different LLM provider than the one I selected?
Yes. The LLM provider is configured via environment variables (AI_MODEL, OPENAI_API_KEY, etc.). You can switch providers by changing the .env file and the model name — no code changes needed for PydanticAI (which supports all providers natively).
| Document | Description |
|---|---|
| Architecture | Repository + Service pattern, layered design |
| Frontend | Next.js setup, auth, state management |
| AI Agent | PydanticAI, tools, WebSocket streaming |
| Observability | Logfire integration, tracing, metrics |
| Deployment | Docker, Kubernetes, production setup |
| Development | Local setup, testing, debugging |
| Changelog | Version history and release notes |
This project is inspired by:
- full-stack-fastapi-template by @tiangolo
- fastapi-template by @s3rius
- FastAPI Best Practices by @zhanymkanov
- Django's management commands system
Contributions are welcome! Please read our Contributing Guide for details.
MIT License - see LICENSE for details.